

☕[AT Community Q&A Coffee Break] 10/14/20, 8am PT: Jon Tehero, Group Product Manager for Adobe Target☕ [SERIES 2]
Join us for our next monthly Adobe Target Community Q&A Coffee Break,
taking place Wednesday, October 14th @ 8am PT
👨💻☕👩💻Register Now!👨💻☕👩💻
We'll be joined by Jon Tehero aka @jontehero, Group Product Manager for Adobe Target, who will be signed in here to the Adobe Target Community to chat directly with you on this thread about your Adobe Target questions pertaining to his areas of expertise:
- AI improvements
- A4T for Auto-Target
- Slot-based Recommendations
- General Adobe Target backend & UI
Want us to send you a calendar invitation so you don’t forget? Register now to mark your calendar and receive Reminders!
A NOTE FROM OUR NEXT COMMUNITY Q&A COFFEE BREAK EXPERT, JON TEHERO
REQUIREMENTS TO PARTICIPATE
- Must be signed in to the Community during the 1-hour period
- Must post a Question about Adobe Target
- THAT'S IT! *(think of this as the Adobe Target Community equivalent of an AMA, (“Ask Me Anything”), and bring your best speed-typing game)
INSTRUCTIONS
- Click the blue “Reply” button at the bottom right corner of this post
- Begin your Question with @jontehero
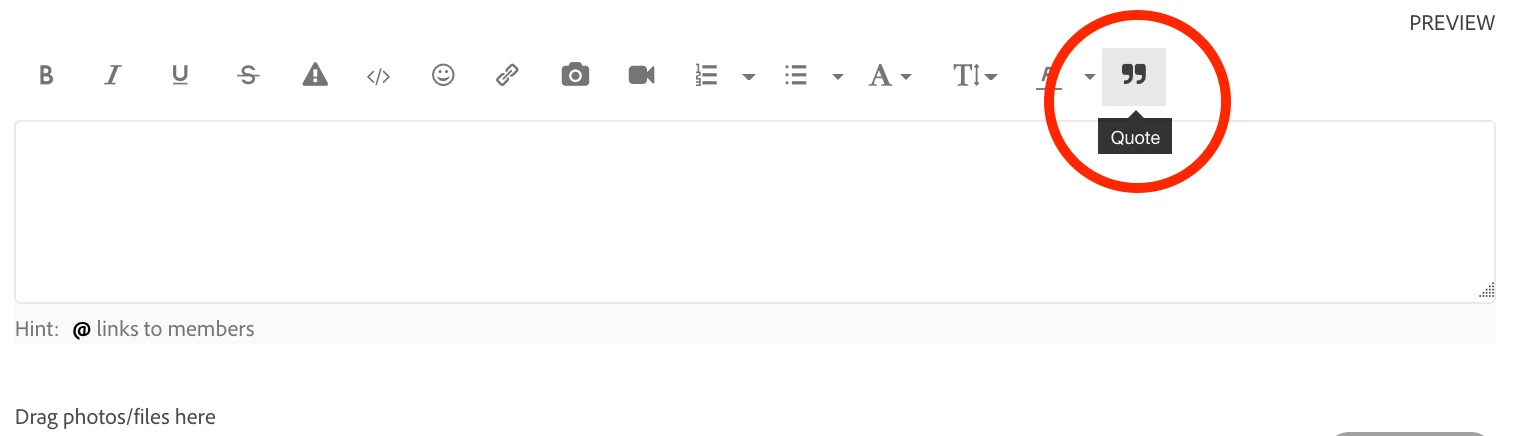
- When exchanging messages with Jon about your specific question, be sure to use the editor’s "QUOTE" button, which will indicate which post you're replying to, and will help contain your conversation with Jon

Jon Tehero is a Group Product Manager for Adobe Target. He’s overseen hundreds of new features within the Target platform and has played a key role in migrating functionality from Target's classic platforms into the new Adobe Target UI. Jon is currently focused on expanding the Target feature set to address an even broader set of use-cases. Prior to working on the Product Management team, Jon consulted for over sixty mid- to enterprise-sized customers, and was a subject matter expert within the Adobe Consulting group.
Curious about what an Adobe Target Community Q&A Coffee Break looks like? Check out the threads from our first Series of Adobe Target Community Q&A Coffee Breaks