
Transactional Coverage — a Functional Approach to Detecting Test Gaps
Author: Baubak Gandomi

This is the second post in a two-part series about the importance of measuring efficient functional tests in platform engineering and in complex products. Baubak Gandomi is a Test Architect with Adobe Customer Journey Management.
Code Coverage has been a buzz work in the industry as a means to detect holes in our certainty regarding the testing of our products.
This is actually a very good measure since it helps us find lines in the code that are not tested. We also think it is quite misleading if used on its own to represent test gaps, and that the efforts in it could be misplaced. We have covered these problems in more detail in a separate article “Problems with Code Coverage when Assessing Functional Tests”.
Instead, we propose “Transactional Coverage” as a new approach to code coverage, which is simpler in its implementation, and which better maps to the business. It will also help you better prepare a harness for an application to which you are new.
The main focus of this article is functional testing. We will often use the term “line-level” coverage to designate coverage reports that point to a line of code. This includes among other things, line- and branch coverage.
Laying up the Background
Imagine you have a multi-tier web application with multiple technologies. It uses a framework where the different modules are interwoven using XML or JSON.
We also have tests. Tests on all levels such as unit, integration, functional and Manual tests.
Unless you have the super coverage application the general process is:
- You generate coverage for the unit tests.
- You create a build of your product generating coverage data. And run tests against it.
- You merge the results.
This sounds quite simple, and it seems so to those who do not implement this. We think that this approach has a lot of problems related to it.
Although we think line level coverage is very well adapted to low deployment tests such as unit and some component tests, we think they also have a number of important drawbacks.
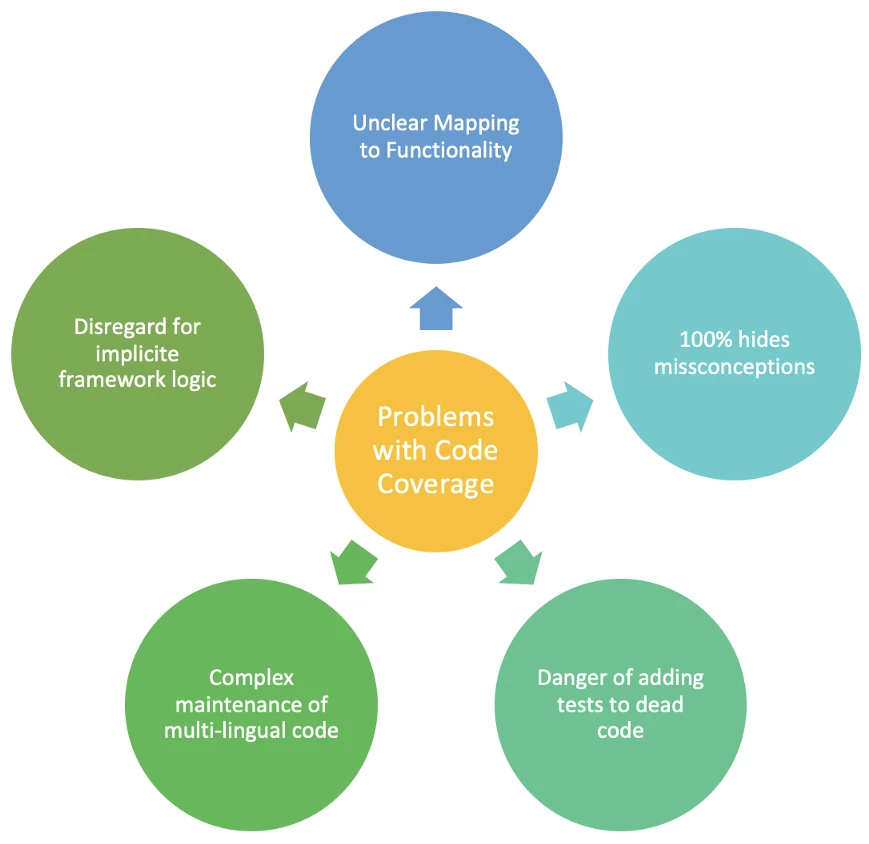
For more details on these problems please refer to the article “Problems with Code Coverage when Assessing Functional Tests”. We think that transactional coverage could address many of these issues.
Transactional Coverage
We originally started out to introduce a light-weight solution to line-level coverage due to the problems described above.
The approach we propose is to measure all the triggered transactions by our tests against all the possible transactions that could happen in your product.
