
Tracking and Analyzing LLM and AI-Generated Traffic in Adobe Customer Journey Analytics
Introduction
As artificial intelligence technologies continue to gain widespread adoption across various digital platforms and channels, developing an understanding of how Large Language Model (LLM) and AI-generated traffic influences and shapes your analytics data has evolved from being merely important to absolutely essential. Adobe Customer Journey Analytics (CJA) provides capabilities designed specifically to help organizations identify, segment, and analyze this unique category of traffic. These powerful features enable data professionals to not only maintain the highest standards of data integrity in an increasingly AI-driven digital landscape, but also to extract valuable, actionable insights into the specific ways that LLMs and AI systems interact with and navigate through your digital properties and assets.
In this guide, we will explore approaches to handling LLM and AI traffic in CJA using derived fields and CJA reporting methods, covering implementation across web, app, and agent interactions. We will examine how the technical behavior of LLMs and AI agents, particularly their limited JavaScript execution capabilities, affects detection methods and creates unique challenges for analytics practitioners. Most LLM and AI crawlers do not execute JavaScript when accessing web content, instead parsing HTML directly. This key distinction impacts how they are detected and tracked within analytics platforms, requiring specialized approaches to ensure accurate data collection and analysis.
NOTE: The effectiveness of these detection methods and implementation strategies depends on your specific data collection method, Adobe Experience Platform dataset coverage, and Customer Journey Analytics implementation. Results may vary based on your technical environment, data governance policies, and implementation approach. When using Experience Edge, you'll need to choose between recording the raw User Agent string or collecting device information.
Detection Methods and Analytics Implications
As artificial intelligence technologies rapidly expand, it has become increasingly important to have AI detection methods. We should distinguish between two key categories: LLM crawlers and AI agents. LLM crawlers primarily collect data for training and Retrieval-Augmented Generation (RAG), while agents function as user interfaces performing tasks on behalf of humans. When these different AI systems engage with websites, applications, and online platforms, their activity can significantly shape analytics data, making detection strategies essential for accurate measurement.
It's worth noting that AI agents generally prefer to interact via APIs when available, as these provide more secure and machine-friendly interfaces. Unfortunately, these API-based interactions typically bypass web analytics tracking methods, creating blind spots in our data. Despite this limitation, we can still identify and analyze a significant portion of AI-generated traffic through web interfaces.
This section examines three core detection methods commonly used to identify and monitor LLM and AI-generated traffic: User Agent Detection, Referrer Analysis, and Query Parameter Detection. Both User Agent and Referrer data are captured automatically by default through Adobe's data collection libraries (when they execute properly), while Query Parameters require specific implementation configuration to ensure proper capture. Each method has unique strengths and limitations, and understanding these differences is crucial for an effective CJA implementation strategy. We will explore the technical constraints of each approach, their potential impact on data analysis within CJA, and key considerations for implementation. With this understanding, CJA practitioners can better adapt their tracking and measurement tactics to meet the challenges of the evolving AI landscape.
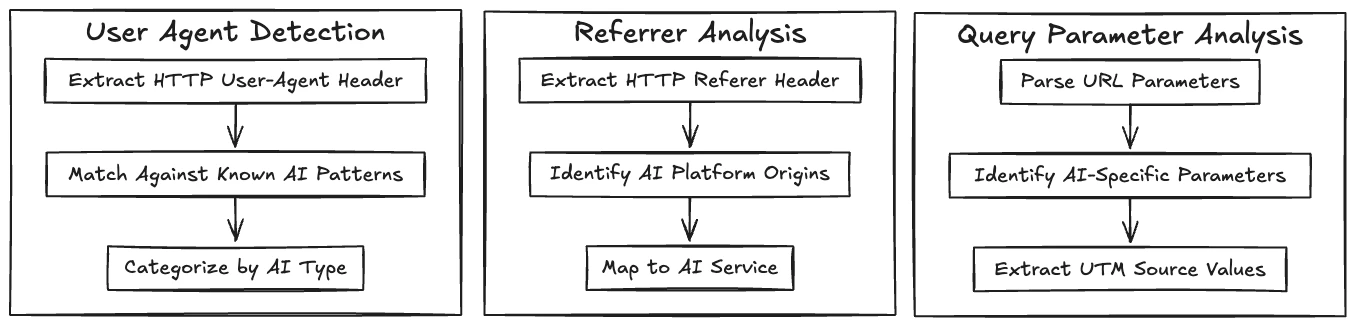
- User Agent Detection: When a request is made to your server, the HTTP User-Agent header is extracted and analyzed against known AI crawler and agent patterns. This server-side method requires access to HTTP headers and is most effective when implemented at the data collection layer.
