
(Part 2) Redesigning Siphon Stream for Streamlined Data Processing in Adobe Experience Platform
Authors: Costin Ochescu, Ciprian Barbieru, Corneliu Vasile Creanga, and Jenny Medeiros
This is the second of a two-part series on how we redesigned Siphon Stream, a key data processing service within Adobe Experience Platform, to optimize costs and efficiency. In this post, we dive into the architectural improvements that dramatically enhanced Siphon Stream’s performance. Make sure to read part one here.
Siphon Stream is an essential component within Adobe Experience Platform that channels data streaming in from Adobe solutions (e.g. Adobe Audience Manager) through the Adobe Experience Platform Pipeline and into the data lake.
With billions of inbound data running through the application every day, we needed to find new ways to improve Siphon Stream’s processing capacity while cutting down on operational costs.
In our previous post: Redesigning Siphon Stream for Streamlined Data Processing, we described the approach that led to a 3x improvement in performance. This follow-up post goes under the hood to describe the architectural changes that made this achievement possible.
Small Spark improvements = big gains
As a brief reminder, Siphon Stream was built using Spark Streaming, a distributed and scalable data processing engine with support for writing Parquet files, and connectors for Apache Kafka and Azure Data Lake (ADL).
To begin optimizing data processing in Adobe Experience Platform, we focused on the following Spark improvements:
- Minimize the Resilient Distributed Datasets (RDD) size and persistence time.
- Optimize serialization/deserialization.
- Improve the performance of parsing algorithms.
Below, we will dive into each of these improvements and explain the “small code changes” that enhanced our data processing performance from ~300 msg/second per core to ~1000 msg/second per core — while lowering costs.
Minimizing the RDD’s size and persistence time
Currently, we have two Spark actions in our core data flow:
- Grouping the data per organization/dataset/schema
- Saving the data in Microsoft ADSL per organization
Initially, the RDD was re-computed for each action from scratch, which resulted in expensive JSON parsing and merging. But we were unable to persist the RDD (and prevent the recomputation) because serializing the raw RDD required more memory than we had on our cluster.
To optimize the RDD we set out to minimize the amount of unnecessary JSON data to be saved by caching the RDDs used in multiple actions. For this, we hatched the following objectives:
- Save the data in serialized form: rdd.persist(StorageLevel.MEMORY_ONLY_SER) instead of storageLevel.MEMORY_ONLY.
- Replace the default serialization mechanism by implementing custom writeObject/readObject methods for each serialized class.
- Convert plain JSON messages to JSON Smile format to reduce the space needed to store data streaming from Adobe solutions (e.g. Adobe Analytics, Adobe Audience Manager), as well as speed up serialization/deserialization time.
After applying these optimizations to our application, we successfully filtered out superfluous data while retaining what we needed in the RDD (e.g. JSON messages, metrics). Ultimately, these improvements resulted in an 8x reduction in the RDD’s size and persistence time.
Optimizing serialization/deserialization
Like most developers, we initially employed the default Java serialization mechanism. This algorithm was built in 1997 and even Oracle itself has described it as a “horrible mistake.” Before long, we switched to a more efficient and user-friendly serialization framework called Kryo.
Although enabling this third-party framework in Siphon Stream came with its own challenges. For instance, we would notice issues in our serialization code (like missing fields) and discover that the RDD had not persisted at all. With about 30 classes in our domain model and with no clues in our logs, issues like these became too time-consuming.
In the end, we implemented a custom (asymmetric) approach to seamlessly save the RDD with memory-only serialization and dramatically reduce the size needed to store the data.
