
Reimagining Jupyter Notebooks for Enterprise Scale
Authors: Kumar Sangareddi, Ashok Pancily Poothiyot, Chetan Bhatt, and Jody Arthur
Learn how Adobe Experience Platform is pushing the boundaries of what Jupyter Notebooks can do — making data science at scale easier, faster, and more powerful with pre-built notebooks and innovative plug-ins, one-click packaging of Jupyter notebooks to recipes, parameterized notebooks, and capabilities for scaling Jupyter for multi-tenancy.
When it comes to developing machine learning models, Jupyter Notebooks has become the go-to tool for data scientists everywhere. Jupyter Notebooks is highly customizable and allows users to combine code, comments, multimedia, and visualizations in a single interactive notebook that can be shared, re-used, and re-worked as needed to fit the use case. And, the ability to host notebooks in the cloud offers data scientists access to far greater computing resources than they would have on their local machines.
Despite these benefits, Jupyter Notebooks out of the box presents some challenges for enterprises working at scale to develop models that will help them provide better customer experiences. In Adobe Experience Platform, we have reimagined what Jupyter Notebooks can do and have significantly extended its capabilities for handling enterprise-scale data at all stages of the machine learning model workflow.
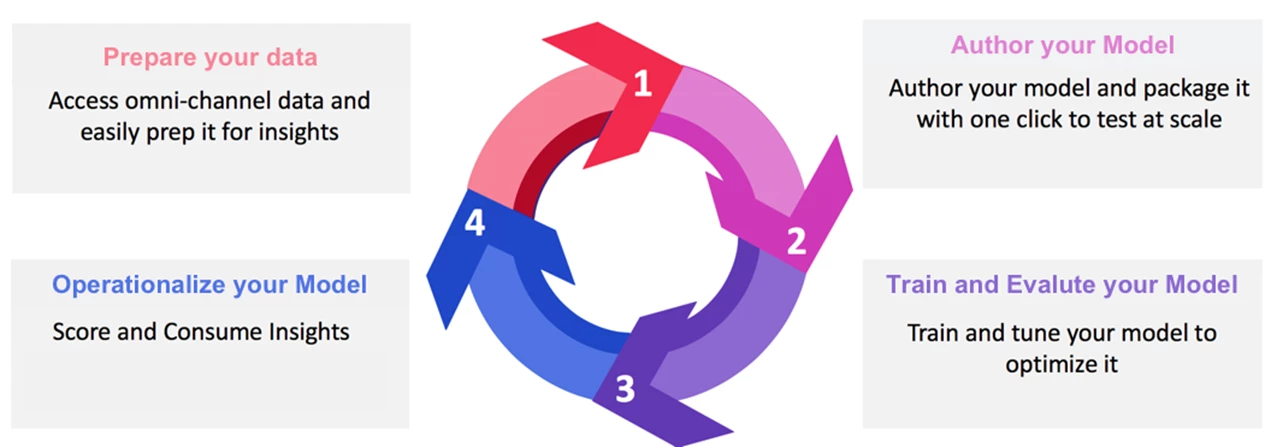
Extending Jupyter's capabilities
Before any modeling effort, data scientists must first explore the data, understand the data statistics, and identify and extract the most useful features of the data set. One of the biggest bottlenecks in any machine learning project is the vast amount of data that must be acquired and analyzed. It is estimated that data scientists spend 60–80% of their time on the feature engineering phase because the data they work with typically comes from a variety of complex sources, which is often not structured into well-defined data models.
This is not the case for data scientists working in Adobe Experience Platform in which Data Science Workspace is accelerating intelligent insights with cross-channel customer data already centralized and standardized into Experience Data Model (XDM) schemas. XDM significantly simplifies data preparation. In Data Science Workspace, data scientists can choose from a number of popular languages, including Scala, Spark, PySpark, Python, R, and SQL to work with in addition to hundreds of other kernels that can be enabled. With direct integration with Jupyter Notebooks, every step in the data science workflow, including exploration, cleaning and transformation, numerical simulation, statistical modeling, model development, and visualization is much more streamlined.