- Referrer Analysis: The HTTP Referer header contains the URL of the previous webpage that linked to the current request. This header reveals when users click through to your site from web interfaces like ChatGPT or Perplexity.
- Query Parameter Tracking: URL parameters (particularly UTM parameters) may be appended to links by AI services. These parameters persist in the URL and can be captured through standard analytics implementations, making them valuable indicators even in client-side tracking scenarios.
Each of these signals can flow into CJA's derived fields functionality, where they can be transformed into meaningful components for reporting and analysis. The multi-signal approach provides redundancy, as different AI interactions may only be detectable through specific methods.
LLM & AI Traffic Detection Matrix
The following matrix shows how different LLM & AI interaction scenarios can be detected across three key methods.
| Scenario | User Agent | Referrer | Query Parameter |
| Training of a Model | Detectable (GPTBot, ClaudeBot, etc.) when server-side logging is implemented | Not present as AI crawlers don't generate referrers during training | Not present as crawlers don't typically add parameters during training |
| Agent Browsing | Detectable (ChatGPT-User, claude-web) when server-side logging captures headers | May appear if agent navigates from an AI interface with referrer preservation | Sometimes present if the AI service adds tracking parameters |
| Retrieval-Augmented Generation (RAG) to Answer Query | Detectable (OAI-SearchBot, PerplexityBot) with server-side logging | Not typically present as RAG operations often bypass referrer mechanisms | Rarely present unless specifically implemented by the AI provider |
| User Click Through | Not detectable as appears as normal user agent | Detectable when users click links from AI interfaces (chatgpt.com, claude.ai, etc.) | Sometimes present as AI services may add UTM parameters to outbound links |
| Traffic Visibility Conditions | Requires server-side logging integration with CJA, or server-side tagging | Depends on AI platform referrer policies and proper HTTP header transmission | Requires parameter preservation through redirects and proper URL parameter collection |
Mixed Detection Challenges
LLM & AI agents demonstrate complex and evolving behaviors when interacting with digital properties. These technologies operate inconsistently across platforms and versions, creating unique challenges for data professionals. Their behavioral patterns vary significantly depending on the specific AI platform, version, and interaction mode used. This operational diversity complicates efforts to track and categorize such traffic within standard analytics frameworks. The complex nature of these interactions, combined with their rapid evolution, requires nuanced detection and classification methods to maintain data integrity:
- Partial Data Collection: Some newer AI agents execute limited JavaScript, resulting in incomplete analytics data for client-side implementations. This causes some interactions to be tracked while others are missed.
- Inconsistent Session Data: AI agents may execute JavaScript differently across sessions or page types, creating fragmented user journeys in CJA for client-side implementations.
- Detection Challenges: With partial tracking, detection becomes unreliable as certain touchpoints may be invisible to analytics.
Strategic Implementation Guidelines
To address these challenges in CJA:
- Deploy a multi-layered detection approach that integrates user agents, referrers, and query parameters tailored to your specific implementation environment and technical capabilities.
- Build derived fields in CJA that combine multiple signals to enhance detection accuracy.
- Create custom segments that capture the distinct behavioral patterns of LLM & AI traffic.
- Continuously monitor for new LLM & AI crawlers and promptly update your detection rules to keep pace with the rapidly evolving landscape.
This multi-faceted approach is essential for ensuring your CJA implementation can accurately identify, differentiate, and analyze AI-generated traffic. By using these methods, you’ll overcome the technical and behavioral challenges inherent in tracking AI-driven activity, allowing your analytics platform to adapt to shifting AI interaction patterns and uphold the highest standards of data accuracy and insight.
