
Accelerating Intelligent Insights with Adobe Experience Platform Data Science Workspace
Authors: Ashok Pancily Poothiyot, Kumar Sangareddi, Pari Sawant, and Jenny Medeiros
This article goes behind-the-curtain to show how Adobe Experience Platform Data Science Workspace uses AI and machine learning to streamline the data-to-insights journey and enables brands to quickly deliver personalized customer experiences.
Today's brands and customers want personalized experiences delivered in real-time. This prioritizes mining big data for insights that deliver meaningful customer interactions. The greatest barrier to insights is refining data, similar to how crude oil must be refined before it is useful.
Skilled data scientists are at the helm of the data-to-insights delivery, but their workflow is hindered by repetitive tasks, overly-complex technology, and scattered data across multiple repositories in different schemas. Data scientists spend 80% of their time organizing data instead of deriving insights from it.
Adobe Experience Platform Data Science Workspace is leading the effort to help enterprises simplify and accelerate their data insights journey. Data Science Workspace leverages artificial intelligence and machine learning to optimize the process of transforming data into actionable insights. This frees data scientists from mundane tasks while returning time to them to empower and creatively deliver personalized, meaningful experiences in real-time to their customers.
Data Science Workspace streamlines data into business value
Data Science Workspace enables enterprises to rapidly create, train, and tune machine learning models using data ingested into the Adobe Experience Platform to make predictions and power intelligent services across any channels (i.e. web, desktop, and mobile apps).
Data Science Workspace draws its power from Adobe Sensei, Adobe's internal ML framework, that leverages AI and ML technology to drive contextual experiences. Initially, this framework was developed for internal use only. We now empower Adobe Experience Platform customers to streamline their data into insights and shorten the time-to-value of their ML models.
Before diving into the details of Adobe Experience Platform Data Science Workspace, here is a brief summary of key terms:
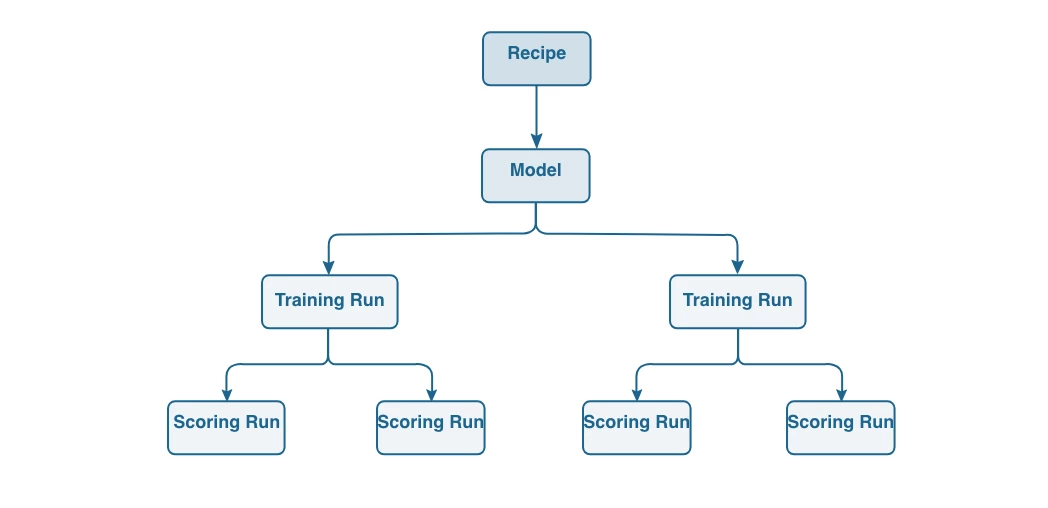
- Recipe: Adobe's term for a model specification. A top-level container for the ML/AI algorithms, processing logic, and configuration required to build a trained model, train it at scale, and help solve a specific business use case.
- Model: An instance of a recipe that is trained using historical data and configurations.
- Trained Model: A model created by the training process. A trained model is ready for scoring and to be published as an intelligent web service.
