
Evaluating Streaming Frameworks for Large-Scale Event Streaming
Authors: Fakrudeen Ali Ahmed, Jianmei Ye, and Jody Arthur
This post offers a behind-the-scenes look at Adobe Experience Platform process for evaluating streaming frameworks for large-scale event processing to provide better customer experiences with Adobe Experience Cloud.
Adobe Experience Cloud provides personalization, advanced analytics, and other services to help enterprises using Adobe Experience Platform meet the rising customer expectations for personalized experiences. Helping our customers deliver these kinds of experiences in real-time requires an ability to process huge amounts of data while at the same time ensuring reliability and peak performance.
Every day, billions of events are uploaded to Adobe Experience Platform and into Adobe Experience Cloud in batches and processed with daily or weekly workflows on Apache Spark. And the volume of data our system receives is growing fast. We evaluated four different streaming frameworks in order to find the best one to support our need for large-scale event processing in order to process an ever-increasing volume of data needed by our customers.
This post describes our methods, which development teams in other organizations can use as a model for evaluating streaming frameworks for their own use cases.
Selecting the candidate frameworks for our use case
Our primary goal was to convert the static workflow we built for our weekly batch event processing in Adobe Experience Cloud into a real-time streaming workflow with sub-second latency. There are many frameworks available to support event streaming. After doing some initial research to narrow down the list, we chose to evaluate Storm, Flink, Samza, and Spark based on their feature set relative to our particular use case. In this section, we provide a brief description of each of these frameworks in terms of its potential benefits for our use case.
