
Experiences with Spinnaker on Adobe Experience Platform
Authors: Constantin Muraru, Iulian Titiriga, and Jody Arthur
Read about Adobe Experience Platform's experience using Spinnaker installed with Kubernetes to turn a cumbersome and error-prone, script-based deployment of critical applications into a fast and easy process resulting in better security, higher availability, and lower costs.
Today, Adobe uses Spinnaker to deploy some of our most critical Adobe Audience Manager applications to production, And, we're now using Spinnaker in Kubernetes to deploy Adobe Experience Platform's "new" Experience Edge in several regions across the world.
Most of our deployments are virtual machines in AWS Elastic Compute Cloud (Amazon EC2). We can deploy for staging purposes to some of our most critical applications. For example, we are now using Spinnaker to deploy Experience Edge is an Adobe Experience Platform initiative that provides a single, optimized gateway for requests that want to interact with other Adobe Experience Cloud edge services, such as Adobe Target, Adobe Audience Manager, and Adobe Analytics.
We first heard about Spinnaker in 2016 when Netflix published a blog post touting its benefits in automating deployments in AWS. However, it wasn't until earlier this year that, with the addition of Kubernetes, we were able to really get this powerful tool dialed in to fit our unique needs for deploying applications to the cloud at scale. This post describes our journey to where we are today with our cloud deployments, with the help of Spinnaker installed with Kubernetes.
Before Spinnaker
Before we began working with Spinnaker, deploying our Audience Manager applications was a cumbersome process, which took a lot of engineering effort and was prone to error. This is because we were using custom scripting to perform deployments from the developer's laptop (Figure 1). The deployment took a lot of time and would fail whenever the developer's laptop would run of battery or internet connection, or if the developer shut down the laptop by mistake while deployment was in progress. We were also still using custom scripting, so if a new version of an application did not function properly, we would have to roll back to the stable version. This required an additional script, and of course, the additional time required to write the script for a rollback resulted in availability issues for the user.
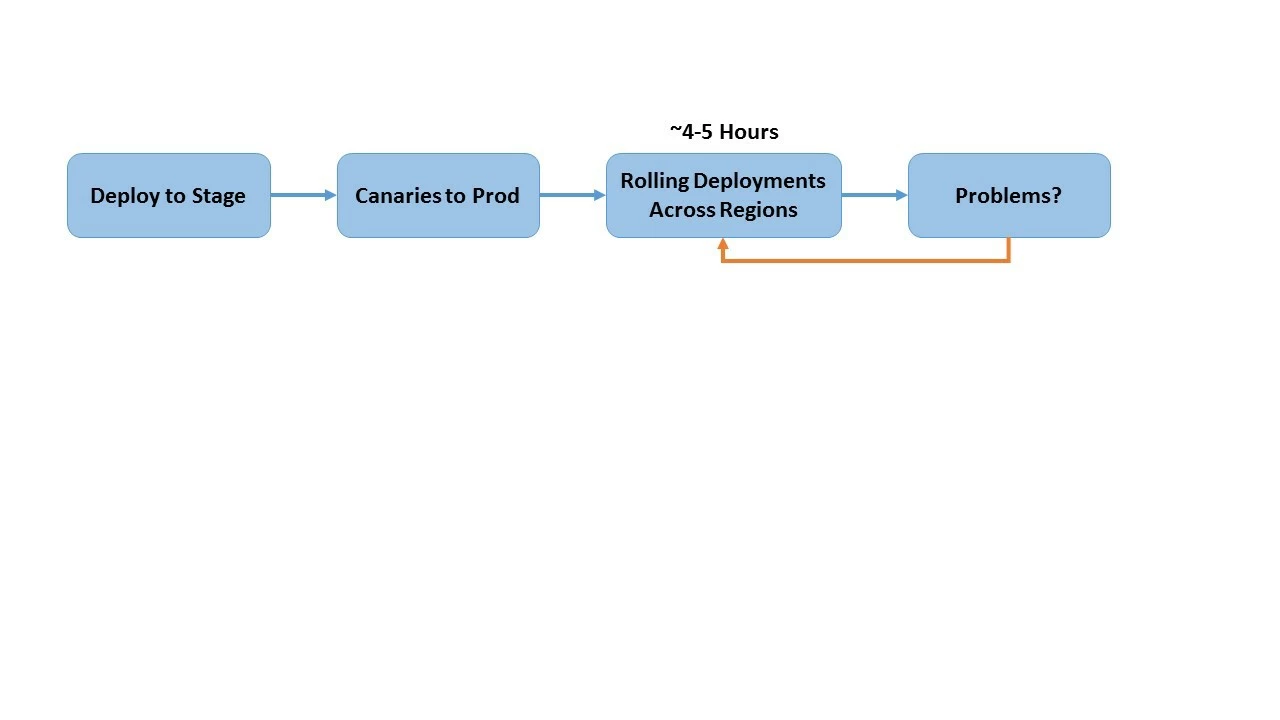
We were using this process to deploy what was (and still is) the most critical application we have in Audience Manager as a web service across the globe. Our deployment includes a few hundred servers hosted mostly on AWS. At this scale, deployment was an extremely time-consuming process because it required that we create RPM Packages for each type of virtual machine we were deploying and then installing them on hundreds of servers.
