
Understanding Field-Based Stitching and Graph-Based Person Stitching in Adobe Customer Journey Analytics
Introduction
In today’s multi-device, multi-channel landscape, customers often engage with brands across multiple platforms and touchpoints on their path to conversion. A customer might discover your product on their mobile device during their morning commute, research it on their work computer during lunch, and finally make the purchase on their tablet at home. Without person stitching, these would appear as three separate customers in your analytics, leading to fragmented insights and missed opportunities.
Organizations increasingly need to effectively combine customer data from multiple touchpoints to gain meaningful analytics insights. This is crucial for Customer Journey Analytics (CJA), which uses a single declared field identifier per dataset to maintain consistent person identity. To meet these data integration needs, CJA for person-based stitching offers two distinct approaches: Field-based Stitching (FBS) and Graph-based Stitching (GBS). These stitching methods help maintain consistent customer identity across touchpoints.
What is Person Stitching?
Stitching is a process that unifies different events of a person's activity within a single dataset into one cohesive customer journey. Unlike the cross-dataset unioning capabilities in CJA, person-based stitching focuses on reconciling different identifiers for the same person within a single dataset to reveal the complete totality of their experience.
Without person stitching, your analytics might show:
- Anonymous visitor views product page
- Different anonymous visitor adds to cart
- Yet another visitor completes purchase
With proper person stitching, you see the complete journey:
- Customer discovers product → researches options → makes purchase decision
This unified view gives organizations powerful capabilities across multiple aspects in CJA. It allows for more precise attribution modeling to reveal the true impact of owned and earned marketing touchpoints, enables richer personalization by considering the customer’s full context, and unlocks deeper insights into behavior patterns and preferences. With this broadened understanding, organizations can make smarter decisions about customer engagement strategies and optimize their marketing investments for stronger results.
Field-based vs. Graph-based Person Stitching Approaches
CJA offers two distinct approaches to person stitching, each with its own methodology and specific use cases. Understanding the technical underpinnings of these methods is crucial for implementing the right solution for your organization's needs. The fundamental difference between these approaches lies in how they connect customer identities. Field-based Stitching relies on direct ID relationships within a single dataset, while Graph-based Stitching leverages an identity graph structure enriched from relationships found in first-party data and through deterministic algorithms.
Field-based stitching involves two important identity concepts: Persistent IDs and Transient Person IDs. The Persistent ID is a stable identifier that remains consistent across sessions (like a cookie ID or device ID), providing continuity even when users aren't authenticated. The Transient Person ID is a higher-value identifier (like a customer ID, email address, or loyalty number) that appears intermittently when users authenticate or identify themselves.
To better understand the key distinctions and capabilities of these two approaches, let's examine them side-by-side in a comparison matrix:
| Feature | Field-based Stitching | Graph-based Stitching |
|---|---|---|
| Source of Identities | Direct field matching within a single dataset | Adobe Unified Identity Service |
| Identity Types | Persistent and transient Person IDs within single dataset | Multiple ID types across devices and channels |
| Capabilities | Limited to defined field relationships within a single dataset. FBS uses time-based sessionization, which means it groups events from the same user into sessions based on activity within defined time windows (e.g., 30 minutes of inactivity signals a new session). Because FBS is session-based, a single device/identity may contribute to multiple sessions, possibly spanning different people or behavioral contexts over time. | Advanced graph-based relationship establishments. GBS does not utilize time-based sessionization. Instead, it focuses on establishing durable identity links across devices and events. The system continuously maintains a graph of identifiers, but does not split user activity into individual sessions based on time. In the current GBS model, a particular device can be attributed to only one person at a given time. This means, for identity resolution and downstream processing, a device won’t be split across multiple users within the attribution window as there’s a unique mapping per device at any moment. |