Storm
Apache Storm is an open-source real-time streaming framework that integrates with any queueing and database technologies that may already exist in the stack and can be used with any programming language.
Storm is fast, too. It's ability to process streaming data has been measured at more than a million events per second per node. Storm topology is able to consume streams of data and process them in arbitrarily complex ways and repartitioning them from node to node in any way required for the workflow.
Flink
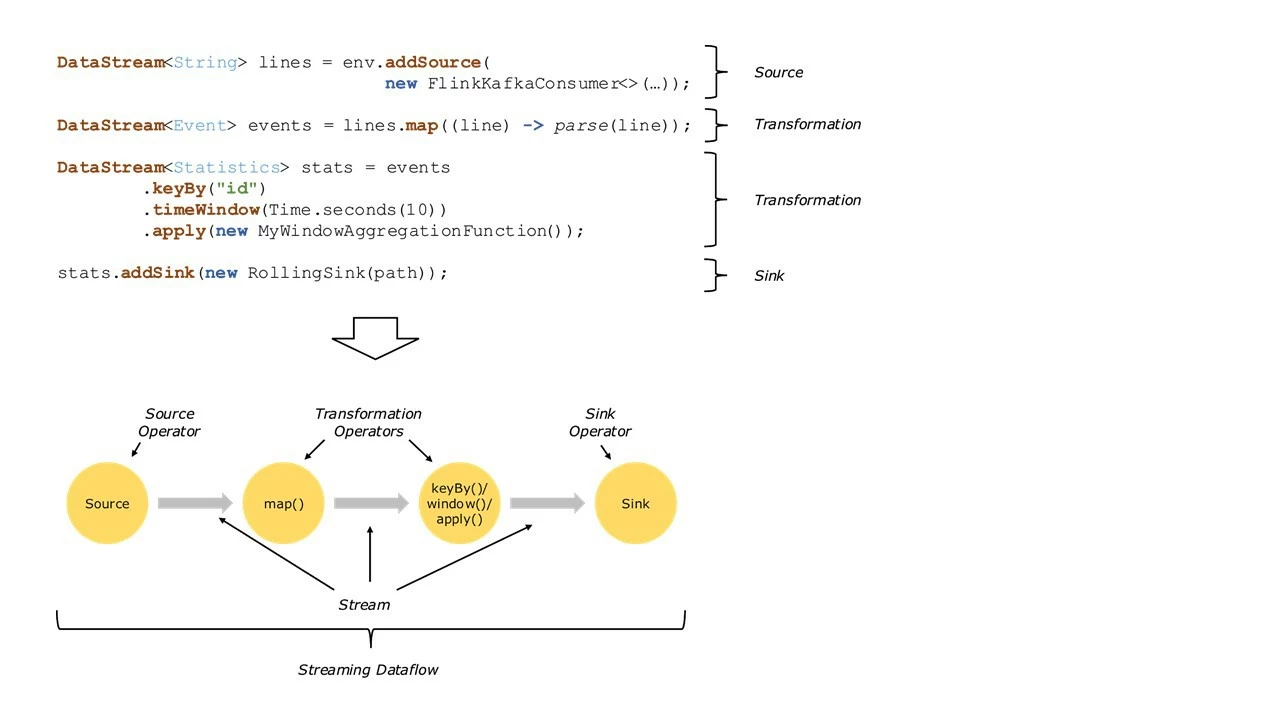
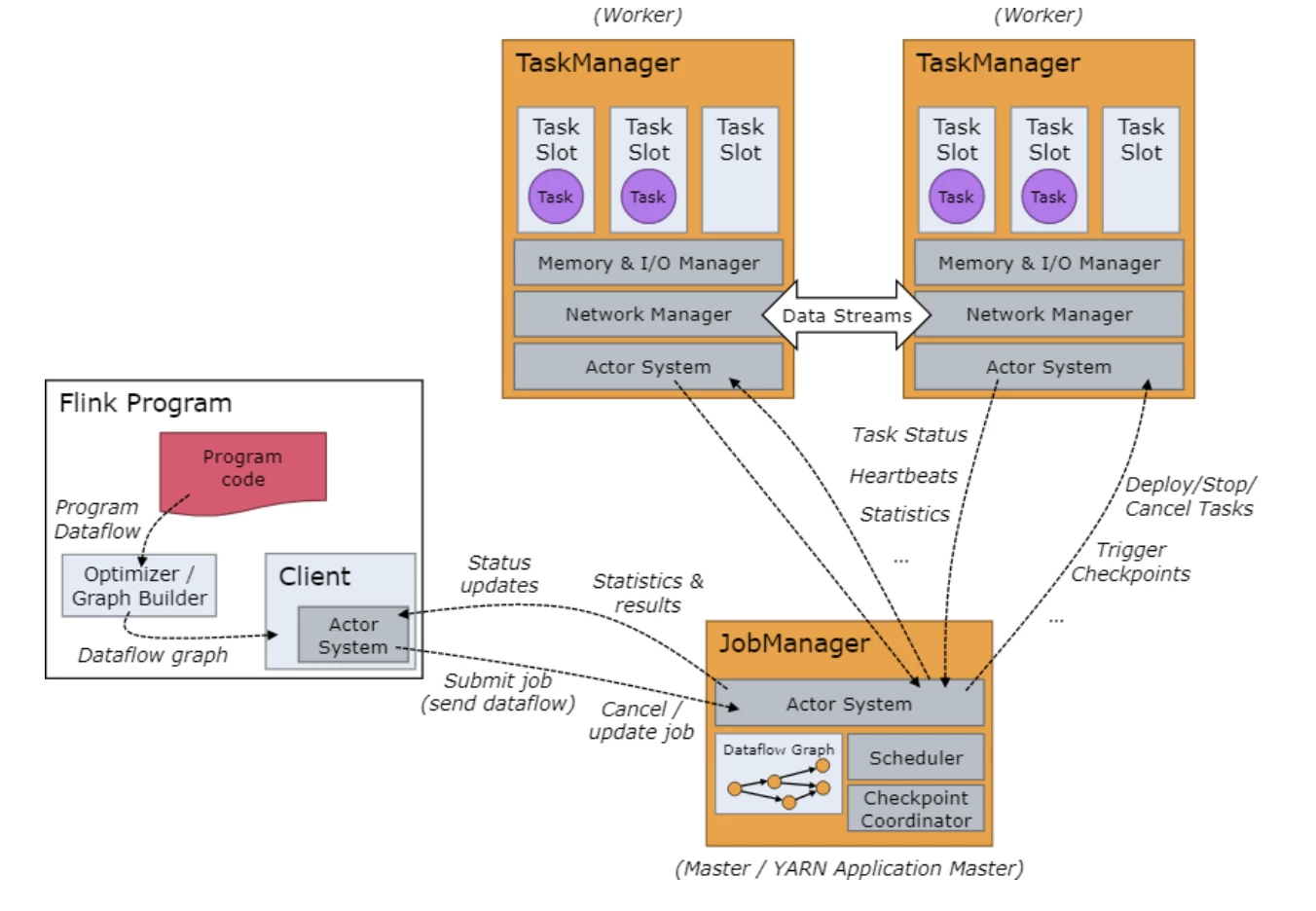
Apache Flink supports both streaming and batch processing. Flink runs in all common cluster environments and is capable of performing computations at in-memory speed and at any scale. By precisely controlling time and state, Flink's runtime can run any kind of application on unbounded streams. When configured for high availability, Flink does not have a single point of failure and is capable of scaling to thousands of cores and terabytes of application state, while still delivering high throughput and low latency.
Spark
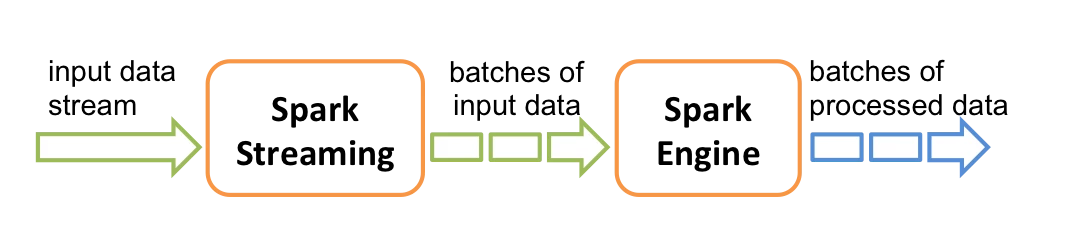
Apache Spark Streaming is an extension of the core Spark API. Spark Streaming is very scalable, offering high-throughput, fault-tolerant processing of live data streams. Data can be ingested from many sources, processed and pushed out to filesystems, databases, and live dashboards.