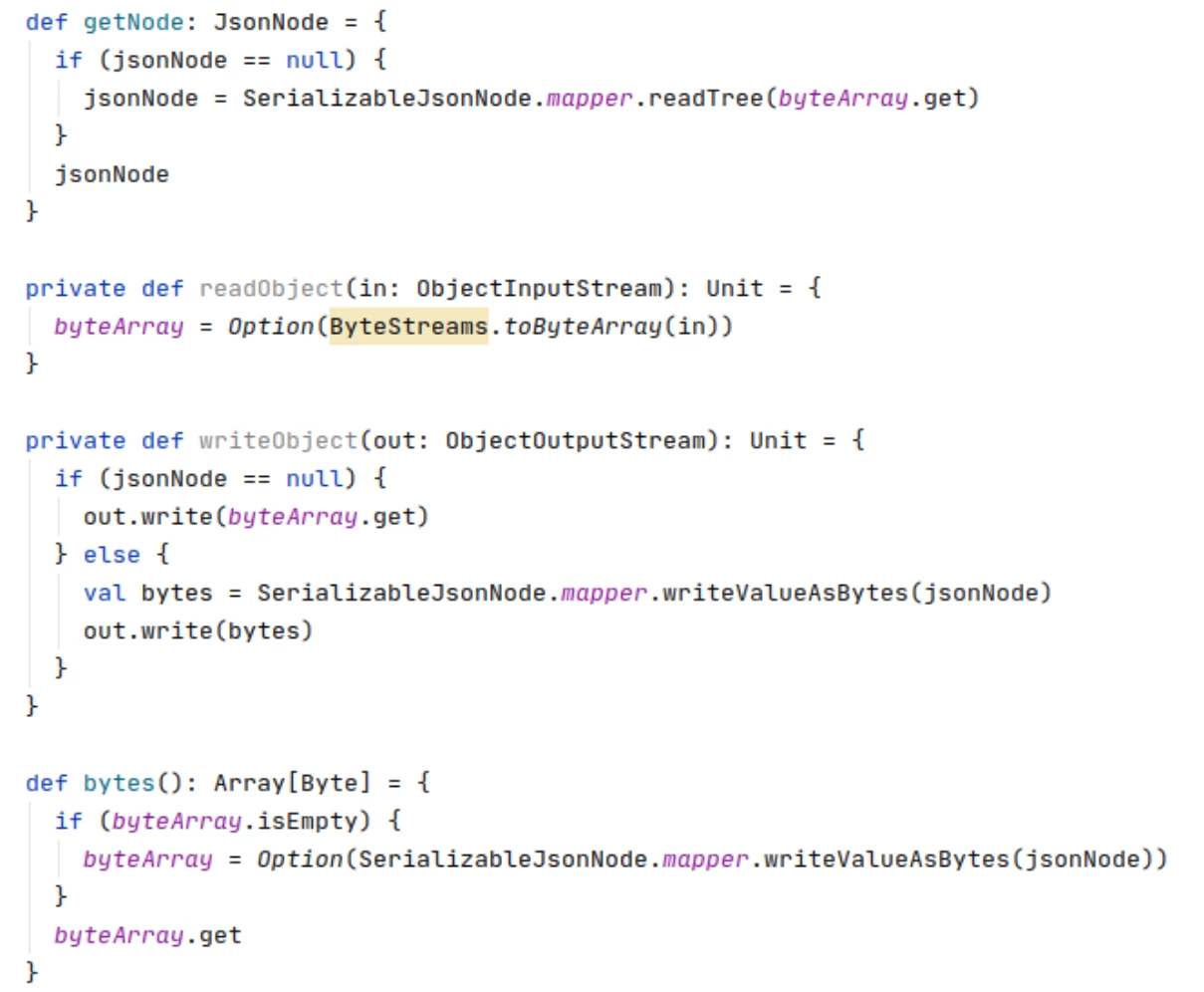
By “asymmetric” we mean that on serialization the code changes from JSON nodes to a byte array, whereas on deserialization we read the array and build the JSON nodes on demand (i.e. lazy loading). This approach essentially speeds up serialization/deserialization by removing a transformation cycle.
For a more technical explanation, consider the following (simplified) structure of our main RDD:
(shard: Shard, jsonNodeBody: Array[Byte], schema: JsonSchema)
The first Spark action groups the data by shard and computes the JSON schema for each group. The second action only needs the body-related data, so we made the readObject “smart” in that it only reads the serialized body into memory without constructing the actual schema nodes.
Below is an example code snippet showing how readObject and writeObject can be structured in an asymmetric approach:
Improving parsing performance
Customer events (e.g. clicking on an ad) enter Adobe Experience Platform as Experience Data Model (XDM) messages in JSON format, which Siphon Stream consumes and writes as Parquet XDM files into the staging area of the customer’s provisioned data lake.
Considering that single Parquet file generation cannot be parallelized, we had to optimize each CPU core workload as much as possible. Here is what we did:
Build our own parser
To write the JSON into Parquet format, we first needed to convert our JSON objects into SparkSQL Rows. What we found, however, was that the method converting our JSON sets to Parquet was spending 66% of the time on building SparkSQL Rows and only 33% on actual Parquet generation.