When we first heard of Spinnaker in 2016, we didn't quite have the bandwidth to give it a try. But as our deployment expanded into new regions and the installation and update processes became even more complicated, in 2017, we decided we had to invest the time in exploring Spinnaker.
To our pleasant surprise, that initial investment turned out to be quite minimal, thanks to a very useful starting guide we found for implementing Spinnaker on AWS. For our proof-of-concept, we used the CloudFormation template provided by AWS in order to automatically create the required resources. And in less than an hour, we had our automation up and running. Having gotten off to such a great start, we knew that Spinnaker was going to solve some of our most critical issues with deployment and save us an extraordinary amount of time.
Challenges encountered early in our Spinnaker journey
While our early use of Spinnaker was very promising, it was not without its issues. In order to bring Spinnaker to production deployment in our environment, we had to deal with the difference in distributions. At the time, Spinnaker was packaged for Ubuntu servers, which are built on the Debian architecture, while Adobe was moving toward CentOS, which is a Linux product. As a result, we had to spend significant time repackaging the Spinnaker services as RPMs and ensuring they would work. We were able to accomplish this work in a few months. However, this approach was less than ideal.
Spinnaker development is happening fast, which made it difficult to keep up. As a result, we quickly found ourselves left behind with the rapid introduction of new Spinnaker versions and services (e.g. Kayenta, Spinnaker's service for automatic canary analysis, was developed after we had completed repackaging the Spinnaker code as RPMs for CentOS).
At the same time, we were also experiencing significant growth in our client base, which would seem like a good problem to have. However, with more clients come more and more requests that need to be handled by our services. It wasn't long before our growth began offsetting some of the greatest advantages our Spinnaker implementation was providing.
Realizing the concept of "immutable infrastructure"
Before Spinnaker, our script-based deployment relied on a "mutable" infrastructure in which upgrades, downgrades, and configuration changes were made directly to our existing servers and deploying different code depending on the type of server we were using.
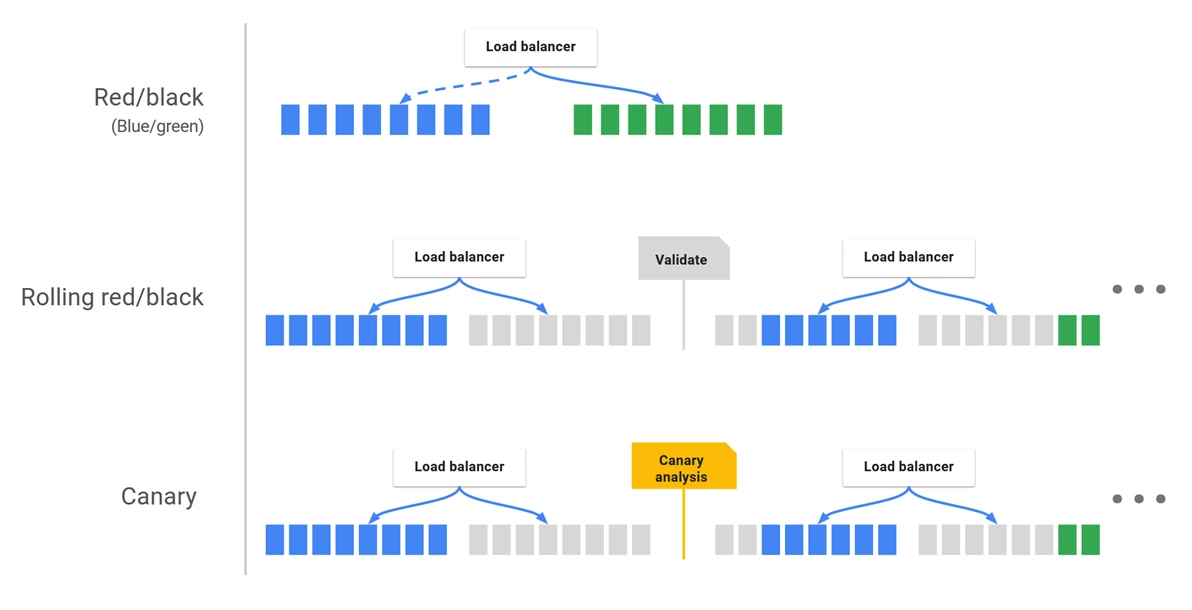
In contrast, Spinnaker provides the ability to create an "immutable infrastructure" that would allow us to leave our existing servers in place and unchanged while we work to create a new set of virtual servers from a common image alongside them. Using Spinnaker's deployment strategy (Figure 2), we can make all of our changes and tweaks to the new servers, verify that they are functioning properly, and deploy them thus avoiding issues such as configuration drift and snowflake servers. With the new servers online, the original servers can then be decommissioned.
