
(Part 2) Solving the Conundrum of Disparate Data and Different System Architectures to Build a Truly Unified Profile
Authors: Sandeep Nawathe and Jody Arthur

In Part 1 of this series, we described all the digital components enterprises need to develop a 360-degree view of their customers and the capabilities and limitations inherent in the technologies available to help them do that. Here in Part 2, we + a new approach — one that unifies disparate data sources and system architectures to develop a Unified Profile that is actionable in real-time.
With the proliferation of information technology systems, an enterprise’s customer information is often fragmented across disparate sources hampering its ability to fully leverage the power it holds. Delivering the real-time personalized experiences that today’s consumers demand starts with building a holistic understanding of the customer, a Unified Profile.
In Part 1 of this series, we described the digital components needed to develop a unified, centrally accessible customer profile that allows an enterprise to target people with personalized cross-channel experiences at the right time, based on behavioral insights and customer attributes.
In exploring the landscape of available technologies, we also illustrated why enterprises today must go beyond solutions such as customer relationship management (CRM), email service providers (ESP), data management platforms (DMP), and customer data platforms (CDP) to address the growing enterprise’s need to consistently and proactively recognize consumers interacting with it through online and offline channels. This holistic recognition is critical to building the 360-degree view of the customer necessary to ensure the best customer experiences through one-to-one marketing, customer support, sales, and advertising.
A Unified Profile architecture
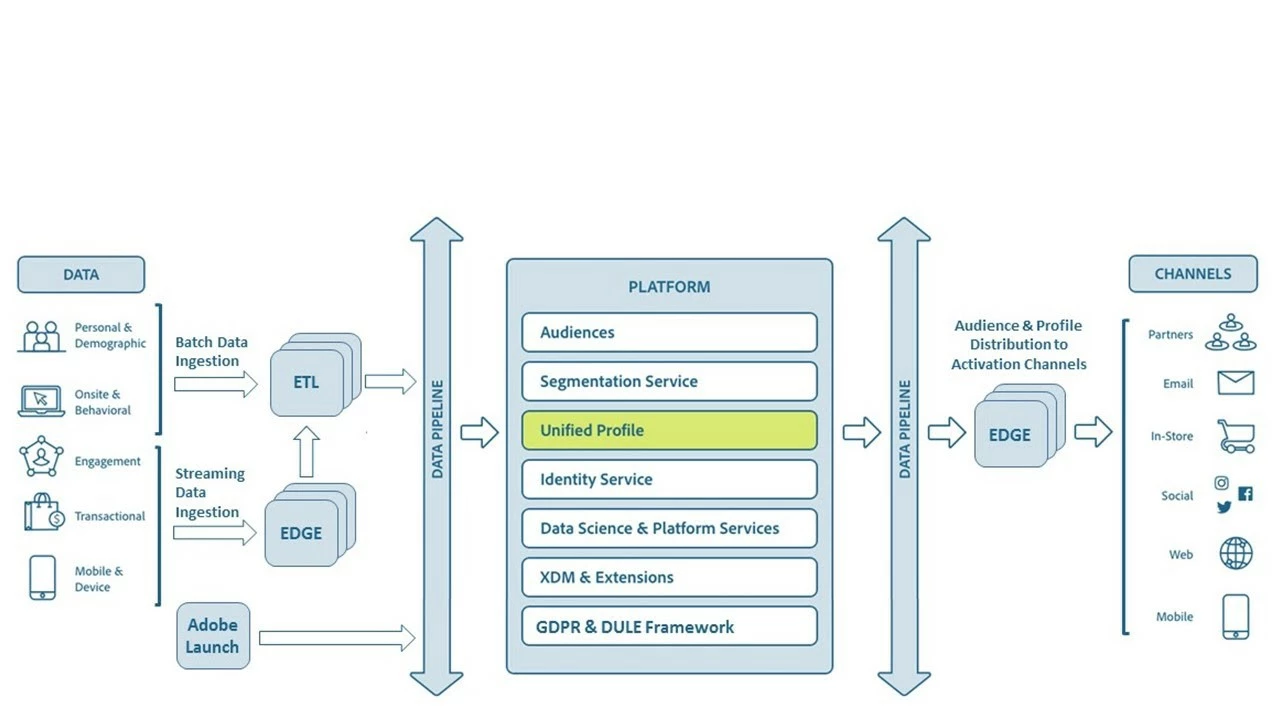
Adobe Experience Platform and its Unified Profile architecture together provide all the necessary components to build a holistic view of the customer (Figure 1):
- Experience Data Model (XDM) supports batch and streaming data ingestion through Adobe Experience Platform Pipeline and provides Extract, Transform, Load (ETL) capabilities to enrich the Unified Profile as new data flows into the system.