This post will introduce the different ways that Adobe Experience Platform has significantly extended Jupyter's capabilities within Data Science Workspace. We have developed pre-built notebook templates and a number of useful plug-ins including a one-click notebook-to-recipe packaging extension, a service for scaling the multi-tenancy of Jupyter, and parameterized notebooks.
Pre-built notebook templates
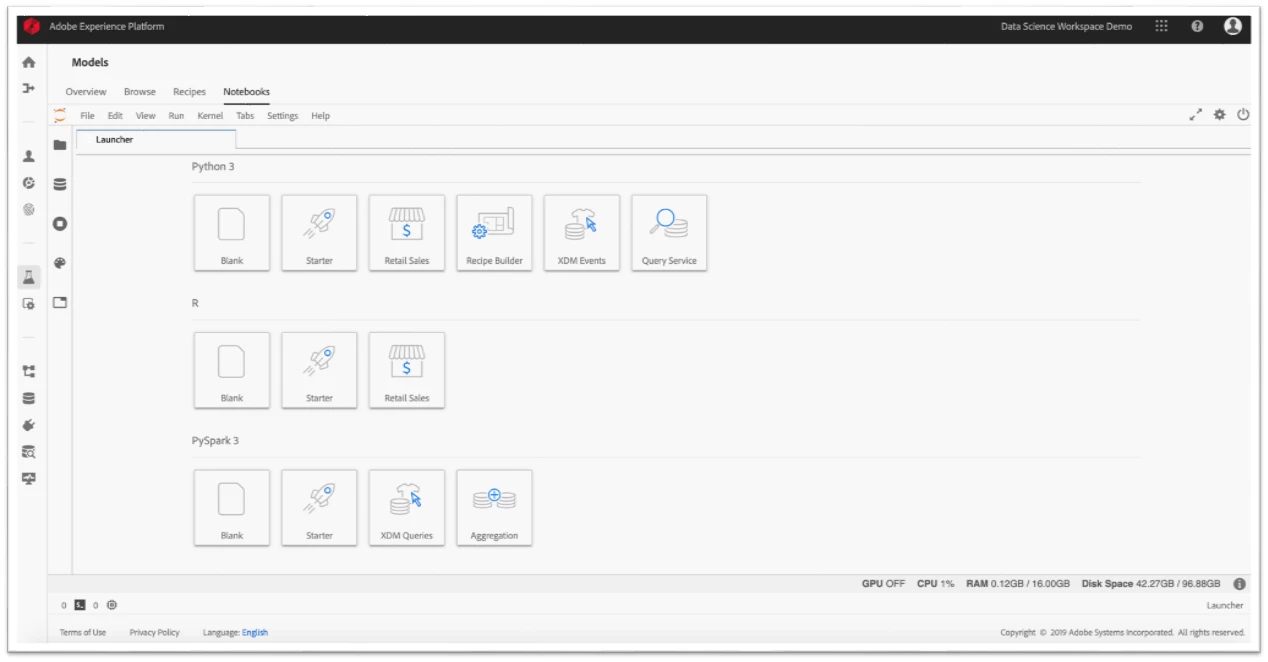
To facilitate data exploration for data scientists working in Adobe Experience Platform, we have embedded Jupyter Notebooks into our Data Science Workspace with out-of-the-box notebook templates (Figure 2).
We have developed pre-built notebook templates to cover every stage in the development of a machine learning model. With Data Science Workspace, users can find very simple templates as well as templates that provide for a full-blown machine learning model covering data exploration, model building, and model training and scoring. While some data scientists have a use case that requires them to write their own code, many enjoy the advantage of having templates with much of the complexity abstracted. For these users, the ability to copy a template without having to figure out the code to access their data in Adobe Experience Platform is a key benefit because it allows them to get started more quickly.