Understanding LLM and AI Traffic Signatures
Building on the detection methods and analytics strategies discussed above, it's important to recognize that AI and LLM interactions produce distinct patterns in your data that differentiate them from human traffic. These unique digital footprints manifest across multiple dimensions of your analytics implementation, creating recognizable signatures that can be systematically identified and categorized. By understanding these patterns in depth, you can develop more sophisticated segmentation strategies and gain valuable insights into how these emerging technologies interact with your digital properties.
Specifically, as of August 2025, there are three primary types of signals that can be used to detect and categorize AI-generated traffic across your digital properties:
1. User Agent Identification
LLM crawlers and AI agents typically identify themselves through specific user agent strings:
| Crawler | User Agent String | Purpose/Behavior |
|---|---|---|
| GPTBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbot |
OpenAI's primary web crawler for training ChatGPT and language models |
| ChatGPT-User | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot |
Used when ChatGPT browses websites on behalf of users (legacy) |
| ChatGPT-User v2 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/2.0; +https://openai.com/bot |
ChatGPT's updated version for on-demand fetching and in-response lookups |
| OAI-SearchBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot |
ChatGPT's search-focused crawler for discovering content |
| ClaudeBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ClaudeBot/1.0; +claudebot@anthropic.com |
Anthropic's crawler for training and updating the Claude AI assistant |
| Claude-User | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0; +Claude-User@anthropic.com) |
