

Real-Time Data Deduplication Solution for Adobe Experience Platform Ingestion and Campaign Execution
Authors: Raminder Singh, Praneeth Palevela, Manjeet Singh Nagi, Prithwiraj Gupta and Pratul Kumar Chakravarty
In today's fast-paced automotive market, data is constantly streaming in from every direction—dealership visits, online inquiries, test-drive bookings, and much more. However this abundance of information can become a liability if duplicates run rampant. This blog delves into the details of a real-time data deduplication solution for Data Ingestion to Adobe Experience Platform(AEP) which can help organizations maintain trustworthy and high-quality data without manual intervention.
Our goal here isn’t just to lay out the technical roadmap, but to highlight how real-world challenges—like ballooning data sets and time-sensitive marketing decisions—can be tackled through a well-orchestrated data pipeline. We believe that having reliable, deduplicated data in near real time is instrumental for personalized experiences.
Our problem statement is with one of the Automotive Industry giants. Automotive organizations often face an enormous stream of operational and customer engagement data. Whether it’s capturing leads from a showroom, service center or recording an online enquiry etc. can produce large volumes of overlapping records, typical issues include:
o Duplicate records in customer streaming queues (e.g., repeated “test drive” registrations).
o Inconsistent data flows from third-party or legacy systems like clickstreams
o Redundant or stale events generated by automated scripts or system errors
o Not all the attributes from source systems are required for AEP Data Ingestion. A subset of attributes is ingested as per marketing needs. If an update occurs on an attribute which is not part of AEP data ingestion will result in data duplication from AEP perspective.
Owing to this data deduplication, high numbers of records per second are ingested to AEP beyond the streaming ingestion guardrails. These duplicates can snowball into inflated storage costs, conflicting reports, and misaligned marketing spend. With the help of data distiller, these duplicates can be filtered. However, this transformation process converts the data ingestion mechanism to batch fashion which will then pose a limitation for executing real time marketing campaigns through media and non media channels like SMS and WhatsApp. This solution ensures that only pristine data is ingested to AEP and businesses can orchestrate their marketing campaigns with higher efficiency.
We have detailed out the key objectives of this solution.
1. Data Quality (Integrity): A hash-based lookup in DynamoDB checks event identifiers in near real-time, guaranteeing only unique data moves forward. This ensures each incoming record is verified against recent events, eliminating duplicates before they propagate downstream.
2. Latency and Near Real-Time Processing: AWS Lambda triggers on small batch sizes with short batch windows, allowing the pipeline to process data with sub-minute latency.
3. Scalable Processing: Amazon Kinesis and AWS Lambda services provides auto-scaling functionalities. DynamoDB scales seamlessly for high write/read volumes without data loss or excessive delays.
4. Governance & Compliance: Integration with AWS CloudTrail, AWS Config enforced data governance policies across ingestion workflows.
5. Security: To protect data in transit and at rest, AWS KMS & TLS/SSL were configured respectively. Additionally VPC endpoints were created to isolate internal traffic, and restricted access to IAM roles.
6. Cost Efficiency: Pay-as-you-go services like Lambda and DynamoDB were preferred in designing to keep costs tied to actual usage, while deduplication saves compute and storage. These components avoided inflating cloud costs by storing or processing redundant events.
7. Omnichannel Activation : Dynamo DB data is published across Real-time Kinesis streams to ingest consistent and reliable data to AEP in streaming fashion.
Whilst the objectives are clear, there were learnings and challenges to call out which we have overcome in our solutioning journey -
1. High-Velocity Data Streams: Modern automotive data flows can spike unpredictably (e.g., promotional events), requiring a pipeline that handles large volumes with low latency.
2. Event Concurrency: Multiple, nearly identical events can arrive in short bursts. Efficient concurrency management is crucial so that duplicates are reliably identified under high throughput.
3. Complex Data Structures: Events often contain nested fields or multiple unique identifiers. Ensuring the right key (or combination of keys) is used for deduplication is non-trivial.
4. Latency Requirements: Marketing automation, personalization, and real-time analytics demand near real-time latency. Deduplication logic must be efficient enough to avoid bottlenecks.
5. Security and Compliance: Sensitive customer data must be protected and governed in compliance with standards such as GDPR, while still enabling deduplication logic to operate effectively.
