
How Adobe Experience Platform Pipeline Became the Cornerstone of In-Flight Processing for Adobe
Authors: Anshuman Nangia, Anand Phatak, Nipun Nair, and Douglas Paton
This blog post continues our look at how Pipeline powers the Adobe Experience Platform. We break down the components and look at how Pipeline is being used for data processing in-flight.
Our team thinks of Adobe Experience Platform Pipeline, a Kafka-based message bus, as a “data power grid” for Adobe. It is a critical piece of our infrastructure, which runs across 14 clusters covering AWS, Azure, and our private data centers.
Going back about five years, most of the communication between services at Adobe was point-to-point. Unsurprisingly, this pattern became untenable very quickly as teams started to break down existing monolithic systems and the number of services started to grow. Configuration management burdens grew exponentially and became unmanageable to the point where “integration” horror stories became commonplace.
Adobe Experience Platform Pipeline project started with the goal of making it easier to integrate services by breaking down Adobe’s internal data silos and simplifying inter-service communication. Some amount of basic in-flight processing of data has always been done on Pipeline because of its Adobe-specific API semantics but more complex processing requirements are starting to come into focus now as the speed of delivery and activation become key differentiators for Adobe Experience Platform Customer Data Platform.
In our last post, we described how Pipeline has delivered on this promise and evolved in other interesting ways. This time, we’ll dig deeper into how Pipeline is being used for in-flight data processing adding support for data transformations, enrichment, filtering, and splitting or joining of streams of data. We’ll highlight some ways Pipeline is allowing our customers, and Adobe itself, to move faster.
Adobe Experience Platform Pipeline components
First, let’s have a quick look at the different components that come together under Pipeline.
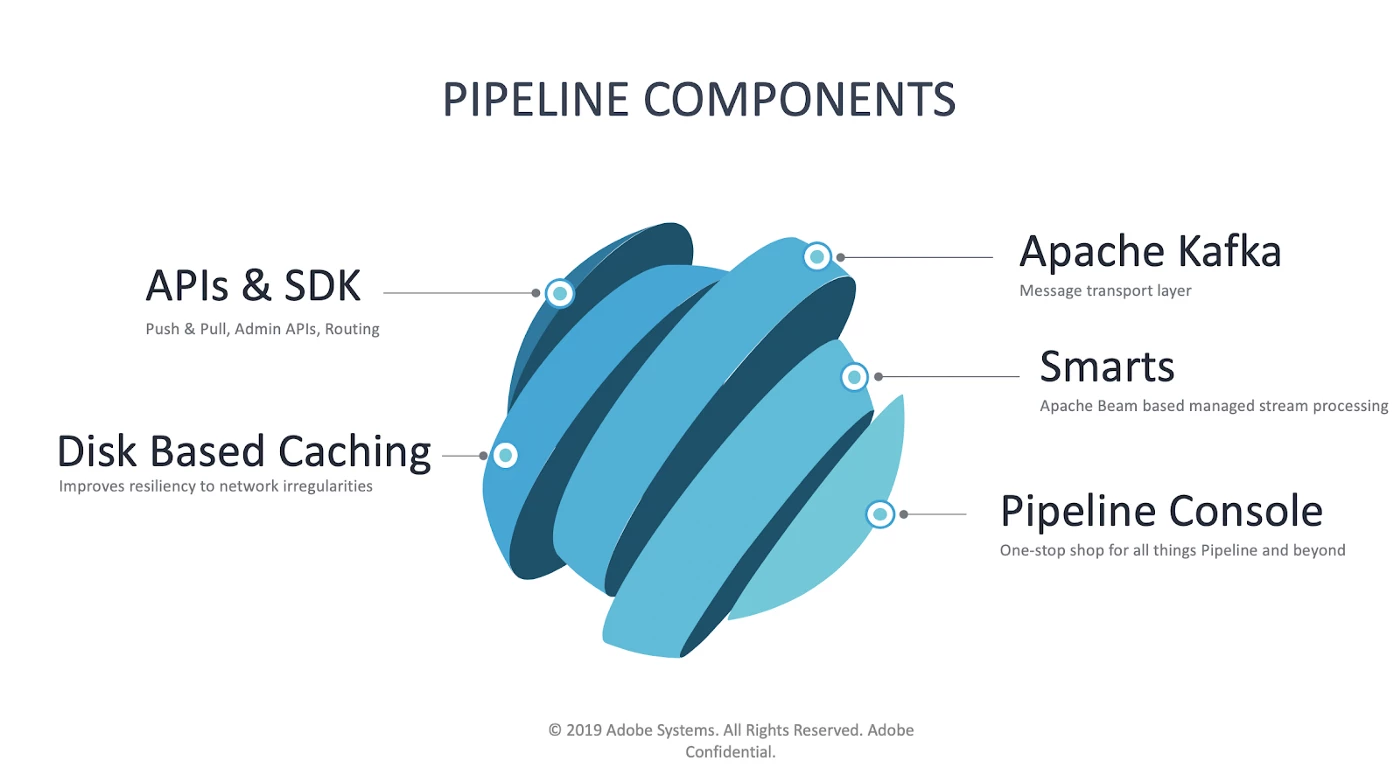
APIs and SDK
Adobe Experience Platform Pipeline has an API and SDK surface area that clients interact with. It supports push and pull semantics for different types of workloads to provide administrators APIs to manage the lifecycle of topics. This layer also supports Adobe-specific metadata around access control, how messages are routed across various data centers, and topic ownership.
Disk-based caching
At the core of Pipeline is Apache Kafka, the distributed streaming processing software platform. Kafka is built resilient from ground-up. It supports multiple replicas of messages served by a cluster of fault-tolerant brokers. In front of Kafka sits Pipeline Edge API service that provides convenient REST APIs to produce and consume messages. Edge API service provides additional features such as rule-based message routing, filtering, authorization, and authentication.
