
Using Akka Streams to Build Streaming Activation in Adobe Real-Time Customer Data Platform (Part 1)
Authors: Bianca Tesila, Nicolae-Valentin Ciobanu, and Jenny Medeiros
This is the first of a two-part series in which we explore how to build and roll out data-intensive applications to production using Akka Streams. In this first post, we focus on our challenges and learnings while setting up a resilient Akka Streams application capable of running at an enterprise scale.
Adobe Real-time Customer Data Platform is a service built on Adobe Experience Platform to help companies stitch known and unknown data into comprehensive customer profiles. They can then activate those profiles to deliver personalized experiences in real-time.
As customers interact with companies through a growing number of channels and devices, Adobe Experience Platform receives a tremendous amount of data every second. With most of this data entering in different formats and at an unpredictable throughput (i.e. from 10,000 events per second to one million events per second), our systems were under immense strain and at risk of being overwhelmed.
To deliver on Adobe Experience Platform’s promise of continuous performance, we embraced Akka Streams — a framework for building highly concurrent, distributed, and fault-tolerant applications. In this post, we share how we are leveraging Akka Streams to design a resilient streaming activation application capable of sustainably consuming data and resources for uninterrupted performance.
Streaming Activation in Adobe Experience Platform
One of the core functionalities for ingesting and seamlessly activating first-party data is Real-time Customer Data Platform destinations — a set of pre-built integrations with destination platforms, such as Google Ads and Amazon S3.