Supports Claude AI users when individuals ask questions to Claude, it may access websites using a Claude-User agent |
| Claude-SearchBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0; +Claude-SearchBot@anthropic.com) |
Navigates the web to improve search result quality for Claude AI users by analyzing online content to enhance the relevance and accuracy of search responses |
| PerplexityBot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot) |
Perplexity.ai's crawler for real-time web data indexing |
| Perplexity-User | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://www.perplexity.ai/useragent) |
Loads pages when users click Perplexity citations (bypasses robots.txt) |
| Google-Extended | Mozilla/5.0 (compatible; Google-Extended/1.0; +http://www.google.com/bot.html) |
Google's AI-focused crawler for Gemini, separate from standard Googlebot |
| BingBot | Mozilla/5.0 (compatible; BingBot/1.0; +http://www.bing.com/bot.html) |
Microsoft's crawler powering Bing Search and Bing Chat (Copilot) |
| DuckAssistBot | Mozilla/5.0 (compatible; DuckAssistBot/1.0; +http://www.duckduckgo.com/bot.html) |
Scrapes content for DuckAssist, DuckDuckGo's private AI answer feature |
| YouBot | Mozilla/5.0 (compatible; YouBot (+http://www.you.com)) |
Crawler behind You.com's AI search and browser assistant |
| meta-externalagent | Mozilla/5.0 (compatible; meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)) |
Meta's bot for collecting data to train or fine-tune LLMs |
| Amazonbot | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) |
Amazon's crawler for search and AI applications |
| Applebot | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot) |
Apple's crawler for Spotlight, Siri, and Safari |
| Applebot-Extended | Mozilla/5.0 (compatible; Applebot-Extended/1.0; +http://www.apple.com/bot.html) |
