
Using Adobe Experience Platform AI Assistant
I recently gave an internal enablement session on the AI Assistant. It was straight forward and didn’t go into too much depth. Out of it came a lot of asks for any kind of rules or methodology I was following.
My approach is simple; just use it to do my job. As I think of any question, I quickly frame the question and ask the AI. Nothing fancy, not trying to trick it, not doing large verbose prompts or persona, just straight forward Q&A. Break down more complex questions to simpler prompts and then tie these answers together myself for more critical thinking.
Basic prompts:
- Do you know any documentation about Edge API?
- What are segment guardrails?
- What is the difference between rbac and obac?
- Can I do an upsert?
At some point I started taking questions that others were posting in an email to me or more broadly to a group. Then have the AI Assistant answer them as is without changing anything.
Questions people were asking:
- How are profiles qualified into an edge audience
- Does the _id need to be unique within one datasets or all datasets
- How can I subscribe to an alert for a streaming segment
The interesting part is 70% of the time I got an answer without any rewriting of their question. A good amount of time, some rewording was needed. Periodically, I’d run into larger challenges.
By no means did it solve all my questions, but what I discovered was interesting...
Boy, do we ask vague questions!
We have this context in our head that never makes it in our question. We use pronouns that are open to interpretation, like “it”. I never realized it over the years of working in this industry, because most of the time when I’d face these situations, I’d ask a few follow-up questions and get all the detail and context to clarify everything I needed.
I gave a presentation recently on this and it really opened some peoples’ eyes as I showed multiple examples and scenarios where I had felt the AI was wrong in its response yet realized later that my prompt itself was vague.
Here is what I covered in my presentation
Prompts
Be Clear in your prompt
- Vague: show me a list of audiences that were edited recently
- “Recently” can mean different time frames. The AI gave me audiences that were edited in the last 30 days
- Better: show me a list of audiences that were edited in the last 2 days
- Vague: how many profiles have consented for marketing emails
- The AI checked for consent values = y and dy
- Better: how many profiles have consented for marketing emails = y
Provide Context
- Vague: how many people have been to my website recently
- “Recently” again can mean different time frames.
- The AI returned a list of people who had a computed attribute called visited website last 30 days
- I wanted people in an audience
- Better: how many people are part of the audience “recent website visitor”
Be ready to reword a few times
- Prompt: list any audiences that have child audiences
- Gave me the parent audiences, but I wanted the child.
- Reworded Prompt: list any audiences that have a parent audience
- Got the wrong answer.
- Reworded Prompt: list any audiences that have child audiences and the name of the child
- Now I get the parent and child audiences
Be aware some words have multiple meanings or similar names (goes hand in hand with provide context)
- Vague Prompt: What is a tag?
- Gave me an answer about labeling objects in Adobe Experience Platform.
- But I thought tags were things that collected data???
- Better: What is a tag in data collection?
- By providing the data collection context, it switches and now I get better info
- Misunderstood Prompt: what attributes are in +[audience]
- My Audience is named Platinum or Gold Loyalty
- The AI split the OR thinking I was talking about two different audiences
- WHERE (LOWER(S.NAME) LIKE LOWER('%platinum%loyalty%') OR LOWER(S.NAME) LIKE LOWER('%gold%loyalty%'))
- Better: what attributes are in "+[audience]"
- By adding quotes around it, I was able to bring it back together
- WHERE LOWER(S.NAME) LIKE LOWER('%platinum%or%gold%loyalty%')
- Best: We are working on this one…
- Have the AI do an = rather than all the LIKE and wildcards so we don’t include similar named objects
- By adding quotes around it, I was able to bring it back together
Understand the answer
Read through the answer, many times it sounds right, but may not be. What we are asking the AI to do is read through all kinds of docs or internal objects in the sandbox and give us an answer. But it doesn’t mean we check out and don’t think. If it is telling us it can’t save an RTCDP audience because the tag on the website doesn’t have the right data element in the Journey, alarm bells should be going off everywhere. (I made that up, it never said that to me).