Additionally, consider the hierarchy of a data scientists' workflow with their models in the following diagram:
Accelerate each step of the data science journey
We designed Adobe Experience Platform Data Science Workspace specifically to provide reliable, easy-to-use, and automated tools to address the data science workflow:
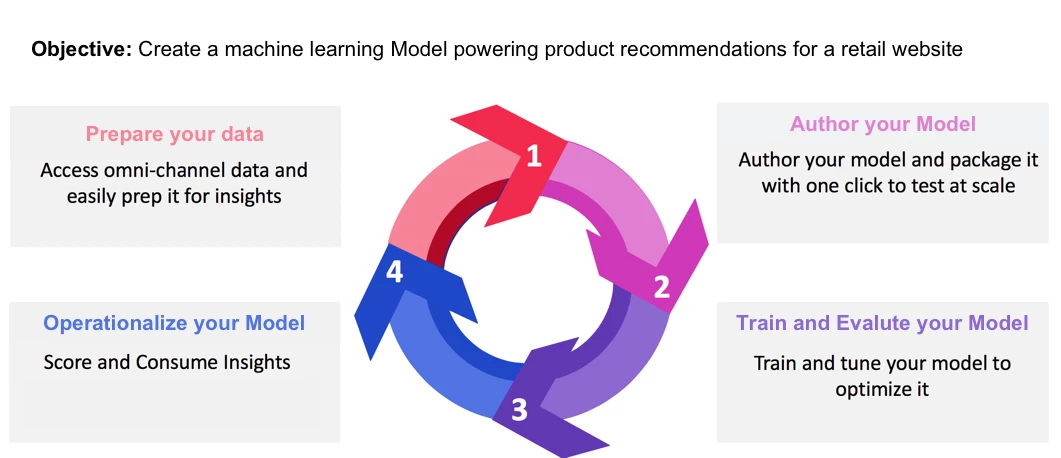
For example, an online retailer looking to deliver personalized offers to its customers during checkout. With Adobe Experience Platform, their cross-channel customer data would already be centralized and standardized into Experience Data Model (XDM) schemas for simplified data preparation.
To author a recipe, Data Science Workspace gives the data scientist three options:
- Choose a pre-built ML recipe tailored to specific business use cases (e.g. Product Recommendations)
- Build a recipe from scratch using Jupyter Notebook
- Import their own recipe from a repository (i.e. GitHub)
Training an ML model is optimized with Data Science Workspace's intelligent experimentation process. A data scientist can create multiple recipe instances (i.e. models) and train them while Data Science Workspace automatically tracks and compares evaluation metrics to highlight the best performing model.
To operationalize the optimized model into an intelligent service, data scientists can click to publish it without writing a single line of code. The intelligent service will then be live and accessible to the digital experience team. As time goes by and new data rolls in, the model can be scheduled to automatically retrain and refine itself to ensure continued efficiency and efficacy.
This is how brands like the online retailer can harness the power of AI and ML to optimize their data science workflow and deliver personalized experiences to their customers sooner.
Behind the scenes: Architecture and design
The vision for Adobe Experience Platform Data Science Workspace was to enable both technical and non-technical personas to derive insights from data using AI and ML. Subsequently, we focused on two particular users: the code-savvy data scientist and the citizen data scientist.