| Processing Method | Field-based continuous upon collection and set lookback window-based replay stitching. | Graph-based continuous upon collection and set lookback window-based replay stitching. |
| Use Case Suitability | Direct identity resolution scenarios requiring precise time attribution or handling of shared devices | Complex identity resolution scenarios |
| CJA Product Description | Field-based stitching (FBS) has tiered availability: •Foundation: FBS is not included. •Select: FBS provides a 13-month one-time backfill capability with two lookback window in days/replay window frequency options (1/1 or 7/7 days) and supports up to 5 stitched datasets. •Prime: FBS provides a 13-month one-time backfill capability and expands lookback window in days/replay window frequency to three options (1/1, 7/7, or 14/7 days), and supports up to 15 stitched datasets. •Ultimate: FBS offers the most comprehensive coverage with a 25-month one-time backfill, all lookback window in days/replay window frequency options (1/1, 7/7, 14/7, or 30/7 days), and supports up to 50 stitched datasets. Understanding Replay Window Frequencies: The replay window frequency is expressed as X/Y days, where X represents the lookback period in days and Y indicates how often in days the replay refreshes data: •1/1: Looks back 1 day and refreshes daily, ideal for maintaining recent data accuracy. •7/7: Examines 7 days of historical data and refreshes weekly, balancing recency with processing efficiency. •14/7: Reviews 14 days of data with weekly refreshes, providing deeper historical context with moderate refresh frequency. •30/7: Analyzes a full month of data with weekly refreshes, offering the most comprehensive historical view. Note that while organizations can implement different replay options across datasets, once configured, these settings are fixed at the individual dataset level. |
Graph-based stitching (GBS) has tiered availability: •Foundation: GBS is not included. •Select: GBS is not included. •Prime: GBS provides a 13-month one-time backfill capability with three lookback window in days/replay window frequency options (1/1, 7/7, or 14/7 days) and supports up to 15 stitched datasets. •Ultimate: GBS offers the most comprehensive coverage with a 25-month one-time backfill, all lookback window in days/replay window frequency options (1/1, 7/7, 14/7, or 30/7 days), and supports up to 50 stitched datasets. Understanding Replay Window Frequencies: The replay window frequency is expressed as X/Y days, where X represents the lookback period in days and Y indicates how often in days the replay refreshes data: •1/1: Looks back 1 day and refreshes daily, ideal for maintaining recent data accuracy. •7/7: Examines 7 days of historical data and refreshes weekly, balancing recency with processing efficiency. •14/7: Reviews 14 days of data with weekly refreshes, providing deeper historical context with moderate refresh frequency. •30/7: Analyzes a full month of data with weekly refreshes, offering the most comprehensive historical view. You can enable a mix of replay options in a given organization, but they are fixed on a per-dataset level. |
Field-based Stitching: The Direct Approach
Field-based Stitching (FBS) operates on individual event datasets, analyzing and connecting data across both authenticated and unauthenticated user states. FBS systematically rekeys identities within dataset rows by examining key fields to generate a unified, stitched ID for each event. A stitched ID in CJA is a unique identifier field that holds either the elevated identity (like login credentials) or the lower identity (like cookie or device IDs) to maintain a single, consistent identifier that represents the same customer across different interactions and sessions.
How Field-based Stitching Works
- Data Ingestion: Events enter AEP with lower persistent IDs (like cookie IDs) and as available elevated transient Person IDs (such as login or CRM IDs)
- Field Analysis and New Column Creation: The system analyzes specified identity fields within each event and creates a completely new column called "Stitched ID" built by the internal stitching processes. This is not an update to an existing field but rather a new field added to a new dataset specifically for identity stitching purposes.
- Deterministic Matching: The system identifies when the same persistent ID has been associated with a transient ID in the past. It then applies that transient Person ID to other events with the same persistent ID, even when the user was not authenticated during those events.
- Value Assignment Logic: In this new "Stitched ID" column, the system populates each row with either:
• The Transient Person ID (like customer ID) when available in that event
• The Persistent ID (like cookie ID) as a fallback when no Transient ID is present
- Continuous Dataset Updates: Both live stitching (as new data arrives) and replay stitching (reprocessing historical data at scheduled intervals) continuously update the values in this new "Stitched ID" column to maintain accuracy as more identity relationships are discovered.