Read the steps – do they make sense
Validate the Sources – go to the links and skim through them. Open the SQL to check it isn’t doing something out of left field
Provide Feedback
Make sure you give a thumbs up/down. Otherwise the AI might assume it gave you the right answer. Say why, give some feedback, it takes only a minute including typing a sentence or two. Let’s all help it get better.
Get your job done, but push the boundaries
Given all that. The best thing I’ve done is to start pushing the boundaries.
This is both the most fun and frustrating part. Here I get excited because I know I’m about to cross over the line where I’m at the edge of its scope/capabilities. Here I start to think… I wonder… Which is where we get to try new things. I like to expand and explore. My mind starts to ask questions I never would have before since it might take too long to get the answer otherwise… or I’ve headed down a path that got me curious about a topic.
I know I’ll run into a wall at some point, but it’s worth it since I might discover something new.
I’ll leave you with one train of thought I did on one of these explorations. It shapes now how I think about my prompts.
Note: since I’m pushing the edge a little when I do this, I end up having to sometimes:
- Tell the AI “Ask Anyway”
- Start a new Conversation
- Reword a few more times than normal
- Get the syllabus out
- State the obvious
Use Case: Lately there seems to be a lot of data going into profile. Which datasets contribute the most?
Prompt: list the top 20 datasets, their size, if enabled for profile, and when created, sorted by created ascending
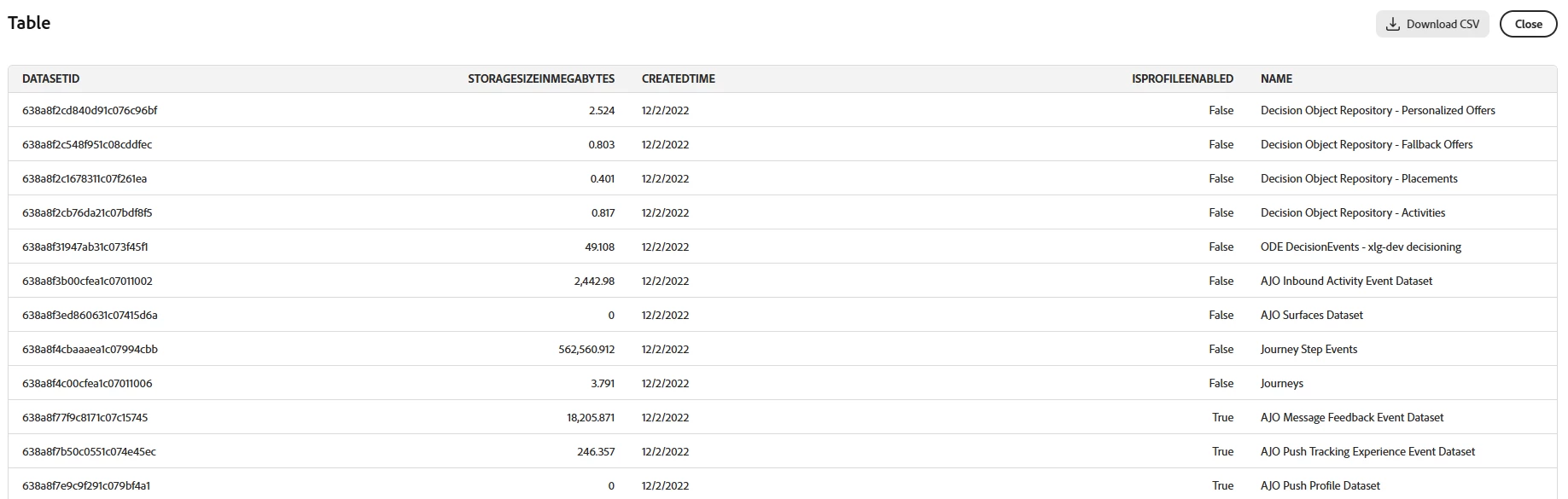
Too many system datasets.
