
Redesigning Siphon Stream for Streamlined Data Processing (Part 1)
Authors: Costin Ochescu, Ciprian Barbieru, Cornel Creanga, and Jenny Medeiros
This post describes how we proactively improved the cost and efficiency of data processing within Adobe Experience Platform by redesigning one of its key data processing services: Siphon Stream. Check out Part 2 here.
Adobe Experience Platform is home to an increasing number of customers who rely on its ability to process tremendous amounts of data in real-time.
To maintain the pace that new and existing customers expect, we set out to proactively improve Siphon Stream, a key component within Adobe Experience Platform that is responsible for much of the streamed data processing.
This post details the challenge we faced, thought processes, and subsequent solutions that ultimately tripled our application’s performance and greatly reduced operational costs.
What is Siphon Stream?
Siphon Stream is a component within Adobe Experience Platform responsible for taking the streaming data sent by Adobe solutions (i.e. Adobe Audience Manager) through the Adobe Experience Platform Pipeline, and importing it into the Data Lake.
This service is built using Spark Streaming, a distributed and scalable data processing engine with support for writing Parquet files, and connectors for Apache Kafka and Azure Data Lake (ADL). Spark is also the default data processing engine for Adobe Experience Platform, partly due to its rich processing semantics.
One of our primary objectives for Siphon Stream is to comfortably process billions of inbound data per day, akin to the ingestion rate of Adobe Analytics and Adobe Audience Manager, to meet the growing demands of current and upcoming customers.
The challenges
For context on the challenges we were working to solve, the figure below shows the architecture for Adobe Experience Platform Data Lake.
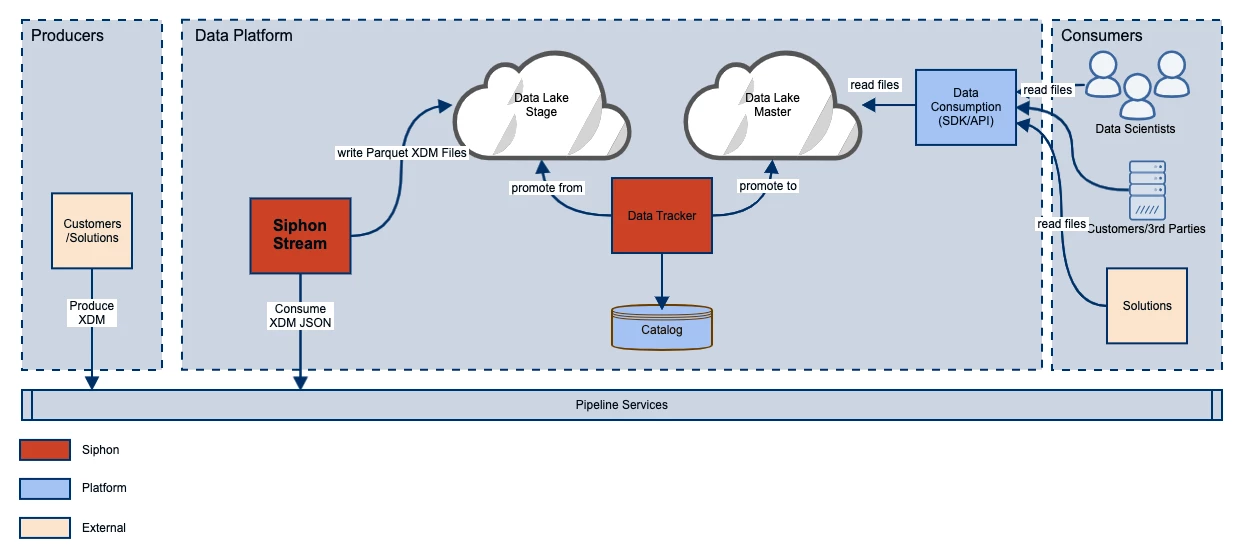
This architecture can be briefly explained in three main stages:
Producers: In this first stage, the customers or external solutions generate an Experience Data Model (XDM) message. The messages can be events (e.g. clicking on a webpage), CRM data, or dimensional data. These streams of messages then enter the Adobe Experience Platform Pipeline.
