

Designing a Kubernetes Cluster with Amazon EKS From Scratch
Authors: Dan Popescu and Jenny Medeiros

This post describes how Adobe Experience Platform designs, deploys and manages production-ready Kubernetes clusters running on Amazon EKS, while also providing recommendations and open source tooling for developers interested in achieving the same.
Kubernetes (K8s) has become the industry standard for container orchestration, although it's also notoriously difficult to maintain. As a result, most developers choose one of many available hosted and managed Kubernetes services to streamline their deployment and management processes.
For Adobe Experience Platform, we decided to deploy our first Kubernetes cluster with Amazon Elastic Container Service for Kubernetes (Amazon EKS) – a fully managed service that allows us to run Kubernetes on AWS, while also handling the Kubernetes control plane. This makes it easy for us to deploy, manage, and scale containerized applications.
In this post, we provide an overview of our thought process when designing and deploying a Kubernetes cluster with Amazon EKS. The raison d'être of this project is to migrate Adobe Experience Platform applications, such as Adobe Audience Manager, from virtual machines to container-based infrastructure for simpler scaling, better infrastructure management, and optimized resource usage.
Furthermore, we will include lessons learned and valuable considerations for developers looking to run Kubernetes on EKS for increased security, reliability, and scalability in their own applications.
Setting up the cluster
Before designing a Kubernetes cluster on Amazon EKS, we recommend evaluating a few important components first. (Note that any of these components may be switched to others with similar capabilities.)
Cloud solution
Selecting the most suitable cloud solution for the cluster is arguably the most important aspect. If you are not constrained to a specific solution, then you must consider whether to use a public cloud or an on-prem solution.
At Adobe, we chose Amazon Web Services (AWS) – a public cloud computing service on which we host a significant portion of our infrastructure for its reputed reliability and scalability.
Kubernetes cluster service
Currently, AWS offers two options to host a Kubernetes cluster:
- Self-hosted: This option deploys Kubernetes on Amazon EC2 instances, giving you full flexibility in designing and deploying the cluster. You will, however, need to manage the entire control plane.
- Elastic Kubernetes Service (EKS): This option allows you to deploy a Kubernetes cluster without the overhead of managing the control plane, as it is fully hosted in AWS. Only the K8s worker nodes need to be managed, sparing you from some of the complexity of the self-hosted solution.
In our case, we chose the managed service (EKS) to ease the effort involved in deploying the cluster, since self-hosting would require additional time, attention, and resources.
Note that both service options deploy the worker nodes in Auto Scaling Groups (ASGs), allowing you to treat nodes and groups instead of as individual instances. ASGs also offer features such as automatic node replacement, tagging inheritance, or scaling in and out. This last feature is particularly important since it is mainly used by the cluster autoscaler service – which we will expand on later.
Multi-tenant or single-tenant Kubernetes cluster
While this decision varies from project to project, we should note that a multi-tenant EKS cluster could become problematic due to its size.
Kubernetes is flexible when deploying a multi-tenant cluster, but we have run into situations where multiple applications running on the same infrastructure ended up obstructing each other.
For this reason, it's advisable to limit clusters to 150 worker nodes when working with multi-tenant EKS clusters. Although, there are other aspects to consider regarding multi-tenancy, such as:
- Deploying critical business applications on the same infrastructure as non-critical apps may result in the latter consuming the other's resources.
- Incidents may not limit the blast radius, potentially taking down clusters along with your applications.
- Increased setup complexity that results in expanding resource quotas, pod security policies, monitoring and logging, authentication and authorization, among others.
Some of these concerns are solved by using single-tenant clusters. So, we prudently chose a single-tenant solution for critical apps that cannot be affected by others. We also created clusters in which multiple apps are deployed, but are limited to engineers within the same team/project. This ensures that all actions are coordinated from a single management point.
Type of worker node instances
This depends on the type of applications that are to be deployed on the cluster. Some apps may consume a lot of CPU, while others prefer memory or GPU. Choosing multiple worker node flavors for smarter resource usage is an option, but it strings along with the following considerations:
- The need to manage multiple ASGs
- Increased cost to host multiple instance types
- Added complexity when designing the cluster
EKS offers the possibility of employing multiple ASGs with different instance flavors, where each ASG has specific tags that can be used to schedule pods via label selectors. For our design, we chose C5.9xlarge instances that provide enough compute power for our CPU-hungry applications while also optimizing costs.
Designing the cluster
Next, we will describe a few considerations when designing Kubernetes clusters on Amazon EKS.