With destinations, customers can ingest their first-party data (either by batch or streaming) and activate it for cross-channel marketing campaigns, email campaigns, targeted advertising, and many other use cases.
While streaming activation is a seemingly simple function where you dispatch data to a set of configured partner destinations, there are a few important criteria to consider:
- Back-pressure: Carefully consume the data without overwhelming our systems — or those of our partners.
- Resilience: Ensure that the failure of one integration does not affect neighboring integrations.
- Asynchrony: Use computing resources efficiently and maintain the level of performance our customers expect.
Akka Streams is a powerful implementation of Reactive Streams designed to regulate the exchange of streamed data across an asynchronous boundary so that the receiving side does not have to buffer arbitrary amounts of data.
This is exactly what we need to meet the criteria above and build the streaming activation pipeline. The following sections of this post provide a glimpse into how we leveraged Akka Stream’s capabilities and the key points that aided us through our journey, which may also prove useful to developers on similar projects.
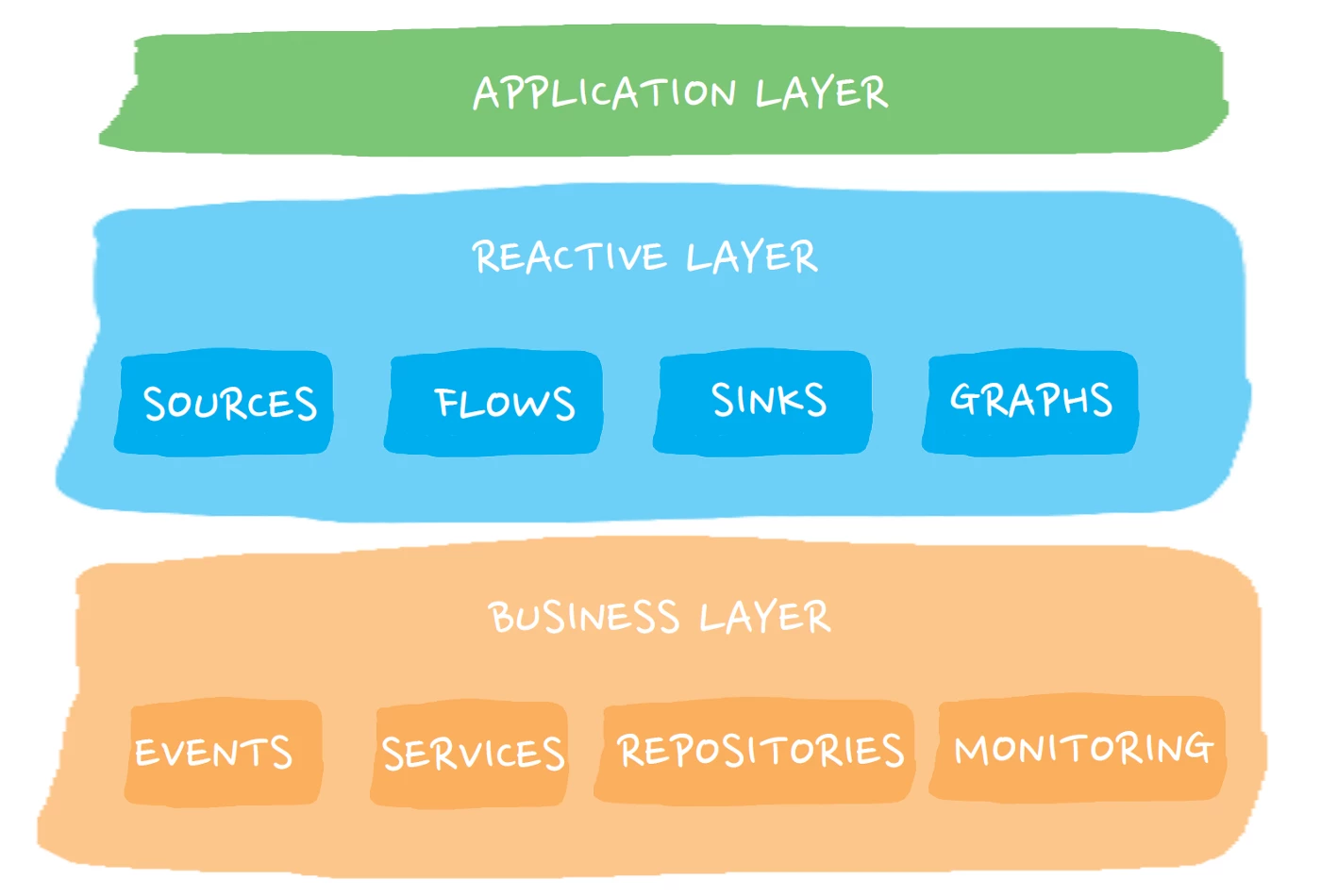
The building blocks of an Akka Streams application
To illustrate our process when building an application using Akka Streams, we will use a simplified architecture of a Real-time Customer Data Platform application as an example. The figure below shows said application, which continuously fetches profile updates from an Apache Kafka topic and dispatches them as HTTP requests to an endpoint.