While Kafka is fault-tolerant, the system is not immune to occasional network glitches between the Kafka brokers and Pipeline Edge API service. In the event of such outages, Pipeline cannot accept messages sent by the producer. The result is that the producing service either has to retry or drop the message then move on. Most of the producers are not configured to handle such back pressure, which results in data loss.
We improved client experience by introducing a disk-based caching layer. In the event of Kafka outage or network problems, Pipeline’s APIs can still accept messages by writing them to the disk. When Kafka becomes available again, cached messages are written to Kafka. While we haven’t rolled out disk-based cache globally, it has shown promising results in a couple of clusters boosting our perceived API availability to over 99.99% over the last two quarters (up from 99.85%).
Apache Kafka
It’s no secret that we love this Apache Kafka. We built Pipeline on this framework, after all. We go into more detail in our previous post about Pipeline.
Smarts
We named Adobe Experience Platform stream processing framework “Smarts.” Smarts allows a high degree of flexibility in how data is filtered, enriched, and routed between publishers and consumers. It enables activation of events in real time by:
- Expressing a streaming or continuous query that can monitor and filter events across topics in multiple data centers.
- Creating a pluggable framework that allows other teams in Adobe to contribute services that can be invoked conditionally in a streaming context.
- Routing qualified events in an efficient manner to one or more internal or external destinations.

Smarts also allow teams within Adobe to filter out the noise and consume only what they care about. Imagine if you had to read through a few thousand emails to get to the one that you actually cared about. We’d never build a system like that for humans. With the many optimizations in place to reduce the cost of reading data, wasteful patterns in machines are quite common. In a way Kafka’s read-optimized architecture promotes this pattern (or dare we say anti-pattern?). Pipeline prevents the creation of these non-optimized patterns of data consumption. This allows us to take advantage of Kafka’s insane read scalability without overwhelming the underlying infrastructure.
Pipeline Console
Pipeline Console is the face of Pipeline. It is arguably the most loved feature, both by our team and by our clients. It provides a glimpse into the physical nature of our infrastructure as well as a logical view of how services are consuming it by cataloging all the different integration points. It is also a mature self-service portal, which helps us get out of the way of our clients by allowing them to run day-to-day tasks themselves without having to wait for the core team to be available. You can read more about Console in our previous post on Pipeline.
Thanks to the self-serve nature of Pipeline, we’re saving roughly 127 hours (~15 days) of on-call time each month. We also save countless hours of development time by allowing hundreds of teams within Adobe to move at their own pace and fix common problems themselves. These savings are harder to quantify, but we expect it to be exponentially higher than our on-call time savings.