Apple's AI-focused crawler for future AI models (opt-in) |
| Bytespider | Mozilla/5.0 (compatible; Bytespider/1.0; +http://www.bytedance.com/bot.html) |
ByteDance's AI data collector for TikTok and other services |
| MistralAI-User | Mozilla/5.0 (compatible; MistralAI-User/1.0; +https://mistral.ai/bot) |
Mistral's real-time citation fetcher for "Le Chat" assistant |
| cohere-ai | Mozilla/5.0 (compatible; cohere-ai/1.0; +http://www.cohere.ai/bot.html) |
Collects textual data for Cohere's language models |
2. Referrer Analysis
When users interact with your content through AI interfaces, the traffic may contains specific referrer signatures:
| Source | Referrer | Traffic Type |
|---|---|---|
| ChatGPT | chatgpt.com | Direct traffic from ChatGPT interface |
| Claude | claude.ai | Traffic from Anthropic's Claude interface |
| Google Gemini | gemini.google.com | Traffic from Google's AI assistant |
| Microsoft Copilot | copilot.microsoft.com | Traffic from Microsoft's AI assistant |
| Microsoft Copilot | m365.cloud.microsoft | Traffic from Microsoft's AI assistant (Microsoft 365 cloud services) |
| Perplexity AI | perplexity.ai | Traffic from AI search with citations |
| Meta AI | meta.ai | Traffic from Meta's AI assistant |
3. Query Parameter Signals
LLM services may include specific URL query parameters that identify traffic sources. These parameters provide valuable tracking data that reveals how AI systems interact with your content. By examining these URL patterns, you can identify the origin of LLM services through their distinctive query parameters, enabling accurate identification and analysis of AI-generated traffic in your analytics. Note that the examples below are not comprehensive and may not reflect the most current parameters used by all LLM services, as these can change over time