Global Server Load Balancing (GSLB)
Deploying a GSLB allows you to route traffic for specific regions based on the source IP of the request. For example, a DNS request from an IP within Europe would be redirected to a specific load balancer in the same continent.
This mechanism lowers latency since the client would be redirected to the closest regional point of presence. For this, simply add the GSLB record within the DNS service provider and configure the country's mappings. Note that DNS replication and record propagation may take a while, so you could have inconsistent DNS resolution until the DNS is fully replicated across the globe.
This DNS design is crucial for the entire Kubernetes ecosystem, and a bad setup may disrupt the whole architecture. During this stage you should take into account the DNS zone configuration and replication, caching and resolution, how records are added or removed, and how you can implement DNS failover.
Choosing an ingress controller
You are practically spoiled for choice when picking ingress controller solutions, many of which are open source. Here are a few aspects to consider when selecting your controller solution:
- Scaling requirements, available resources, and resource use patterns.
- Traffic type that will be served (HTTP, gRPC, WebSocket, etc.)
- Number of requests, networking policies, monitoring, and logging.
If using a public cloud provider, it is possible to start with AWS Elastic Load Balancing (ELB) for ingress then gradually migrate to a more complex solution. In our case, we use dedicated ELBs for critical applications with a high number of requests, and a self-hosted ingress controller for the rest (mainly Nginx).
While ELBs may have a limited feature set, it minimizes operational complexity as well as providing stability and easy scaling.
Exposing private/public endpoints
In most scenarios, endpoints will be exposed on your Kubernetes cluster to allow other applications to communicate with it. These endpoints may be in the form of an ingress controller, such as a load balancer.
When working with large-scale distributed systems that span multiple geographical regions, you may encounter the problem of inter-region, inter-cluster, or inter-network communications (e.g. public cloud vs. corporate network).
Whether the apps must communicate with the cluster or with a corporate network, you will need to consider how network rules are created, how filtering and isolation are performed, and how all of these are managed.
In our scenario, we were faced with creating a communication link between our clusters hosted in AWS and the corporate network. We also create a few "dedicated" private subnets that are advertised to other projects using AWS Transit Gateway service. This way, any endpoint exposed on these subnets will only be available to our internal network.
Deploying the cluster
Every project has its own particularities, but here are a few considerations we found when deploying Kubernetes clusters on Amazon EKS.
Cluster redundancy for a single region
This refers to deploying multiple Kubernetes clusters in a single region to limit downtime if a cluster should fail. Redundancy is especially important in scenarios where critical applications are deployed and no downtime is allowed.
These clusters may be deployed in two scenarios: active-active or failover.
Active-active: This scenario involves multiple clusters serving the same traffic. If one of these clusters should go down, all processing power would be lost. When combined with a Kubernetes cluster autoscaler feature, available clusters may scale up to cover the loss.
Failover: In this scenario, you may have one or more clusters in standby that can become available if the main cluster goes down. The caveat is that you will need to pay for resources that may never be used.
With these scenarios in mind, it's encouraged to employ multiple Kubernetes clusters. For example, choose two Kubernetes clusters with 25 nodes each instead of a single Kubernetes cluster with 50 nodes.
Granted, this setup raises the subject of cluster management. At Adobe, we chose the open source continuous delivery platform, Spinnaker, for simpler application management and cluster deployments, as well as upgrades and replacements.
VPC Peering or AWS Transit Gateway
If you were to deploy K8s clusters across multiple regions for several projects and needed cluster-to-cluster communication, it may be difficult to decide between peering between VPCs or communicating publicly.
VPC peering, as well as Transit Gateway (TGW), requires non-overlapping IP blocks across all VPCs – an aspect that may raise the complexity of the setup. Without clearly defined standards, managing VPC CIDR blocks across teams and regions can be nightmarish, so public communication instead of VPC peering is preferable.
Since our infrastructure pushes us to employ TGW to access other internal projects, we also have to peer each cluster with TGW. For the design, we use two CIDR blocks attached to the same VPC:
- The first block is used to deploy the infrastructure for Kubernetes.
- The second block is used to create private subnets that expose internal endpoints.
The CIDR block used by Kubernetes is blocked within TGW, allowing us to use the same internal CIDR block for all clusters. This scenario may apply to other large corporations where hundreds of projects must communicate with each other.
VPC considerations
The largest CIDR block that can be used in AWS for any VPC is /16. While it seems big enough for most scenarios, we found that this is not always the case due to some constraints with the AWS CNI.