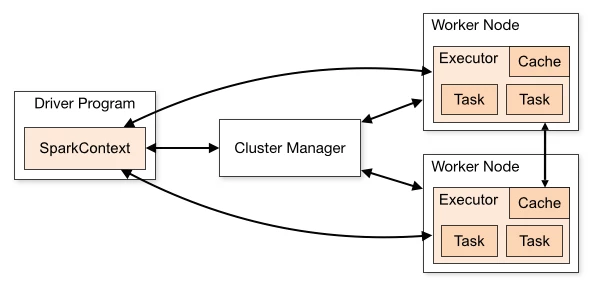
It is important to note that Spark with Spark Streaming is not a native streaming framework. Unlike the other three systems, we evaluated Spark Streaming processes data in micro-batches, which is a variant of traditional batch processing. Because it allows processing in very small batches, those batches can be processed in rapid succession, closely mimicking real-time streaming of discrete event data.
It could be argued that comparing Spark Streaming with native streaming frameworks isn't really a fair test. However, Spark is so widely used in the industry, one might reasonably assume it to be a logical choice, especially with the availability of Spark Streaming, for building streaming workflows.
But, is it the best choice? Without testing, there was no way for us to know if this option would be a wise choice in our use case. We also wanted to see how micro-batch processing built on a system as reliable as Spark would stack up against other widely-used native streaming frameworks.
Samza
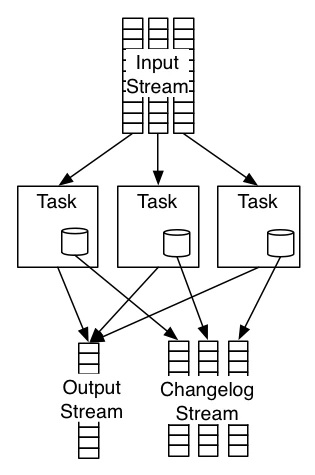
Apache Samza offers scalable, high-performance storage that supports stateful stream-processing applications. One of its key features is stateful stream processing. The ability to maintain state allows Samza to support very sophisticated stream processing jobs, such as joining input streams, grouping messages, and aggregating groups of messages.