| LLM Service | Example URL | Query Parameter | Example Value |
|---|---|---|---|
| ChatGPT | https://www.yoursite.com/product?utm_source=chatgpt.com | utm_source | chatgpt.com |
| Perplexity | https://www.yoursite.com/article?utm_source=perplexity | utm_source | perplexity |
Implementing LLM Traffic Analysis in CJA
Adobe CJA offers a framework for identifying and analyzing AI-generated traffic through its advanced derived fields functionality. The examples below illustrate how CJA can detect AI traffic. Unlike traditional processing rules that permanently alter data, derived fields provide a flexible, non-destructive approach to classifying field value inputs.
NOTE: The effectiveness of these LLM and AI traffic detection methods will evolve as AI technology advances. Organizations should regularly update their Customer Journey Analytics derived field logic to capture new AI user agents, referrer patterns, and query parameters. Today's effective methods may become outdated as AI services modify their identifiers or new providers emerge. We recommend implementing a quarterly review process to validate and refresh your detection criteria, ensuring your analytics data stays accurate and reliable as AI interactions with your digital properties continue to evolve.
Step 1: Create Derived Fields for LLM & AI Traffic Classification
Based on your tracking capabilities and implementation environment, as achievable apply the following derived field strategy at the Connection level to ensure consistent handling across all corresponding Data Views:
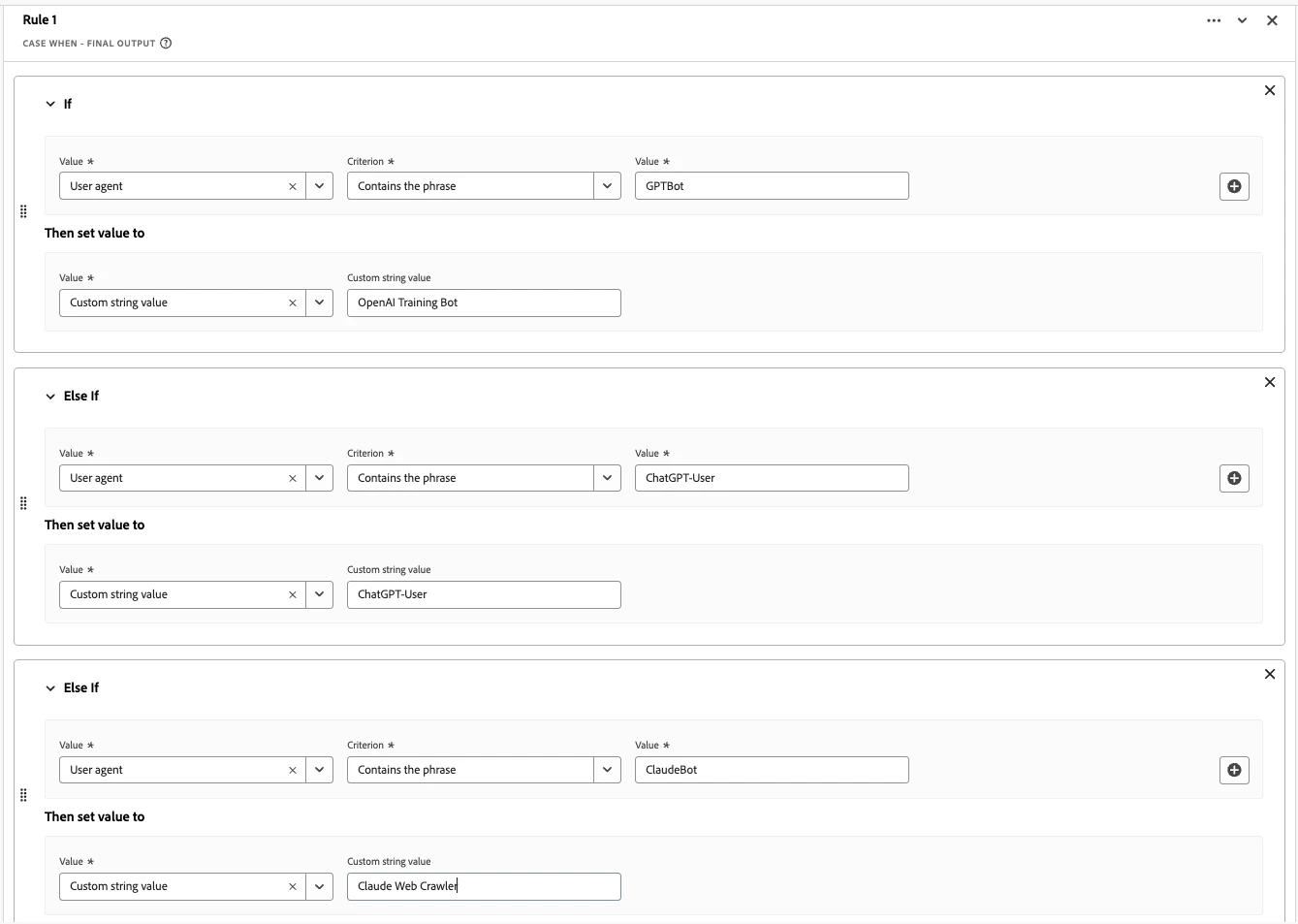
- LLM/AI User Agent Identification: Create a derived field using Case When functions to identify and categorize LLM traffic based on user agent strings. This allows you to flag and segment different types of AI crawlers and agents.