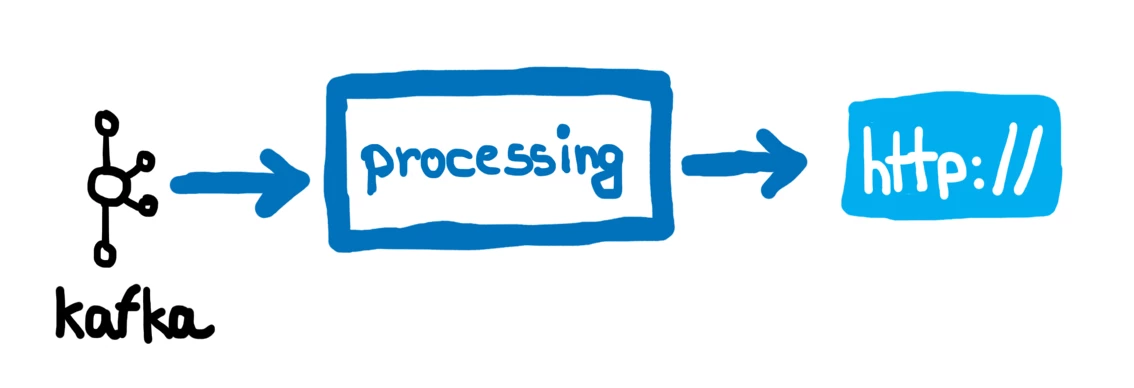
With this as our foundation, we can move onto sketching the pipeline for the application. For this, we enlist the help of Akka Streams DSL, which provides three core operators that we can leverage to sketch our pipeline:
- Source hydrates the stream with incoming data
- Flow encompasses all the transformation steps the data undergoes
- Sink where all the processed data is dispatched
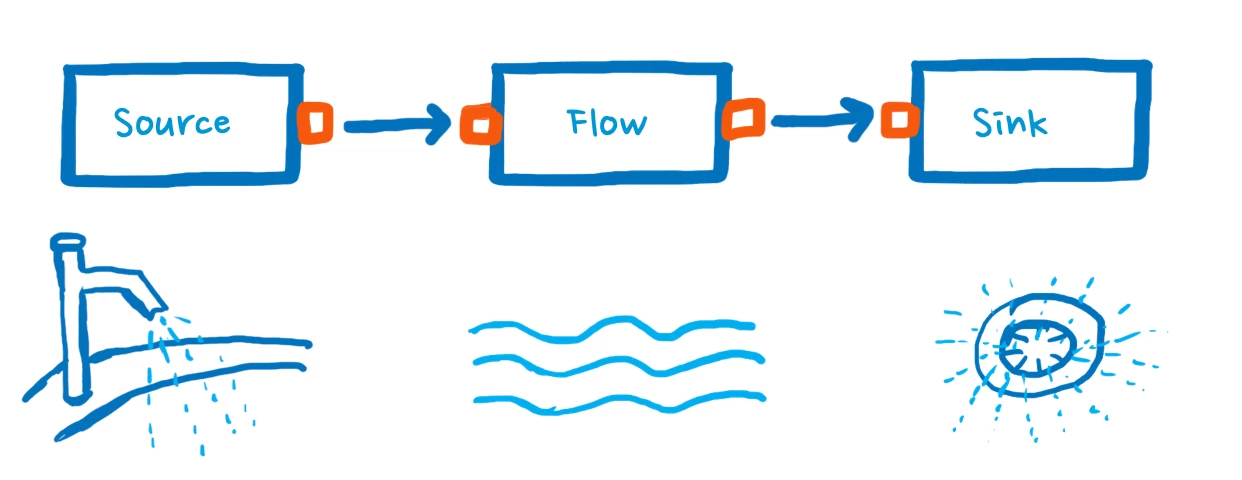
Like puzzle pieces, these blocks are composable shapes that can be defined through their connecting ports (outlined in red in the figure above). Source and sink have just one output, whereas flow has both an input and output. If you need to define a new shape with, for instance, two input ports and one output port, Akka Streams DSL makes it easy to do so.
In addition to sketching the pipeline, we can also start planning the domain model. The flow stage, for instance, has two interconnecting ports, which are described through the types: In, Out. The third type, Mat, is called the materialized value type.
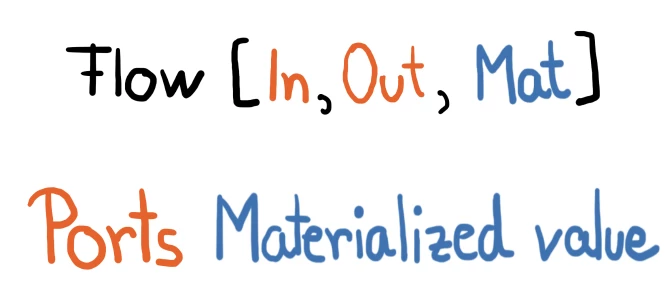
Besides providing the connectors to get data from one end to another within a stream, Akka Streams also provides the ability to use the materialized value to interact with the stream from outside this materialized value. This is where we can take an external decision on the stream, such as stopping the stream when a specific value is met.
Sketching the Akka Streams application
Next, we will move onto mapping our reference application. As shown in the figure below, we will start with the main stages and then add the types.