- Infrastructure of the Identity Graph provides the backbone for identity resolution and the corresponding relationships.
- Adobe Experience Platform’s Profile Query Language (PQL) provides the ability to query the profile repository for segmentation and building audiences.
- A robust set of APIs available through Adobe I/O make the Unified Profile easily accessible and edge computing capabilities that allow for segmentation in seconds.
- Adobe Experience Platform’s Data Usage Labeling and Enforcement (DULE) framework provides the data governance needed to ensure compliance with data privacy regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act of 2018 (CCPA).
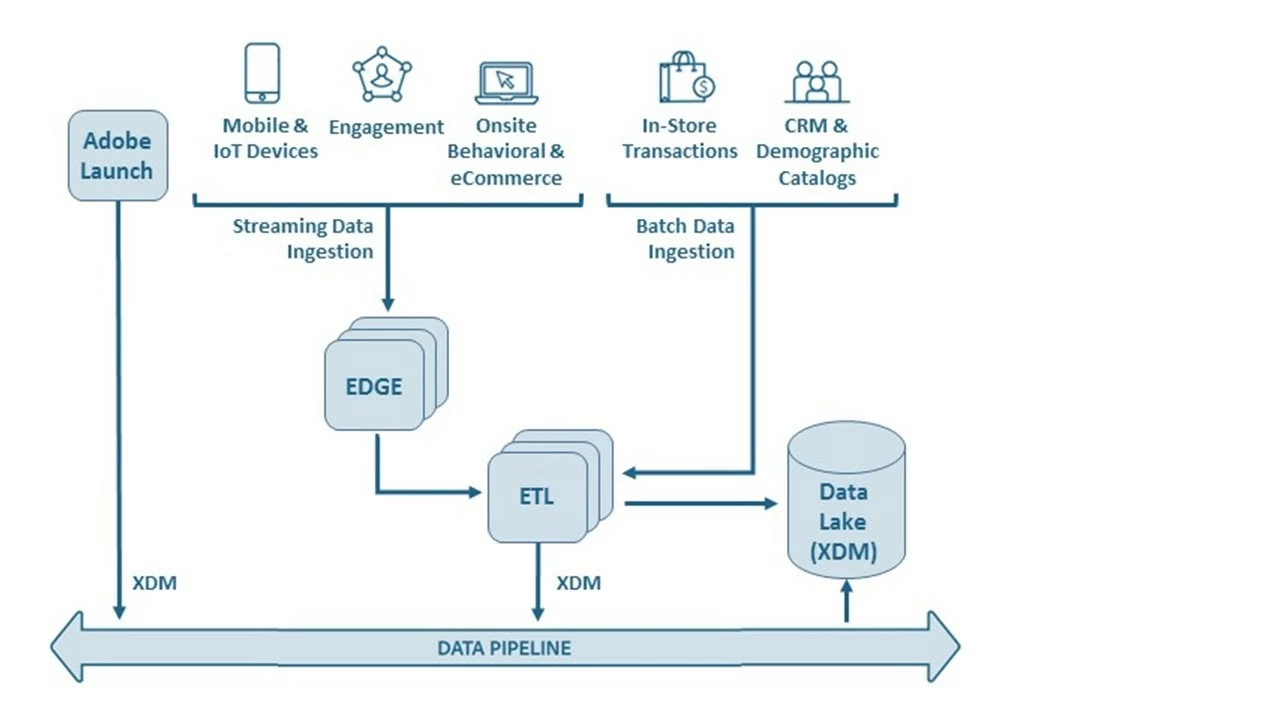
Data ingestion
Adobe Experience Platform architecture provides scalable data ingestion through Adobe Experience Platform Pipeline, which supports both batch and streaming data (Figure 2). Enterprises can use the built-in Adobe Experience Platform Edge or Adobe Experience Platform Launch with various other industry-standard tools to provide the ETL logic necessary to convert incoming data into XDM format. Batch ingested data is stored in the platform’s data lake while the streaming data is made available through Adobe Experience Platform Pipeline for any client once the ETL is complete.