The following diagram provides a high-level architectural overview of the components used for each stage of the data scientists workflow:
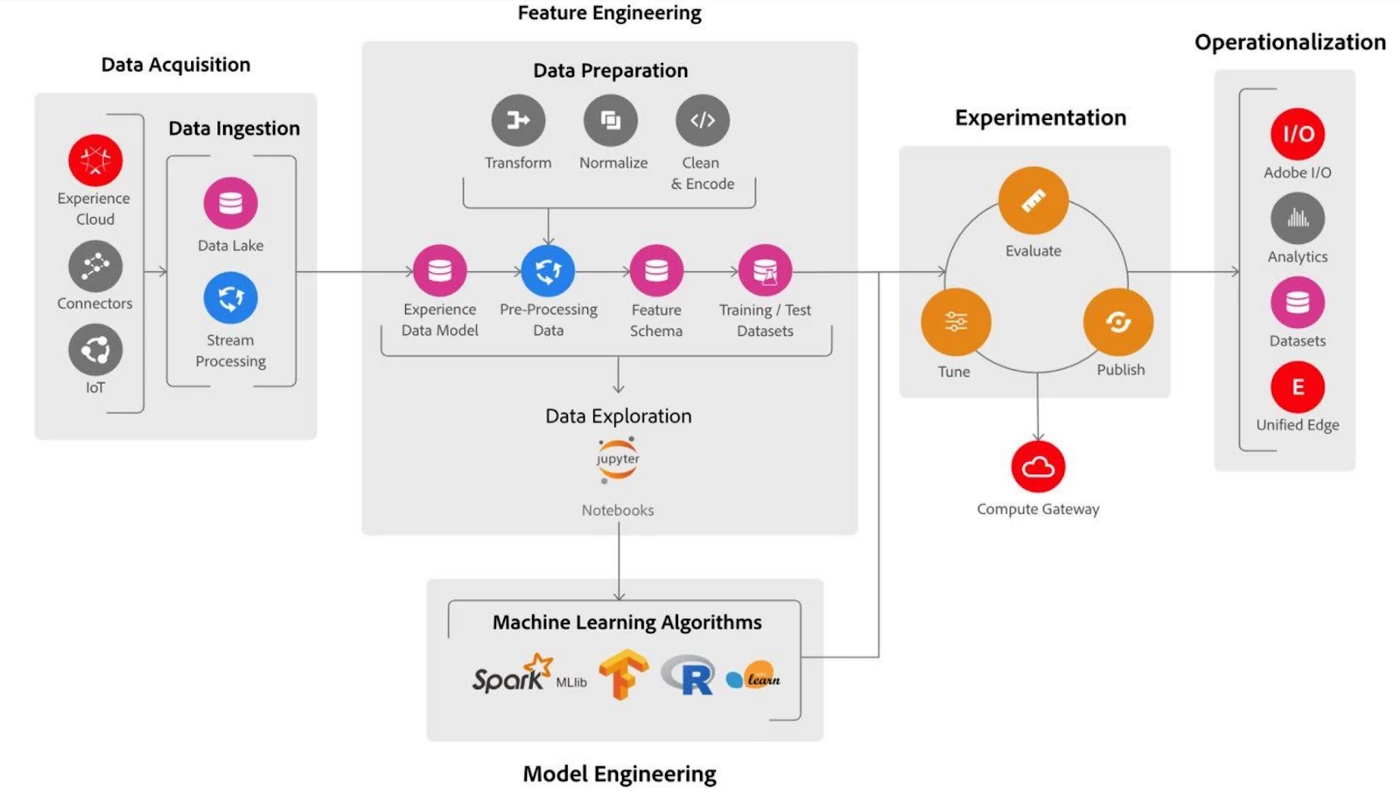
Data acquisition
Data is ingested into the Adobe Experience Platform in two modes:
- Batch: Batches of data can be ingested using Connectors from other Adobe Experience Cloud products such as Adobe Analytics, as well as from external CRM applications such as Salesforce and Microsoft Dynamics.
- Streaming: This enables users to send data from the client and server-side devices in real-time.
To ensure clean, consistent data within Adobe Experience Platform, all the data is automatically transformed into Adobe's standardized XDM schemas.
Data preparation
The first step to building a model is exploring the data and extracting features (predictor variables) to accurately train it. This process is called “Feature Engineering”.
Since data scientists spend most of their time on this stage, we baked the following time-saving components into our Feature Engineering framework:
- Feature Pipelines to allow the creation and reuse of Feature Pipeline entities (Scala Spark and PySpark).
- Data Quality to auto-compute scores indicating data quality.
- Auto-Featurizer to automatically determine the best combination of features for an ML model.
- Integrated Jupyter Notebooks for iterative development of feature pipelines.
- Integration with Query Service for SQL based transformations
- ML Featurizer SDK Utility Library for generating the most commonly used features.
Data exploration
During our initial survey, we discovered that the open-source system, Jupyter Notebooks, was the primary tool data scientists used to explore the data and build models.
Simply put, the Jupyter Notebook provides a dedicated container with built-in data visualization and ML libraries for data exploration and model building. For Data Science Workspace, we built a customized version of Jupyter integrated within Adobe Experience Platform. We also created out-of-the-box notebook templates (see image below) for the citizen data scientist to quickly understand and visualize their XDM data.