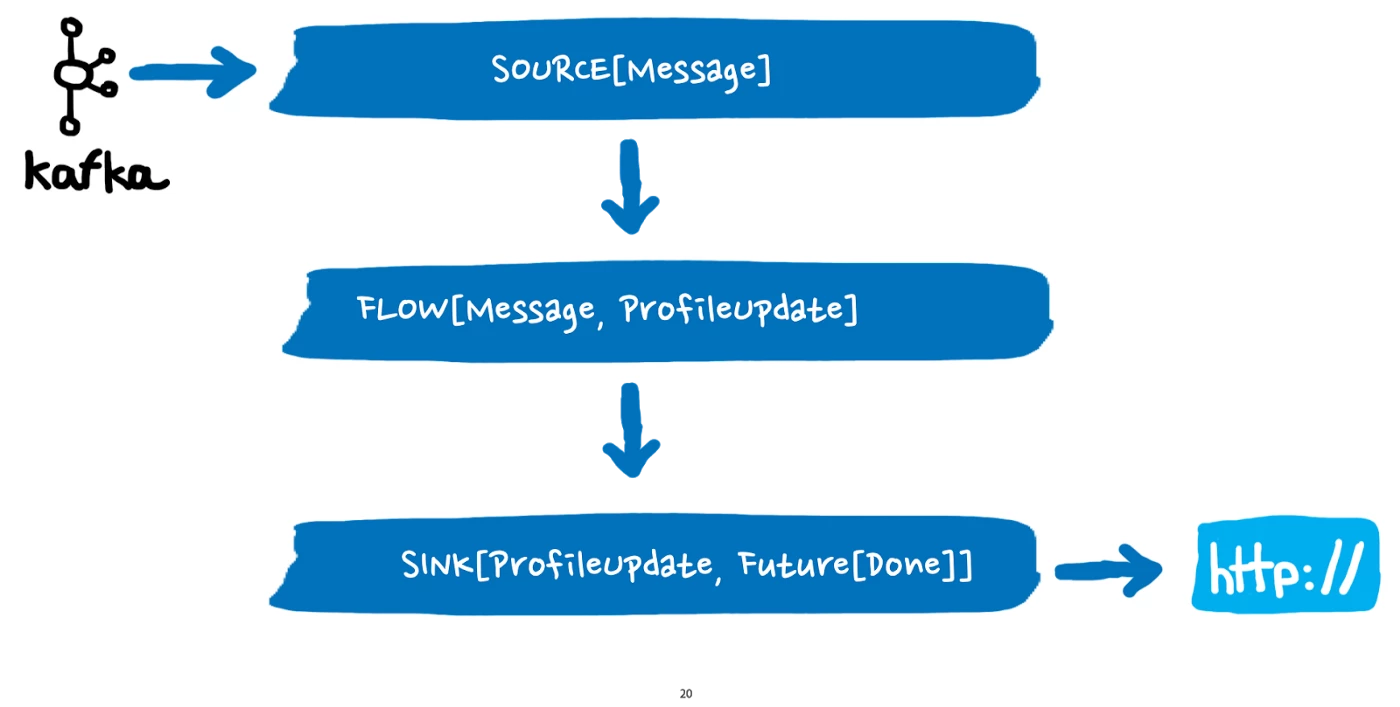
Granted, this data flow is over-simplified and skips over important failure handling, like deserialization, for example.
For this, we use Scala Either — a dual-type that can wrap a result or a failure. With Scala Either, we can easily transform business logic failures from a Profile Update event to an Either[ValidationError, ProfileUpdate], which is also an event. This is then processed downstream by specialized stages without impacting the entire data flow.
In our application, failures often arise from incoming invalid data or failed calls to the HTTP endpoint. Instead of throwing exceptions and dealing with the side effects, we simply add specialized stages that take care of these failure events. See the resulting graph below.