Data Platform: Here, Siphon Stream consumes the XDM JSON and writes it as Parquet XDM files into the staging area of the customer’s own provisioned ADL. This acts as a first stop of the ingestion process before the Data Tracker shuffles and masters the data into a location that customers have access to.
Consumers: In this final stage, customers can pull the data using Adobe Experience Platform SDKs and APIs to train their machine learning models, run SQL queries, build dashboards and reports, hydrate the Unified Profile store, and run audience segmentations.
With this in mind, we can appreciate the following challenges:
- Ingress is in JSON or JSON Smile format — egress is in Parquet: Writing in a columnar storage format requires a micro-batching mechanism to transform row storage into column-oriented storage.
- Ingress Kafka topics are multi-tenant while the egress is single-tenant: This means that each tenant has its own data-lake with different write credentials.
- Ingress is not only multi-tenant, but multi-dataset and multi-schema: Inbound messages need to be persisted to different tables and, even within the same tenant, we can have multiple tables where each has its own schema.
- Minimize fragmentation on the data lake: We needed to reduce the number of files since too many small files lead to fragmentation and poor performance while reading.
Our approach
Solving these challenges led our team through many hours of brainstorming and experimentation. Here are our findings, solutions, and initial results.
Defining the key performance metric (KPI)
Our primary objective was to streamline the ingestion processes at the lowest possible cost. To measure this achievement, we needed to define a framework that could measure any performance improvements/losses induced by specific code changes.
To begin, we identified a key performance metric: TPC (Throughput per core), which allows us to measure efficiency, performance, and scalability.
ThroughputPerCore = Number of messages processed by each CPU available in the cluster in each second
