
Simplifying the Data Science Lifecycle with Adobe Experience Platform
Authors: Tina Dilip Soni, Marina Mahtab, and Althaf Kudiyama Kandi

In this post, we explore how we can take a business problem to potential business outcomes using Adobe Experience Platform Data Science Workspace to quickly connect to data and build, experiment, validate and deploy machine learning models at scale.
While the model building itself has several steps like data cleaning, data preparation, feature engineering, and ultimately, model building, Adobe Experience Platform provides a much broader and wider end-to-end framework to accelerate the data-to-insights process, perform experiments through hyperparameter tuning, and creating a custom, personalized and intelligent publishing service which can be shared in just a few clicks. This service can be monitored, and retrained for continuous optimization of personalized experiences
The end-to-end machine learning framework in Adobe Experience Platform can be broken down into five interdependent steps.

Model building and recipe creation steps are performed by machine learning experts as this requires in-depth knowledge of machine learning algorithms and coding. Experimentation and service can also be performed by marketers with basic knowledge of models.
Machine Learning Framework in Adobe Experience Platform
The first step is learning from data. For this, we build a machine learning model to find patterns and insights within our collected data. We can think of our model as a set of instructions. What makes a machine learning algorithm different is that instead of having a set of instructions, we start with the data and the final outcome. The machine-learning algorithm then looks back at the data and works out the set of instructions to reach the final outcome in the most optimized way.
Let’s take an analogy to understand this better.
I am sure you must have had a burger. Let’s look at the process of making a burger and compare it with our model building process
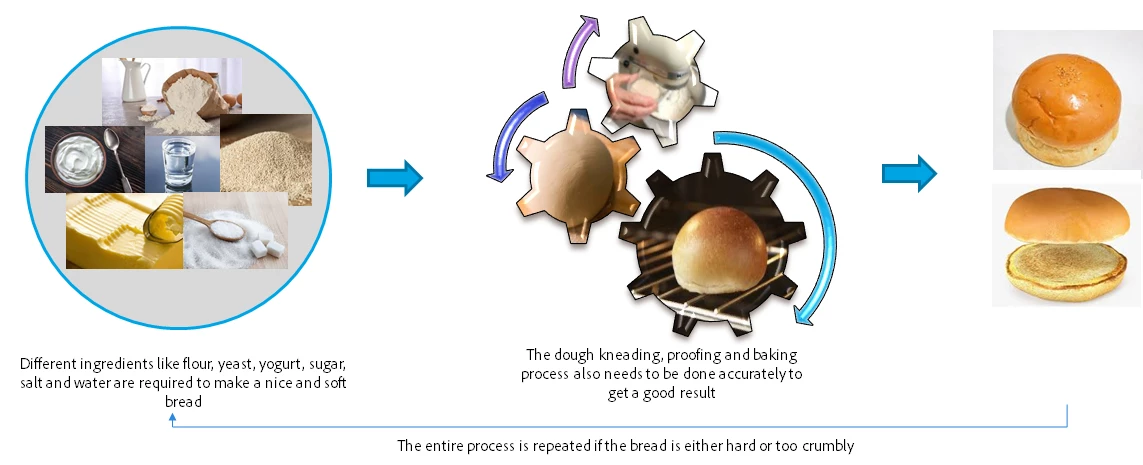
To make a burger, the first step is to bake the bread. Bread is made from ingredients like all-purpose flour, yeast, sugar, etc. Just like flour, yeast, sugar, and butter are ingredients to make good bread, data is the ingredient of our model. As important as the kneading and baking process is to bake a soft bread, transforming our data, using the right algorithm, and training our model to learn patterns or signals is also extremely important to get a reliable predictive model. It is essential to have the right quality, amount, and type of data and choosing the correct algorithm in order to get an accurate model.
Once the bread is made, you cannot change it. If the bread is not good, it needs to be remade. Similarly, once a model is finalized for production, you cannot change it.
What is a recipe?