In Samza, each task is associated with its own instance of a local database, which only stores data corresponding to the partitions processed by that task. When scaling a workflow, Samza provides more computational resources by transparently migrating the tasks from one machine to another, giving each task its own state. This allows tasks to be relocated without impacting the overall performance.
Our evaluation criteria
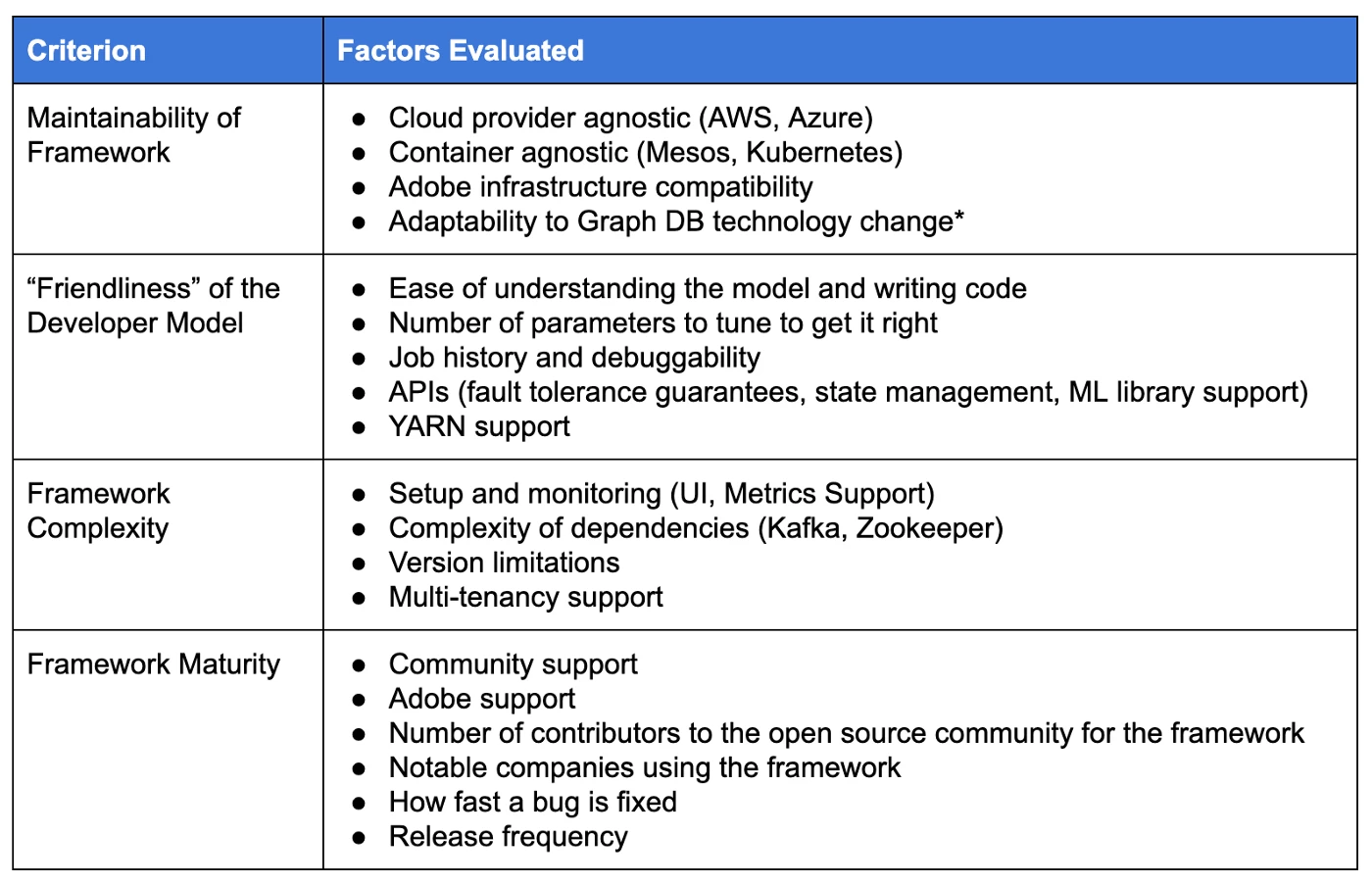
Our evaluation included both qualitative and quantitative criteria. While quantitative benchmarking is critical in evaluating a streaming framework, the additional, more qualitative measures included in the list below were also important to consider in choosing a streaming framework to support the real-time needs of Adobe Experience Platform customers using Adobe Experience Cloud:
- Maintainability
- Developer Friendliness
- Framework Complexity
- Maturity
- Throughput
- Latency
- Reliability
While these criteria will not be relevant to all use cases, the basic process we describe here for evaluating qualitative criteria can be applied to any situation in which a developer needs to identify the best solution to meet his/or needs.
Evaluating a streaming framework qualitatively
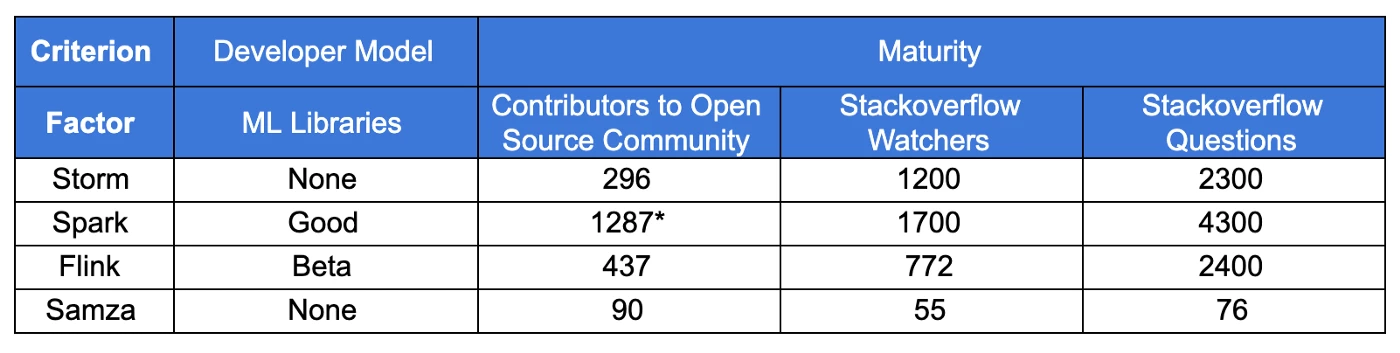
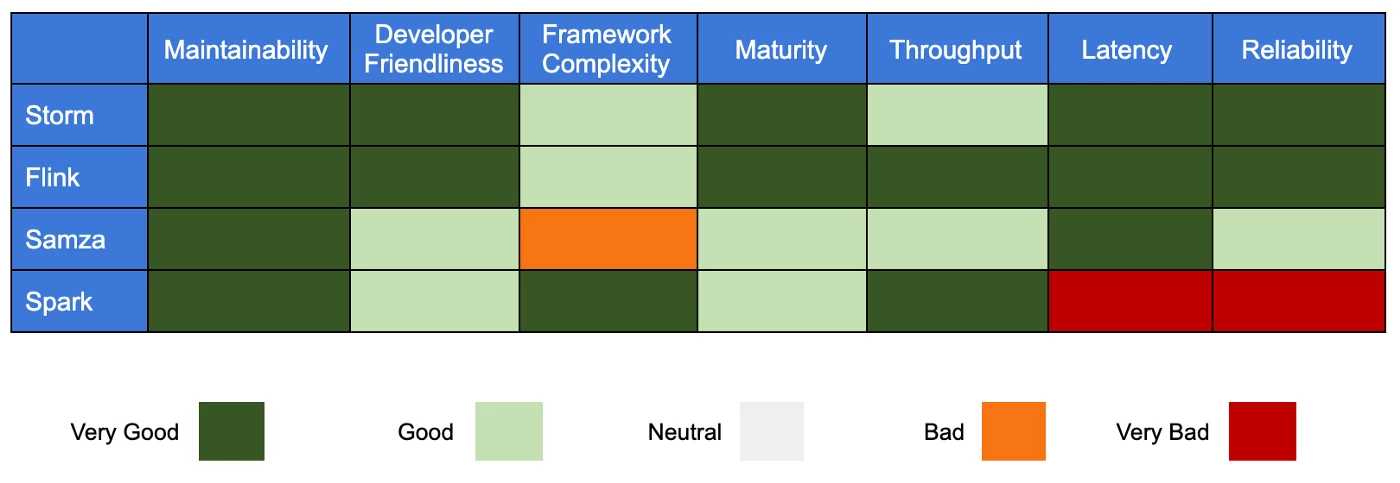
The following are two tables for criteria we used for our qualitative evaluation with the factors we considered for them and some of our results.