Templates within the library are categorized based on the technology used to develop them (e.g. Python or Spark) so users can more easily find those that are compatible with whatever technology they are using.
Data scientists working in Adobe Experience Platform can expect the library of pre-built templates to grow. Our vision for the integration of Jupyter Notebooks into Data Science Workspace also includes facilitating the sharing of user-created templates by:
- Building new templates around different types of use cases and making them accessible to other users within their organization.
- Publishing templates for all users within Data Science Workspace to copy and customize for their own use cases.
In addition to user-created templates, our library will eventually support a partner ecosystem that includes templates authored by Adobe Experience Platform partners as well as templates created by other Adobe product teams (e.g. Adobe Analytics).
Jupyter plug-ins
We have built a number of customized Jupyter plug-ins to extend its use within Adobe Experience Platform, some of which are server-side plug-ins working behind the scenes to make working with Jupyter Notebooks easier. For example, data scientists familiar with Jupyter's classic UI will immediately notice additional features in the Data Science Workspace such as the Launcher tab, which displays all the templates available to the user.
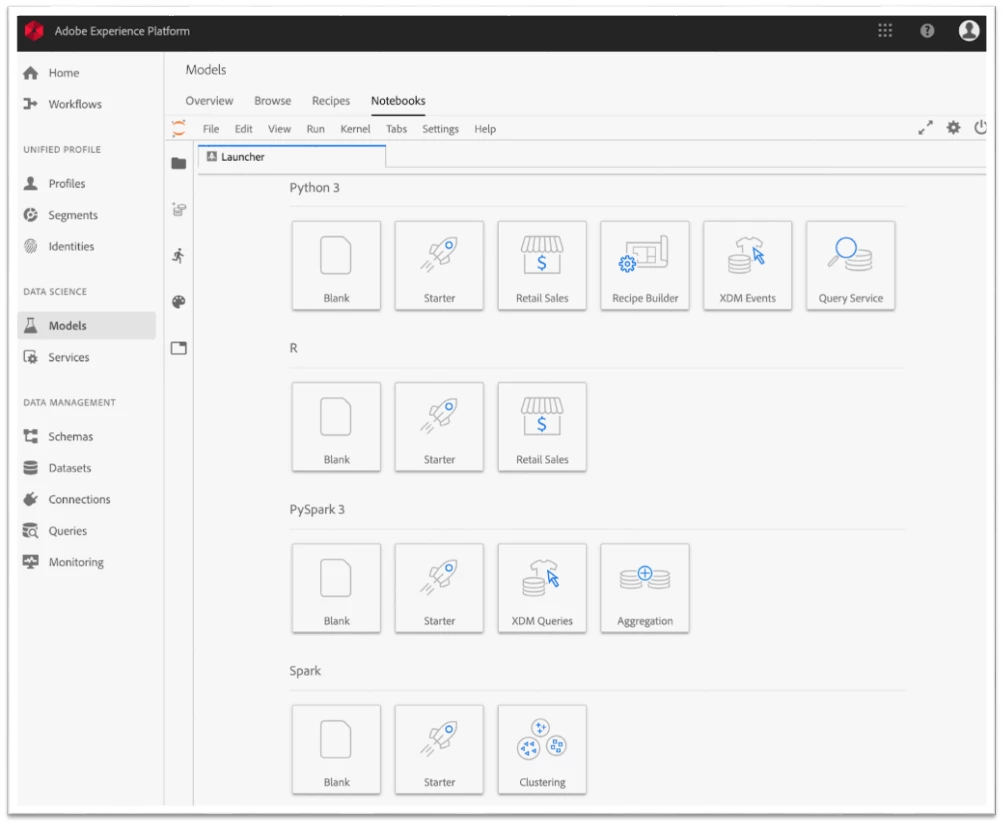
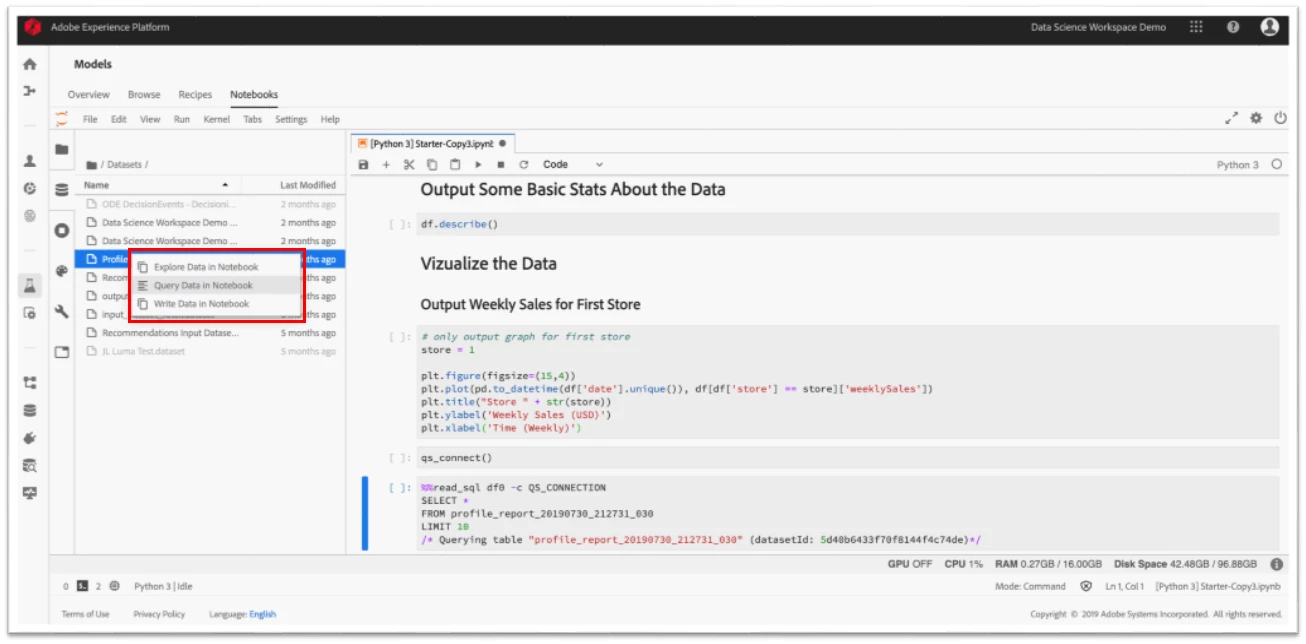
Users also enjoy friction-free data exploration and access to the data in Adobe Experience Platform using the data exploration plug-in, which handles all the necessary authentication behind the scenes to eliminate the need to provide credentials for access. This allows users to navigate to their data in the platform directly from within Jupyter Notebooks.