Initially, our TPC was around 500 msgs/second/core for Spark micro-batches spanning one tenant with one table, and approximately 10 msgs/second/core for micro-batches containing data from 5 tenants with 10 tables each.
These numbers reveal that the TPC drastically drops as the number of tables increases, significantly slowing down overall data processing.
Identifying key pain points
With these numbers in hand, we dug into the application and identified three pain points that would later become our objectives:
- Reduce message passes: Passing through all the received messages to select and save each dataset sequentially is far too inefficient.
- Reduce unnecessary data shuffles: Since we are reducing the number of message passes, we can also introduce partitioning to ensure the data in a certain Spark partition would not need to be reshuffled until data saving.
- Avoid hot partitions: Not all datasets are the same size, so we must divide them in a way that avoids hot partitions, which would make data saving even more time-consuming and potentially affect the quality of service for other tenants.
Drafting solutions
To tackle our first two challenges (reduce message passing and data shuffling), we drafted the following partitioner:
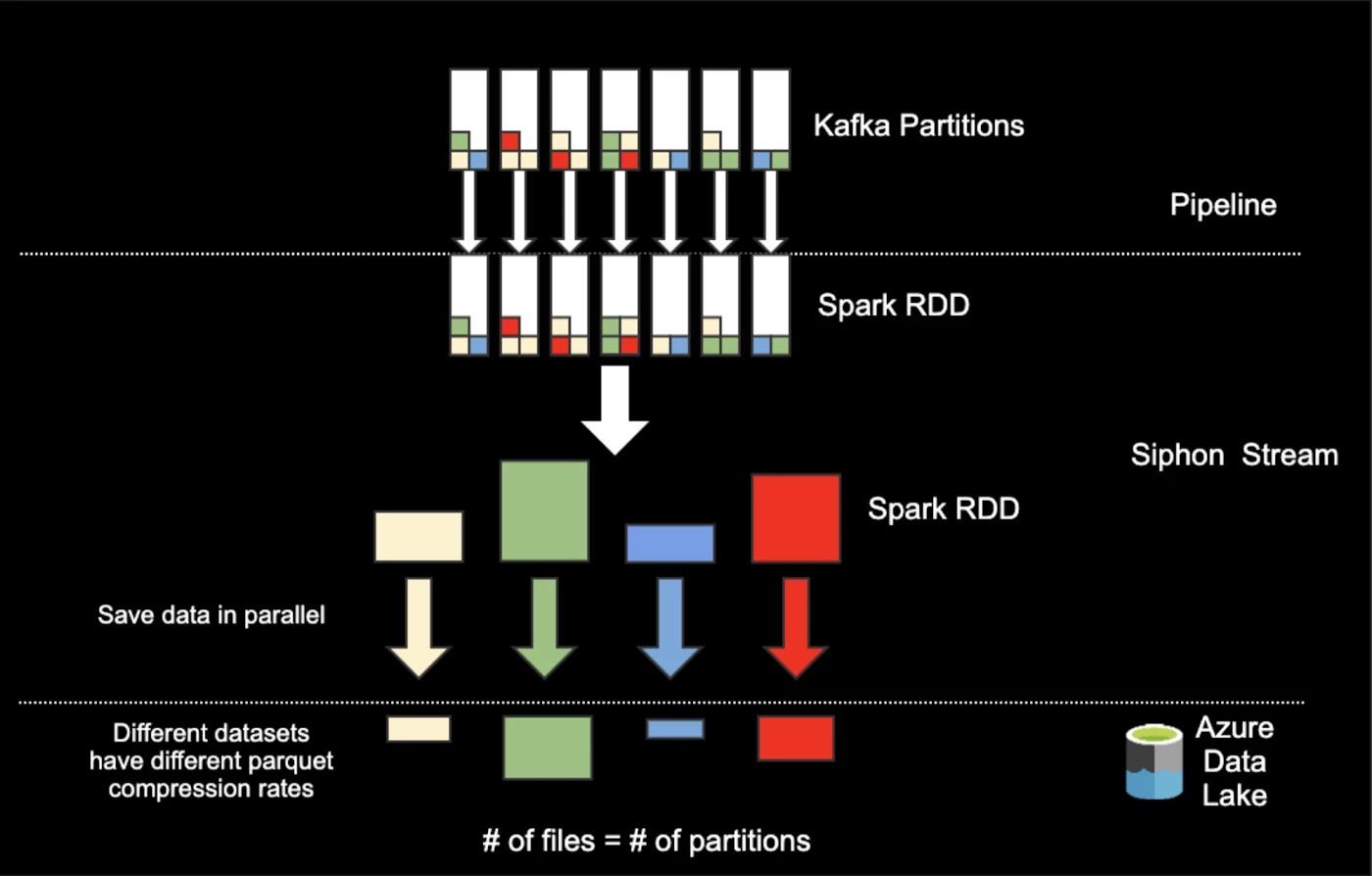
As shown in the figure above, the first iteration of the partitioner starts by reading data from Kafka partitions and storing it in Spark Resilient Distributed Datasets (RDDs). Then, it partitions the data, almost naively, simply by the table and saves the data from each partition in ADL.
With this solution we restrict message shuffling and passing by processing each message twice: once for partitioning, and again for saving it in ADL.
We should note that by using RDDs we are able to process each partition independently and save the data using different ADL credentials. This means that we can now save each data partition in parallel to potentially different output locations.
The initial implementation of this partitioner had one drawback: tables that have higher throughput can create hotspots — meaning some partitions will be larger than others. To avoid hot partitions, we further improved the partitioner to take into account the throughput of data for each table.