Quantitative benchmarking
For each framework, we evaluated the relative difficulty in set-up and operational complexity as part of our quantitative benchmarking.
The figure below provides a generalized diagram of our benchmarking set-up. Every streaming framework has typically two components: the source, which consumes the data from the message queue and sends it to the processors, and the processors that do the computational work. The interrelationship between these components is important for back pressure awareness and for the source to be able to throttle when necessary to ensure even consumption in line with processing.
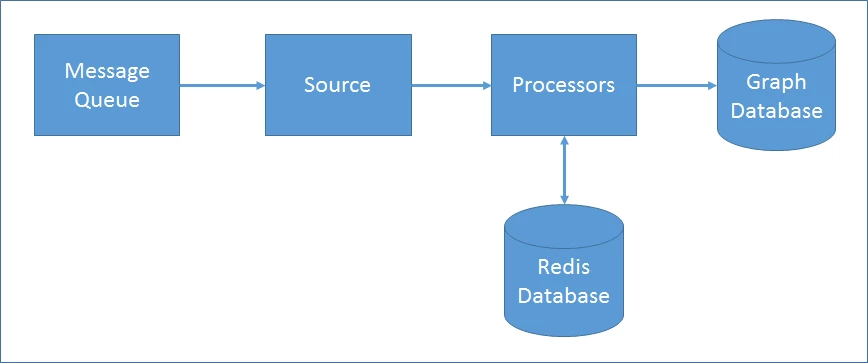
For our performance testing, we set up our event stream processing to run multiple times with one million event runs for each test. We then ran a long-running reliability test for three days. We repeated this for each of the four frameworks we were evaluating.
Benchmarking Results
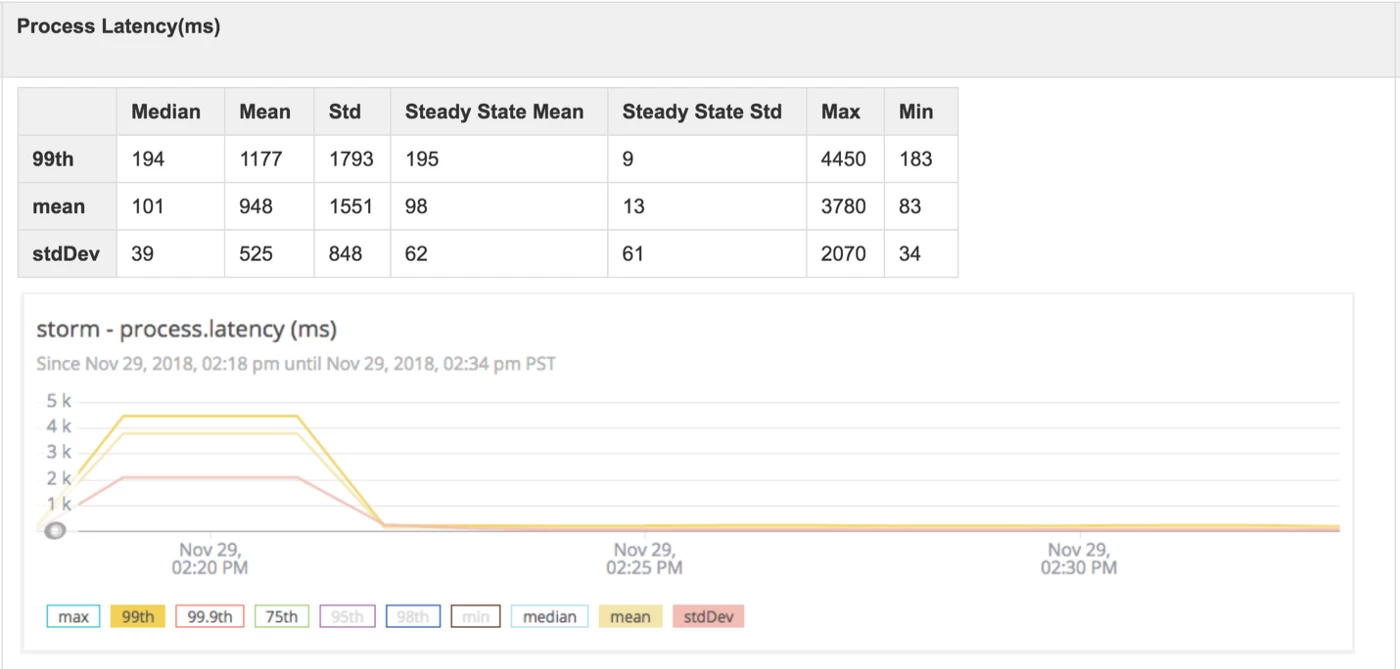
Storm
- Throughput: For the majority of event runs with our Storm set-up, the mean throughput was 800 events per second with a standard deviation of 250 milliseconds. These results translate into a 99% confidence level that we can expect throughput between 50-1,500 events per second
- Latency: The 99th process latency was below 200 milliseconds for most of our event runs, and the 99th process latency standard was less than 30 milliseconds. Both of these results were obtained at a confidence level of greater than 99%.