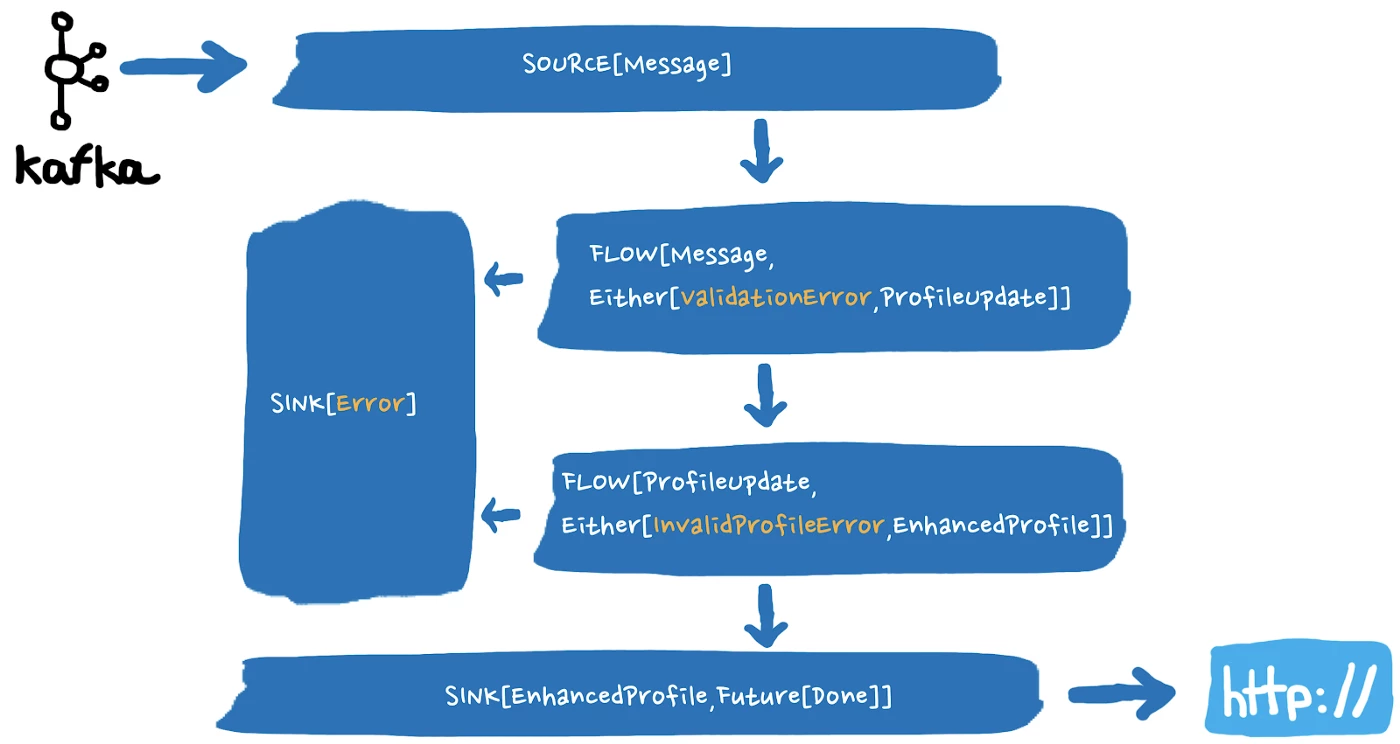
In this particular example, the extra sink presents the opportunity to define a dead letter queue or even a separate log file of erroneous events to ease debugging and audit. We use an extra sink in our actual application within Real-Time Customer Data Platform for this exact purpose.