Additional benefits of using Spinnaker for our deployment
We found that the ability to create an immutable infrastructure with Spinnaker is just one of the many benefits it provides. And because Spinnaker runs remotely on our Spinnaker servers, the problems we encountered before when deploying on individual laptops were eliminated. Other benefits we've enjoyed in our experience with Spinnaker include:
- Audit capabilities: With Spinnaker, developers are no longer required to run the deployment from their laptop, and with its audit capabilities, we now have the ability to see which developer performed what changes to a given application.
- Authorization at the application level: Before using Spinnaker for our deployment, all developers had to be given access to the AWS account, which meant that any developer would have access to servers belonging to all applications. What we really needed was to follow the principle of least privilege and have a more granular way to assign administrative rights. Spinnaker provides this with authorization at the application level, allowing us to grant access to specific users for specific needs.
- Better security: Before Spinnaker, application upgrades used the same fleet of servers, which meant that we had servers running for long periods (sometimes as much as 400 days) with no OS upgrade despite the availability of new upgrades. This is because it can be difficult to predict what that upgrade will do to existing applications, and with applications running on hundreds of servers, it was difficult and risky to perform OS upgrades. With the ability in Spinnaker to create an immutable infrastructure, we're able to spin up a new fleet of machines, allowing us to upgrade both the OS and Data Collection Servers at the same time. And, because many of the updates we perform involve security patches, using Spinnaker allows us to ensure better security.
- Reduced costs: Every year, AWS upgrades its own fleet of servers and offers better pricing. Before Spinnaker, the work involved in switching to these new servers significantly reducing the cost-benefit of doing so and thus limiting our ability to take advantage of better pricing. With Spinnaker, we can easily switch to a new, upgraded server, which allows us to optimize our costs. And, we can choose servers based on the needs of a specific application and can easily experiment to achieve greater cost savings. For example, we were able to decrease our costs for IRIS (one of our Audience Manager applications) by almost 70%.
Ramping up to scale using Spinnaker with Kubernetes
In 2018, the Spinnaker community packaged Spinnaker as container images that could be deployed in Kubernetes. And in 2019, when we heard that a helm chart had also become available, we decided to work towards deploying our microservices to Kubernetes using Spinnaker. Using a single service like Kubernetes would allow us to deploy our applications more efficiently at scale on both AWS and Azure from the same central hub.
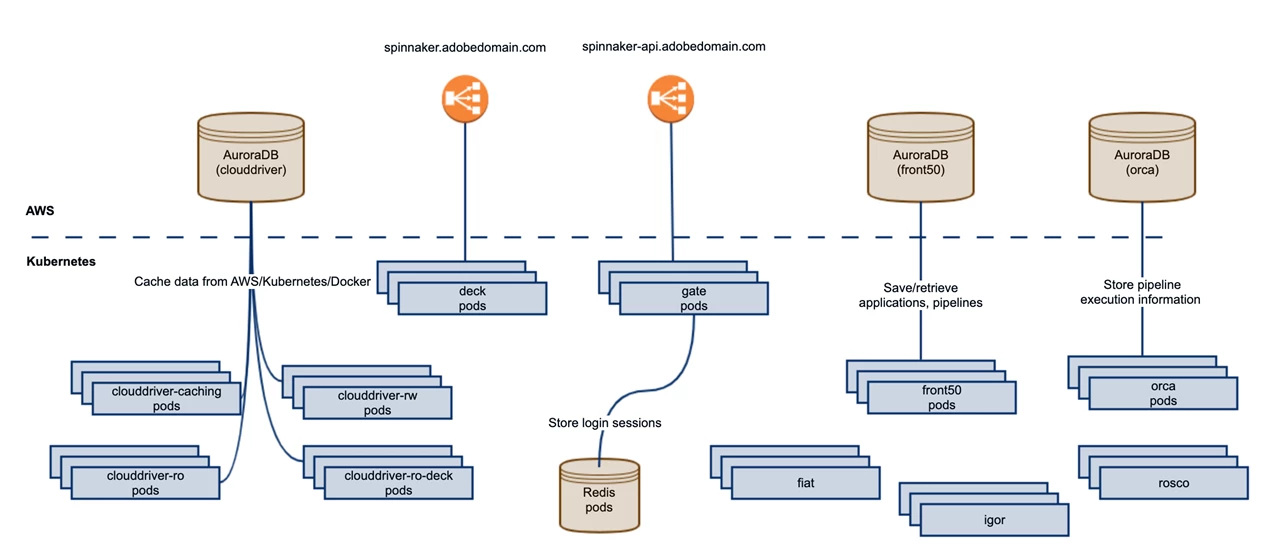
In the past 18 months, Spinnaker has saved us more hours than we can count and provides a more reliable deployment process for our team. And now, with Spinnaker deployed to Kubernetes, we have a highly available setup that allows us to achieve an even greater scale.