By transactions, we identify “any action that can be initiated by an end-user, and that leads to access or manipulation of application data”.
The calculation is:
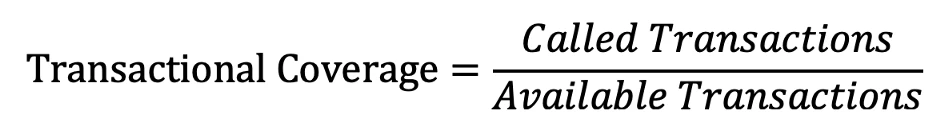
An example of a simple 3-tier web application would be the submission of a web form, that leads to an entry in the attached database.
The approach is definitely not completely new, but it is rarely requested in KPI’s. Yet in the industry, we have similar approaches in the concepts such as function points IFPUG. Similar approaches are used to measure metrics in some static code analyzers such as CAST.
Our experience shows that, where line level coverage gaps are covered by unit tests, transactional coverage gaps are more intuitively covered using functional and integration tests.
When identifying transaction coverage, we identify two dimensions of coverage:
- Breadth
- Depth
The Breadth of transactions is coverage all possible paths. We look at all the possible entry points into the system and ensure that they are tested.
Example REST: In Rest API this would mean testing all API and their associated verbs
The Depth of transactions involves covering a certain depth regarding the data being passed to the backend. The challenge in-depth coverage is to define an achievable boundary. The complexity of calculating this grows very fast depending on the size of the payloads and their nested depths.
Example Rest API: We ensure that we pass all the fields in a payload, and do not rely on the default values.
Note: In this document, we will focus mostly on breadth transactions as it is easier to define an intuitive perimeter for a finite goal. There are many strategies for creating boundaries for depth transactional coverage, but we feel that they probably deserve a separate article.
Advantages of Transactional Coverage
We have identified the following advantages of using transactional coverage:
- Very close to an estimation for functional coverage.
- The metric is easily mapped to business logic and functionality. Hole in this coverage metric map to functional gaps in testing.
- Transactional coverage can be easily applied to the usage by clients.
- Questions such as framework logic, and what technologies lie behind the code are of much less importance.
Approach
As in all coverage approaches, we need to identify an approach that allows us to embed it in a software life cycle. This requires some level of preparation. We identify the following steps to prepare for this:
- Identify the transactions (and defining the perimeter)
- Tracking the transactions
- Generating a Report
- Creating a backlog
1. Identifying the Transactions & Abstraction
Identifying the transactions involves the detection of our target coverage. With this information, we can calculate what 100% transactional coverage is.
If we followed the definition of “transaction” then one would need to trace all paths from the user interface to the application storage mechanism. We think that we need to go further and identify what is called the “attack surface”. By this, we identify all methods by which a user can initiate a transaction. In this abstraction, we assume all access to the product interface will lead to a transaction.
Examples of the non-UI interface are REST and SOAP API.
In the remainder of this article, we will also use the wording “API” to designate the transactions.
The approach here is to look at the application model in order to identify the API. This requires model analysis, which is done by identifying the forms and the transaction.
We identify the following challenges and risks here:
- Does the application allow us to deduce transactions?
- Can we create an attainable perimeter of what is to be tested?
We have discovered that making a distinction between UI accessible transaction is very useful when we need to prioritize the gaps we find. We will cover other methods of prioritizations later in the chapter on creating a backlog.