Prompt: list the top 20 datasets, their size, if enabled for profile, and when created, sorted by created ascending. Exclude system datasets
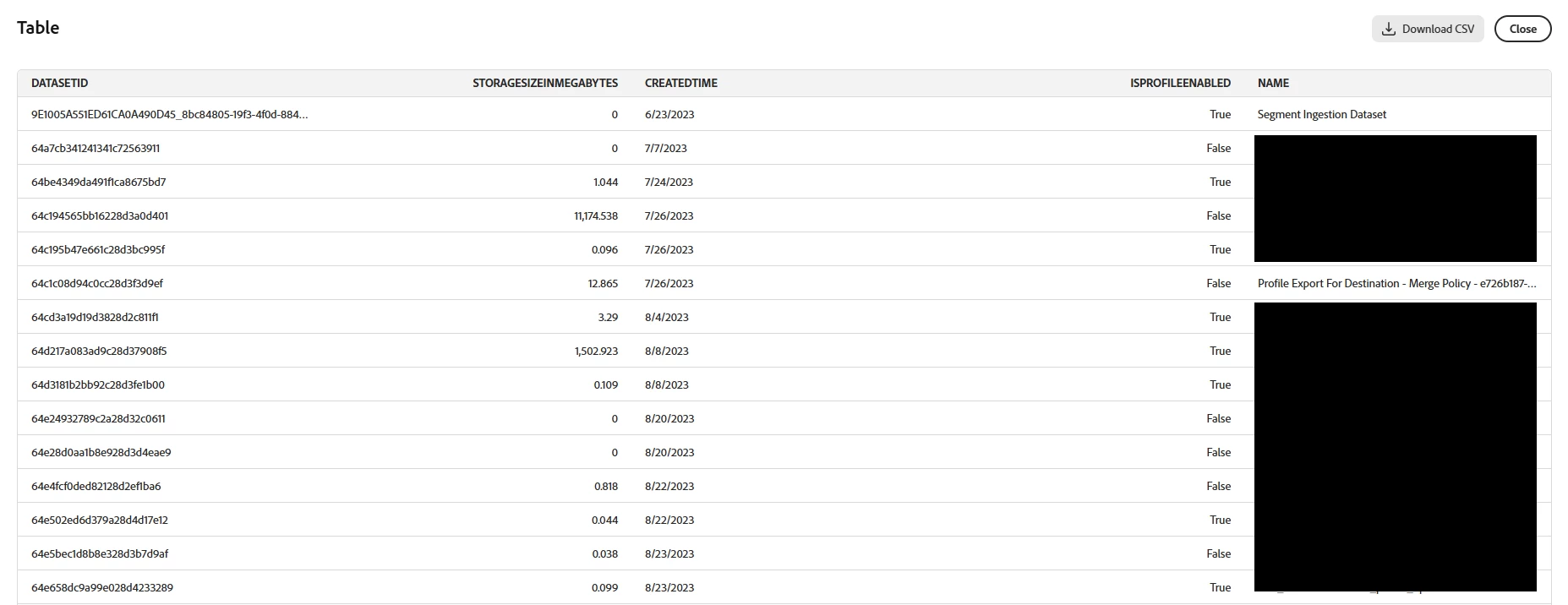
I only want profile enabled.