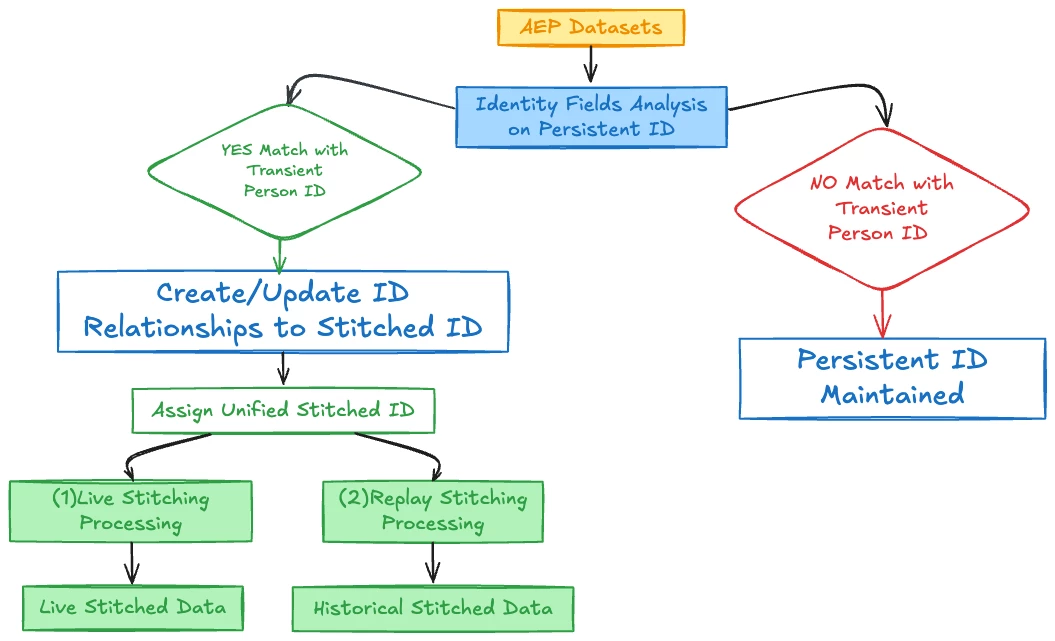
Key Considerations for Field-based Person Stitching
- Schema Requirements: Requires both lower persistent ID and elevated transient Person ID columns to be defined as identity fields in the schema. Currently, FBS is only available for XDM Experience Events datasets.
- Identity Availability Dependency: Transient Person ID must appear at least once for each persistent ID for stitching to occur
- Dataset Compatibility: Works best when datasets share similar common identifiers
- Scenario Fit: Better suited for simpler identity resolution scenarios with clear field relationships. With shared devices, FBS cannot connect user actions across devices in shared environments. In scenarios where individuals use multiple shared devices, each device's activities remain isolated.
- Fixing Data Issues: FBS doesn't combine identities from outside the dataset as no external graphs are used. The FBS identity mapping can be regenerated (replayed) whenever source data is fixed. The output stitched dataset is simply a copy of the source with a new stitched ID column.
- Privacy & Consent: Only enable datasets for stitching that should be linked and do not mix records lacking proper consent. Consider tracking consented IDs separately by populating a dedicated identifier column only when consent is present. Once a dataset is provisioned for FBS, the process is non-reversible; changes require creating a new stitched dataset.
When to Choose Field-based Person Stitching
Field-based Stitching is ideal when you have well-defined identity fields across your datasets, with a Persistent ID on every row and a Transient ID present in at least some rows. Since FBS is session-based, a single device/identity may contribute to multiple sessions, potentially spanning different users or behavioral contexts over time.
Graph-based Stitching: The Network Approach
Graph-based Stitching (GBS) leverages Adobe's identity graph within the Adobe Experience Platform Identity Service to provide identity resolution. Using algorithms, it creates identity graphs that link various identifiers (like mobile IDs, cookie IDs, CRM IDs) to a single person identifier within a given dataset.