This led us to the following solution:
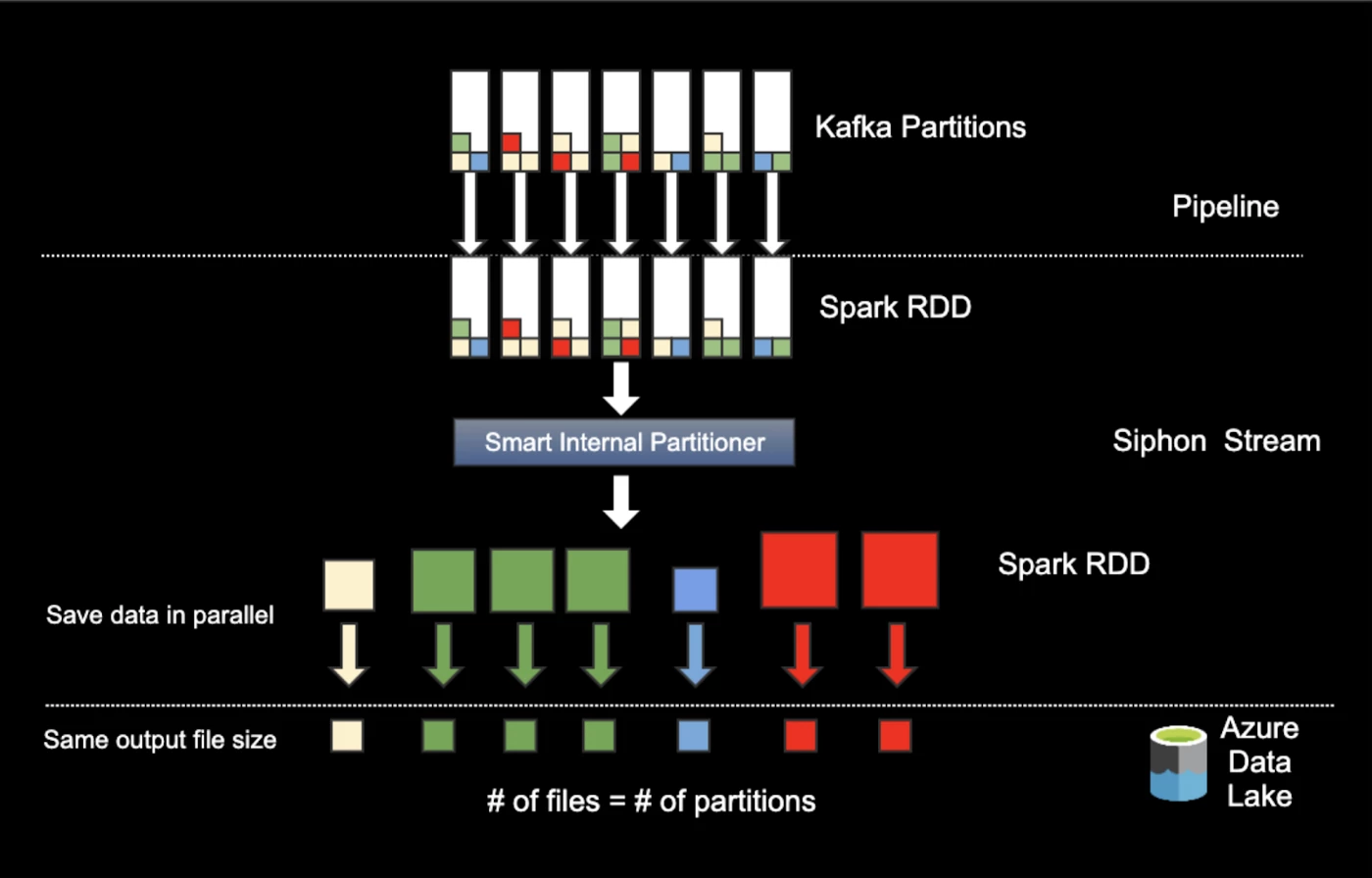
To put it simply, this improved internal partitioner takes the partitions from Spark RDD, intelligently compresses the data and outputs equally-sized files into Azure Data Lake.
Initial improvements
While these solutions are still in the early stages, we have already noticed significant improvements in data processing performance.