Prompt: list the top 20 datasets enabled for profile, their size, if enabled for profile, and when created, sorted by created ascending. Exclude system datasets
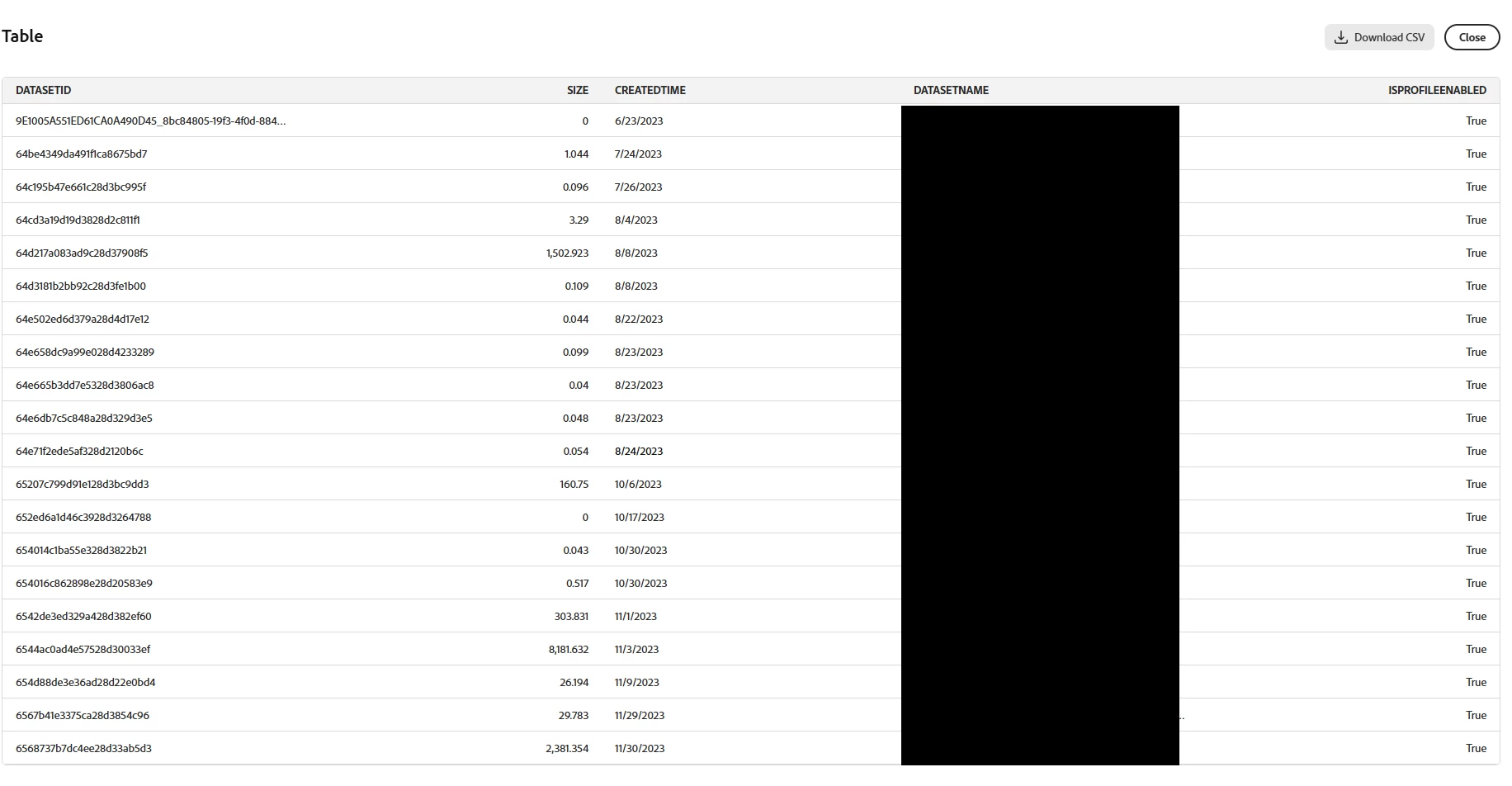
Now sort by size.
