

Automating Data Warehouse Testing with a Functional Test Framework
Authors: Keerthika Koteeswaran and Jenny Medeiros

This post describes the challenges of data warehouse testing for Adobe Audience Manager and walks through the in-house functional test framework we developed to solve them.
As a leading data management platform, Adobe Audience Manager processes billions of real-time and batch events every day. This data is then transformed into comprehensive reports to help marketers deliver custom experiences to the right audience.
To ensure the accuracy and reliability that is expected of these reports, we must first verify that the data itself is correct, complete, and in the right format. This is achieved through diligent data warehouse testing. The testing process, however, is largely manual and notoriously difficult due to the tremendous scale of ingested data. As a result, comprehensive testing is practically impossible, which leads to weakened data integrity and a higher risk of bugs slipping into production.
To counter these challenges, we developed a functional test framework capable of automating data warehouse testing for the Adobe Audience Manager reporting stack. With this framework, we can support detailed testing at scale, and easily certify the accuracy and quality of each data point at a much lower cost.
Testing the Adobe Audience Manager reporting stack was complex and unreliable
For context on what the framework is designed to test, we will first give a simplified overview of the Adobe Audience Manager reporting stack. (See figure below.)
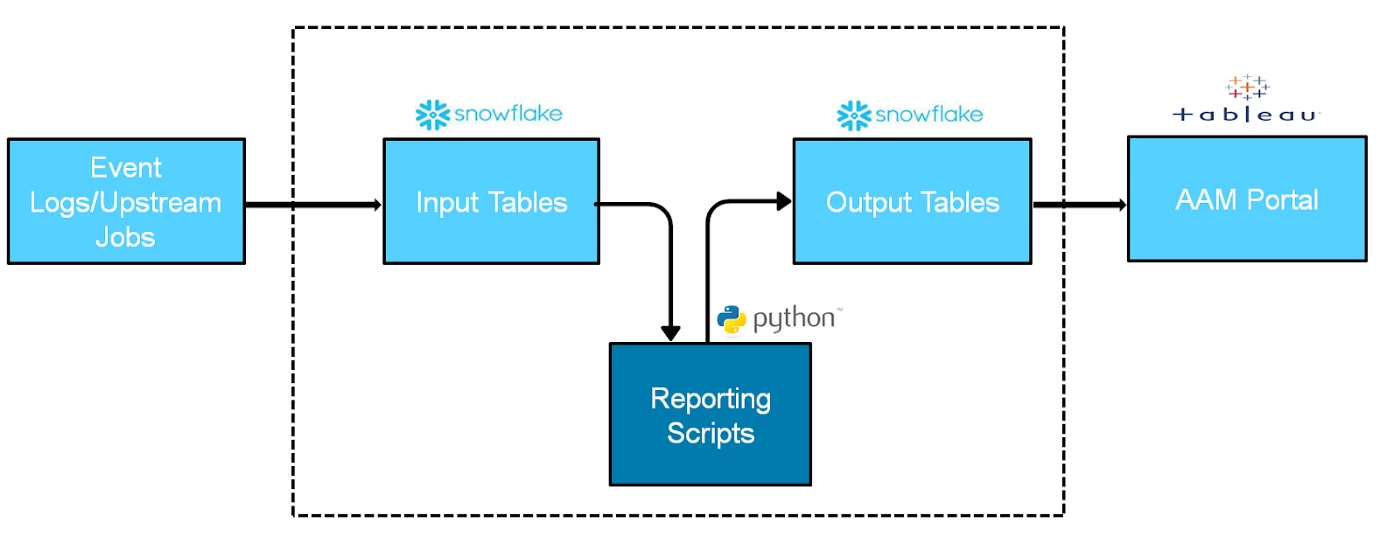
The pipeline starts with event logs received from Adobe Audience Manager customers. These logs can be stored in S3 Buckets or written into tables in Snowflake — an efficient cloud-based data warehouse that we migrated to in lieu of Amazon Redshift to streamline Adobe Audience Manager reporting at scale.
These Snowflake tables serve as input and output tables for our reporting scripts, which are basically Python scripts that apply business logic to the input table’s data in the form of SQL. The result is then returned to the output tables and rendered as reports using Tableau.
As for testing the growing amount of data flowing through this reporting stack, we faced the following challenges:
- Error-prone, manual testing: With millions of data points streaming into Adobe Audience Manager at any given time, it was impossible to thoroughly test every single one. As a consequence, manual testing is extremely error-prone and significant bugs can easily slip through the cracks.
- Unreliable quality control: Due to the impossible task of manually testing an ever-increasing amount of data, we had little control over the quality and integrity of the data. Additionally, we had no access to good quality test data and relied on unpredictable data sitting in production.
