

Unifying Search over Isolated Microservices and Data Stores in Adobe Experience Cloud
Authors: Piyush Gupta, Subrahmanya Giliyaru, and Pratik Panchal

With the emergence of the microservice architecture pattern, several organizations build technology solutions involving data distributed across several microservices. Further, the number of such microservices and data stores within the organization continues to grow with the growing number of products, features, and capabilities.
Much of this data distributed among isolated data stores is surfaced to the end-users simply as one or more products and capabilities offered by the organization. But the end-user would want to quickly find desired data from across any of these products and capabilities using a centralized search bar or user interface. Given the isolation between such microservices and data stores, building such a unified text search solution poses fundamental problems:
- Each of the microservices needs to build an index exposing text search capabilities over its data entities, leading to duplication of effort and resources.
- A single search from an end-user needs to translate into a search over such multiple isolated indices.
- The isolated indices might follow different text search technologies and algorithms, thus losing the consistent experience in search results.
- It’s challenging to guarantee an appropriate ranking of the results, merged from such isolated indices.
Adobe Experience Cloud, comprising a number of diverse products and capabilities, like Adobe Experience Platform, Adobe Analytics, Adobe Target, and others, faced a similar problem. Each of these products exposed it’s own Search Bar and User Interface with its own search capabilities. This resulted in an inconsistent search experience as the user navigates across the offered capabilities. And each capability exposed search confined over it’s own business entities. What we needed was a unified search experience where a user could search for data that is persisted across data stores, and find the matching results appropriately ranked by relevance, from across any of these products in a single search operation.
Architecture Principles
In order to expose a consistent unified search over all such products and their business entities, we decided to build a unified search index that exposes searchable data from across all these products, while maintaining the isolation and separation between the various data stores and services.
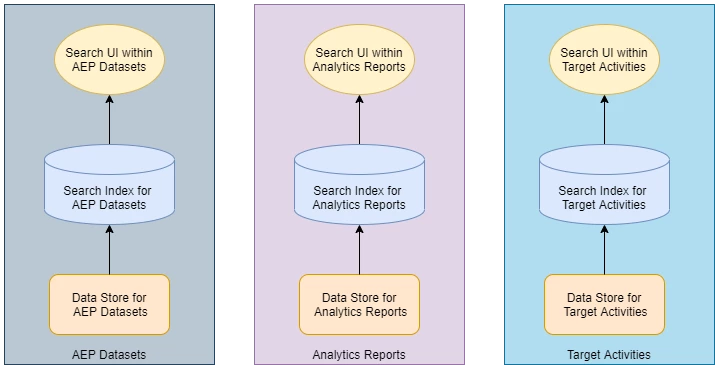
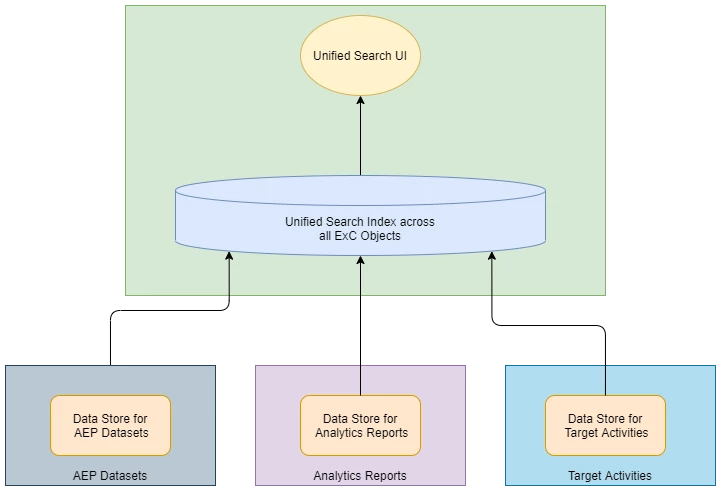
And as part of achieving this goal, we laid out 3 fundamental principles to follow in our system design, to help build a scalable and efficient system that could easily evolve over the growing number of products and data sources.
- Decoupling between Unified Search system as well the integrated data sources: While we needed a way to ingest data from all of the product services and data stores to the Unified Search Index, we also wanted to keep the systems de-coupled, such that the actual product workflows do not have any dependency on the Unified Search system, neither should the Unified Search system have any potential to impact the product services and workflows in any way.