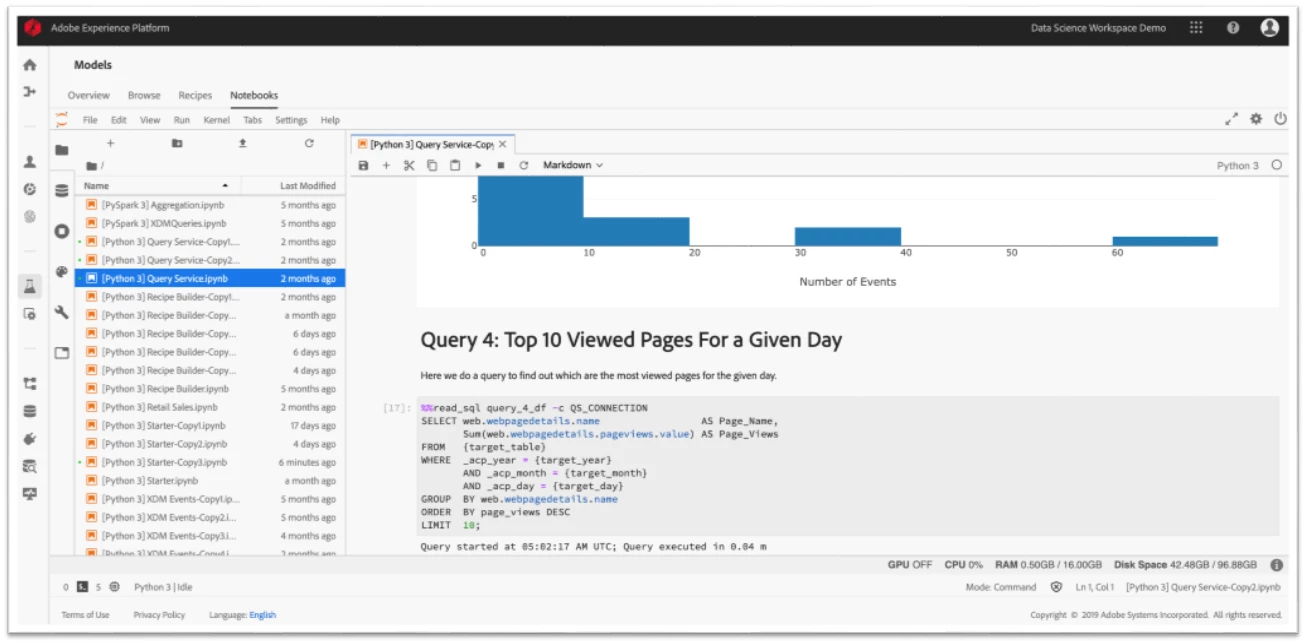
Users can also explore their data in notebooks through direct integration with Adobe Experience Platform Query Service, which provides a standard approach to querying the datasets with SQL (Figures 5 and 6).
We have also developed a couple of other useful plug-ins to make working with Jupyter Notebooks within Adobe Experience Platform easier, which include a resource usage plug-in and server configuration plug-in.
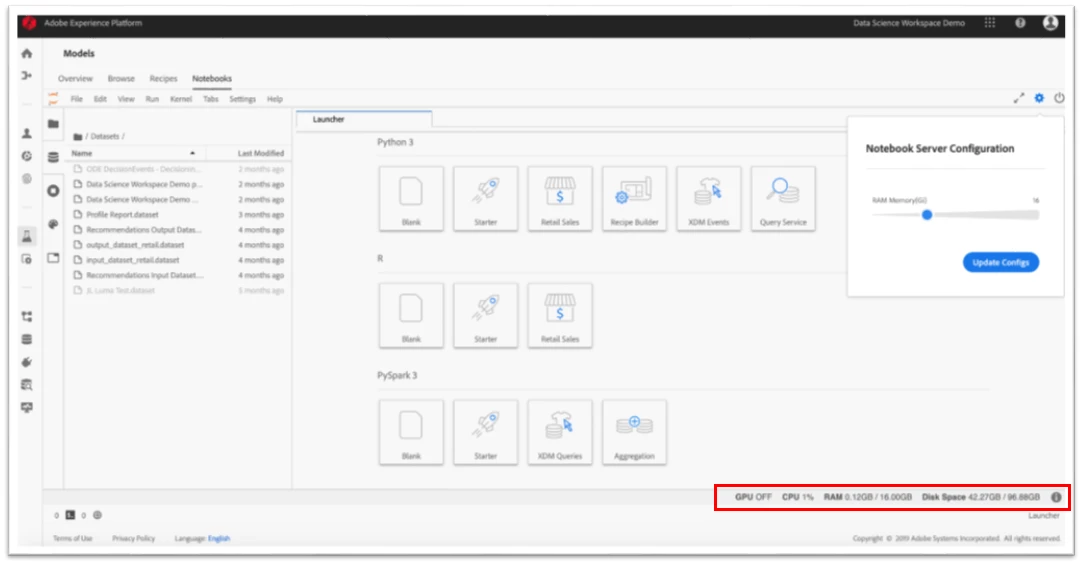
Jupyter was designed for use on local machines where users already know their compute limitations. On a local machine, users can simply open their task manager to see what resources they are using. However, in Data Science Workspace, they are working in the cloud where we are continuously spinning up containers for them to run their processes. This presents a challenge for users because out of the box, Jupyter Notebooks does not provide any way for them to know how much resources such as disk, memory, and CPU/GPU resources they are using.