- Complex business logic in SQL: In specific applications, most of the business logic is stored in the SQL, and very little in the actual Python script. While the script can easily be assessed using a unit test framework, the business logic in the SQL requires a much more sophisticated solution.
- Difficulty handling scale: As our audience grows and the demand for real-time business insights increases, the challenges of manual testing and ensuring the quality of data are continually exacerbated. Sampling data for testing is an option, but it doesn’t guarantee good quality data that passes all the business logic criteria in our reporting scripts.
With these challenges only predicted to escalate, we set out to develop a functional test framework that would automate testing of our data warehousing stack, generate high-quality test data, and ensure data integrity in every report.
Developing the functional test framework
We designed this framework mainly towards Database and Warehousing Business Intelligence (DWBI) use cases, particularly reporting. Put simply: when given a script, the framework will generate test data based on seeding queries, then execute the test script and verify the results.
To develop the functional test framework, we began by defining the test criteria, the tech stack, and the test workflow.
Test criteria
First, we examined our current challenges to hatch the following test criteria for the framework:
- Validation of business logic in the SQL.
- Ensuring data integrity (i.e. accuracy, format, and completeness).
- Isolating test environments to avoid affecting any production jobs or other test instances running simultaneously.
- Integration with our existing Jenkins Pipeline so pull requests and comments can trigger functional tests.
Tech stack
The tech stack for this framework closely resembles that of the actual reporting scripts to be tested. This reduces the barrier to entry for writing tests, instead of making it a natural extension of developing application code.
The framework is written in Python and uses pytest for assertions, setup and teardown, and generating XML test reports. The SQLs are stored in a YAML file, which runs on Snowflake. The framework also runs within a dedicated Docker image, which contains all the dependencies required to execute the tests, as well as the scripts.
A notable feature of this framework is that the tests are co-located with the application code, thus making any reporting script changes easy to develop, test, and review. Additionally, tests are run in parallel to reduce runtime and streamline our overall build pipeline.
Lastly, the entire test environment is self-contained. This means that aside from the Docker image containing all the required dependencies, we also created a separate database and warehouse in Snowflake for each test to run smoothly.
Test workflow
A typical test workflow begins with the creation of the database and warehouse for a specific test instance, as shown in the figure below.

The next step is to populate the input tables with the test data, followed by the execution of the reporting script, which runs against the generated test data within the dedicated database and warehouse. Once this script is complete, the output tables are verified using validation SQLs. Finally, the results are published in an XML file and written to a mounted volume accessible outside the Docker container.
This workflow is automatically triggered by any changes in the code as part of our build process, allowing us to catch failures early and identify regression bugs before they affect the system — or our customers.
Defining the test framework architecture
For a deeper dive into the functional test framework workflow, here is a brief description of the building blocks.
functional_tests_main.py: This is the entry point for scripts that want to use the framework. One caveat was that our reporting scripts use Python 2, which isn’t compatible with pytest plugins for parallel testing. So, we built our own solution that parallelizes execution by checking the number of test files in the functional test directory, then spawns a separate subprocess for each one.
conftest.py: This pytest construct is where we define the fixtures and external plugins to be shared by the tests in the functional test directory. It’s also where we define our setup and teardown methods.
functional_test_runner.py: This script has a class that creates a test object for each test, and contains all the dependencies and properties needed for the test to run (e.g. details of its unique database/warehouse).
query_<script>.yml: This contains the SQLs for generating test data for the input tables, and also for the validations against the output table.
test_<script>.py: This script contains the test files with the test methods and assertions. It’s also responsible for orchestrating the flow for a particular test. These files start with test_* so pytest automatically picks them up for execution.