From whiteboard to code
Now that we have defined our stages, types, and way of representing failures, here is what our application code looks like now:
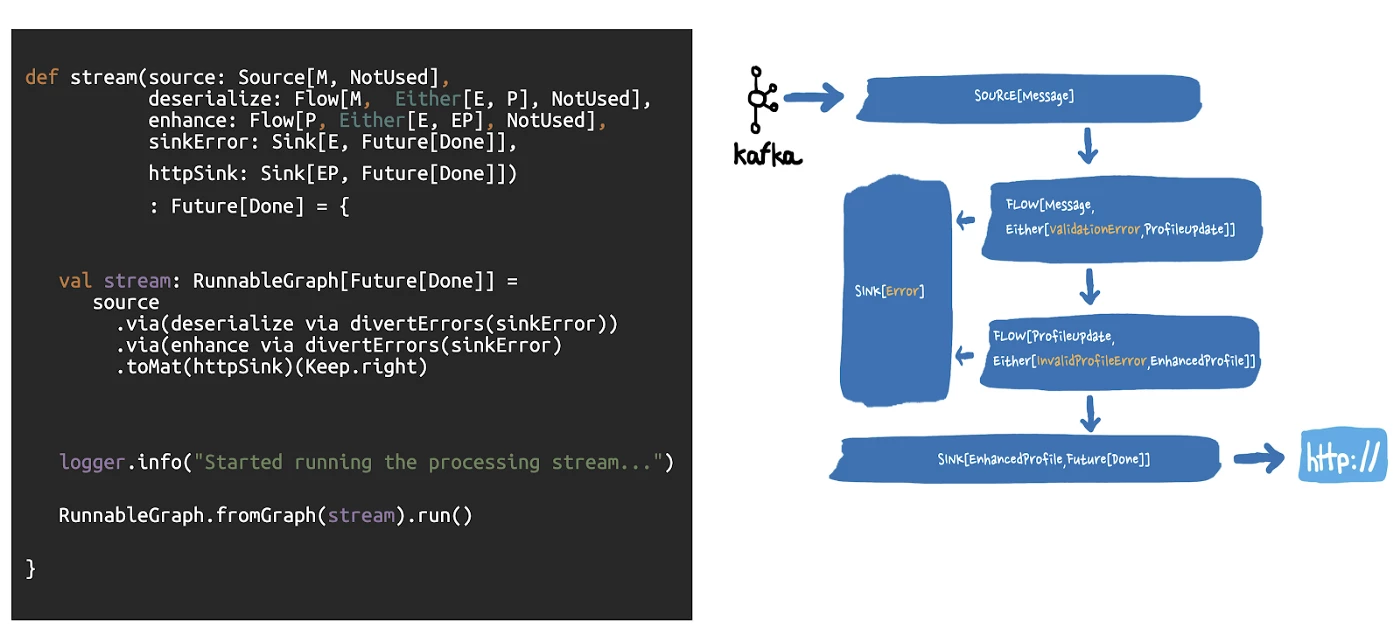
When a stream has been completed by having a source, a sink, and .run(), it becomes a RunnableGraph, as seen in the last line of the script above. This indicates that the stream is ready to be executed. The figure also shows that an Akka Streams application is almost a blueprint of the graph, and each stage is easily visible in the code — underscoring how each stage can be swiftly reused and reshuffled.
In our actual Akka Stream application, we have greatly leveraged this composability and modularity by separating the business logic from the stream definition. This enables us to reuse stages across multiple applications.