Experience Data Model
In Part 1 of this series, we explained the importance of having a data model that provides the flexibility needed to combine offline data and online data for all the different types of workloads necessary to build a holistic customer profile. Unified Profile uses Adobe Experience Platform’s Experience Data Model (XDM), a semantically rich data model capable of normalizing data from any channel using standard schemas and schema-based workflows. XDM data models provide a standardized foundation upon which enterprises can build unified profiles and customize them as needed using XDM schemas with various Adobe Experience Platform services.
Built on the XDM, the Unified Profile contains:
- A simple key-value map where every key-value pair complies with the XDM schema. For example, demographic data can be considered as a key-value map of fields, such as { age:25, gender:Male, … }.
- An ordered set of time series events, where each time series event is a finite record containing the timestamp and one or more field(s). The data set consists of time-series events from one or more data collection channels, and each time series event complies with a channel-specific XDM schema.
- External dataset references, such as product catalogs, store directories, and store inventories, which are maintained in a separate lookup store made accessible to the profile through warehouse-style joins while the Unified Profile data model maintains a reference key to individual records.
In contrast to a traditional relational database model in which identity data is organized in tables based on type, the Unified Profile is considered a collection of documents, where each document stores part of the profile data in an unstructured or semi-structured manner. This model performs most of the operational and analytical workloads necessary to build a unified profile, such as querying for batch segmentation workloads, real-time lookups and updates for streaming segmentation, and machine learning workloads.
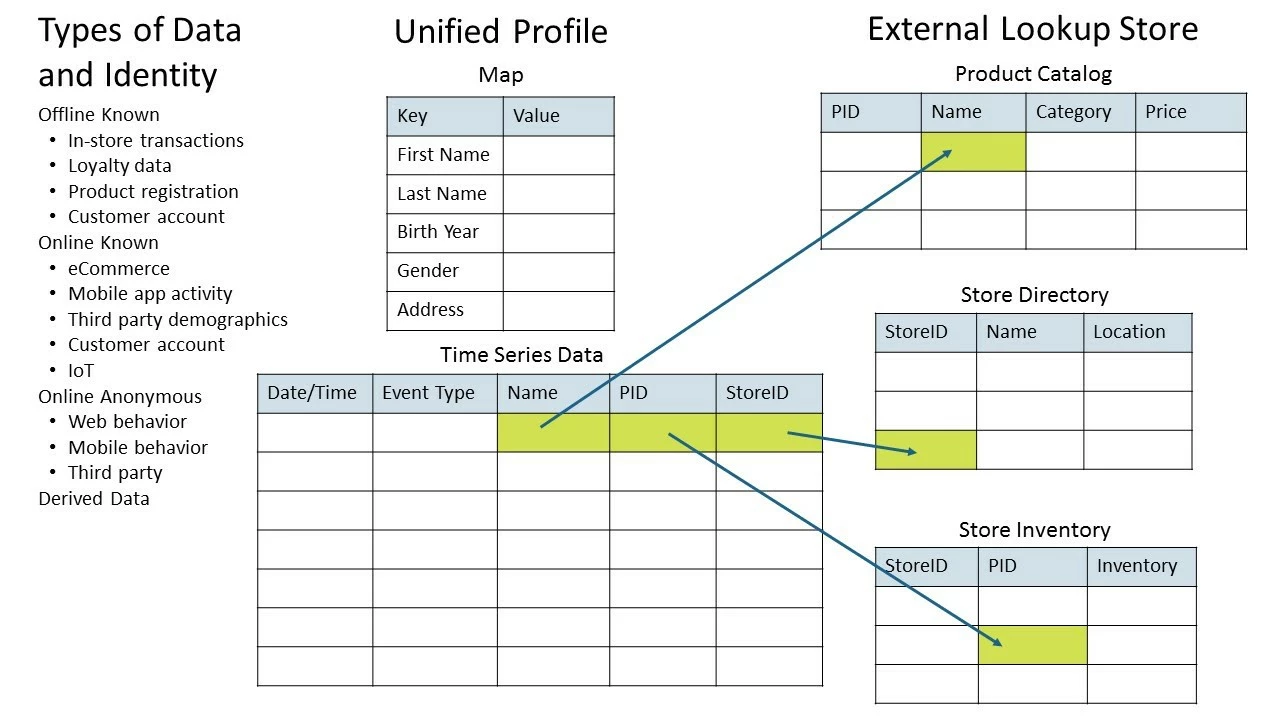
Maintaining external object data such as product catalogs and store inventories in a separate lookup store does require a tradeoff when it comes to interactive querying, However, that trade-off allows enterprises to achieve high performance with lower costs with warehouse-style joins.