In EKS, worker nodes consume a considerable amount of IP addresses depending on the instance type. A single worker node can consume anywhere from one to over 200 IPs. There is no private address block used by Kubernetes pods, each pod will consume an IP address from the whole VPC CIDR block.
Unfortunately, the /16 VPC size cannot be changed or switched for an alternative. Because of this, we opted for multiple, smaller clusters (maximum 100 worker nodes), rather than using large clusters.
Multiple subnet types or a monolith
When we first designed the EKS cluster we chose the simple solution of deploying everything in a single VPC with multiple subnets distributed across multiple availability zones. After several iterations, however, we considered splitting both network traffic and resources into multiple subnet types. Subsequently, we had the following subnet categories:
- Control plane subnets: EKS may handle the control plane, but it still needs to pull IP addresses from the VPC. This is crucial since you don't manage the control plane instances, but you do provide the subnets where those machines are deployed. For this reason, we've created dedicated subnets for this component to create isolation between worker nodes and control plane worker nodes. These subnets have also been distributed across multiple availability zones for redundancy.
- Worker node subnets: This is the largest subnet category that we have created. This is where pods are going to be deployed, so these can be as large as your setup allows.
- Public subnets: This is where the publicly accessible endpoints are deployed. For this category, we chose smaller CIDR blocks since only load balancers are deployed within this range.
- Private subnets: For private accessible endpoints we created this special subnet category that offers an entrance to the cluster from the corporate network. Within these subnets, you can deploy a limited number of worker nodes for an ingress controller or use an AWS provided load balancer.
CI/CD tools for deployment
There are many aspects to consider when choosing the most suitable CI/CD tool for your particular project. In our case, we chose the cloud-agnostic Spinnaker CI/CD platform for its usable UI, streamlined API, and built-in features to easily manage multiple Kubernetes clusters regardless of complexity.
In our deployment pipeline, we hooked Spinnaker with Jenkins, Helm and Artifactory to perform simultaneous deployments on more than 40 clusters. See Figure 1.
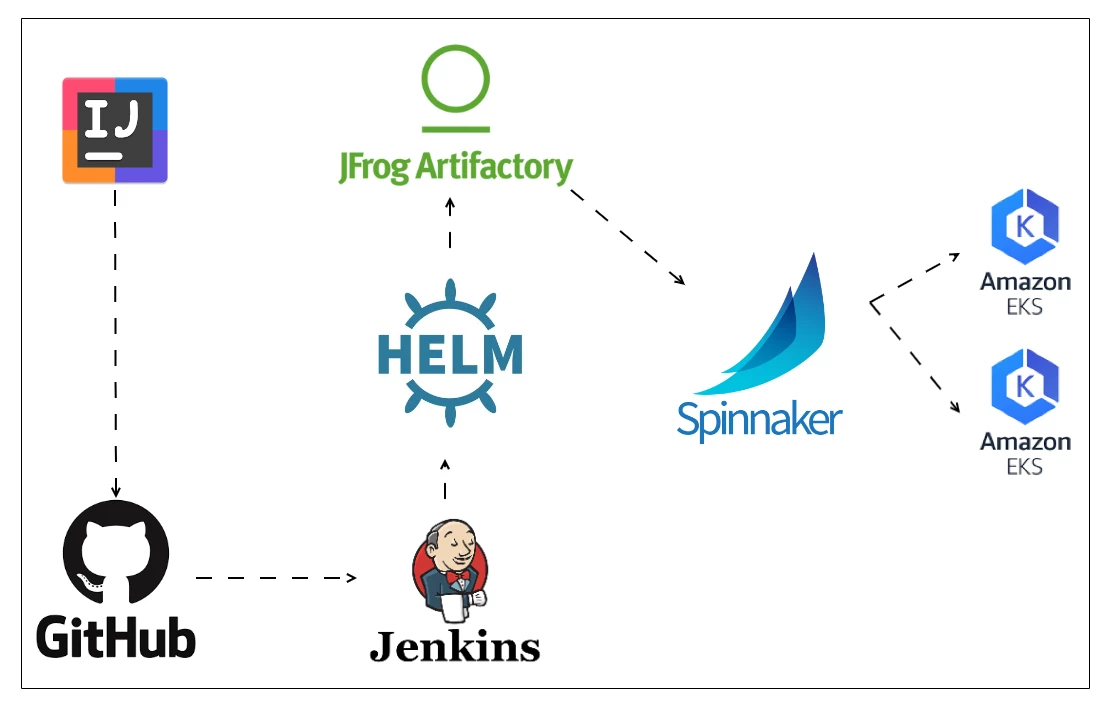
The resulting pipeline operates as follows:
- The code is written in the IDE and pushed to GitHub.