In order to help them determine how much resources their notebook session is consuming, we developed a resource usage plug-in to provide RAM, CPU, and disk space usage indicators. Knowing how much compute they are using helps data scientists identify whether they may have a bug that is causing their notebook session to drag, or whether the code they are writing is too memory-intensive and needs optimization.
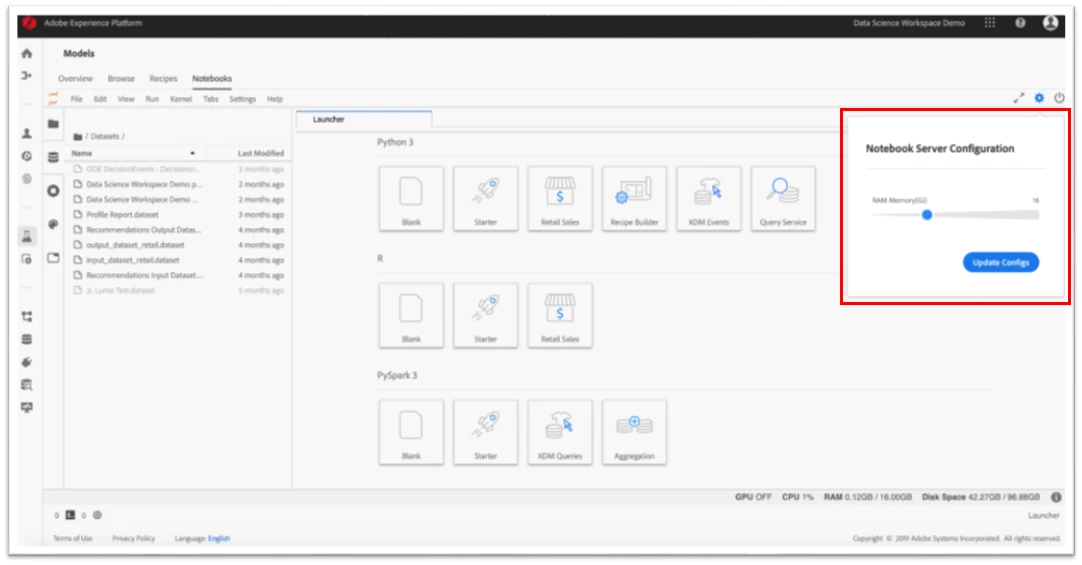
Our notebook server configuration plug-in allows users to configure the server on which they are using Jupyter Notebooks. When users are running notebooks on their own machines, they know their resource limitations. However, when working in the cloud, users need a way to get access to additional resources when needed. The server configuration plug-in allows users to choose their hardware based on the requirements of their use case. Another feature this plug-in provides is the GPU on/off toggle, which helps users choose a GPU Virtual machine if their use case requires one.