Unified Profile offers a highly denormalized (or pre-stitched) view of a customer’s data. Denormalizing customer data avoids expensive runtime joins that are often necessary for profile segmentation queries. For example, the data handling of time-series events becomes easier because the complexity of self-joins is substantially reduced in time-series queries.
This approach does not lend well to business intelligence (BI) and reporting-style use cases, so a duplicate copy of this data is maintained in the data warehouse to facilitate BI and reporting. To simplify the consistency and join issues across these two systems, Unified Profile provides frequent snapshots of data.
Stitching together customer data
Most customers today have many different identities created through different interactions with a brand, and each enterprise dataset might contain one or more types of identities (Figure 4). Each identity represents a fragment of a customer profile and the relationships between them might not be known until identity matching is performed on the new data flowing into the system.
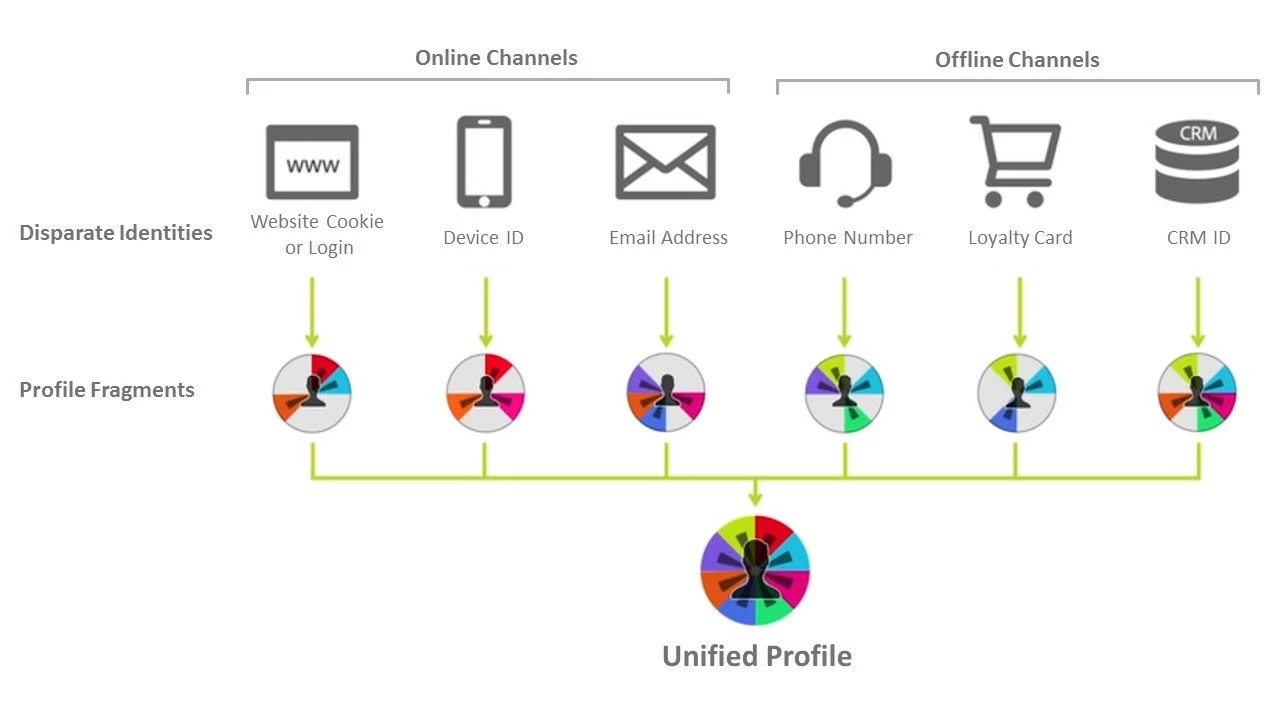
As enterprises collect these identities, XDM places each fragment in its own container in the enterprise’s data lake. Storing each profile fragment in a separate container allows identity relationships to evolve independent of profiles. The Unified Profile is created by using a run-time merge of all the profile fragments in the data lake.