Scalability
Loads on a large-scale system like Pipeline vary based on various factors, such as seasonality, new product launches, one-time significant data processing needs (like backfilling), or an unexpected sudden burst of traffic. A correctly provisioned system is the key to its performance and cost-effectiveness. Kubernetes provides us an excellent framework for deploying and scaling applications rapidly, making it our choice of technology for running our Edge API and Smarts services. Kubernetes allows us to scale our services based on predictable demands and react to unforeseen traffic spikes.
Scaling up Kafka, on the other hand, is more challenging. There are many rapidly evolving initiatives in the industry to run Kafka on Kubernetes. However, we are taking a cautious approach to deploy our large-scale clusters in Kubernetes. Aspects such as rolling restarts, broker upgrades, data balancing, multi-availability zone deployments, rack awareness must be adequately tackled. Meanwhile, we devised a different strategy to scale our Kafka clusters to address our scale concerns. We scale Kafka horizontally by creating smaller on-demand clusters called “satellite clusters” rather than scaling Kafka vertically by adding more brokers to the existing clusters.
Using Terraform scripts, we can quickly provision compute and storage resources in the cloud and rapidly deploy Kafka. Satellite clusters are primarily used by Adobe product teams that have short-term needs for a specific use case. They’re also used by Adobe teams that prefer to have their own Kafka clusters rather than using a shared infrastructure. Pipeline’s routing framework allows for messages to be selectively replicated from our main clusters to satellite clusters so that they can be consumed independently.
Composability
The primary mission of Pipeline is to remove friction and enable hundreds of different services in Adobe to blend seamlessly with each other. But we didn’t want Pipeline to become a utility to just move bits around as it would be a significant waste of an amazing resource. Through Smarts, we’ve been working towards making it possible for clients to build applications on top of Pipeline without having to deploy any code.
Our focus has been on allowing our clients to easily express the following four details:
- Which source data streams they want us to listen to and the encoding of messages on those data streams (JSON or Protobuf, as an example)?
- What static filters and streaming joins need to be applied to those data streams to identify relevant messages?
- What business logic and/or transforms are needed to shape messages into specific output formats (this is optional)?
- Which destinations messages should be published to?
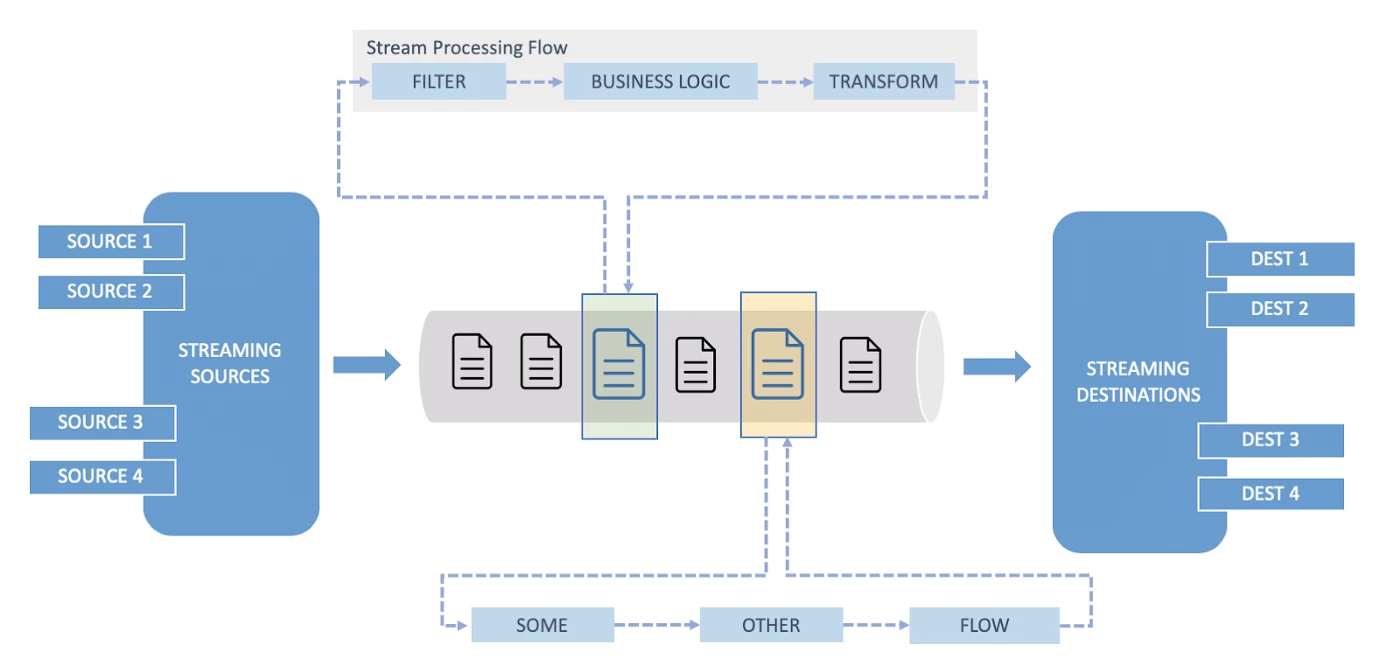
This framework allows us to deliver a feature set that:
- Filters and fans out data so each service only sees the data they care about, minimizing cycles spent dealing with irrelevant data.