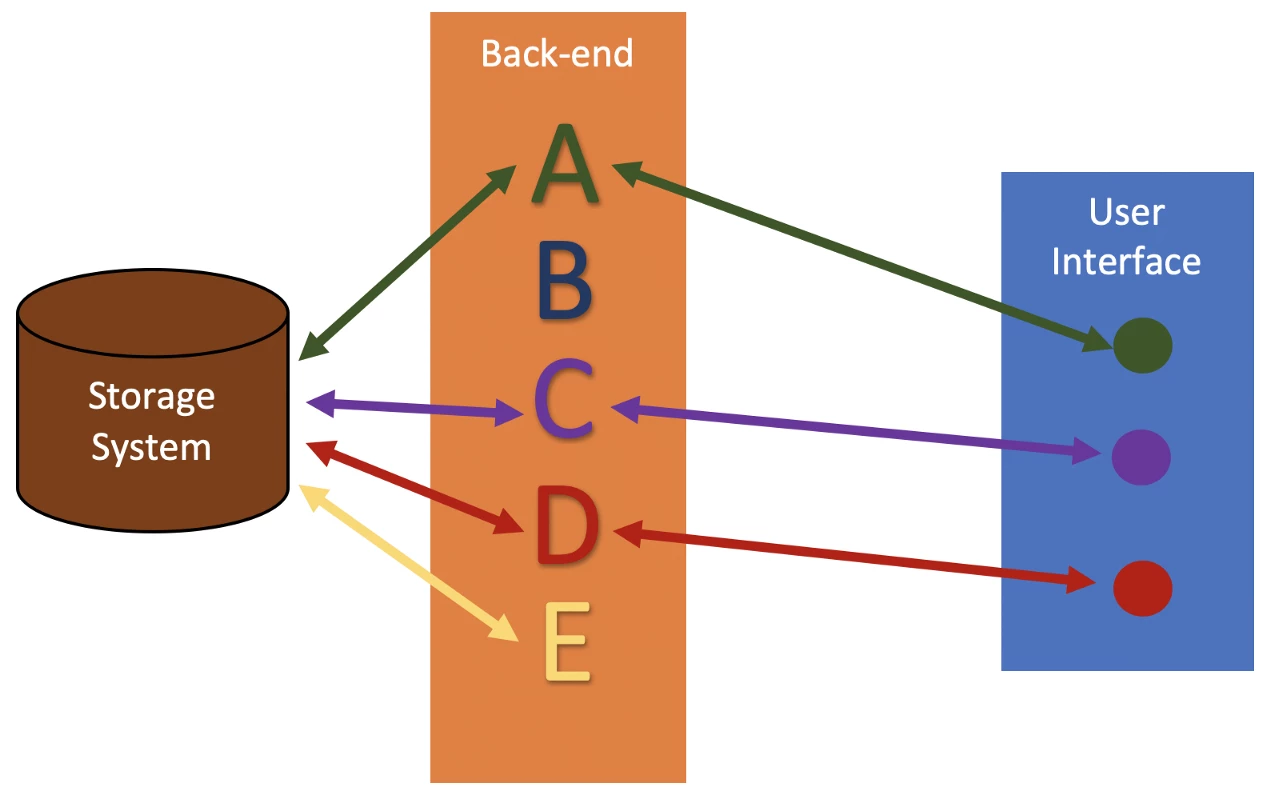
In the example above, the attack service consists of the endpoints A, B, C, D, and E. We can also see that A, B, and C are the transactions that an end-user will be more likely to trigger. We can also see that where E is not called by the UI it can be called, and where it needs to be tested, whereas chances are that B is a source of dead code.
2. Tracking the transactions
Tracking transactions allows you to measure which transactions you are executing during your tests. This allows you to also identify the gap.
This is done by analyzing the test and application logs. The challenge is usually accessing and parsing the logs. Log collectors such as Splunk could be very useful here, since not only will you have a centralized location where you can access them, but can also monitor the transactions triggered by your clients. This allows you to better track the usage of your applications.
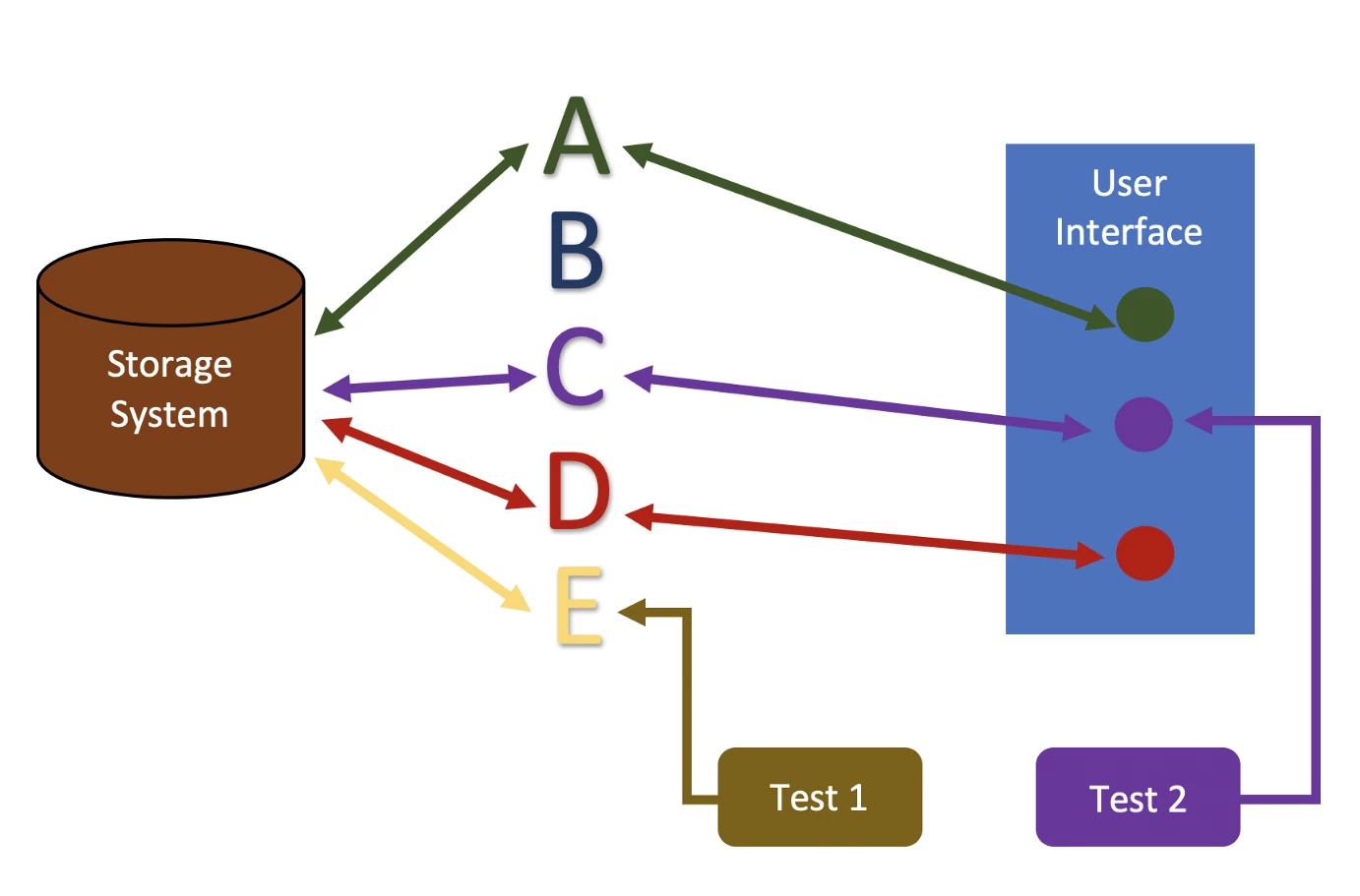
Once you have tracked the transactions, you can calculate the coverage. In the example above you have 2 tests, and you have a total of 4 API. One tests the UI, the other directly accesses the API. In this example, the coverage is 50%.
3. Generating a Report
We need to be able to communicate our findings to all levels of the company. This is vital because it helps to get insights from the different stakeholders.
Hi-Level Coverage Overview (Management)
We need a very concise report that allows readers to see the state of the transactional coverage at a glance. Simply, the number of transactions that are tested, and the number of transactions that need to be tested.
Cube Reports
We also use a cube report that allows us to perform fault searches. This is a .csv report that contains the following data:
- All of the transactions
- The transactions that are accessed by the UI
- The transactions triggered during the testing phase