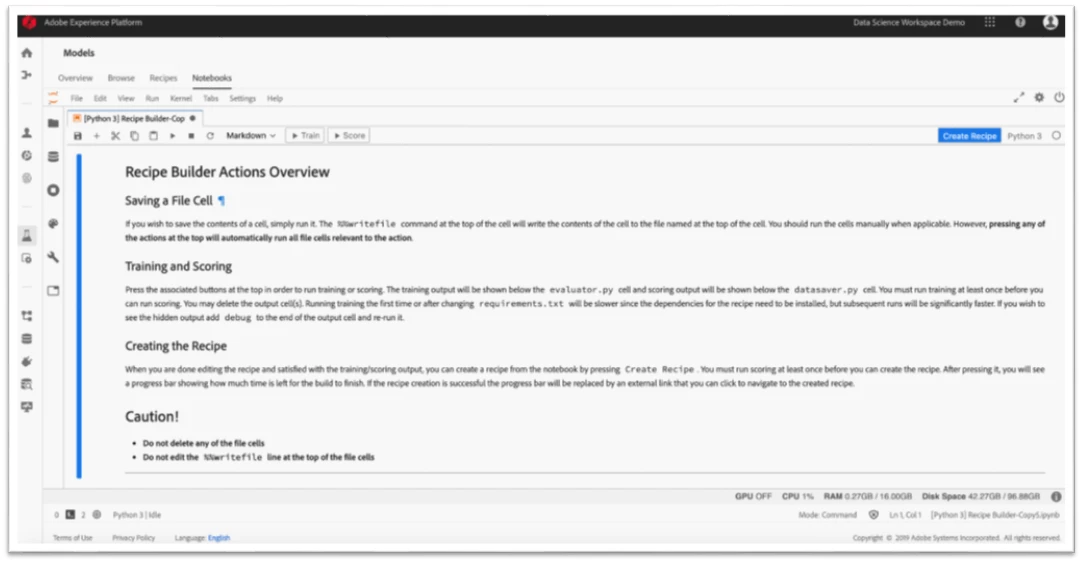
One-click packaging of Jupyter Notebooks into recipes
Exploring the data and choosing the right algorithms to use is the first step in any modeling effort. Often, data scientists will want to develop a “recipe,” which is a top-level container for the ML/AI algorithms, processing logic, and configuration required to build a trained model and train it at scale. The traditional approach to developing a recipe from a Jupyter notebook involves several manual steps by a technical developer (e.g. dockerization). To streamline this process, we have developed a packaging extension that automates the process with predefined steps allowing users to locally train, score, and then package their notebook model code as a recipe with the click of a button.
Packaging this work as a recipe can save significant time on future modeling efforts and provides a way for the data scientist to more quickly operationalize the training and scoring of the model at scale, both in terms of compute and data. They can also easily share their recipes with other users in the organization so it can be configured to run for different use cases and data sets, democratizing ML for the entire enterprise. The same recipe can then be re-used to power multiple use cases. For example, a recipe to generate product recommendations can be applied to when viewing a cart or searching for a product.
While these tools are complex, they are abstracted so that even users with a little data science background can implement them to get meaningful results from their data.
Our "Hanshi" service for scaling multi-tenancy of Jupyter
To ensure the best experience for Adobe Experience Platform customers, we have developed an orchestration and management service, which eliminates the need to install Jupyter Notebooks on individual machines for every user in the enterprise by serving it out through a centralized server. We call this our "Hanshi" service, which works behind the scenes in Data Science Workspace to effectively transform Jupyter from an on-premises tool into a hosted tool.
Within Adobe Experience Platform, Hanshi spawns a dedicated container for every data scientist with built-in machine learning and data visualization libraries that are customized and curated by Adobe. The Hanshi service handles the orchestration and management of containers for our enterprise users working with data at scale.
Hanshi provides a sandboxed environment for Adobe Experience Platform customers within the larger, hosted environment. The service is secured with Adobe's Common Control Framework (CCF), which is a compliance framework that meets several different national standards and regulations to add a high level of security to the images we provide to our Jupyter Notebooks users. These images are loaded with many popular machine learning libraries that work in harmony with each other (no conflicts). Users can select an image based on the technology they use and can install our image library and/or their own libraries on top of it. If they run into problems, they can get a fresh container with the click of a button.
Normally these libraries will run on virtual machines within a containerized system, such as Kubernetes. Hanshi allows access to many Kubernetes clusters, communicating with multiple Adobe Experience Platform services. These services, in turn, communicate with Azure services to identify which data center the user's data resides in (important for regulatory purposes) and which Kubernetes cluster within that data center to access.