A recipe is our term for a model specification and is a top-level container representing a specific machine learning, AI algorithm or ensemble of algorithms, processing logic, and configuration required to build and execute a trained model and hence help solve specific business problems. Similarly, a recipe helps in training different models by just changing the hyperparameters, but not the basic ingredient, the data.
If a model is already created, what is a recipe and how is it used in the entire machine learning framework?
A “recipe” is our term for creating a container or a repository for our set of instructions to continuously update and compare all versions of a model.
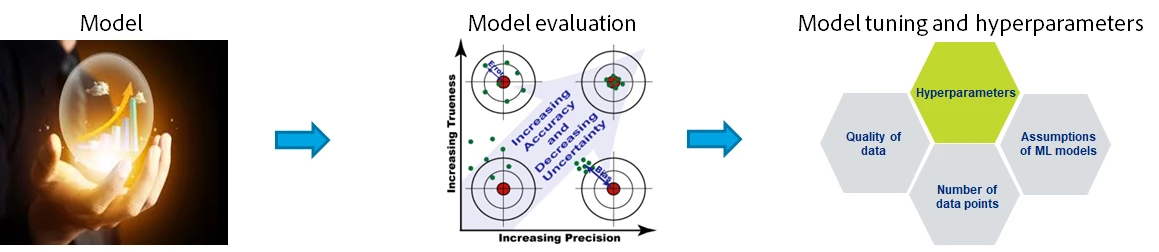
We know how a machine learning model works and as a data scientist, you might need to create multiple model instances by tuning hyperparameters, train, and track them and compare accuracy metrics to highlight the best performing model. The recipe component solves this particular problem by automating the entire process.
Let’s compare a recipe with the analogy of a burger! Once the bread is made, you can use different toppings to make the burger — meat, lettuce, tomatoes, olives, etc. as per your choice. If you want to try the different flavors, you keep all the toppings ready! You would wash and cut the vegetables, different types of meat, and lettuce.
Hyperparameters are user-defined configurations that we feed into the model before we start the machine learning process and are based on the judgment and best intuition of a data scientist or a marketer. Comparing to our analogy, hyperparameters are toppings of your model. Some of these hyperparameters are the number of clusters in segmentation, the learning rate of a neural network model, or the depth of a decision tree.
In Adobe Experience Platform, however, configurations are not restricted to hyperparameters. We can configure anything we want, for instance, the number of rows to train or say if we are building a churn model, the percentage we want to classify as a high probability to churn could be configured. This provides us complete flexibility to update the recipe we build.
Accuracy refers to the closeness of a measured value to a standard or known value. For example, if in the lab you obtain a weight measurement of 3.2 lbs for a given substance, but the actual or known weight is 10 lbs, then your measurement is not accurate. In this case, your measurement is not close to the known value.
Precision refers to the closeness of two or more measurements to each other. Using the example above, if you weigh a given substance five times, and get 3.2 lbs each time, then your measurement is very precise. Precision is independent of accuracy. You can be very precise but inaccurate, as described above. You can also be accurate but imprecise. For example, if on average, your measurements for a given substance are close to the known value, but the measurements are far from each other, then you have accuracy without precision.
Now, that we understand how to gauge accuracy let’s talk about how we can improve accuracy, while model accuracy is determined by a lot of factors that are not controllable such as quality or completeness of data, there are certain parameters that we can control such as specifics of an algorithm like number of iterations, batch size which can be updated and experimented with for achieving best accuracy. These parameters, that are not related to the data quality but to the model learning mechanism are called hyperparameters.
Experimentation
With configurations in place and our model saved as a recipe, you can begin your experimentation.
Let's understand this with the analogy we have been using. Hyperparameters are toppings of the burger. You may want to experiment with your burger with different toppings — one with mayo and one without, with meat and without meat. But the basic ingredient, bread, does not change. These toppings are important to add flavor to your burger. However, the bread remains the same.