High-level representation of overall architecture:
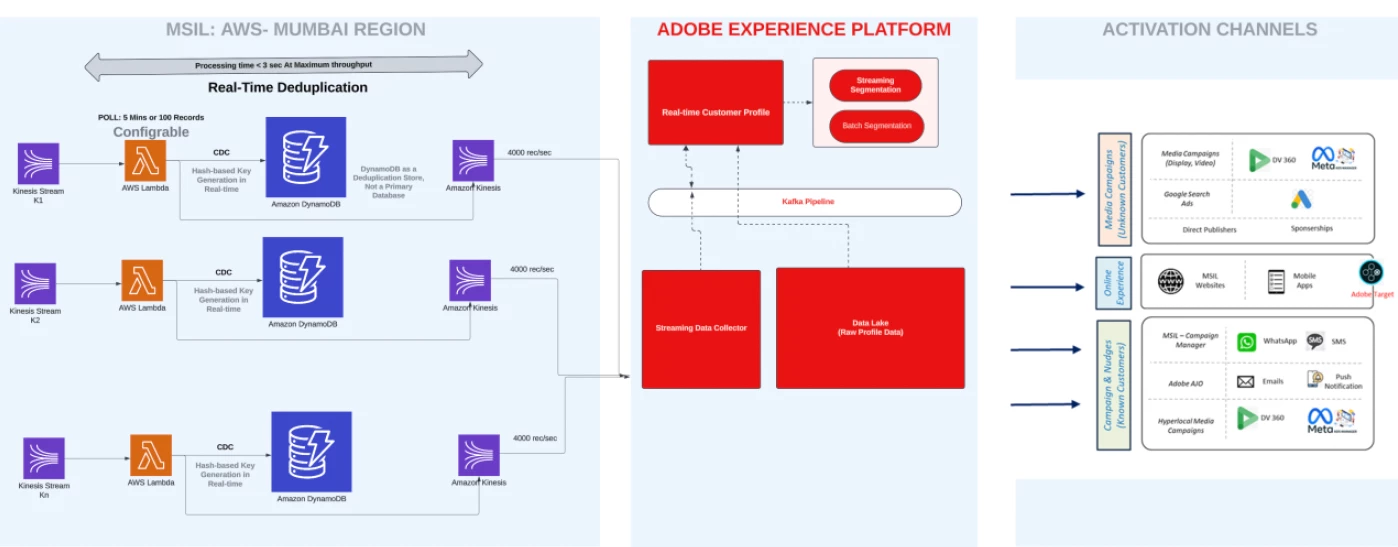
Data Deduplication Solution orchestrates multiple AWS services to funnel raw events into AEP, free from the burden of repetitive entries. Key components include:
o Amazon Kinesis (Source Stream): Aggregates real-time event data from dealerships, websites, or partner APIs.
o AWS Lambda (Deduplication Logic): Leverages a hash-based lookup strategy to instantly catch duplicates.
o Amazon DynamoDB (Deduplication Store): Maintains a short-lived registry of recent events, expiring older entries automatically.
o Amazon Kinesis (Target Stream to AEP): Relays verified, duplicate-free data for AEP ingestion.
o Amazon S3 + Amazon SNS: Records failed transactions and triggers alerts, allowing rapid incident response.
o Adobe Experience Platform (AEP): Consumes the curated data for personalized campaigns and analytics through OOTB Kinesis source connector.
Further delving into step wise solution details:
Step 1: Source Data Collection through Kinesis. It's configured with robust, fault-tolerant buffer for capturing real-time automotive events (e.g., test-drive confirmations, vehicle Purchase events etc).Data retention of two days window configuration enabled data replays incase of any failures.
Step 2: Event triggered AWS Lambda was created for deduplication. It gets triggered upon receiving a batch, commonly 100 records or we can set a timeframe. Workflow of this lambda is -
a. Extract an event_id by hashing all the attributes values required for AEP apart from timestamps through MD5 algorithm and assign it as a unique key from each record.
b. Check the corresponding entry in DynamoDB.
c. Skip if found; otherwise insert.
Step 3: Dynamo DB is the deduplicated data Store. A partition Key which is md5 hashed algorithm value is created for every record based in the attributes values. Applied TTL of 48 hours to ensure data storage overhead on Dynamo DB.
Step 4: Deduped data from Dynamo Db is published to target Kinesis Streams which are integrated with AEP for segmentation, enrichment, and multi-channel outreach.
Step 5: As part of Error Handling, a S3 Bucket is configured to capture an immutable log of any processing anomalies. SNS Alerts are set up to notify stakeholders whenever an error or conflict arises.
Additional configuration settings are required to maintain low latency by limiting batch size and window, support cost efficiency by processing only unique data, and contribute to scalability by automatically adjusting to data spikes. These configuration also align with governance objective via explicit fallback handling (S3) and error management.
o Batch Size: 100
o Batch Window: 300 seconds
o Concurrent Batches: 1
o Max Record Age: 3600 seconds
o Split Batch on Error: Yes
o Retry Attempts: 3
o Failure Handling: arn:aws:s3:::<S3_Path>
The future directions of this solution is to further drive enriched business value through -
1. Proactive Alerting: Integrate with Slack or ChatOps for immediate stakeholder visibility when deduplication thresholds are reached, or anomalies are detected.
2. Advanced Data Enrichment: Apache Flink provide real-time ETL and ingestion to AEP and stateful processing for augmented data insights, going beyond data deduplication.
3. AI-Powered Predictive Deduplication: Integrate ML models to detect near-duplicates or anomalies, improving data quality in cases where event identifiers may be inconsistent.
These enhancements benefit customers by lowering time-to-insight, improving data-driven decisions, and automating complex tasks, all of which drive improved marketing outcomes and ROI.
Finally to conclude addressing near real-time deduplication at the heart of the data pipeline strengthens organizations to gain substantial improvements in campaign execution, data quality and operational efficiency. This comprehensive approach alleviates the need of data transformation in scheduled/batch manner and resulting in limitation of running business campaigns in real time, inflated storage, contradictory metrics, and unoptimized marketing spend. Real time data solution integration with AEP like this drives ultimately fostering stronger, data-driven relationships with customers.