- Jenkins builds the Helm artifact and pushes it to Artifactory.
- Spinnaker monitors the Helm repository hosted in Artifactory and pushes any new versions across multiple EKS clusters.
At this point, our Kubernetes network looks as shown in the high-level diagram below.
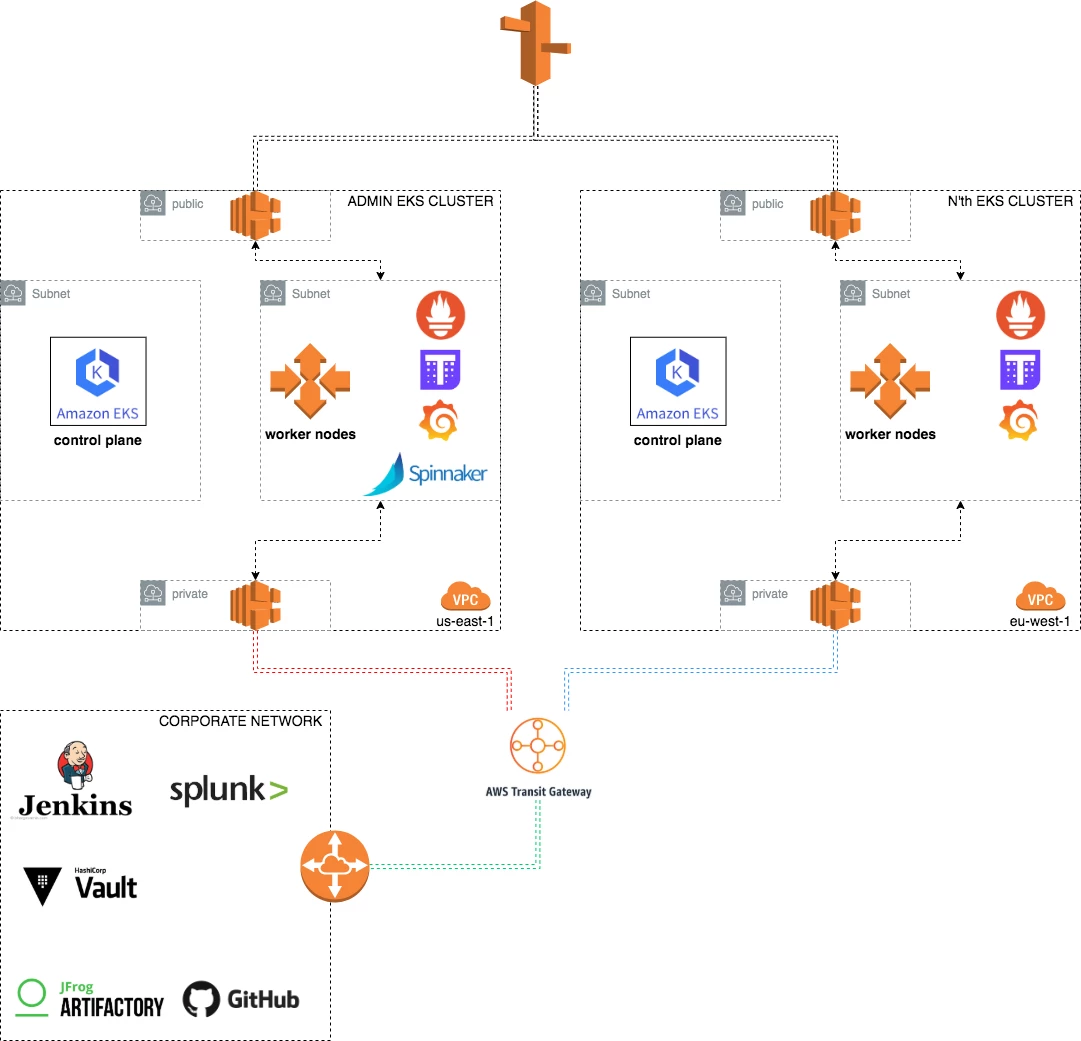
Managing Kubernetes clusters
Last but not least, we arrive at the crucial stage of maintaining your Kubernetes solution. Here we will highlight a few tools that we have found most useful for our projects, but note that these can easily be substituted for others, depending on your own requirements.