“Experimentation” democratizes model tuning or update. A recipe can be accessed by a data scientist or a marketer who might want to update a model based on intuition or market intelligence. We can tune, refine, and update models from the UI with a single click. This recipe can be run multiple times with a click of a button on the user interface to trigger the entire process of model building by updating only the configurations or hyperparameters within the user interface itself.
Let’s say we run our model thirty times and for all these thirty times we get the accuracy and precision of all models. From these runs, we can now select the model that has the maximum accuracy and precision for production deployment.
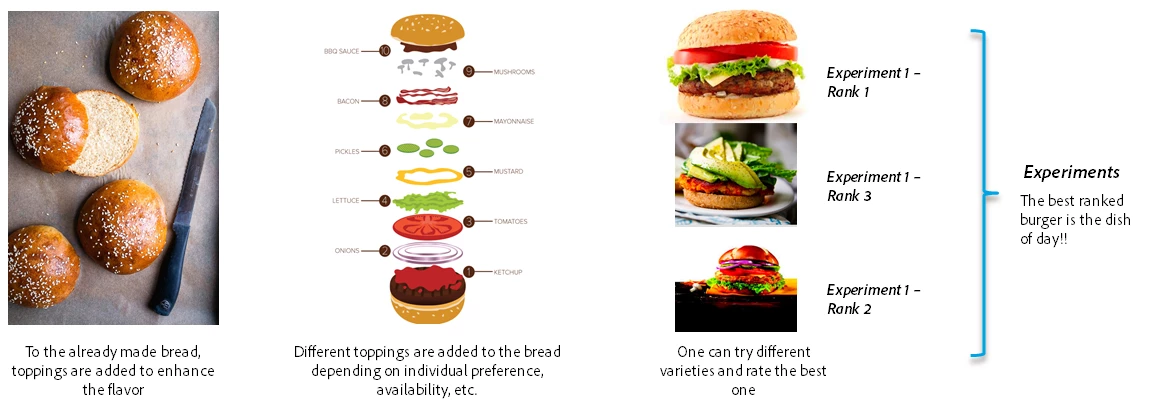
Just as toppings can be customized according to your choice, hyperparameters are important to customize the model to build a usable and scalable model. The point to remember though is that we cannot change the bread anymore! The structure of the data that goes into the recipe cannot be updated. In other words, the schema of our data is fixed at this point.
In machine learning, experimenting with hyperparameters is called hyperparameter tuning and the results from each experiment are called a model experiment. Accuracy and precision are evaluated for every experiment and the best one is selected for deployment.
Model as a Service
The fourth step entails the finalization of the optimized experiment.
Once you have customized your burger, it is properly wrapped or packed and served to you. Similarly, once we have the model with the desired accuracy, it can be deployed into production and used for all future purposes. Each time we want to draw insights, we can refer back to this optimized version. This is also what we call “scoring”, or using a pre-created machine learning model to get predictions. This optimized version is then packaged with a single click into a ‘service’ which is scheduled for continuous runs.
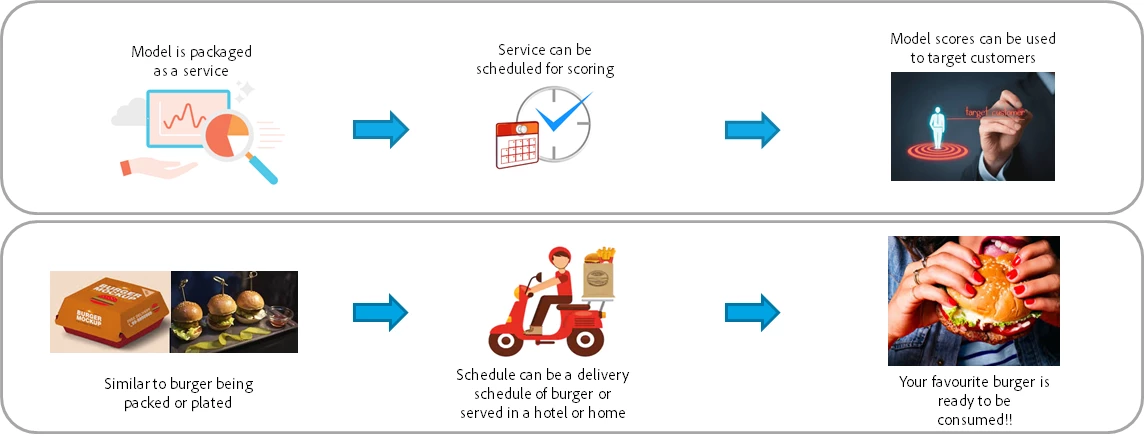
A deployed service exposes the functionality of artificial intelligence, machine learning model, or advanced algorithm through an API so that it can be consumed by other services or applications to create intelligent apps. This service cannot be changed or modified — no data can be added nor can hyperparameter tuning be done. Neither can basic ingredients be changed nor can toppings be added.