Prompt: list the datasets enabled for profile, their size, if enabled for profile, and when created, sorted by size. Exclude system datasets
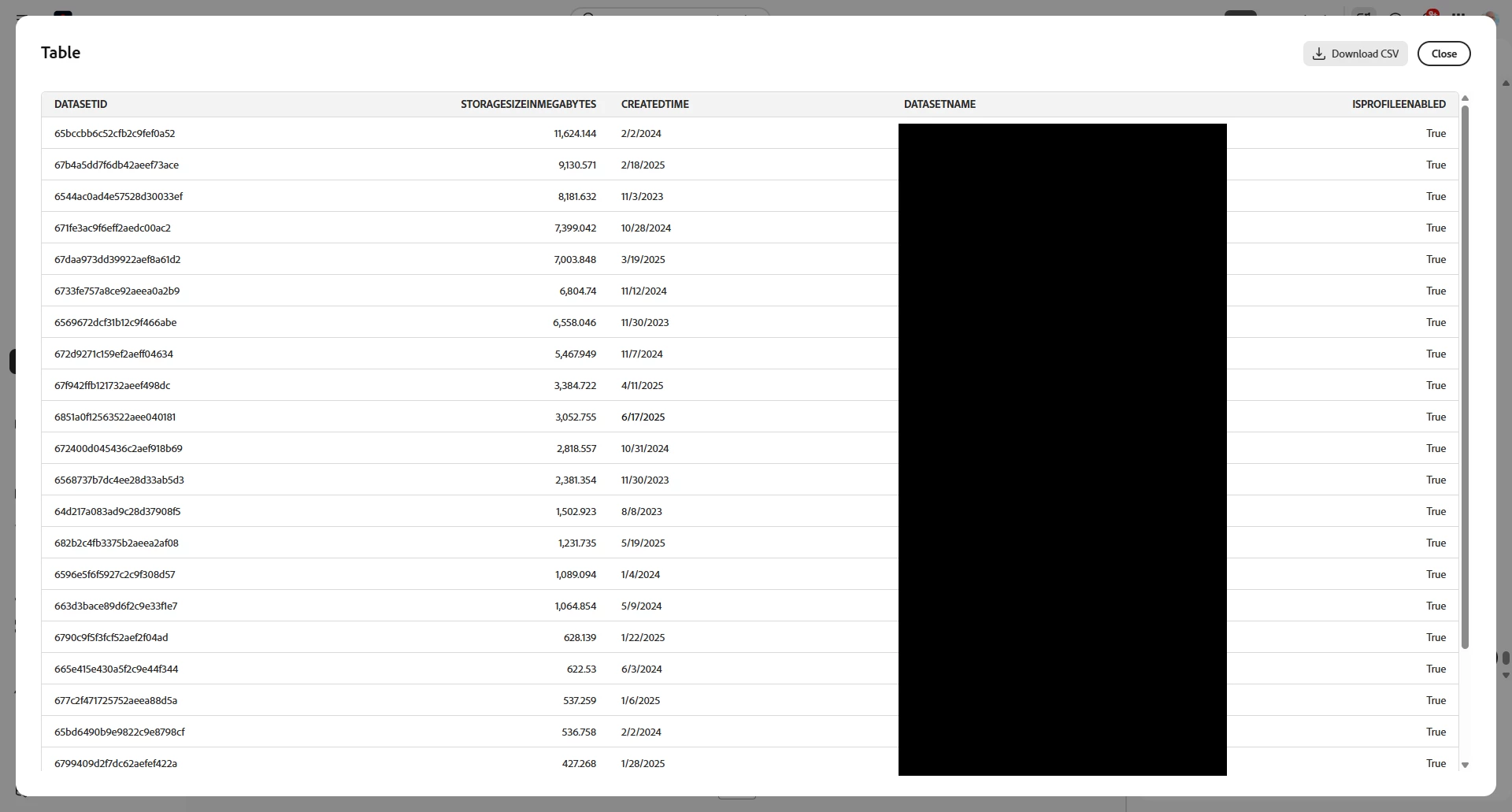
Now I’ve got a list of the datasets that contribute the most to profile. I need to dig into some of these that are large. But where is this data coming from?
