
Making the Adobe Cloud More Resilient — with Chaos
Author: Nils Meder

The first time most people hear about chaos engineering their instinctive response is "Be careful," "Be safe," "Keep buffers up." But when they say that, they're missing the point. With chaos engineering, we are making our environments stronger and more useful by purposefully trying to destroy them. To ensure a working platform even under the most inconceivable circumstances, you have to move beyond planning for the "known" scenarios.
We began our chaos engineering journey a few years back, starting with small experiments and tools such as Chaos Monkey, used by Netflix, Amazon, and others. With these first smaller experiments, we mostly confined our chaos to a very limited non-production environment. One where you probably already know beforehand what the consequences are. Often we'd even disconnect the system from other services, to mitigate damage. Each of those experiments produced results that were improving the system, and we grew from there. But the recent addition of Chaos "GameDays" was our first big effort.
Why "GameDays"
GameDays are regular two-to-four-hour events, intended to increase the reliability of systems by intentionally injecting failure. The point is to find things that don't work, long before they become an issue. GameDays increase the scope of potential failure by including teams from multiple services all working at once.
Getting started
The ultimate goal of chaos engineering is to execute experiments in live production systems without affecting real users. However, for our first GameDay we decided to keep the chaos to our development environment, so we would not risk being the reason for real customer impact.
The focus for our inaugural Game Day was learning and getting comfortable with GameDay exercises. While introducing chaos in a running system doesn't sound that complicated, even in development systems there is a lot of work to do before starting the experiment. About two months beforehand, we pitched the idea to our head of engineering and one of the ops leaders. We ran them through our schedule, and the idea behind it. They were very supportive, and that made all the difference. The most important element for a successful Chaos GameDay is the team involvement – from the beginning of GameDay planning to the final presentation of results. We like to make GameDays as transparent as possible, working with everyone to get the right people into the team and ensuring management and everyone else are aware of the positive effects of the experiment.
Scoping our first GameDay
Although the term "chaos engineering" assumes uncoordinated failures, it needs thoroughly prepared scenarios. In our experience, a good starting point for getting in touch with chaos testing is small services with clear boundaries. Typical, easy-to-execute scenarios involve tampering with their dependencies, since the effects of those kinds of failure are predictable and often occur during regular service operation.
The Adobe Cloud Platform – supporting the Adobe Creative Cloud, Document Cloud, and Experience Cloud – consists of a multitude of small services, each responsible for a specific domain of the overall platform. Our platform is a globally distributed system, with hundreds of servers, petabytes of storage, and critical network connections. Needless to say, the availability, security, and performance of this platform is critical.
The service we chose for our first GameDay is part of our collaboration system – the feature set that lets users share files, manage access to files and folders, and even publish whole projects. We chose this service because most of the Adobe ecosystem relies on it in some way. Its availability directly affects the availability of upstream services as well, so the potential effects of a failure were uncertain. Since the Adobe Cloud Platform promises 99.99% availability, lower-level services ( such as the one chosen for GameDay ) need to reach an even higher availability and fault-tolerance.
Preparation
While the Game Day itself is a short exercise, we started the planning for our first event about a month before. Our expectation is that the time spent on planning, creating tools, and communication will decrease once GameDays are executed regularly.
After having chosen our target, the main task leading up to the event was to define hypotheses about the behavior of the service during the experiments. We came up with three different scenarios, ranging from slowing down network performance to shutting down system components like the log forwarder. For each of the scenarios, we thought about the mitigations that are in place to ensure the system behaves gracefully and prepared our hypotheses about what will happen once failure is injected.
With our plan handy, it was time to form a team to execute the scenarios and monitor the systems. It was important for us to get people with different views to participate in the event to avoid bias regarding the service and the failure scenarios. After presenting the idea to the Cloud Platform leadership team and during an engineering staff meeting, we found six volunteers from different areas of the platform. Even our head of engineering joined the team. For communication, a dedicated Slack channel was created. The GameDay team, participants, interested engineers, and multiple internal customer teams joined the channel to follow the progress. In our communication to internal clients, we made sure to offer a kill switch for all the proposed scenarios, giving them the opportunity to come in, monitor what we were doing, and at any point stop what was happening if they weren't comfortable. Our message essentially was: This is coordinated chaos, but you can still stop it if you want to. This gave our internal customers the option to easily reach out to the chaos engineers to request an emergency stop at any point if needed.
For failure injection, a collection of scripts was created. These scripts have been used for smaller chaos experiments by service teams before to ensure they would be working properly. Every participant in GameDay was also granted access to the service instances and all monitoring tools.
Execution
We started the Game Day with an introduction to the target service, its architecture, and the chaos tooling. To quickly note all findings and ideas for improvement during the day, we reserved a collaboration-friendly room in our Hamburg office with lots of whiteboard space.
After everyone was prepared with the tools, we started executing the failure scenarios. Each scenario was planned to take one hour, including a short introduction of the scenario and our expectations, a wrap-up of the findings, and the resulting action items. During all scenarios, we generated load with tests that simulate real-world user workflows so we could see if and how our end users would experience issues caused by the chaos.
Scenario 1: CPU stress
During the first experiment we started a process on each service instance consuming a defined percentage of CPU. Our hypothesis that the autoscaling would eventually distribute the load over more instances to keep up with the steadily incoming requests was confirmed. An action item was noted, since the downscaling after the CPU load decreased was too fast, leaving the instance in up- and down-scaling mode when the CPU load was just at the defined scaling metrics.