- Reliability: In the three days over which the data was streaming, our Storm set-up did not experience any crashes or failures.
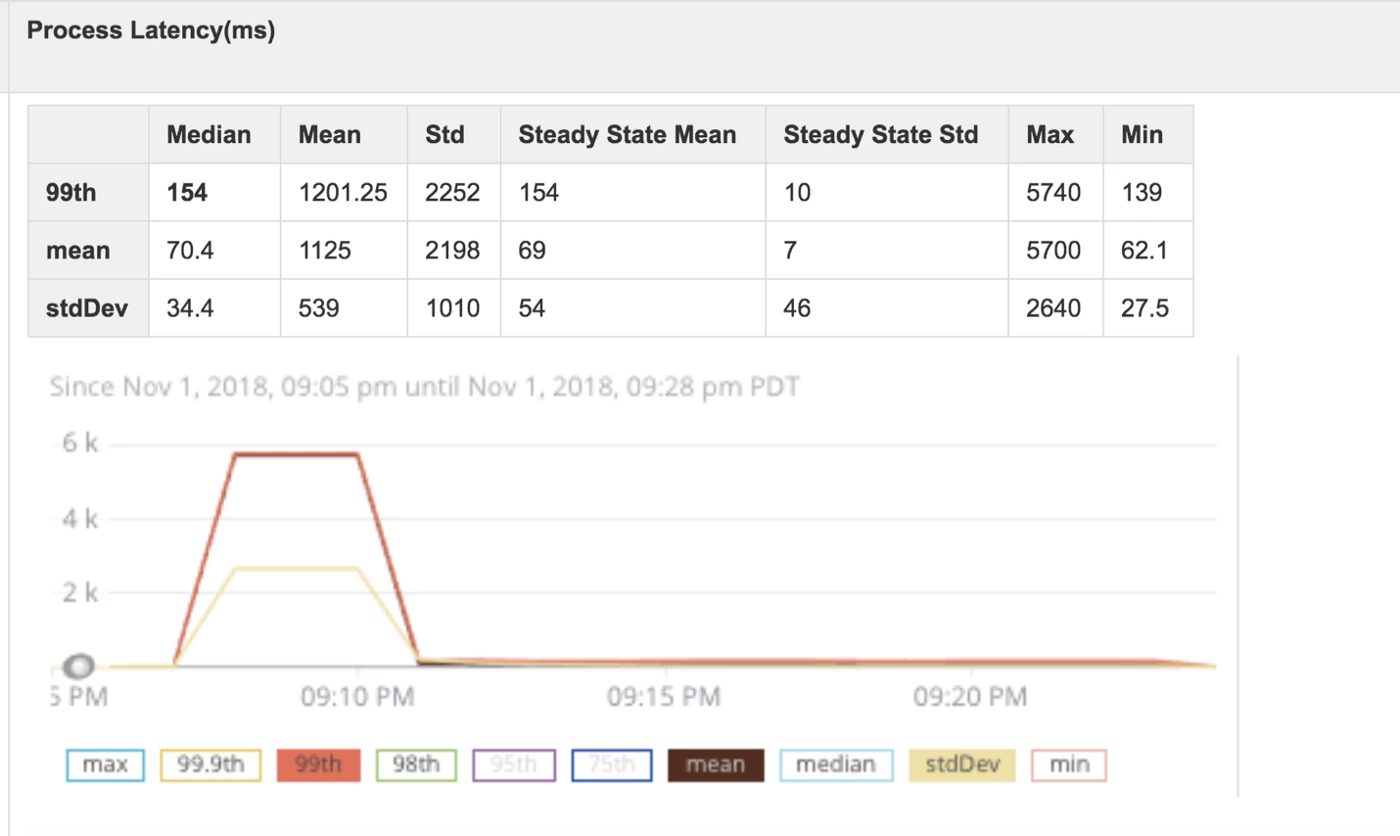
Flink
- Throughput: For the majority of our event runs with Flink, the mean throughput was 1,200 events per second with a standard deviation of 200 milliseconds. With these results, we can expect throughput of 600-1,800 events per second with 99% confidence.
- Latency: The 99th process latency was below 200 milliseconds for most of our event runs, and the 99th process latency standard was less than 10 milliseconds. Both of these results were obtained at a confidence level of greater than 99%.
- Reliability: As with our Storm test, Flink did not experience any crashes or failures over the three-day test.