Prompt: list the datasets enabled for profile, their size, if enabled for profile, and when created, sorted by size descending. Exclude system datasets. Add to the list the dataflow
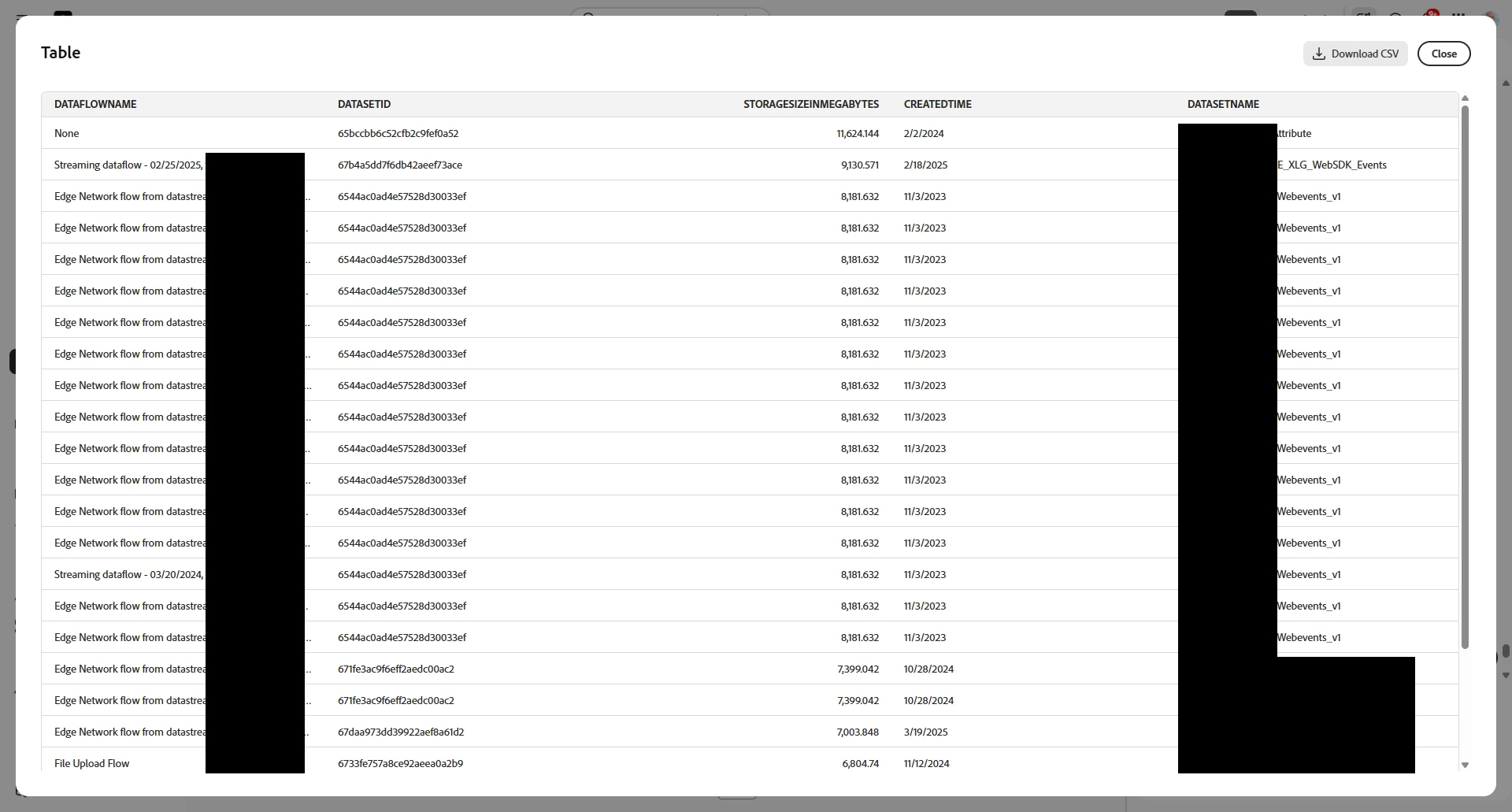
Wow, I have a lot coming into my WebEvents. Need to check that out.
I wonder what else I could do?