- Minimum effort for easy onboarding: As we needed to integrate and expose search over continuously evolving and the growing number of products and services, we needed to minimize the effort required for onboarding any new product onto the Unified Search system, and a Self Service approach for maintaining any on-going changes required by any of the product services.
- Maintaining an eventual data consistency with the actual sources of data: The continuous data ingestion between the product data sources and the Unified Search Index is de-coupled. This can lead to the building up of a delta between the data exposed over search and the data within the product data stores, due to loss of events or errors in event processing. To address this potential problem, we need an on-demand and regular Data Reset workflow.
Proposed Solution
Following these fundamental principles, we laid out the following architecture for the Unified Search System.
Streaming Data Ingestion
In order to continuously ingest data from the various data sources, while keeping the systems disconnected from unified search, we followed Event Carried State Transfer model. The services owning the business entities and the actual source of data, publish events onto a Kafka Pipeline, for any create, update, or delete actions within the owning system. And each event also carries all of the desired searchable data fields for the given entity. Unified Search listens to all such change events, extracts out the searchable data fields from the event to generate the searchable data object, and updates the same into its Elasticsearch index.
This approach helps keep Unified Search decoupled from the data sources, with no direct interaction or inbound/outbound calls in between.
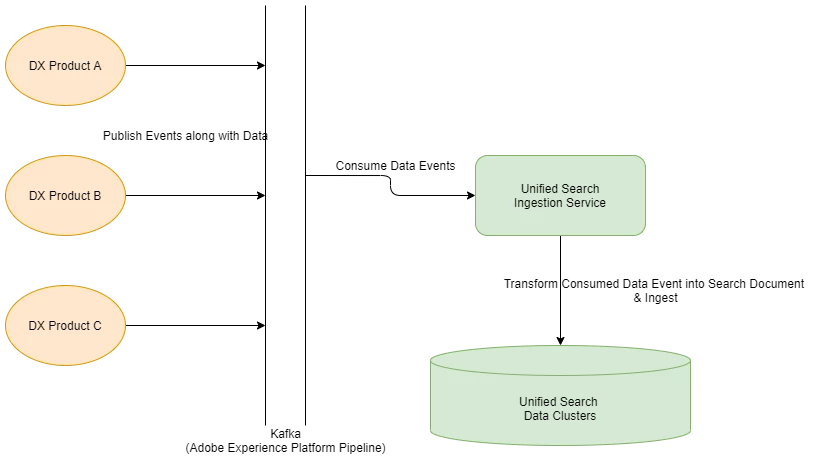
The structure of the published events from the products is prescribed by Unified Search, such that it understands the data format and can easily extract desired searchable data fields from the events of any product in a consistent fashion. But we came across cases when some of the products already had data events published onto Kafka Pipeline, and consumed in other workflows. In order to avoid unnecessary additional effort in such cases, we used a config driven approach to define the extraction of search document fields from any custom event structure, using JSON Paths. Such config could be managed by the product team itself using the Self Service Declarative Configs mentioned later below section.
Data Warm-up and Reset
Apart from streaming data ingestion from the data sources, Unified Search also needed a Bulk Ingest workflow to on-board all of the existing data from a product on-boarding onto Unified Search. And the same Bulk Ingest workflow would also be useful for performing Data Reset operation on-demand when required. Such a Bulk Ingest workflow could also be scheduled to run every few weeks to guarantee Data Consistency, thus following another one of our laid out principles.
Again a decoupling and a clear separation were needed between the product and the unified search system, such that the product database and its access is entirely managed within the boundaries of the product system itself, while the ingestion into the Unified Search Index could be controlled and managed within Unified Search system. Thus we needed a Shared Storage for sharing such a data snapshot from the product data source to the Unified Search system.