How Graph-based Stitching Works
- Graph Construction: The identity graph in Adobe Experience Platform is built from multiple data sources through specific configurations. To contribute to the identity graph, both the schema and dataset must be properly enabled. The schema must first be enabled for Real-Time Customer Profile, making datasets created from it eligible for Profile and Identity Service. Then, the dataset itself needs enablement through two flags:
unifiedProfilefor Profile ingestion andunifiedIdentityfor identity graph participation.When events are processed, identities seen together (such as when a user logs in on a new device) create connections in the graph. While the UI automatically enables both Profile and Identity Service together, API users can enable only Identity Service for graph hydration without populating Profile. This flexibility allows for identity stitching without profile construction. Over time, isolated clusters of identifiers merge into a single "person" node, connecting previously separate identity fragments. For customers already using RTCDP, these identity relationships extend to datasets stitched in CJA through GBS.
- Dataset Update Process: Similar to Field-based Stitching, Graph-based Stitching creates a completely new column called "Stitched ID" in your dataset. This is not an update to any existing field but rather an additional field specifically created for identity resolution. The system populates this new column with a consistent person identifier derived from the identity graph, enabling seamless tracking across devices and sessions.
- Cross-Linking: Using the relationships established in the identity graph, the system connects activities across different devices, channels, and platforms by applying the appropriate person identifier to each event row in the new "Stitched ID" column.
- Continuous Learning: The graph evolves and improves accuracy over time with more data, which means the values in the "Stitched ID" column are continuously refined through both live stitching and replay processes to maintain the most accurate identity relationships.
- Continuous Dataset Updates: Graph-based Stitching results in a transformed dataset that contains a new "Stitched ID" column. This new column adds a consistent person identifier across all events, enabling more accurate cross-device analysis. The transformation occurs through both live stitching (as new data arrives) and replay stitching (reprocessing historical data at scheduled intervals). The process maintains the original dataset structure while adding this critical identity resolution field for more comprehensive customer journey analysis.
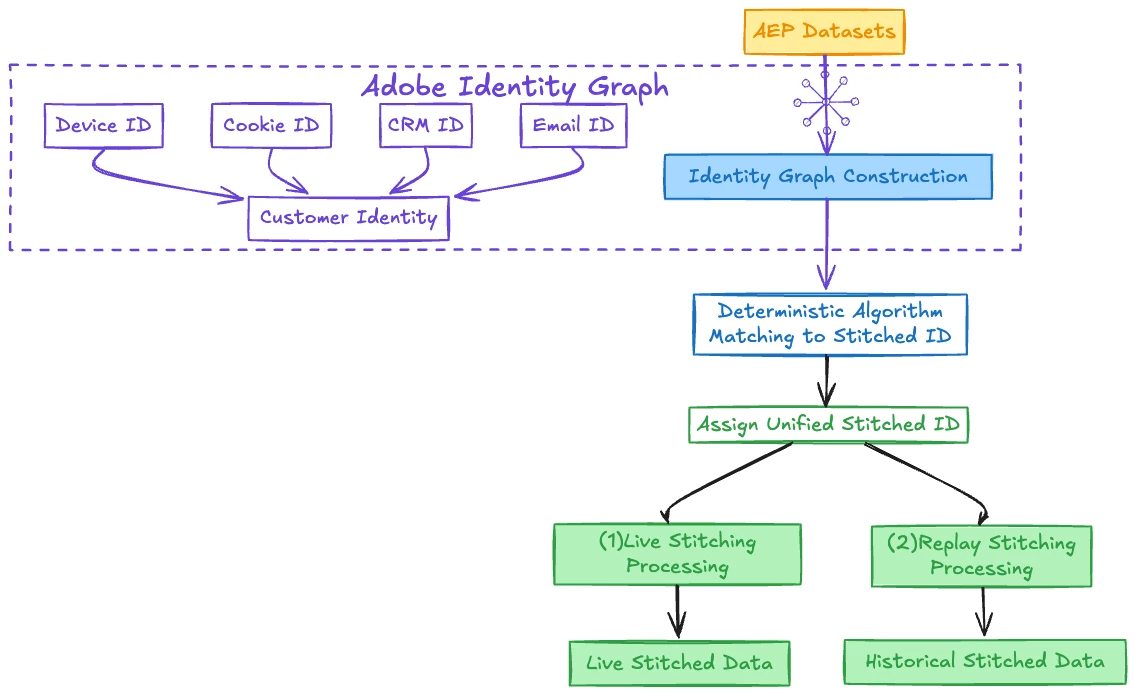
Key Considerations for Graph-based Person Stitching
- Schema Requirements: The schema must specify which field serves as the person identifier and its corresponding identity namespace. This namespace is used to query the Experience Platform Identity Graph. Currently, GBS is only available for XDM Experience Events datasets.