- Enriches data and computes derived attributes (such as exchanging product SKU for detailed product information) before data lands into persistence stores.
- Invokes custom business logic on individual messages through an extensible set of APIs.
Together, Adobe Experience Platform Pipeline Console UI and Smarts Runtime allows teams to compose streaming workflows that can be authored and managed through a single interface.
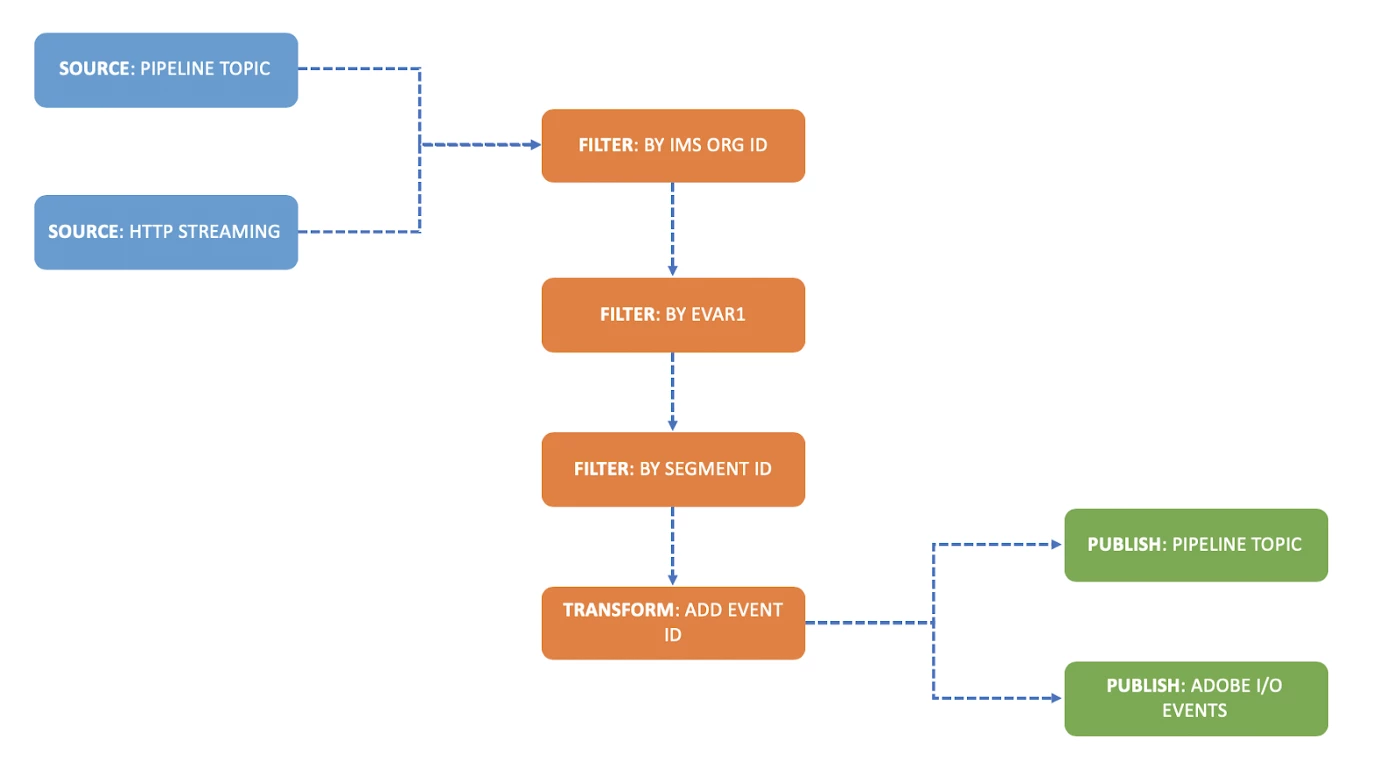
Finally, Smarts is powered by Apache Beam workflows running within Apache Flink Runners. Smarts allows clients to execute a variety of workflows quickly, by chaining together a collection of actions and Apache Beam based operations piping the output of one as the input of another with ease.