With the standard JacksonParser proving unsuccessful, we opted to use it as the base for our own custom parser. This decision was based on a few good reasons:
- We needed to parse the JSON messages in the new JSON Smile format, which JacksonParse does not handle.
- JacksonParser was slow to convert timestamps that did not fit the default format. Since our timestamps do not have a fixed format and each core parses tens of millions of timestamps, this conversion caused a significant delay in performance.
- We had to use an internal cache to handle duplicates in the JSON data to avoid wasting time on multiple parsing.
Using our own parser, we managed to upgrade the method so that it spends only 20% of its time building SparkSQL Rows and a more appropriate 80% on Parquet generation.
Infer the schema more efficiently with a custom algorithm
When writing the JSON messages into Parquet format, we begin by detecting the schema we are going to use when saving to the customer’s data lake. The problem is that this schema is defined by the customer and can be very large — sometimes with properties extending into the thousands.
The generic Spark inference algorithm was not built to support our use case and would not have been able to efficiently process our XDM schema. Our solution was to write our own inference algorithm capable of seamlessly computing the schema associated with potentially tens of millions of JSON messages.
With this custom approach, we can also compute the schema and process the JSON files in a single step, further improving our application’s performance.
Reducing the number of temporary objects
Upon further inspection, we realized that the code would sometimes use immutable structures in counterproductive ways, such as recreating the structures entirely in each mutable operation. So, we changed our internal structures from immutable to mutable to save on the resources that were needlessly being used to recreate the structures.
After this optimization, along with all those mentioned above, we managed to jumpstart Siphon Stream’s performance from just ~300 msg/second per core to ~1000 msg/second per core — an improvement of over 100%.
General recommendations to improve JSON processing
While not directly related to Siphon Stream, we want to share a few general improvements that we picked up on the way. These may come in handy for any application that handles JSON events or streaming.
- Always reuse heavy objects like ObjectMapper or JacksonFactory since they build many internal caches that can be reused instead of rebuilt.
- Avoid strings when working with JSON and use low-level data types whenever possible. Most major parsers are able to work with raw bytes, sparing you from creating intermediate objects and burning through resources.
- Use the JacksonStreaming API to optimize computational costs when you don’t need to read all of the JSON data into memory. In our case, the data used for filtering messages received from Apache Kafka is less than 1KB and lives in the header node. As a result, we only read the header and, if that meets our criteria, we then read the rest of the body (between 2–150KB).
- Use JSON Smile (on both serialization and deserialization) especially if you know that some of the data from the messages is similar or redundant.
Learnings and next steps
Our journey to optimize Siphon Stream has been a winding one with many lessons learned that we will continue to implement moving forward.
First, we learned that it is essential to understand our input data and edge cases. For example, we had JSON nodes with hundreds of sub-nodes but did not consider this when we wrote our initial schema, resulting in an unimpressively slow algorithm. Eventually, we had to write a Spark application to extract detailed statistics from our input data, such as the level of redundancy, finding extreme cases, and testing various compressions and combinations.
Second, we realized that profiling directly into a Spark-deployed application is more time-consuming (particularly for developers) since more time is needed to deploy, test, find issues and gather results in a distributed environment. After testing our custom parser in a local standalone application, we can safely say that profiling in a simpler environment can save many hours of effort.
Lastly, and possibly the most important lesson of all, is that major decisions should always be backed by data or by testing the hypothesis in a controlled environment. It can be tempting to rely on experience and educated guesses but data will always be more accurate when working with complex systems.
As for future plans, we intend on investigating the value of using Single Instruction Multiple Data (SIMD) for our JSON parsing to enable parallel data processing. We also intend on adding autoscaling to Siphon Stream to further optimize costs — a subject for another blog post, perhaps.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Resources
- (Part 1) Redesigning Siphon Stream for Streamlined Data Processing
- Spark: https://spark.apache.org/
- JSON: https://json-schema.org/
- JSON Smile: https://github.com/FasterXML/smile-format-specification
- Parquet: https://parquet.apache.org/
- Jackson documentation: https://github.com/FasterXML/jackson-docs/wiki/Presentation:-Jackson-Performance
Originally published: May 7, 2020