Model Consumption
The final step is to apply the scores from the packaged services and can be used to create compelling segments for effective targeting. For instance, target the high probability to churn customers with discounted offers.
This is enabled via Adobe Experience Platform Unified Profile. The insights from a data science model are added to a customer or a visitor profile and become available for building segments.
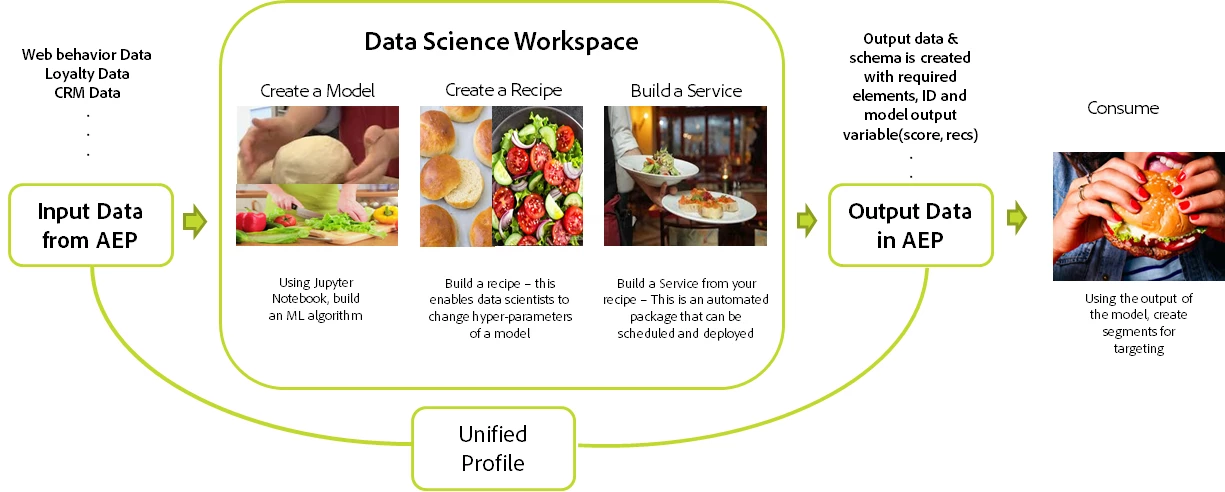
Adobe Experience Platform Data Science Workspace makes it easy to build ML models by enabling the data, providing a framework for data exploration and activation of insights within the same tool, while managing all of the underlying infrastructures, so we can train models and deploy at scale while also reducing the time to insight.
Extend the Framework to Bring In Your Own Model
The framework supports a wide range of customization to use any algorithm or tool such as Python or Pyspark depending on the requirement, what makes the framework truly flexible is the BYOM (bring your own model) feature. We can bring in pre-trained models and deploy within the platform by creating a recipe to continuously enrich the unified profile and optimize the customer journey.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Data Science Workspace Overview
- Adobe Experience Unified Profile Overview
- Create and publish a machine learning model walkthrough
- Bring your own model using the UI
- Train and evaluate a model (UI)
- Score a model (UI)
- Optimize a model using the Model Insights framework
Originally published: Nov 5, 2020