- The transactions that are directly accessed by a test
4. Creating a Backlog
Once you have the list of non-covered transactions, you need to create a backlog. Although this step is essential to track the evolution of the transactional coverage, it is really up to each organization how they manage their tasks.
Prioritization
We have discovered a few methods for prioritizing the backlog. Where the obvious choice is to consult the product experts there are methods that also help assess the priorities.
We think that by analyzing production logs we can get a good picture of the transactions fired by your clients, this also helps to prioritize the testing gaps. One would assume that a transaction that is often executed by your clients would be the best candidate for testing.
If that is possible, as mentioned earlier looking at the API that is called most by the UI is a good approach. We can assume that our clients would have more opportunities to execute those transactions.
Conclusions
I would like to reiterate that we are not suggesting a replacement for line-level coverage, which we think is great for unit tests. We suggest that the transactional coverage addresses issues that line coverage really is not meant for.
As we all know there are few silver bullets. Most possibly using this approach is more decisive in complex and heterogeneous systems. It also allows you to better assess functional coverage not only by your tests but also client usage.
A small micro-service application would probably not need such an approach, and Line Level Coverage should be quite sufficient.
With transactional coverage, we discovered that it was much easier to show information, that involved both the business side and the engineering. It is also very close to the measurement for functional coverage. As such it deserves its place as a standard KPIs to the leadership.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Dec 10, 2020