Profile fragments are ingested from multiple data sources. Each data source has its own unique way of describing identities, which can create conflicts where there are different values for the same XDM field. The standard approach for conflict resolution is deduplication in which one object is created and any conflicts are eliminated during the ETL process. This approach cannot be used with Unified Profile because the relationships between the identities for the profile are not known prior to the ETL.
Unified Profile instead relies on what is known as “lazy merge” which applies a set of rules created by users or machine learning algorithms to resolve the conflicts at run-time. As a result, there is no loss of high-fidelity data in profiles through deduplication. And, while the run-time profile merge can add computing costs to the development of the profile, those costs are mitigated with highly efficient algorithms.
This approach also makes it easy to handle privacy regulations when dealing with a combination of related PII and non-PII identities. For example, with strong data governance built into Adobe Experience Platform, merge policies can be set to make email-based identities and any corresponding profile fragments off-limits when performing profile segmentation for display advertising.
Identity Resolution
Adobe Experience Platform uses Identity Graph to keep track of all the identities for profile fragments (anonymous or known, online or offline) that consumers create when they interact with a business. The relationships between those identities, which are established by Adobe Experience Platform's Identity Service through a combination of deterministic signals, probabilistic matching, and machine learning techniques, are also stored in the Identity Graph.
Identity Graph is designed to be a low latency and high throughput system.
While a Unified Profile lookup starts with one identity, most of the workloads performed on profiles, such as batch or streaming segmentation, require an enormous number of lookups. With an Identity Graph, when a call is made to fetch all the related identities, the profile fragments matching those identities are fetched to build the Unified Profile.
Activation Profile
The Unified Profile data model described here offers a high-fidelity view of all customer data, one that can easily grow to be hundreds of kilobytes (KB) of data for a single customer profile. For example, with time-series data, one page-view or other touchpoints can easily be a 1KB payload, and a customer might have hundreds of page views on a single website. Fast access to this data is necessary for real-time activation use cases, such as web personalization, advertising, or mobile marketing.