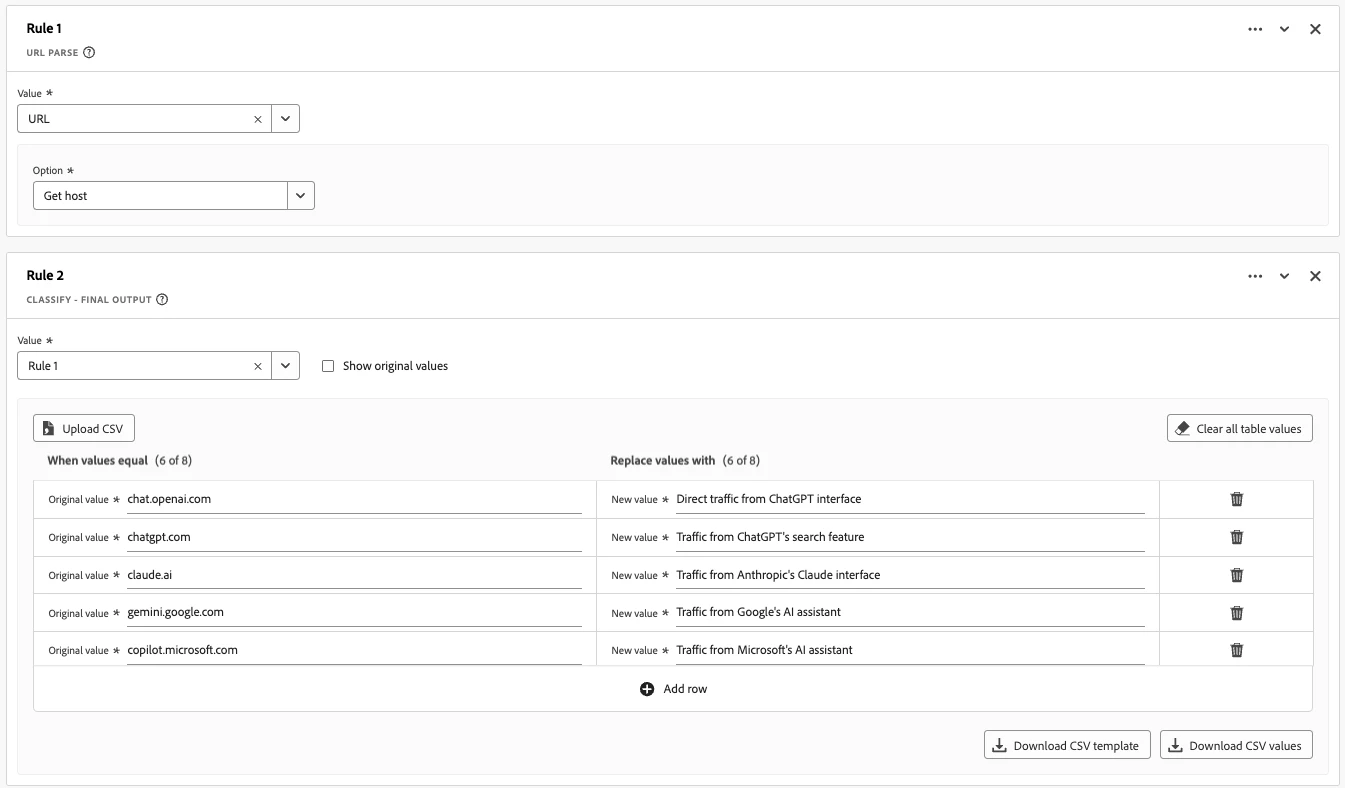
- LLM/AI Referrer Classification: Create a derived field to categorize traffic originating from AI interfaces using referrer information:
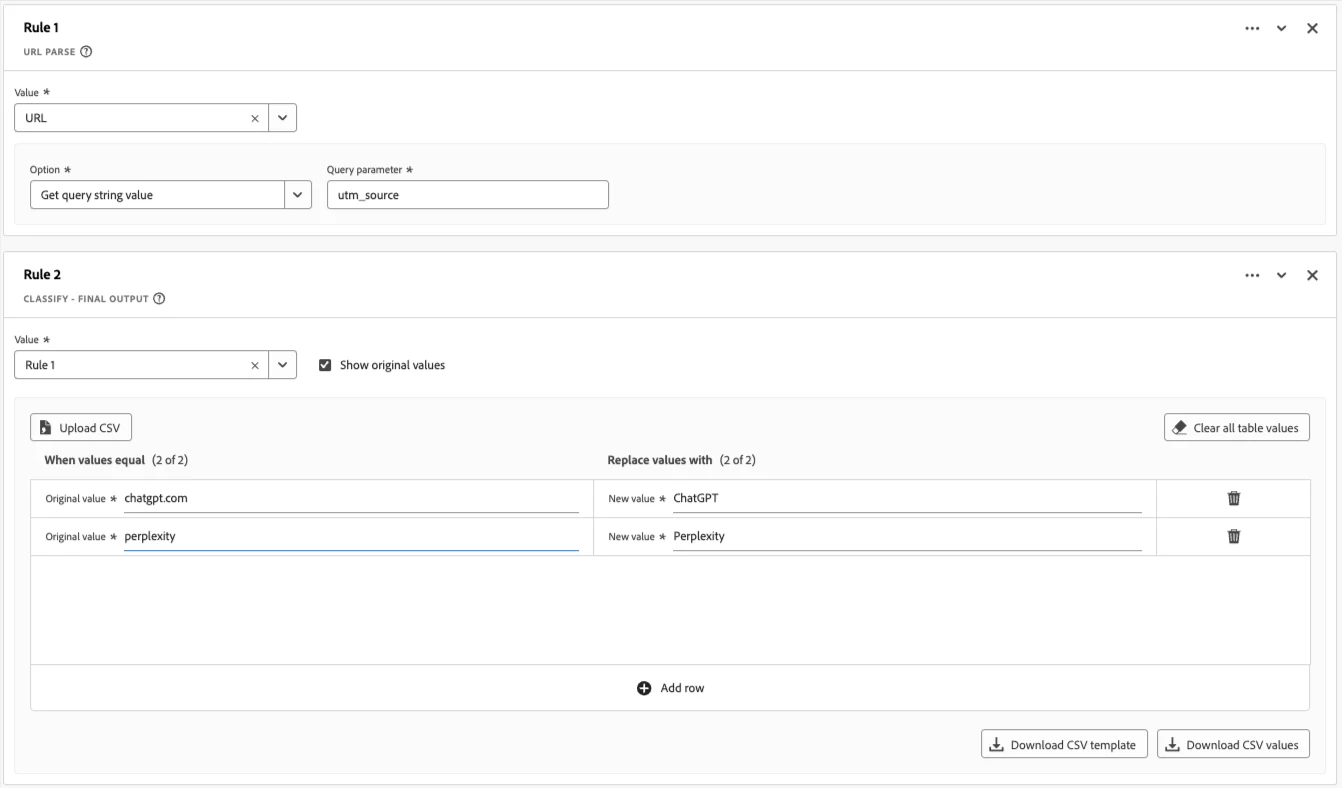
- LLM/AI UTM Parameter Detection: Create a derived field to identify and classify traffic based on AI-specific UTM parameters:
Step 2: Develop Custom LLM & AI Reporting Projects
Leverage the full potential of Analysis Workspace in CJA by building specialized dashboards to track and visualize LLM & AI-generated traffic. These projects enable analysts and stakeholders to monitor trends, compare key metrics, and examine detailed interaction patterns across your digital properties. This provides a clear, comprehensive view of how AI-driven activity affects your analytics environment. Additionally, reporting serves as a powerful identification tool by revealing distinctive behavioral patterns, such as extremely fast navigation between pages for LLM & AI-generated traffic versus human interactions like completing purchases, when analyzing sessions or users.
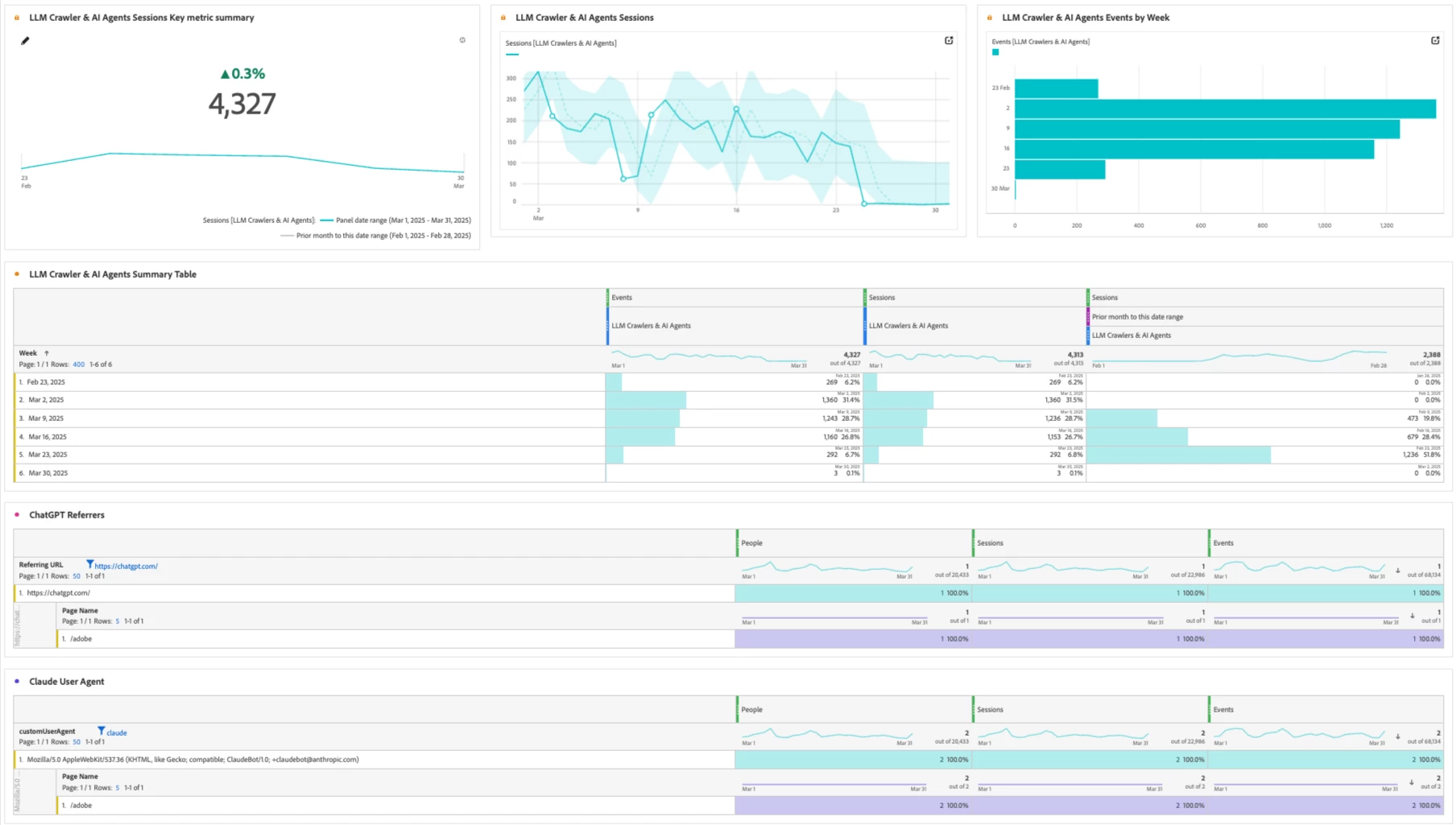
- AI Traffic Overview: Create a dashboard that displays the volume, trends, and patterns of AI-generated traffic across websites, mobile apps, and other channels.
- Content Engagement Analysis: Compare how AI agents and human users interact with content by examining metrics like page views, time on page, and consumption patterns.
- Conversion Impact Assessment: Evaluate how AI traffic influences conversion metrics and determine whether to include or exclude it from performance calculations.
- Segmentation Refinement: Enhance user segmentation by identifying AI traffic to ensure marketing and personalization efforts target human audiences.
- Bot Exclusion Filters: Create exclusion filters in key reports to prevent AI-generated sessions from skewing core performance metrics.