- Identity Service: Utilizes Adobe's proprietary identity graph technology for enhanced identity resolution
- Sophisticated Matching: Provides more comprehensive cross-device and cross-channel identity matching. GBS can link behaviors across shared devices when associations exist in the identity graph, while FBS cannot.
- Complex Journey Handling: Better manages complex customer journeys with multiple touchpoints
- Anonymous-to-Known Transitions: Offers more accurate identity resolution for anonymous to known user transitions
- Platform Integration: Requires instantiation of the Adobe Experience Platform Identity Graph for utilization. Applies consistent "person" view across all Adobe Platform-based applications as the same graph is used by RTCDP (Adobe Real-Time Customer Data Platform) and AJO (Adobe Journey Optimizer)
- Fixing Data Issues: GBS can impact multiple datasets if the same bad ID appears across input data ingested into the graph. If a dataset includes incorrect IDs (e.g., hardcoded ECIDs), these may contaminate the global graph when ingested into the Identity Graph. Cleaning up the data may require support and backend engineering intervention to repair the graph.
- Privacy & Consent: Can link identities even without direct matches present, but only for identities that exist in the Identity Graph and have proper consent. Utilize the latest AEP settings to ensure only appropriate records are stitched together by configuring participation in the Identity Service and applying suitable usage labels.
When to Choose Graph-based Person Stitching
Graph-based Stitching excels when you have datasets with a persistent ID on every row that don't share the same common ID as other datasets you want to connect in CJA, yet the Identity Graph contains the mapping of that persistent ID to your desired common ID. It provides consistency across Adobe products as the same identity graph is used by RTCDP and AJO, ensuring a unified customer view throughout your Adobe Experience Platform ecosystem. In the current GBS model, a particular device can be attributed to only one person at a given time. This means for identity resolution and downstream processing, a device won't be split across multiple users within the attribution window, as there's a unique mapping per device at any moment.
Understanding the Person Stitching Process: Live vs. Replay
Both stitching methods employ a dual-processing approach that balances insight delivery with comprehensive data accuracy. The diagrams show how Field-based and Graph-based stitching process data through two parallel paths: live stitching and lookback window replay. Live stitching processes data as it arrives, while replay handles historical data at scheduled intervals.
While both methods utilize these dual processing paths, they differ fundamentally in their matching approach: GBS leverages Adobe's Identity Graph as the primary source of truth for identity resolution, while FBS considers the customer's own dataset as the primary source of truth. In FBS, authenticated events (those with a non-null transient Person ID) have their transient Person ID value forwarded directly to the Stitched ID column, whereas GBS always consults the Identity Graph regardless of authentication status. Beyond these key differences in truth sources, all flows (live, replay, unstitching) function identically between the two methods.