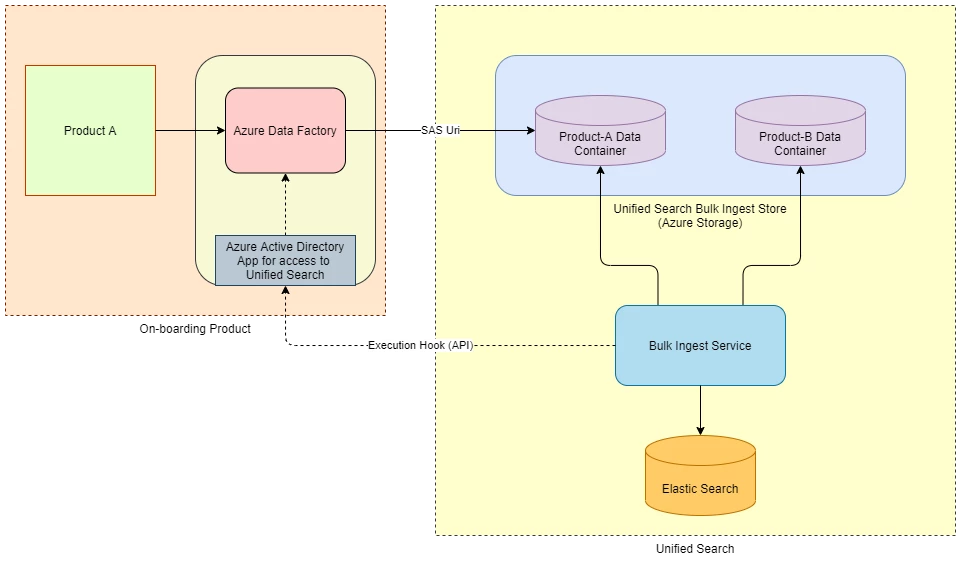
Data stores from different products use an ETL Tool (example: Azure Data Factory) to export a snapshot of its data into Unified Search Azure Storage Containers, and exposes an Export API which could be triggered by Unified Search system on demand. Using Azure Data Factory Pipeline to trigger such an export it’s easy to set up Azure Active Directory Application and Service Principal to grant Unified Search access to trigger such an export operation using Azure Data Factory Pipeline API. On the other hand, Azure SAS URI, passed from Unified Search to the product system in the Export API call, helps restrict the write access to dedicated Storage Containers assigned for the Product, and for a limited time period when the Bulk Ingest Workflow is run. Once the Data Snapshot is dumped into the Unified Search Storage, a Bulk Ingest Service reads the same for ingestion into Elasticsearch.
Declarative Onboarding and Integration
A Declarative on-boarding and Self Service workflow helps to minimize the onboarding effort into unified search. It’s as simple as adding a new YAML file for every new onboarding product, that captures all the configurations required by unified search, like the Kafka Topic, Export API, Data format, and Environments. Such configuration also allows a product entity to define custom Searchable or Filterable fields specific to its business objects and thus should be reflected in search results and options exposed to the user. And the product owners can create and update such on-boarding config file on their own, thus enabling a self-service mode for on-boarding and maintenance of the ingest and search experience for its business entities.
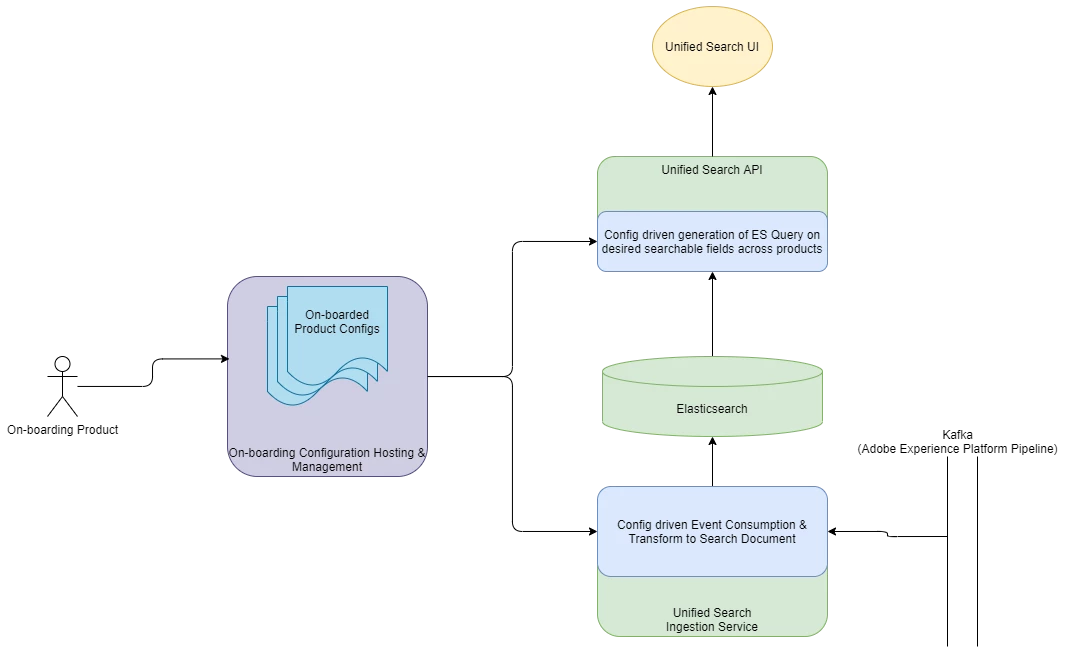
The Unified Search system, including the Ingestion and the Search API Workflows, uses such configs in runtime, such that any new product onboarding or config updates are reflected in the Unified Search system, in runtime, without manual intervention or development effort.