News of our success in deploying Spinnaker to Kubernetes has gotten out within Adobe. As a result, several teams throughout the company have asked to hear more about our experiences and many have already begun to use Spinnaker for both AWS EC2 and Kubernetes deployments. Given the widespread interest internally, we decided to share our experiences with Spinnaker and Kubernetes with the developer community at large. In addition, we have also been able to make a number of contributions to the Spinnaker community, including some fixes, such as support for specifying lifecycle hooks for AWS accounts, support for skipping Kubernetes permissions check at startup and support for read/write permissions for each Kubernetes account.
One of the more important results we were able to achieve is a new level of agility in our deployments. Before Spinnaker, we were only able to complete a new deployment on the platform side about every three months. Due to time between deployments, we were also introducing a lot of changes with each one making it very hard to track, and thus solve, any problems that occurred during or after our deployment.
Now we are able to deploy every two weeks to coincide with our feature development. Note that this two-week time frame reflects our development schedule as opposed to any constraints imposed by Spinnaker. With Spinnaker, the time required for our deployments was reduced from six hours to about 20 minutes. And with Kubernetes, a deployment can be accomplished in less than one minute, depending on its complexity and whether it requires release notes beforehand.
We can deploy for staging purposes to some of our most critical applications. For example, we are now using Spinnaker to deploy Adobe's "new" Experience Edge (Project Name: "Konductor") to eight regions across the globe in Kubernetes. Experience Edge is an Adobe Experience Platform initiative that provides a single, optimized gateway for requests that want to interact with other Adobe Experience Cloud edge services, such as Adobe Target, Adobe Audience Manager, and Adobe Analytics.
We can perform these and other deployments as often as needed, even several times in a single day. There's really no limit here. Each time a developer merges his/her code changes, we're automatically deploying to stage via Spinnaker. If there are 10 pull requests, we'll deploy it 10 times, if there's one, we'll deploy it once. So, we can expect to achieve thousands of deployments a day if needed with no hit to performance. We are also able to deploy for each new feature on the application side, which means that our customers don't have to wait as long for new features we've developed for our applications to become available.
In retrospect, we found the default set-up for Spinnaker to be pretty straightforward. One of our biggest challenges was moving Spinnaker to scale in production to ensure it could cope with the complexities inherent in managing multiple AWS accounts and dozens of clusters. This remains a challenge as does finding the time to fully leverage all the features Spinnaker has to offer.
Next steps for Adobe Experience Platform in our journey with Spinnaker
Over the past couple of years, we have expanded our use of Spinnaker to several other internal user bases/teams, including Adobe Audience Manager, Adobe Target, and Adobe Pass with more to come. This wide adoption internally is due to the fact that installing Spinnaker using Kubernetes is quite easy. However, rather than having each team manage its own implementation, we are leveraging our experience by offering Spinnaker as a service. As the core team for Adobe Experience Platform Experience Edge, we are in discussions with our colleagues working on Adobe Experience Platform and on other Adobe teams to encourage them to register their clusters to our Spinnaker implementation to eliminate overhead costs associated with managing their own. Currently, we are working on PoC (proofs of concept) with Adobe Target, Adobe Launch and "Siphon", which provides the data ingestion layer within Adobe Experience Platform to enable customers, solutions, and third parties to onboard Experience Data Model data into the platform's data lake.
Our ability to offer Spinnaker as a service wouldn't be possible without Spinnaker's ability to offer authorization at the account level (an account can represent an AWS account or a Kubernetes cluster). There are also several other features Spinnaker offers that we are now exploring.
Spinnaker is not just a tool for deployment but can also be used to automate tasks. So far, our use of Spinnaker has focused on creating Infrastructure. Currently, we are experimenting with using Spinnaker to automate tasks including:
- Creating and maintaining Kubernetes clusters (i.e. creating a "cluster factory").
- Automating checks for performance and other issues using Spinnaker's ability to provide scoring for different metrics. We are starting small with Spinnaker's Automatic Canary Analysis and having an engineer perform checks to compare with the results produced with automation.
- Chaos engineering with using Spinnaker with Chaos Monkey, which kills random servers from your fleet to identify any issues in your architecture.
We are continuing our work to make Spinnaker more robust and performant at scale as we attract more Adobe teams to our implementation service.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Dec 30, 2019