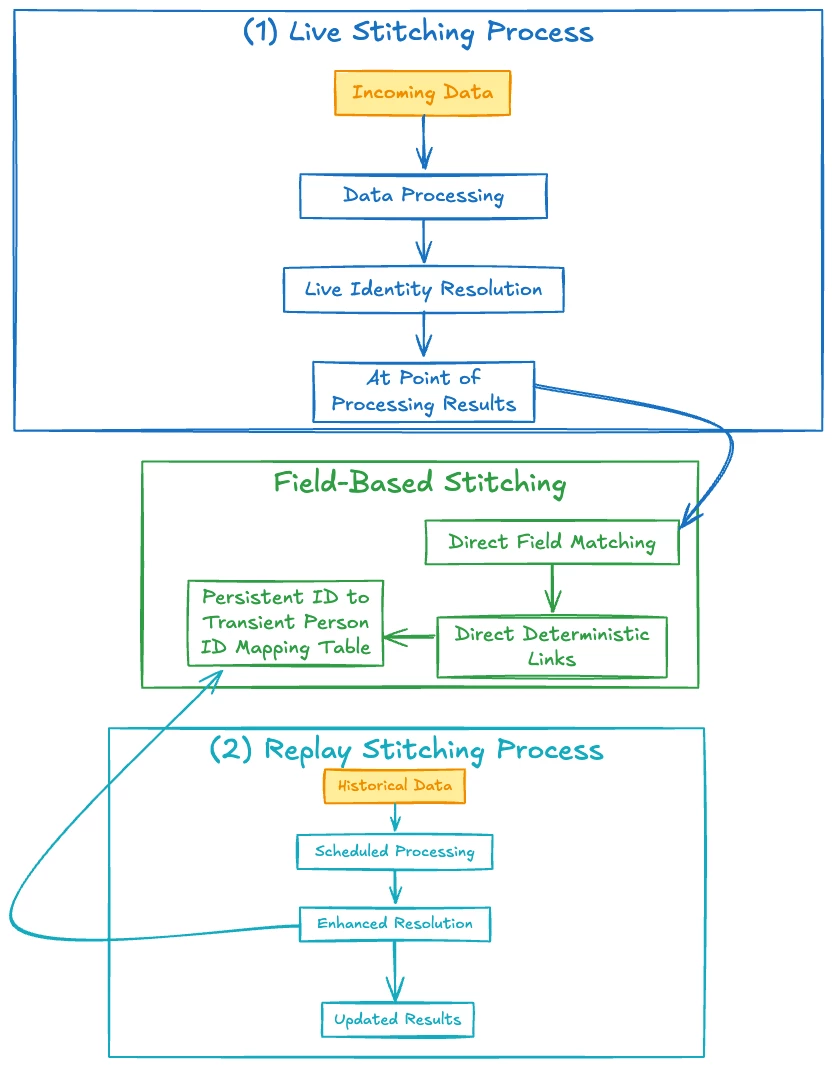
Field-based Person Stitching Live & Replay
Field-based stitching uses direct deterministic map on events for which only a device-level identifier (Persistent ID) was available to a higher-fidelity person-level identifier (Transient Person ID), once it's observed. The basic steps are:
- Live Stitching: As new data comes in, every event is checked.
- If a Transient Person ID is available on the event, a mapping is written: (Persistent ID, Transient Person ID, Timestamp)
- If only the Persistent ID is present, events are joined with the mappings based on the Persistent ID, using any existing mappings to stitch the events. For FBS specifically, a Transient Person ID set directly on the event always takes precedence over any mappings (meaning authenticated events will have their Transient Person ID forwarded to the stitched ID column).
- Replay Stitching: A scheduled process that retroactively updates Stitched IDs for events where later data revealed an association with a Transient Person ID. Replay uses only the stitched dataset for restitching data; it does not need to interact with the the original source data.