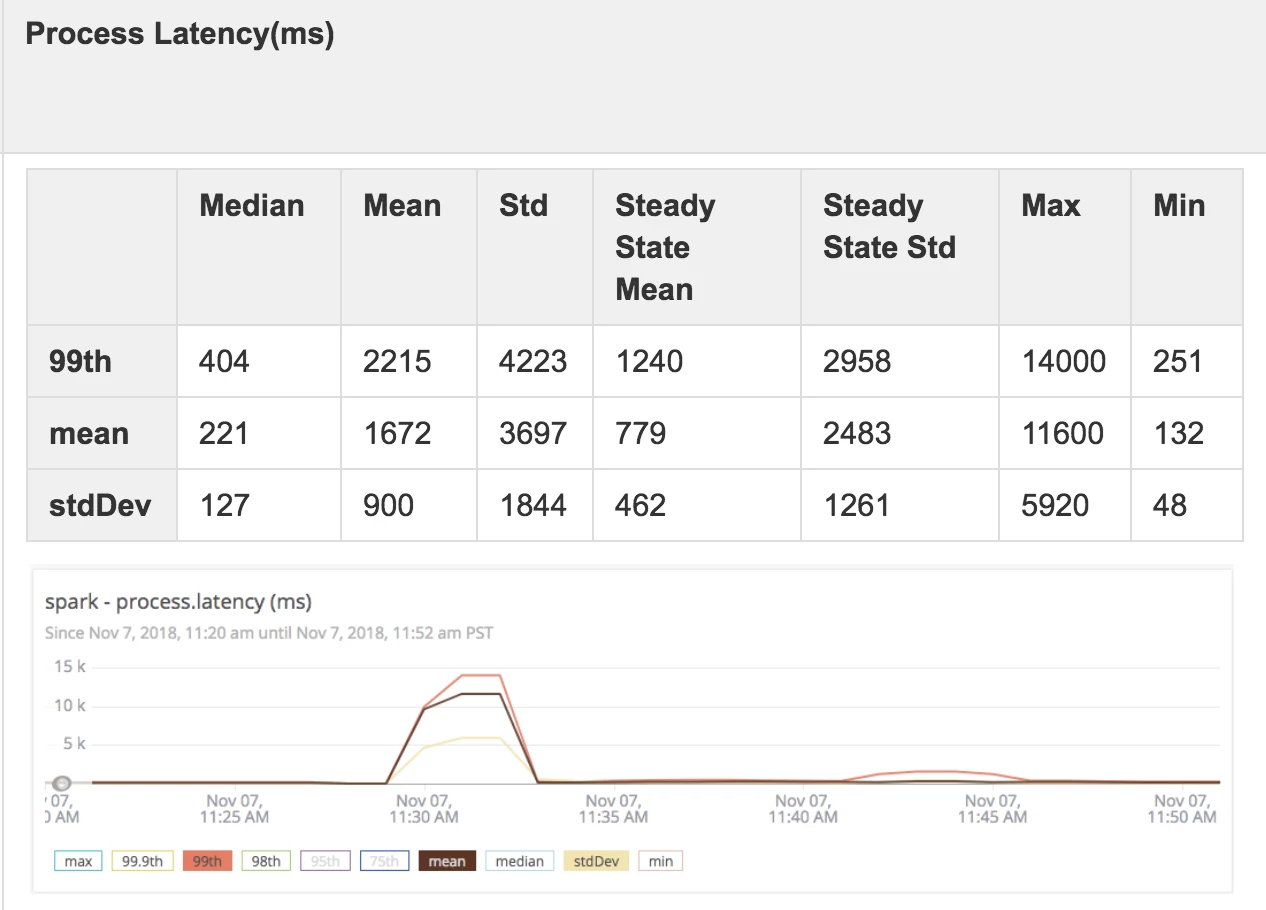
Spark
- Throughput: For the majority of our event runs with Spark, the mean throughput was 1,100 events per second with a standard deviation of 200 milliseconds. These results suggest we can expect throughput to range between 500-1,700 events per second with 99% confidence. However, we found that Spark was unable to distribute the workload to all 100 executors. There were only about 32 executors active during our three-day test.
- Latency: For the majority of the event runs, the 99th process latency was 6-7 seconds with a 99% confidence level.
- Reliability: Over the three-day test, Spark crashed in every streaming attempt. For batches shorter than a minute, and for one-second batches in particular, Spark was unable to complete the one-million event performance run. We attributed this problem to Spark's inability to communicate backpressure back to the source.
Samza
- Throughput: For the majority of our event runs with Samza, the mean throughput was 500 events per second with a standard deviation of 105 milliseconds. This means we can expect throughput of 185-815 events per second with 99% confidence.
- Latency: The 99th process latency was below 129 milliseconds for most of our event runs, and the 99th process latency standard was 54 milliseconds with both results obtained at greater than 99% confidence.
- Reliability: Samza produced a “prelaunch.err” during the consuming job. However, there were no errors or crashes during the process job, which produced a steady-state latency of about 112 milliseconds and a throughput of 925 events/second over the three-day test.