Before redesigning Siphon Stream, our average TPC was around 110 msgs/second using production data. We initially tested the instance using synthetic data but found that these results were misleading, so we tested the instance again using production-like data. This time, we achieved realistic numbers that can be seen in the following figure:
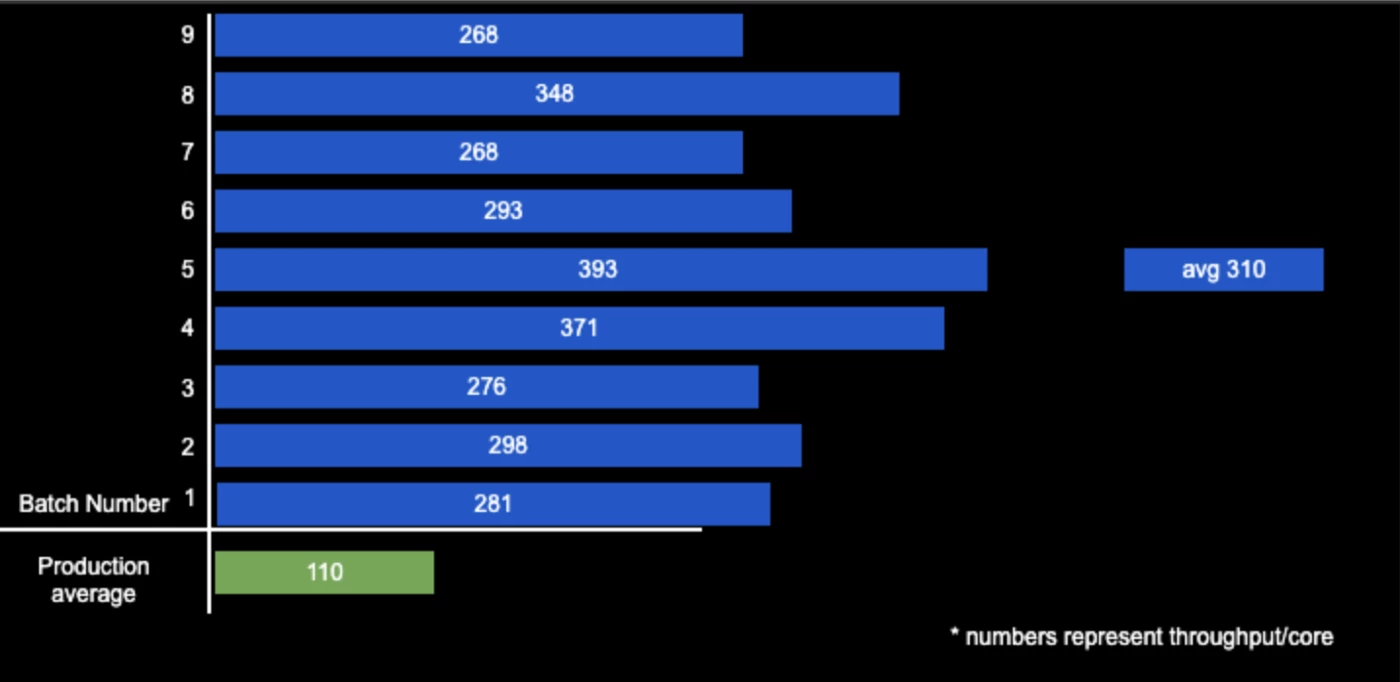
The graph above shows that our efforts have bumped the average TPC from 110 msgs/second to 310 msgs/second on our busiest instance — a 3x improvement.
Additionally, we reduced data shuffles to just one and avoided hot partitions with an intelligent algorithm that evenly distributes data across partitions. This algorithm is now in the process of being patented.
What’s next for Siphon Stream?
Our next focus is on improving low-level tasks, including the performance of serialization/deserialization of messages in memory, JSON parsing, memory caching, and further reducing data shuffling time.
In the meantime, we are left with the key learning of continuously measuring performance and looking for areas of improvement. Another takeaway is to always use production-like data rather than synthetic data for more realistic results.
With plenty of improvements already making a difference in Adobe Experience Platform, we aim to continue polishing Siphon Stream and ensuring that streaming ingestion remains a seamless experience for our customers.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: April 2, 2020