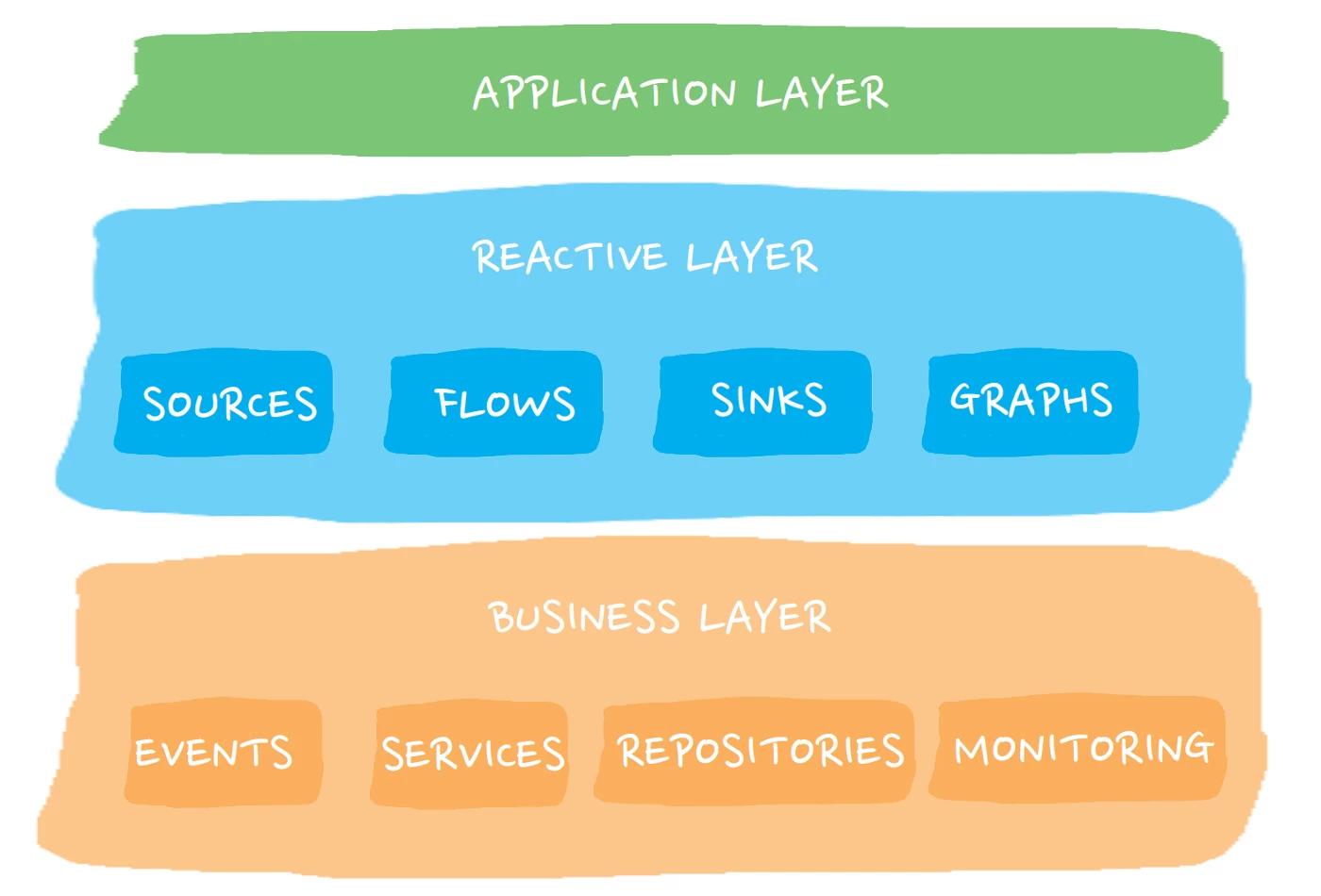
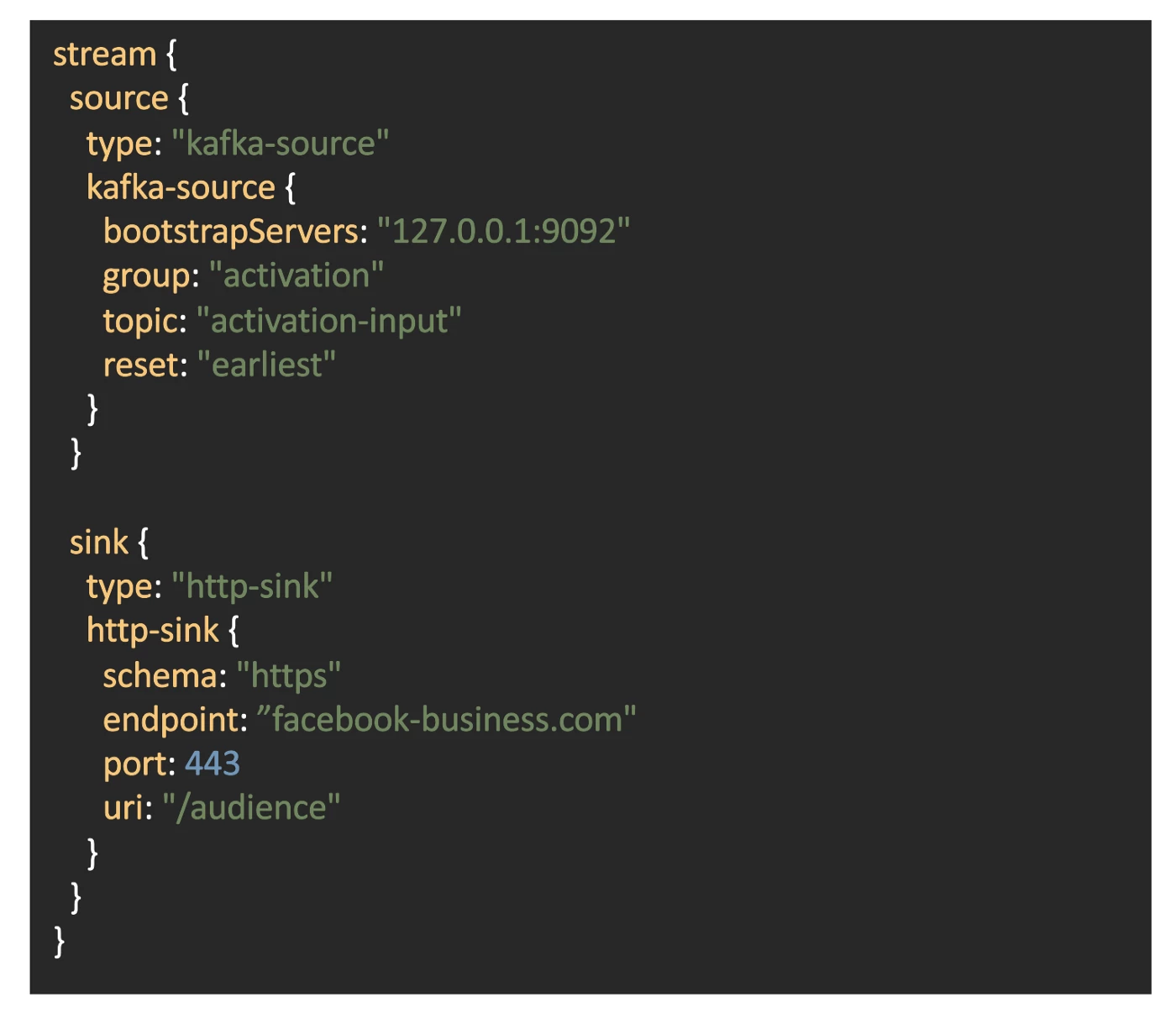
In addition, we have built our application in a configuration-driven fashion since using a different data source or sink should not affect the existing business logic and flow. See the figure below.
What’s next?
At this point, it would appear that we are ready to push the example application to production. But this is easier said than done, especially since we are aiming to meet all of our initial criteria to ensure a resilient and resource-efficient application.
In the second post of this mini-series, we will continue with our ongoing example and outline a few important considerations when rolling out an Akka Streams application in production. Furthermore, we will showcase a performance tuning use-case to illustrate how these considerations work together to optimize data streaming applications.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Additional reading
- Akka Streams documentation: https://doc.akka.io/docs/akka/current/stream/index.html
- Adobe Experience Platform Real-Time Customer Platform: https://www.adobe.com/experience-platform/real-time-customer-data-platform.html
- Real-Time Customer Data Platform documentation: https://docs.adobe.com/content/help/en/platform-learn/tutorials/rtcdp/understanding-the-real-time-customer-data-platform.html
- Real-Time CDP Destinations Overview: https://docs.adobe.com/content/help/en/experience-platform/rtcdp/destinations/destinations-overview.html
- Reactive Streams: https://www.reactive-streams.org/
- Adobe Experience Platform: https://www.adobe.com/experience-platform.html
Originally published: Jul 16, 2020