- Longitudinal Trend Analysis: Track AI-generated traffic over time to identify shifts in search engine and LLM behavior.
- Engineering Collaboration: Partner with developers and IT teams to maintain current user agent, referrer, and query parameter lists as new AI services emerge.
- Alert System Implementation: Set up alerts for unusual traffic patterns that might indicate new AI sources or changes in existing AI behavior.
- Regular Criteria Updates: Continuously refresh identification criteria as new AI services launch and existing ones evolve.
Conclusion
As LLM and AI technologies continue to advance and change how people interact with digital platforms, keeping analytics data accurate and reliable is becoming more challenging. These technologies are creating new complexities in the digital landscape, making it critical for organizations to update their analytics strategies to properly capture and understand data. CJA provides flexible solutions with powerful retroactive analytical capabilities that work dynamically when generating reports, helping you identify, classify, and analyze AI-generated traffic across your digital properties while keeping your data useful and trustworthy even as technology evolves.
When you apply the framework outlined in this guide, including creating derived fields, analyzing traffic behavior, and building custom reporting projects and segments, you'll get valuable insights into how AI systems and automated agents interact with your digital content. These practices help maintain the accuracy and integrity of your analytics, ensuring that reports focused on human activity remain reliable and allowing your organization to confidently tell the difference between human and AI-driven interactions when making data-based decisions.