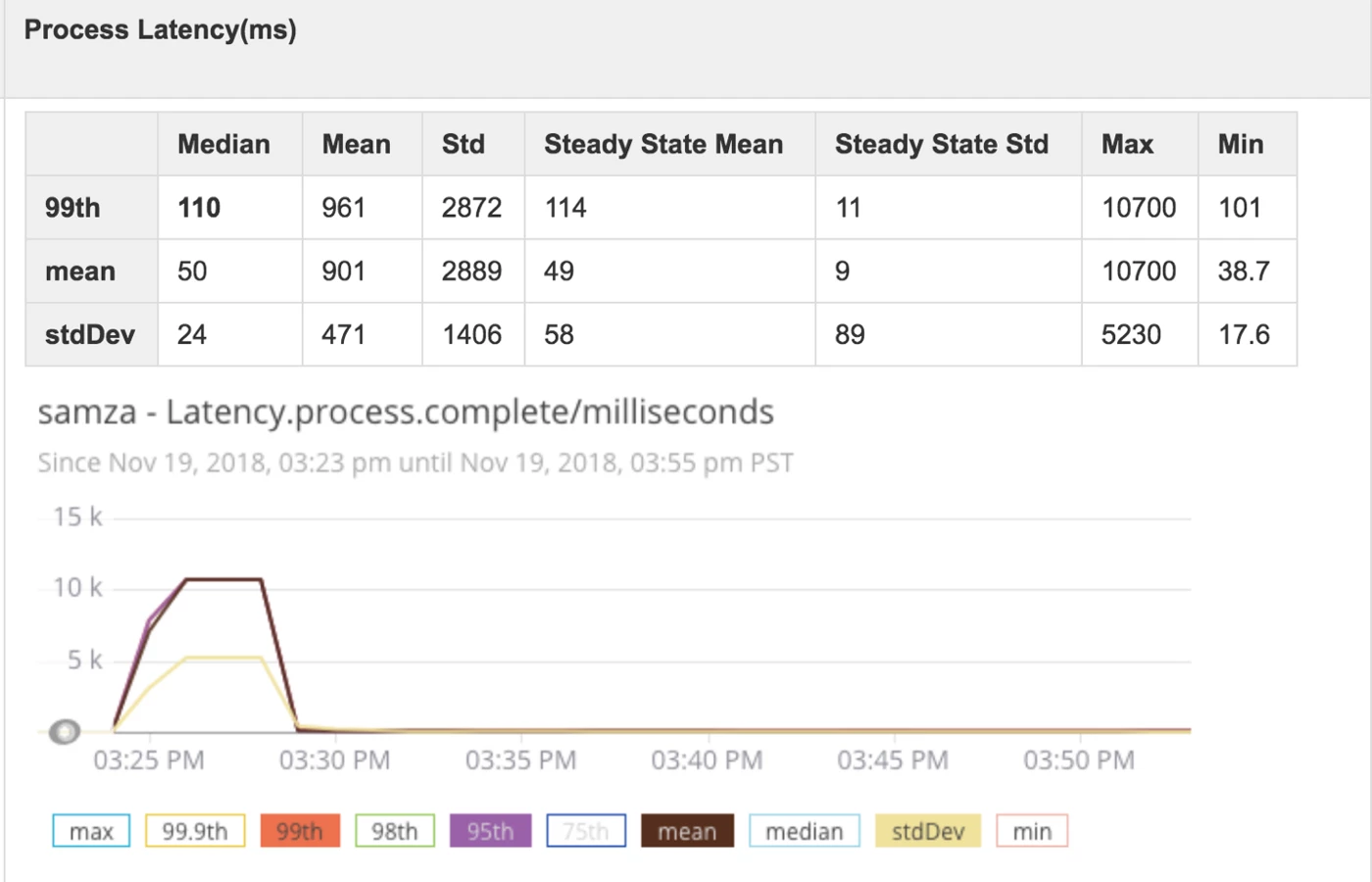
Bringing it all together
Bringing all of our qualitative and quantitative results into a single table, we were able to easily identify the best streaming framework for the large-scale event processing necessary to support the growing real-time needs of our Adobe Experience Platform customers. Apache Flink was our platform of choice for the following reasons:
- The ability to handle backpressure plays a critical role in the stability of a streaming system. Flink provided excellent handling of backpressure compared to Spark streaming, for example, which has no ability to communicate back pressure to source component.
- Flink performed as well as or better than the other three frameworks in terms of its throughput and low latency and proved highly reliable. During our rigorous testing, Flink did not crash and provided excellent performance.
- Flink framework has good community support overall compared to the other frameworks we evaluated, which bodes well for its continued development and maintenance.
Adobe Experience Platform processes billions of events each day within Adobe Experience Cloud at more than 200,000 events per second. With so much data coming into the system, we knew we needed to find a better way to process it to support the growing real-time needs of Adobe Experience Platform customers. In order to build a streaming system capable of processing huge amounts of data in real-time, we needed to thoroughly evaluate our options for streaming frameworks.
We believe the evaluation methods we've described here offer a useful model for developer teams in other organizations tasked with choosing a framework that will help them meet the challenges inherent in processing streaming events at high scale.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References:
- http://storm.apache.org/
- https://samza.apache.org/
- https://spark.apache.org/streaming/
- https://flink.apache.org/
Originally published: Sep 5, 2019