Challenges, Solutions, and Limitations
While we worked on building the Unified Search Index and on-board the different business product entities, we also faced certain challenges along the way.
Access Control on Unified Search Results
Since the unified search results comprise of business entities from across different products having different Access Control requirements, surfacing up such aggregated results while honoring the user permissions, was a tricky problem to solve. A user could have permissions to only certain types of business entities, while may not be authorized for others. And permissions within different business products followed a role-based-access-control in certain cases or an attribute-based-access-control model in others. To overcome this problem efficiently, Unified Search translates all such user permissions into appropriate filters in the Elasticsearch Query itself, such that the retrieved search results are permissioned for the user.
Ingestion Delay
Using the decoupled approach of Event Carried State Transfer means there is bound to be some delay between the data object created or updated within the actual data store of the product, and the change reflecting in the search results, thus not achieving an immediate data consistency. We found this delay to be in the range of ~1–3 seconds, well within our expectations from the search experience. And to further improve the user experience in line with the read-your-own-write consistency model, we introduced the concept of Recents in the Unified Search Bar, which shows the user a list his or her recently visited or created business entities, thus providing a quick way to navigate to such business entities without even having to search for the same.
Data Size-dependent Bulk Ingest Operation
The Bulk Ingest operation can be extremely heavy if the data size within any of the data sources is humongous, thus potentially taking a lot of time to complete. We had the size of any data source varying in the range of 20–50GB, with the bulk ingest operation taking time in the range of around half an hour.
Concurrent Bulk Ingestion & Streaming Ingestion
While the Bulk Ingest workflow is run for Data Reset operation, there is a potential race condition between the streaming ingestion updates and the bulk ingestion writes, and the longer the duration of the export operation and the bulk ingestion run, the larger the problem. There are a couple of ways to address this problem:
- Use last updated timestamps to validate that a bulk ingest operation doesn’t overwrite a more recently ingested document.
- Bulk Ingest operation for Data Reset is not expected to run often, but only once in 4–5 weeks. And moreover, the entire bulk ingest operation takes less than half an hour to complete, given the relatively low volume of the ingested data in a product. Thus after the bulk ingest operation is run, we simply reset the offset of the Kafka Consumer to the start timestamp of the bulk ingest operation. And this helps override and fix any such race conditions that happen during the bulk ingestion run.
Building a Unified Search Index across a growing number of business products, services, and entities within an organization, not only brings in search consistency for the users but also opens up the door for other huge numbers of possibilities. Instead of multiple isolated search systems managed by each of the product teams, a dedicated search team can now focus on evolving the search experience over such a unified search index. Improving the search capabilities and relevance, focus on performance, Personalization, Natural Language Search, analytical search using relationships between the data objects, are all just a few possibilities to go from here.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Adobe Experience Cloud
- Adobe Experience Platform Pipeline
- Apache Kafka
- Event Carried State Transfer
- Elasticsearch
- JSON Paths
- Azure Data Factory
- Azure Storage SAS URI
- Azure Active Directory Application and Service Principal
- Azure Storage
Originally published: Feb 11, 2021