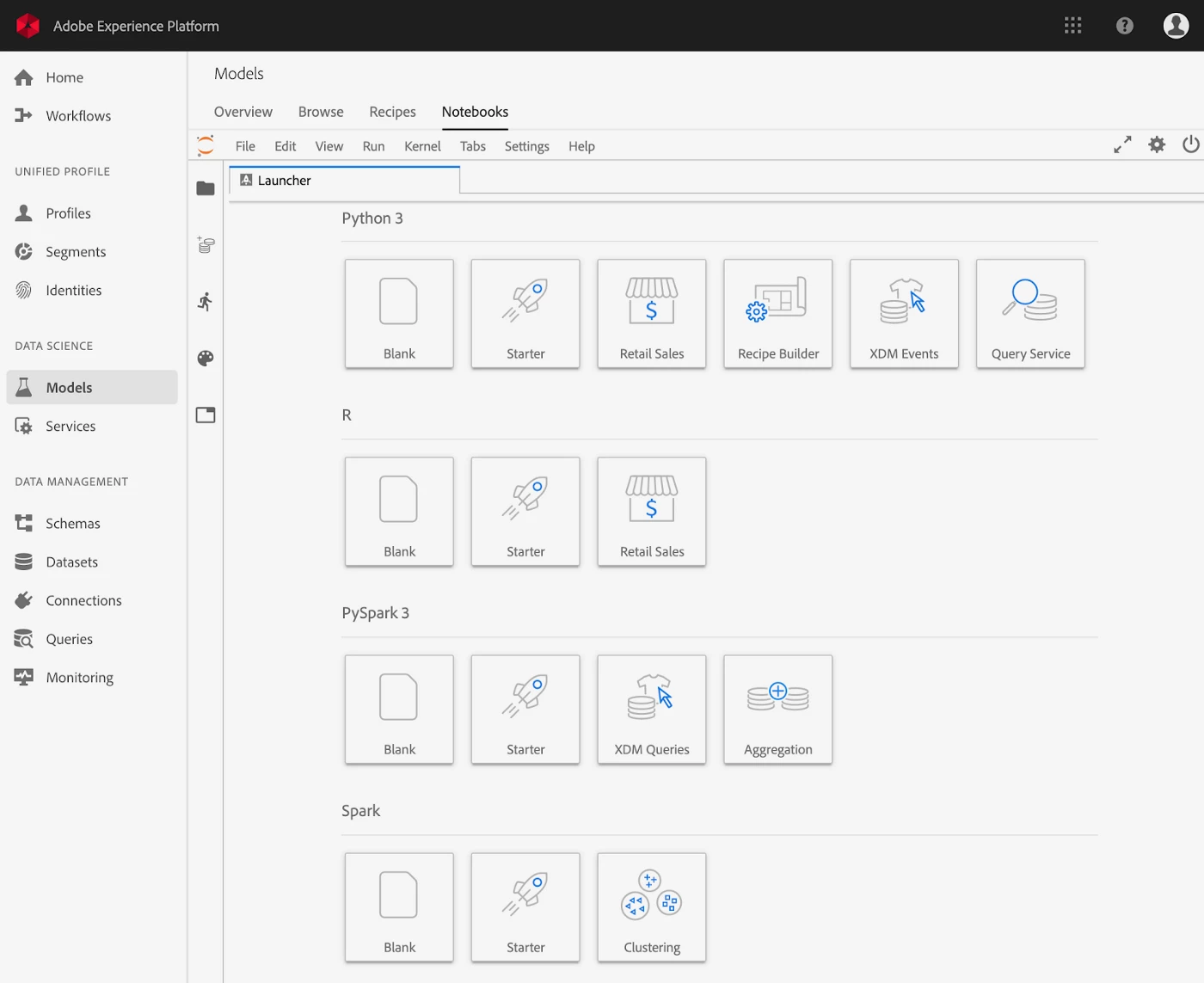
We were an early adopter of JupyterHub, an open-source product to add multi-user support for Jupyter. However, to facilitate the orchestration and management of these Jupyter containers that cater to enterprise users at scale, we built our own Jupyter gateway service. Furthermore, we integrated JupyterLab, the next generation UI for Jupyter, into Data Science Workspace.
Model engineering
We knew that data scientists wanted increased efficiency and flexibility while authoring a recipe, so we provided three options: create, import, or use a pre-built recipe created by Adobe and partners.