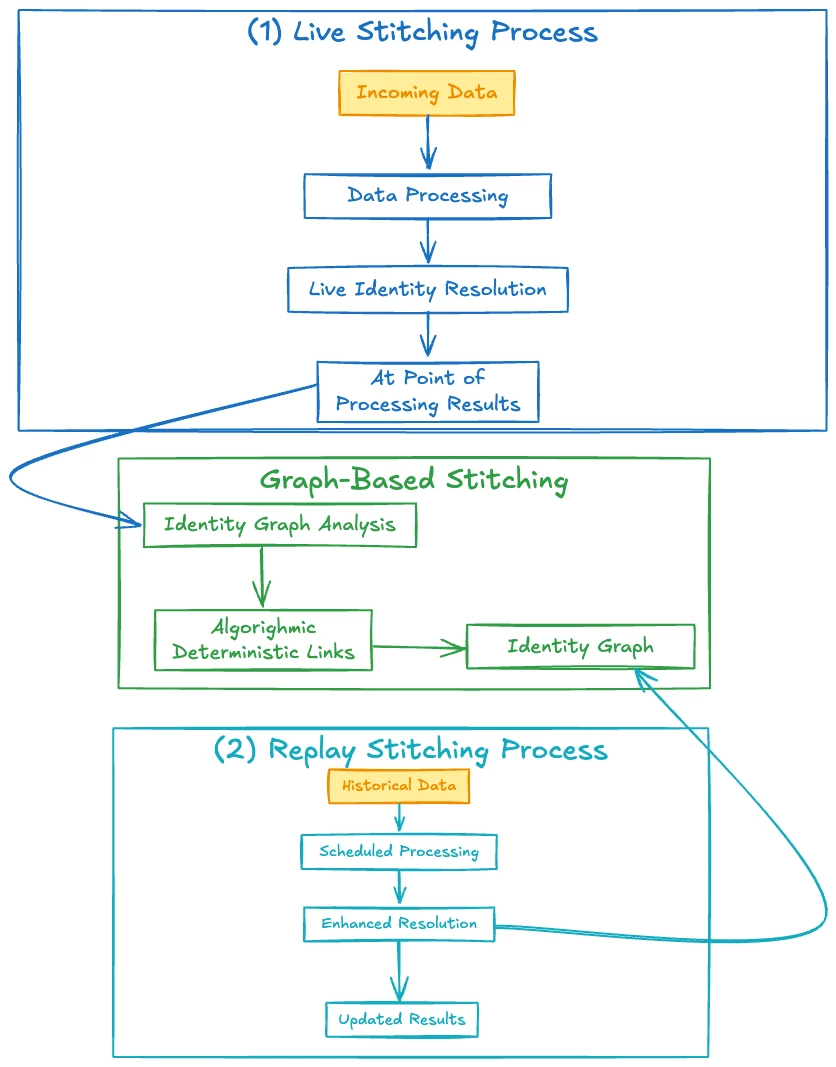
Graph-based Person Stitching Live & Replay
At its core, Graph-based Stitching maps device-level identifiers (like Persistent IDs) to higher-fidelity person-level identifiers (such as email, CRM ID, or another person identifier) by leveraging the Experience Platform Identity Graph, rather than only associations observed within the specific dataset.
- Live Stitching:
- As each event is ingested, the persistent identifier for that row is looked up against the Identity Graph.
- If a reference is found then the system populates the Stitched ID for that row using the selected person identifier from the graph.
- If no reference is found then the row is temporarily stitched with its existing persistent ID (or left unstitched), awaiting further updates via the Graph.
- Replay Stitching:
- Scheduled Replays: At periodic intervals events within the lookback window are re-processed (not using any new replay process unique to GBS, but the same replay approach as with FBS).
- New Graph Mappings: Any updates in the Identity Graph (e.g., a persistent ID was linked to a Transient Person ID after original events were ingested) are retroactively applied so that events can be re-keyed to the correct (possibly newly-discovered) person-level identifier.
- Replay thus ensures that all events benefit from the latest identity graph knowledge, allowing device-based activity to be merged under the correct person as identities are learned.
Optimizing Person Stitching Performance
The lookback window and replay frequency are critical parameters that significantly impact stitching effectiveness:
Lookback Window Considerations:
- A longer lookback window (e.g., 7 days) provides more context for identity stitching as it captures delayed user logins and cross-session activities. This improves accuracy for complex customer journeys.
- The lookback window requires careful consideration regarding data settling, which refers to the time needed for data to completely process, stabilize, and become available in CJA. While longer lookback windows help capture additional identity relationships, they can potentially introduce delays for final results as CJA waits for complete data settlement.
Replay Frequency Impact:
- More frequent replays (daily vs. weekly) result in fresher stitched data, ensuring that your analytics reflect the most current identity relationships and provide more timely insights for decision-making.
- More frequent replays enable faster correction of identity resolution decisions, resulting in more accurate customer journey analysis as identity gaps are resolved more quickly, which leads to improved reporting accuracy.