It enforces a decoupled architectural style, which allows resources to evolve independently of each other, and the actions supported by them to be seamlessly assembled in interesting ways.
In case you missed it, here’s an excellent blog post from our colleagues at Adobe that shows why Flink is a preferred stream compute framework.
Interoperability
Almost all the customers that we’ve spoken with have a business-critical need for a 360-degree customer profile to deliver better experiences. Consequently, they need a comprehensive data warehouse to house different types of data. This ranges from behavioral data from digital devices generated from customer engagement systems (like CRM and ESP) as well as third-party data from walled gardens like Facebook. Teams of data engineers, IT professionals, and developers are collecting data from a multitude of sources, cleaning it, and then curating it to answer difficult questions in and around customer behavior, sentiment, and trends in a reliable way.
With Adobe Experience Platform we don’t expect customers to rip out their existing systems and replace them. Instead, we want to help customers deliver better customer experiences, both inside and outside our ecosystem. We expect customers to leverage event-driven integrations to bridge their technology stacks with that provided by Adobe.
For the sake of simplicity we’ve classified outbound events from Adobe into two broad categories:
Control-plane events
These are high-value, low-frequency events that can be mission-critical to the consuming service. For example, if a weekly task bringing in CRM data fails, the data engineer would want to be proactively notified, not find out after they’ve logged in. Similarly, a dramatic spike in validation errors, if not addressed quickly, could result in a costly recovery and negatively affect regular business operations.
Through the pub-sub model powered by I/O events customers can subscribe to these high-value events from Adobe Experience Platform and receive them in near real-time.
Data-plane events
These are typically higher-frequency events that aren’t mission-critical. Data-plane events include things like a continuous flow of telemetry data or a streaming feed of Unified Profile updates. Customers can use these feeds to bridge adjacent processing systems wherever they choose.
Using the Kafka Connect Framework, we allow egress of high-frequency events from Pipeline to dozens of popular sinks like Azure Event Hub and AWS Kinesis and S3.
Looking to the future
One of the nicest aspects of the way we’re using Pipeline to process information in-flight is that it shortens the amount of time it takes to reach actionable conclusions based on the data that’s being collected. Our customers gain an advantage over their competition by being able to better serve their customers by fine-tuning everything from messaging to troubleshooting in near real-time.
We’re constantly learning new things and are excited about the challenges we’ll be tackling in the future. The next post in this series will be a deep dive on Pipeline Console, and at some point, we’re looking forward to sharing our story on adopting CI/CD and how we optimized our deployment processes.
References
- Adobe Experience Platform: https://www.adobe.com/experience-platform.html
- Adobe Experience Platform Customer Data Platform: https://www.adobe.com/experience-platform/customer-data-platform.html#
- Apache Kafka: https://kafka.apache.org
- Apache Kubernetes: https://kubernetes.io
- Terraform: https://www.terraform.io/
- Apache Beam: https://beam.apache.org/
- Apache Flink Runners: https://beam.apache.org/documentation/runners/flink/
- Kafka Connect Framework: https://www.confluent.io/hub/
Originally published: Sep 26, 2019