For customers creating or importing their own recipe, we conceived the concept of machine learning runtimes. This standardizes the authoring of recipes, allowing data scientists to focus on the core algorithm for model building and abstract the details of accessing data, compute, model management, and model evaluation. These runtimes are available for model development in Python/TensorFlow, R, PySpark, and Scala.
Experimentation
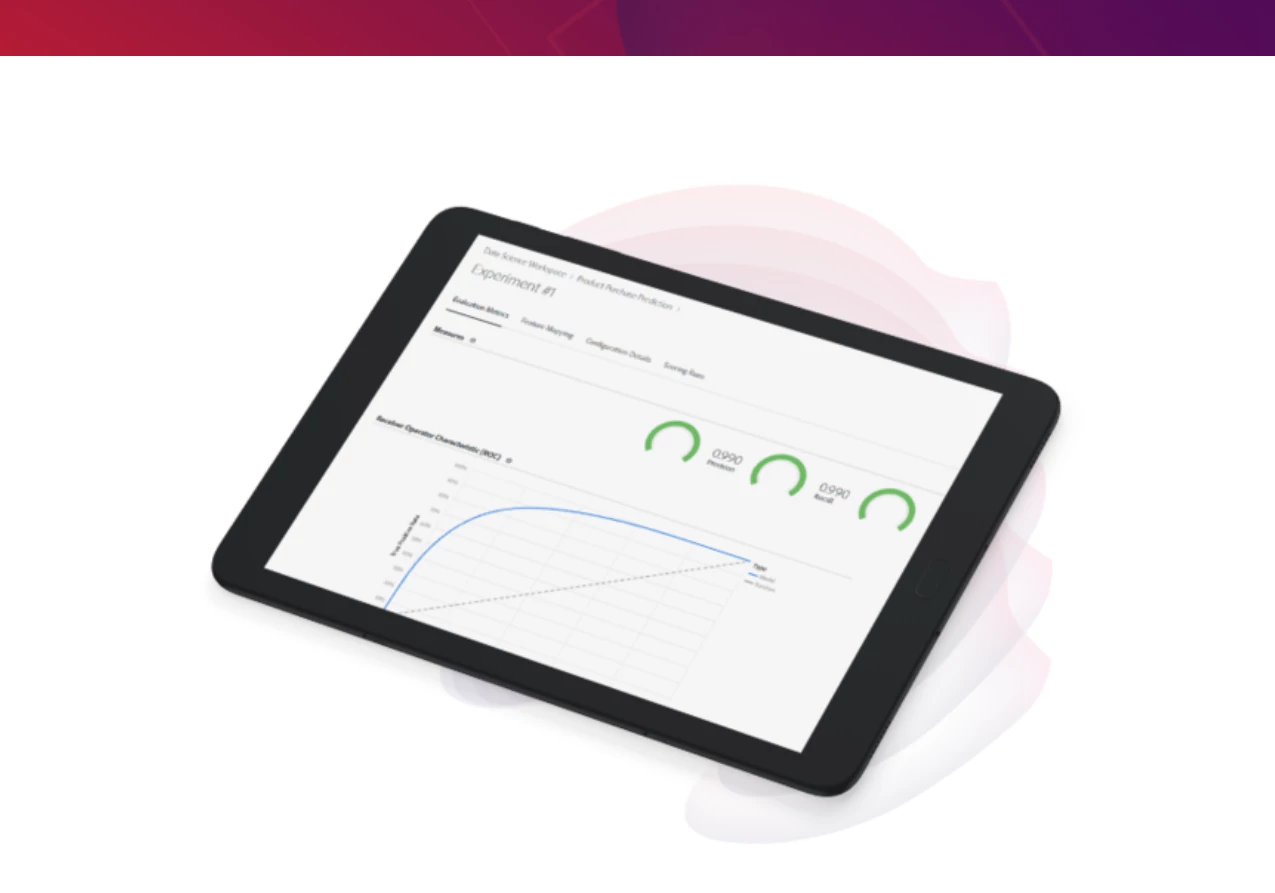
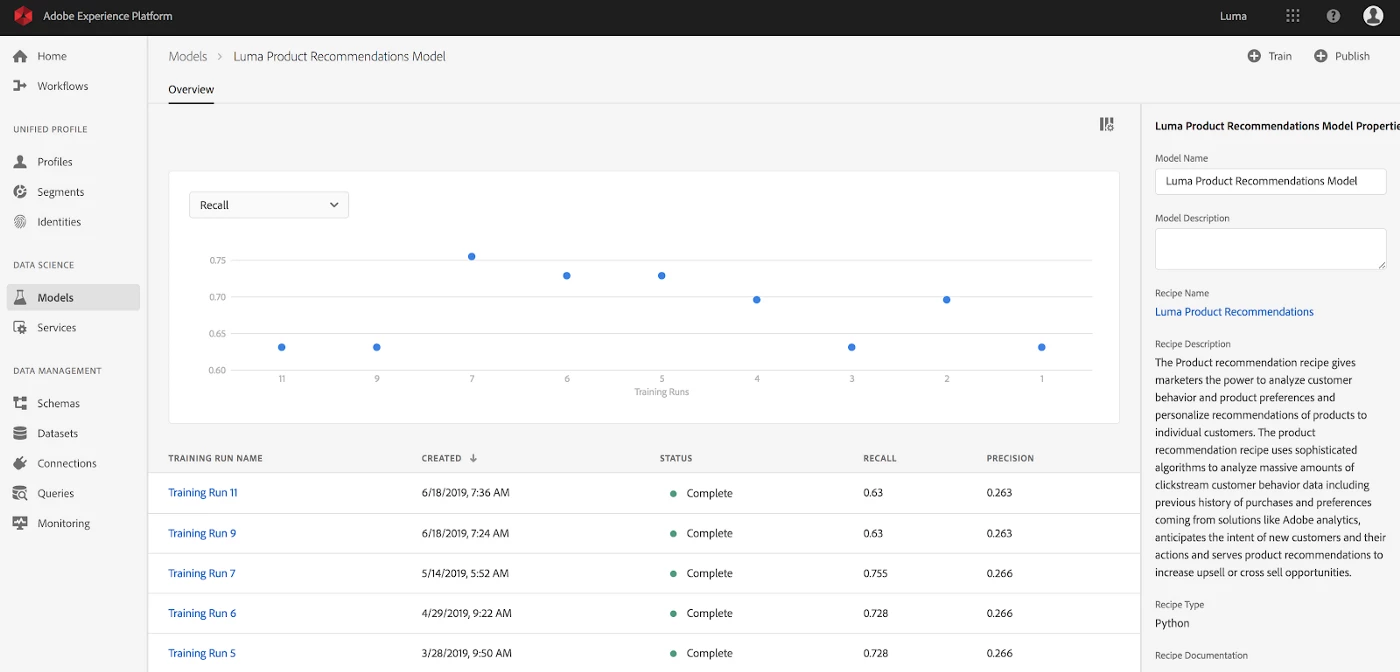
In this phase, data scientists are iterating on their model development by changing different configuration parameters, such as the hyperparameters, which are features used for training. They must also keep track of the different combinations and model versions to operationalize the best performing model.
To support this process we created a model insights framework, which provides an extensible solution, a dynamic interface for data scientists to instantly visualize and compare model evaluation metrics across multiple test runs. See example below:
Operationalization
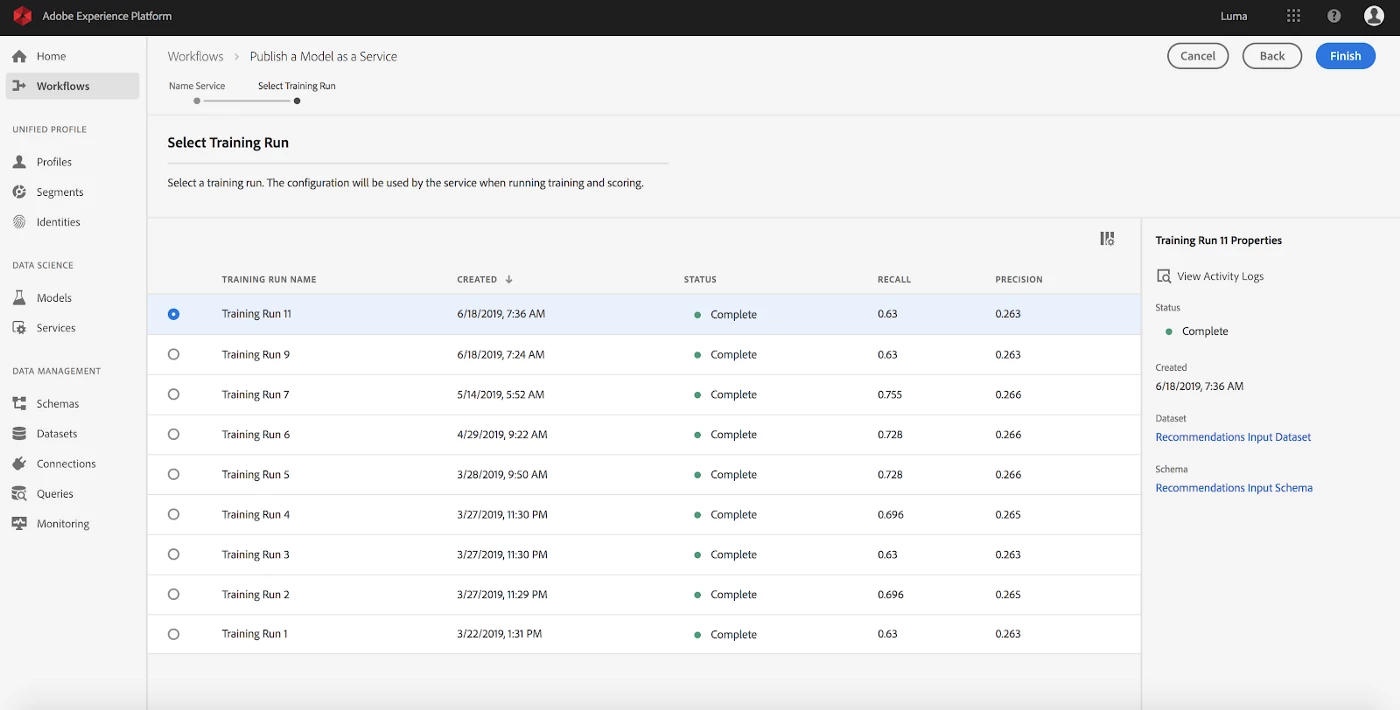
Once the data scientist has evaluated and optimized their model, they can deploy it in just a few clicks as an intelligent service through Adobe I/O, our API gateway for external developers and partners.