Implementation Considerations and Best Practices
Data Preparation
Regardless of your chosen stitching method, proper data preparation is crucial:
- Identity Field Mapping: Clearly define persistent and transient Person ID fields in your schema and mark them as Identity Namespaces
- Data Quality: Ensure consistent formatting and minimize missing values
- Field Standardization: Maintain consistent naming conventions across datasets
- Shared Devices Considerations: Account for shared devices in your stitching strategy and use Query Service to analyze shared device exposure in your data.
- Persistent ID Selection: Choose persistent identifiers with a very high coverage rate to ensure comprehensive identity resolution
Monitoring and Maintenance
Successful stitching implementations require ongoing attention:
- Data Completeness: Ensure all relevant identity fields are captured
- Stitching Rate Monitoring: Track the proportion of authenticated versus unauthenticated events and measure the stitched authentication rate using validation techniques
Making the Right Choice: Person Stitching Decision Framework
Selecting between Field-based Stitching and Graph-based Stitching requires careful evaluation of multiple factors:
Assess Your Current State
- Data Architecture: Evaluate your existing identity management infrastructure, including how identifiers are currently collected, stored, and linked across your various systems, platforms, and touchpoints. Assess whether your current infrastructure can support the identity resolution requirements of either stitching method, and identify any gaps that might need to be addressed before implementation.
- Data Quality: Thoroughly evaluate the completeness and consistency of your identity fields, ensuring no placeholder or static values are ever used for identification. Never use default values like "unknown," "anonymous," or "00000" as identifiers, as these will incorrectly link unrelated users together. Avoid hardcoded ECIDs (Experience Cloud IDs) such as "12345" for testing purposes, as these can contaminate your identity graph. Also, be vigilant about system-generated defaults like "not available" or "undefined" that appear when actual IDs are missing as these should be filtered out before implementing identity stitching.
Define Your Requirements
- Customer Journey Complexity: Assess whether your customer interactions follow simple linear paths with few touchpoints or involve complex, multi-touchpoint journeys across various stages of engagement. Consider the depth and breadth of your customer journeys, including the number of interactions before conversion, the variety of entry points, and the typical path from initial awareness to conversion. Additionally, evaluate whether you need time-based sessionization to properly analyze these journeys, as this may influence your stitching method selection.
- Cross-Device & Channel Needs: Evaluate the diversity and frequency of device, platform, and channel usage in your customer interactions. Consider how often customers switch between mobile, desktop, tablet, in-store, call centers, and other touchpoints. Determine whether your analytics need to track seamless journeys across these varied interaction points or if your customers typically complete their journeys within a single device or channel.
- Freshness Needs: Assess the tradeoff between data timeliness and identity resolution completeness. While waiting for full data settlement provides more comprehensive identity resolution, it also introduces delays in finalized reporting.
- Regulatory Compliance: Evaluate your organization's privacy obligations, consent management processes, and regulatory requirements across all markets where you operate. Consider how identity resolution methods might impact your compliance with regulations and other data protection laws, particularly regarding data minimization, the right to be forgotten, and explicit consent requirements for tracking and profiling.
Conclusion
Choosing between Field-based Stitching and Graph-based Stitching requires careful alignment with your organization's specific CJA implementation requirements, technical capabilities, and business objectives. When making this decision, consider your current data architecture, identity management needs, future growth plans, and the complexity of your customer interactions.
Field-based Stitching provides a direct, deterministic approach that works well for organizations with clearly defined identity relationships and less complex customer journeys. Its directness makes it an accessible entry point for many implementations.
Graph-based Stitching offers advanced identity resolution capabilities, particularly valuable in complex ecosystems with multiple devices and platforms where comprehensive algorithmic matching is necessary to accurately track customer journeys across touchpoints.
By carefully evaluating your data collection methods, identity resolution requirements, and technical resources, you can select the most appropriate stitching solution for your CJA implementation. Understanding the distinct advantages of each approach allows organizations to optimize their CJA deployment while maintaining data integrity and operational efficiency.