Within the selected cluster, Hanshi determines what kinds of resources the user requires and based on that, enables the service to identify and build the type of virtual machine the user needs in moments. This is typically very difficult to do within a hosted environment, which is one of the reasons we developed Hanshi.
Parameterized notebooks
Perhaps one of the most exciting things we are doing with Jupyter Notebooks is our development of parameterized notebooks, which allows a user to invisibly execute a notebook along with certain parameters dynamically in a headless fashion. For example, a data scientist could have a notebook with some code in it and then configure certain parameters to dynamically influence how the notebook will behave. Whatever inputs it requires would activate accordingly on an isolated execution container (one that is dedicated to the execution) to produce certain outputs such as visualizations, text, or tables.
Parameterized notebooks offer data scientists three important capabilities that they cannot get from Jupyter Notebooks out of the box:
- The ability to run long-running jobs: Certain tasks that data scientists must accomplish, such as feature transformation at scale (gigabytes to terabytes) or training complex data with large amounts of training data, can be highly time and resource-intensive. Because parameterized notebooks use isolated containers, running jobs that can take anywhere from a few hours to over a week becomes much simpler.
- The ability for data scientists to develop applications that are intelligent, dynamic, and adaptive: When data scientists need applications for visualizing their data, they usually have to rely on UI developers to create them. With parameterized notebooks, data scientists can take advantage of all the power and functionality of Jupyter Notebooks and all its open-source libraries to power dynamic applications without the need for UI developers and back-end engineers. With these platform capabilities, users can employ parameterized notebooks to dynamically power a UI widget with visualizations that are created instantly for immediate actioning.
- The ability to scale notebooks: Data Science Workspace was built with a scheduling and orchestration framework that allows users to automate the training and scoring for their models as new data comes in. Because Jupyter Notebooks is the tool of choice for so many data scientists, we wanted to apply that same scheduling paradigm to notebooks in order to take advantage of the lean way in which they encapsulate an entire machine learning pipeline. Using parameterized notebooks allows data scientists to automate the execution of notebooks on a periodic basis, which is important for running applications at high scale while automatically adapting to new data that comes in.
Challenges we've encountered in our development of Jupyter Notebooks in Data Science Workspace
When working with open source software, staying ahead of development is always a challenge. For example, Jupyter's transition from its classic UI to Jupyter Labs, a web-based UI, required some additional work to ensure our server-side plug-ins would continue to function properly.
Latency is also always a primary concern. For example, the Docker images we presently use creates images that are much larger than normal, which can introduce latency issues (e.g. long download times). To prevent this, we deployed an Azure container registry with every Kubernetes container to ensure that latency due to image size does not interfere with the Adobe Experience Platform user experience.
For data scientists using terabytes of data to develop and train their machine learning models, running their code on a local container with limited resources can quickly lead to performance issues. So, we have also provided the ability within the Data Science Workspace for users to connect directly to a Spark cluster, which doesn't have any resource constraints.
Adobe Experience Platform continues to push the boundaries of what Jupyter Notebooks can do
Adobe is reimagining what Jupyter can be and is pushing the boundaries of the tool to empower data scientists and data engineers using Adobe Experience Platform to build better models that will result in ever-faster time to value. To date, hundreds of researchers have used our Jupyter Notebook extensions and other tools in Data Science Workspace and continue to inform our development of these tools.
In the future, Adobe has plans to explore the use of Jupyter Notebooks for automated feature engineering, feature store, and to continue our development of Jupyter Notebooks as a platform service. And, the work we have done with parameterized notebooks is just part of our vision for extending Jupyter's capabilities for Adobe Experience Platform customers. Our development of Jupyter Notebooks continues with the goal of providing even more innovative and powerful tools for data scientists working with Data Science Workspace.
Experience Jupyter Notebooks in a whole new way in the Adobe Experience Platform Data Science Workspace through a collection of in-depth tutorials. Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Oct 31, 2019