Finally, to help data scientists continue refining their models as new data rolls in, we automated the ML pipelines so models are re-trained based on new data. The intelligent service then automatically uses the updated models for prediction. These predicted scores can also be funneled into the Real-Time Customer Profile, seamlessly enriching the 360-degree view of the end-users.
Challenges
Allowing data scientists to BYOC (bring your own code) posed two significant challenges from a security standpoint: data isolation and compute isolation.
For data isolation, it became clear that we needed to build an architecture secure and isolated enough so one customer can't access another customer's data. For compute isolation, we wanted to prevent one customer's compute jobs from impacting the resources available for another customer's jobs.
We achieved both by provisioning isolated storage and compute at the cloud infrastructure layer, as well as using access templates that authorized only authenticated users belonging to the customer to the customer's data.
Data Science Workspace puts the power of AI into the hands of enterprise data scientists
For the first time, enterprises can benefit from Adobe's powerful machine learning and AI capabilities to deliver increasingly personalized customer experiences. For enterprise data scientists, these capabilities allow them to optimize each step of their workflow and focus on the high-value tasks they care about.
The most notable features in Data Science Workspace include the pre-built Jupyter Notebook templates, which provide quick insights from complex schemas and a deeper understanding of customer profiles; the ML pipelines that automatically reflect new data for continued refinement, and our “one-click packaging” feature that instantly turns a notebook into an operationalized model with no coding required.
As with every innovation across Adobe products, the sophisticated and easy-to-use features in Data Science Workspace were inspired through the valuable feedback from our early adopter customers. Within Adobe, our data scientists continue to test and inspire improvements as they leverage Data Science Workspace to power internal AI/ML use cases.
For example: Delivering personalized recommendations to attendees during an internal developer conference.
To learn more, Data Science Workspace is equipped with a collection of in-depth tutorials, along with a detailed walkthrough of a data scientist's workflow as they solve specific business problems. To learn more about Adobe Experience Platform Data Science Workspace, its features, and potential use cases, visit us here.
Originally published: Aug 15, 2019