Monitoring and metrics
Prometheus is the go-to monitoring tool for Kubernetes, along with Thanos for long-term storage for a highly available and redundant setup.
Each cluster hosts its own monitoring system while Prometheus and Thanos scrape the local environment for metrics. Additionally, to provide an overview of the whole Kubernetes infrastructure, we deployed an "admin" cluster that acts as the center scraper for all other clusters.
Logging
We use the open source log processor and forwarder, Fluent Bit, which runs on each cluster and sends its logging data to our enterprise Splunk solution. This is especially important for troubleshooting and auditing purposes.
Among the many other apps we employ, that you may also find useful, are:
- ExternalDNS to add dynamic DNS resource records.
- Kube2IAM to provide AWS IAM roles for pods running on K8s.
- Jaeger for open-source, end-to-end distributed tracing.
- Cluster Autoscaler to automatically adjust the size of the Kubernetes cluster under certain conditions.
- Horizontal Pod Autoscaler (HPA) to automatically scale the number of pods running on K8s.
- Security features such as Pod Security Policy (PSP) and Open Policy Agent (OPA).
Disaster recovery
As a precaution, it's advisable to perform "disaster drills" to ensure critical systems can be quickly restored if a real disaster hits. For backups and restores, we use Velero and store our backups in Amazon S3 Buckets that are protected against deletion, and enable versioning and encryption.
Secrets management
Typically, a dedicated secrets management software is approved within an enterprise. We use Vault as it provides an API-oriented architecture, which allows us to programmatically interact with secrets. A Vault operator is deployed within each cluster that has access to a specific Vault namespace. Since our setup is single-tenant, secrets will be only accessible by users that are part of the same project/team.
Upgrading clusters
To use Kubernetes without managing any part of its infrastructure (i.e. worker nodes, control plane), you can use AWS Fargate, a service that will do all the heavy lifting for you.
Until this service is released to production, however, you will need to manually manage cluster upgrades. For this, we chose blue-green deployments. We create a new ASG with the new cluster version in the same cluster, perform any validations and then switch to the new ASG by performing a drain operation on the old worker nodes. This allows us to swiftly switch and revert to a previous version if an upgrade error should occur.
While this infrastructure-heavy method certainly hikes the cost, it also adds confidence in our ability to quickly upgrade and rollback when needed. Another option is to perform rolling upgrades for the ASG by removing one node after another. The cost would be a lower impact, but fully upgrading a cluster would be time-consuming since you would need to add the new worker node, drain the old one and then transition all the applications.
Furthermore, in the case of an upgrade error, you would have to redo the entire process in reverse, which could result in latency costs and downtime.
Additional tooling for cluster management
There is a good chance you will need to create your own tooling to ensure optimal cluster management for your particular project.
To ease our own cluster management operations, we developed an open-source tool named Kompos. This is a configuration-driven tool for provisioning and managing Kubernetes infrastructure across AWS and Azure, leveraging YAML, Terraform and Python.
Consequently, our deploy-upgrade procedure for clusters is as follows:
- Create a cluster definition file (i.e. YAML file) and use deep merging for YAML attribute override. For this, we created another open-source Python module named himl.
- Merge and then fetch secrets from Vault or SSM.
- Deploy the cluster using Terraform.
- Execute Helm to install all cluster-specific applications.
Note that we perform these operations with Kompos on top of Spinnaker, so we rely on Spinnaker for both application deployments and K8s cluster deployments/upgrades.
Final notes and next steps
Designing a new Kubernetes solution raises many challenges, many of which can be solved with Amazon EKS. Like us, you may find the most effective setup for deploying a K8s ecosystem surfaces after multiple iterations of trial and error.
With our current setup, we have managed to deploy and upgrade more than 40 clusters with no management overhead. We have also deployed multiple production-critical applications on these K8s clusters with positive feedback from our clients since they can now deploy and upgrade clusters on their own. By empowering our clients to handle their clusters, we also return time to our team so they can focus on developing new and improved features.
As we steam ahead with this project, our next steps are to consolidate clusters, automate everything we can, add more security features, and streamline alerting and monitoring for newly created applications.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Additional reading
- Deploying Kubernetes clusters with Kompos (previously known as "ops-cli")
- Kompos: https://github.com/adobe/kompos
- Set up your Kubernetes cluster with Helmfile: https://itnext.io/setup-your-kubernetes-cluster-with-helmfile-809828bc0a9f
- Himl: https://github.com/adobe/himl
Originally published: Mar 19, 2020