Use Case: Learning and Exploring what AI Assistant knows about AJO Journeys
Prompts:
list all journeys
list all journeys and their journey type
list all journeys, the journey type and audience they use
list all journeys, the journey type, the audience they use where the journey type starts with audience
list all journeys, the journey type, the audience they use, the sum of entry count, the sum of completed count and sum of failed count where the journey type starts with audience
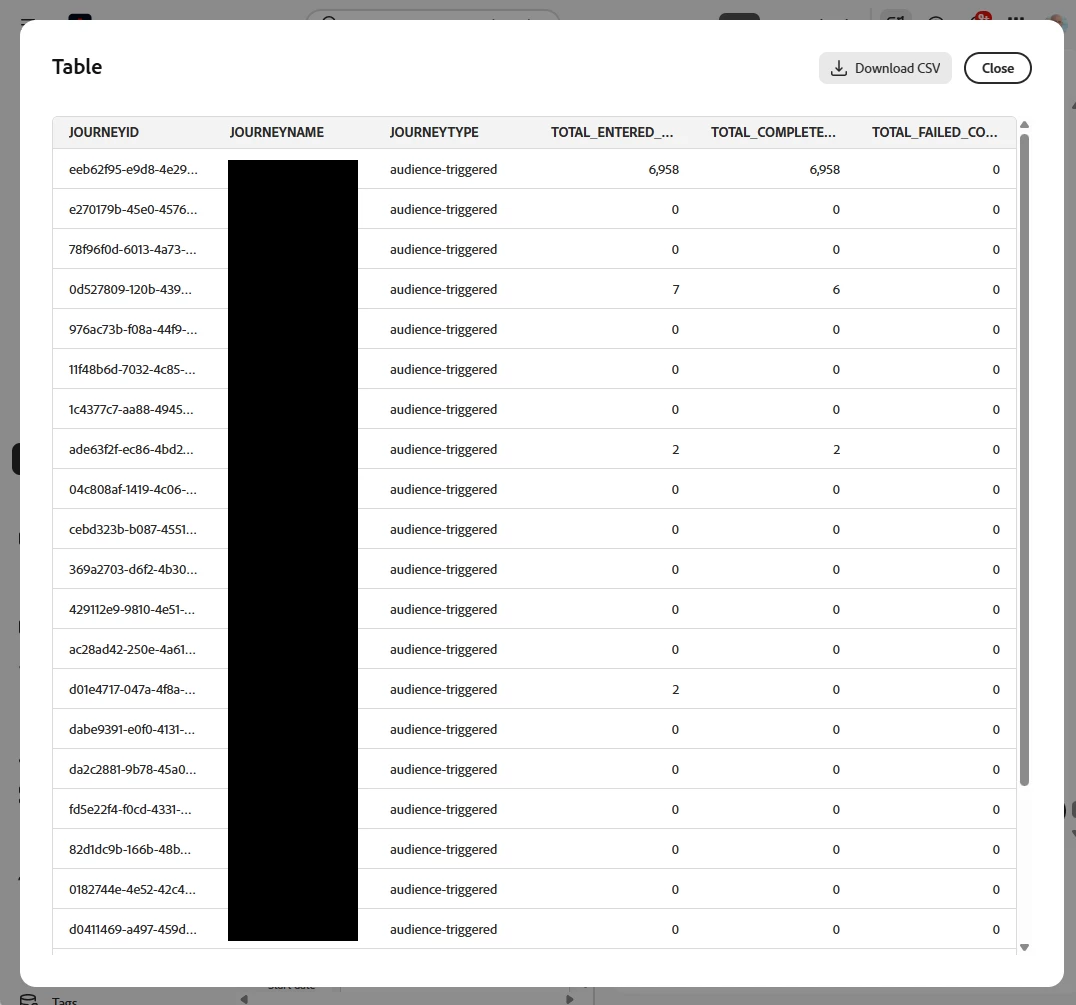
… that should get your juices flowing
Now it’s your turn… what do you wonder the AI Assistant can do? Got something interesting. Post it.