Scenario 2: Broken logging
Second, a process, which reads stdout and forwards the information to our log aggregator, was stopped on all service instances. Since our application runs with an asynchronous logging framework, the hypothesis was that there is no impact to users and the framework will eventually drop some logging statements. To everyone's surprise, the application started to throw errors immediately after the process was stopped, making the API unusable and collaboration features non-functional for users. Action items were recorded to find the root cause, fix it, and make all other service teams aware of it.
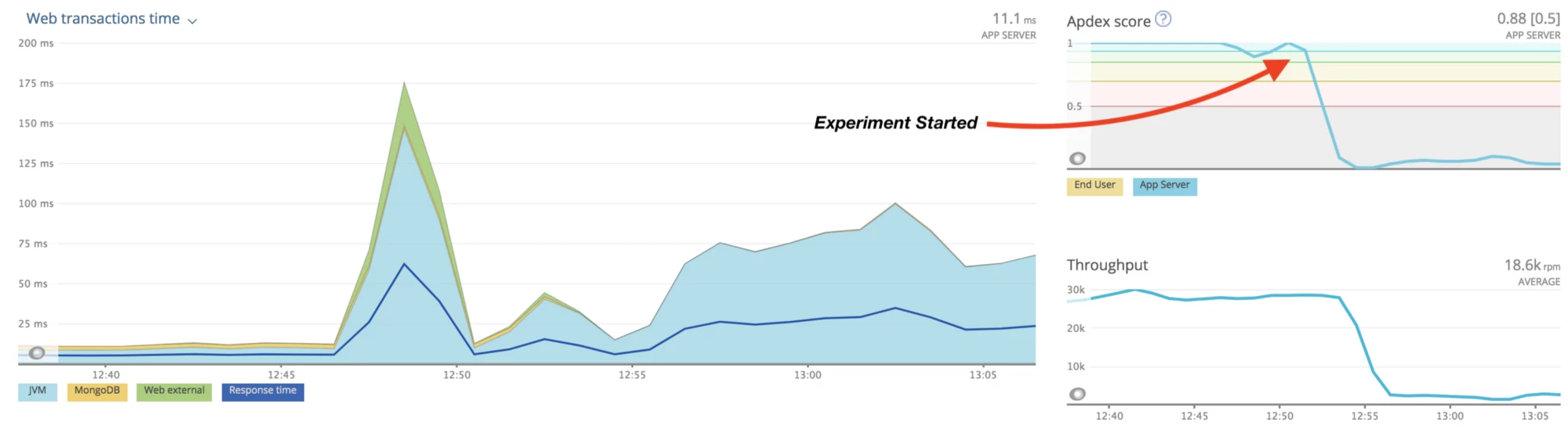
Scenario 3: Slow network to a dependent service (red vs. blue)
While up to this point everyone worked together at one scenario, the last exercise was of a different format. The team was divided into two parts: blue and red. The red team was brought into a separate room, where they started the next experiment. The blue team was left alone, not knowing which failures were introduced into the system. The task for the blue team was to identify the problem just with existing run books, alerts, and monitoring tools and propose a valid solution to the problem. The problem itself–a slow network connection to a downstream service–was identified by the blue team after about 10 minutes. The failure itself didn't cause any unexpected side effects, but we concluded that having an aggregate service dashboard showing all of our monitoring tools would help us locate issues faster.
The last exercise was really fun and was a great contrast following the first two experiments.
Concluding GameDay
Just as important as the exercises itself is the consolidation of results and communication of these. A dedicated time slot during GameDay was reserved to collect all findings from the experiments. Action items were added to Jira, and first pull requests to improve the chaos script collection were opened. A wiki page was used to document the exact process of the experiments. (Tip: Including a timeline and screenshots of our monitoring tools proved very helpful.) Finally, clients were informed that the Cloud Platform would be running without any planned interruption again.
In the days following the experiments, the team in charge of the service began fixing the uncovered issues. The log forwarder issue could be resolved by some simple configuration changes. A short recap and collection of findings were also presented in an engineering staff meeting, spreading the idea and value behind GameDays. We consider the day especially successful because of the effect its had on other service teams – many have already committed to starting their own GameDays and chaos experiments soon based on our work.

What's next?
Our first GameDay was a great experience and delivered significant value to all who work with the Adobe Cloud Platform. For service owners, it provided insight into potential failure scenarios and uncovered configuration issues that could have caused serious problems for customers during times of high load. For participants, the GameDay and tooling serve as a perfect starting point to organize their own GameDays. For the leadership team, regular GameDays provide assurance that we are taking every step to make the whole Cloud Platform more resilient and fault-tolerant, and to minimize the time required to detect and resolve production issues. Most importantly, we hope our creative and business customers benefit greatly from the increased availability and performance of the platform that's at the heart of Adobe's Cloud, powering the tools they use for their everyday work.
For our next GameDay, we plan to expand to include more services and more participants. To shield our paying customers from potential impact, we will likely run the experiment in our test environment again, but increase the chaos – with potentially 20-30 people all working on their own chaos scenarios. From there, we will extend to the whole team. By making this exercise a regular event, the likelihood of catching potential points of failure before they become a bigger risk increases greatly, and that is our goal.
Marvin Hoffman, Till Hohenberger, and Nils Meder started the first Chaos GameDay to Adobe and host a regular chaos engineering meetup near the Adobe office in Hamburg, Germany.
Originally published: Sep 7, 2018