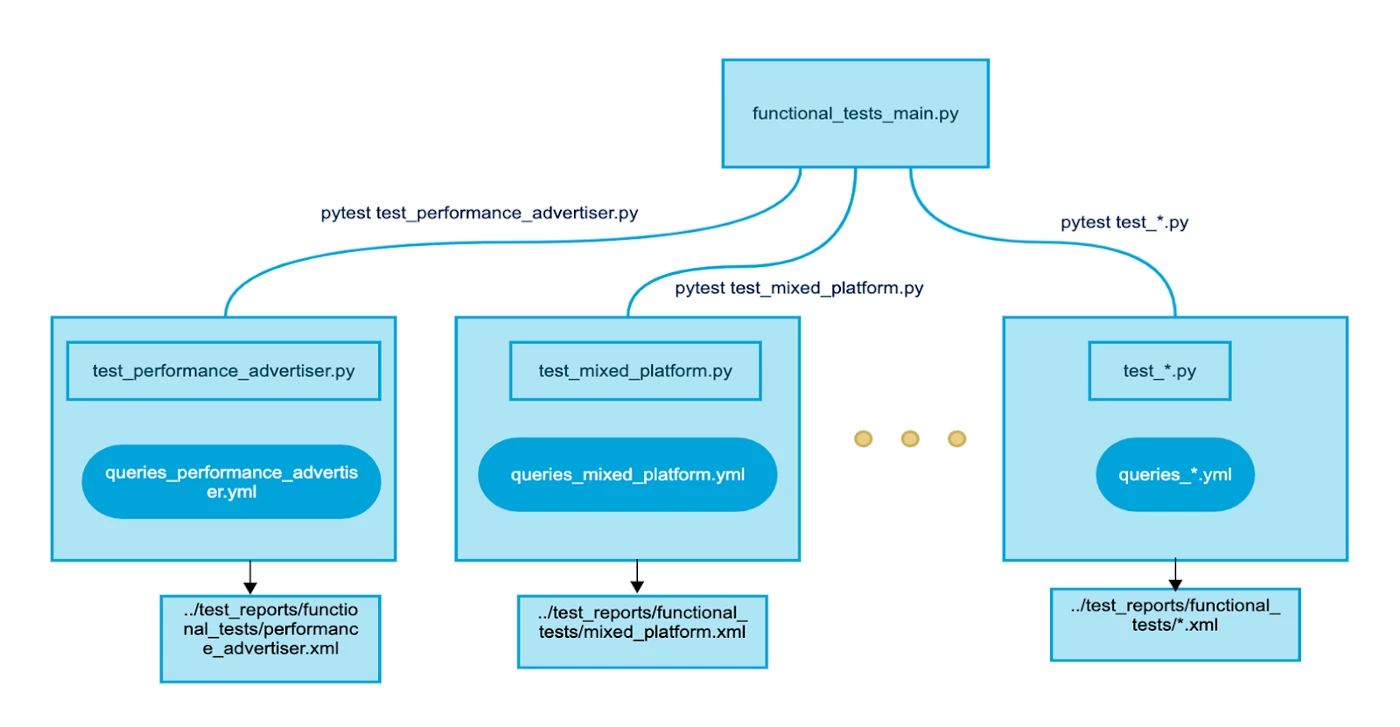
As shown in the diagram above, running a test begins with the functional test name. Then, for each test in the functional test directory, a separate sub-process is spawned with its own test file and queries YAML file for simultaneous execution and validation. Once the test has run, the output is published in an XML file.
Example: Running a functional test framework file
The following image shows an example of a test file within the framework.
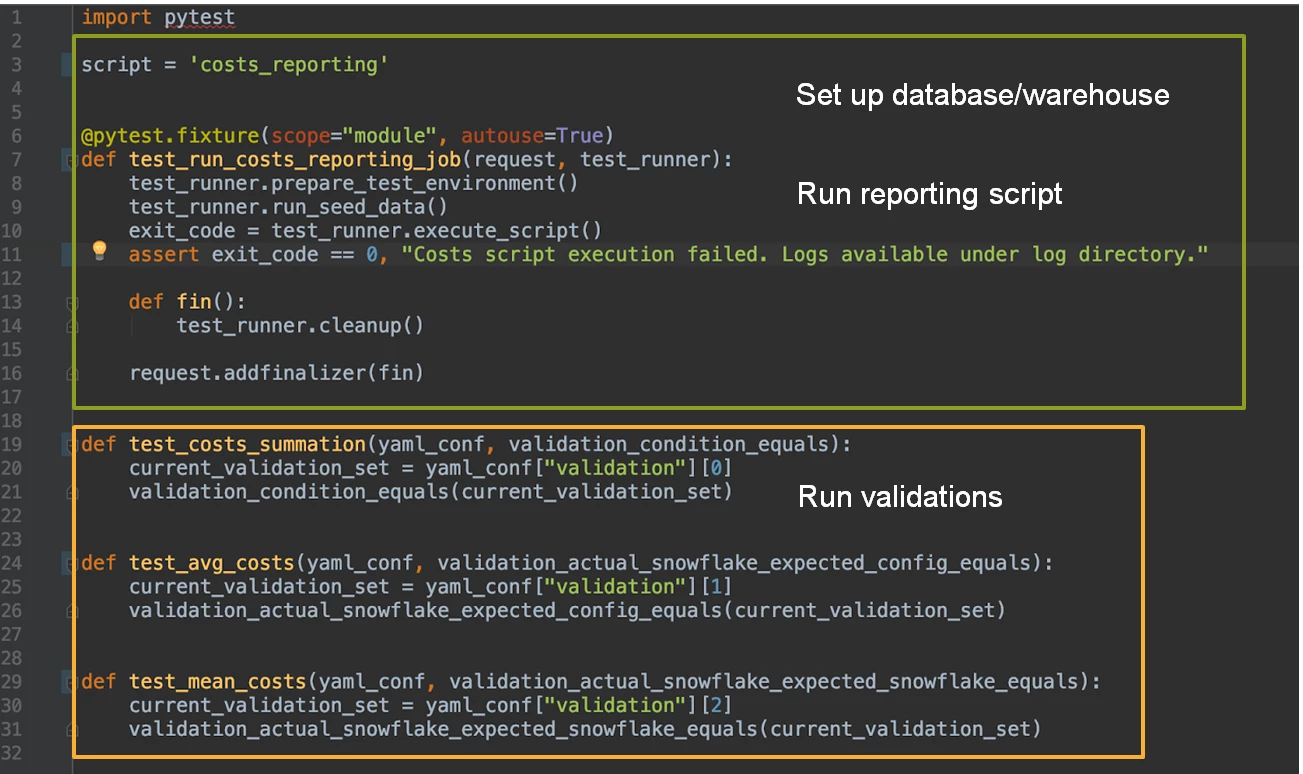
The file begins with the script, where we define the name of the reporting script to be tested. This helps the framework identify which query file the test will use, as well as provide a unique name for the database and warehouse that will be created for the test.
The first method shown in the image is @pytest.fixture, where we begin the test setup. Since the scope=”module”, it only gets executed once by the test. And, because autouse=True, this fixture will be invoked automatically.
To start running the application script, we prepare the test environment by creating an individual database and warehouse in Snowflake. Then, test_runner.run_seed_data() generates the test tables and the data to populate them. Once that is complete, the reporting script kicks off and runs against the generated test data.
Lastly, assert exit_code ensures the reporting script has run its course before request.addfinalizer(fin) steps in to handle the teardown method. This is followed by the validation queries, which have separate test methods to facilitate our understanding of any failures during this stage.
Currently, the framework supports three validation types:
- Expected results based on a Snowflake query, where the actual results are based on a different Snowflake query that is run against the output tables. This validation type is useful in conditions where the data to be compared is transient.
- Expected results based on a Snowflake query where the data is constant. For example, if the output table is expected to have at least five rows, then the expected result will have five rows.
- Expected results based on a conditional Snowflake query. For example, it would run a different SQL on a weekend than on a weekday. Based on the result of the conditional query, the comparison is performed on a separate set of expected and actual results.
Best practices for automating data warehouse testing
While automating testing with the new framework, we tackled a few challenges that, ultimately, led us to the following best practices:
Parallelize to reduce execution time
When reporting scripts are faced with processing an enormous amount of data, automation can become expensive and time-consuming. Parallelizing queries can significantly expedite runtime and plunge computing costs. In our case, we developed an in-house solution that detected the number of test files and created a new pytest sub-process for each file.
Generate test data
Production test data is typically transient and unreliable for testing. For example, if a customer status changes, the data may be stale and fall outside the processing window. Creating test data from scratch grants better control and allows the data to be repeatedly recreated and reused for testing.
Set strict validation queries
When validation queries are too broad, the results they return may be inaccurate. For example, if a column is missing in the validation query, the tests won’t flag any unexpected changes in that column. Adding as many filters as possible strengthens the effectiveness of validation queries and also helps catch regression bugs.
Order the result set
Result sets that are returned in any old order will inevitably cause false positives during the comparison process. For this reason, it’s advisable to add an ORDER BY clause to the query to ensure the result set is always returned in ascending or descending order.
Isolate test environments
When multiple instances of the same test are run simultaneously, the read/write on the tables may conflict with each other. This can lead to flawed test results. Isolating the test environments by creating a unique database and warehouse per test execution will prevent conflict and protect the integrity of data in production.
What’s next for this framework?
Currently, our data warehouse testing framework covers Snowflake’s input and output tables along with the Python scripts. We intend on extending the test coverage to include the Tableau reports and ensure complete end-to-end testing.
Additionally, we plan on adding more validation types to support any scenarios that may surface as we incorporate more reporting scripts into the test framework.
With considerable progress already behind us, we look forward to continue evolving our functional test framework and consistently provide accurate and dependable reports for Adobe Audience Manager customers.
For a deeper understanding of how and why we use Snowflake in our reporting stack, check out our post: Streamlining Adobe Audience Manager with Snowflake.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Dec 19, 2019