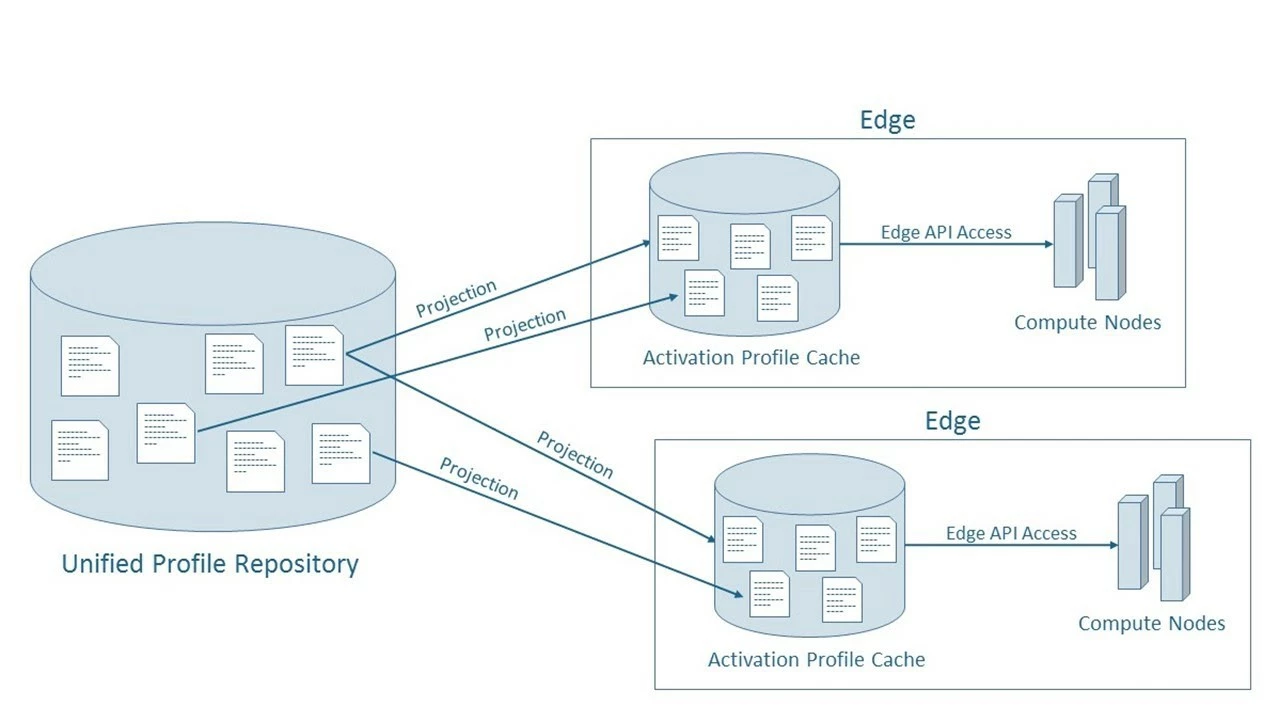
Real-time activation occurs in a large and geographically distributed network of decision-making nodes that Adobe Experience Platform calls the Edge (Figure 5). Edge activation use cases require only a subset of Unified Profile data for their decision process for a specific point in time. Acquiring this subset of data is accomplished by creating one or more projections that allow the creation of smaller “Activation Profiles” with new computed attributes based on the activation use case, while a loose consistency model keeps the Activation Profiles consistent with the main Unified Profile.
Activation Profiles can be used to meet both real-time and standard use cases. For example, an Activation Profile can be built to meet the DMP use case where anonymous user profiles that contain audience membership and behavioral traits are needed for demand-side platforms (DSPs).
Privacy Regulations and the DULE Framework
Data often comes with strings attached. Restrictions can arise from privacy regulations for the use of consumer data, from the contractual obligations on purchased data, or simply from the way an enterprise wants to handle its data. As data is shared across all activation channels, it is necessary to understand and comply with all the restrictions that may apply to that data.
The Unified Profile is built on Adobe Experience Platform, which offers strong data governance based on the Data Usage Labeling and Enforcement (DULE) framework to help enterprise customers ensure they are complying with all privacy regulations. The DULE framework defines a set of metadata and the associated permissible values for each XDM data schema, defines rules for combining data and provides guidance on how the metadata can influence data usage decisions.
Adobe Experience Platform also provides an API-based framework called GDPR Central Service to help enterprises navigate GDPR regulations. Both the Unified Profile and Identity Service achieve GDPR compliance by implementing this API.
The Unified Profile store
The Unified Profile store is built to handle big data. This is necessary because, with the capability of ingesting both batch and streaming data, an enterprise might have a petabyte or more of customer data to manage. Based on the volume of data in the profile store, batch segmentation queries must have scalable access to the data at rest, while the real-time segmentation queries need high throughput, low-latency access to keep up with fast-moving streams of events. Given the different input/output (I/O) and compute requirements of these workloads, each needs to be independently scalable.
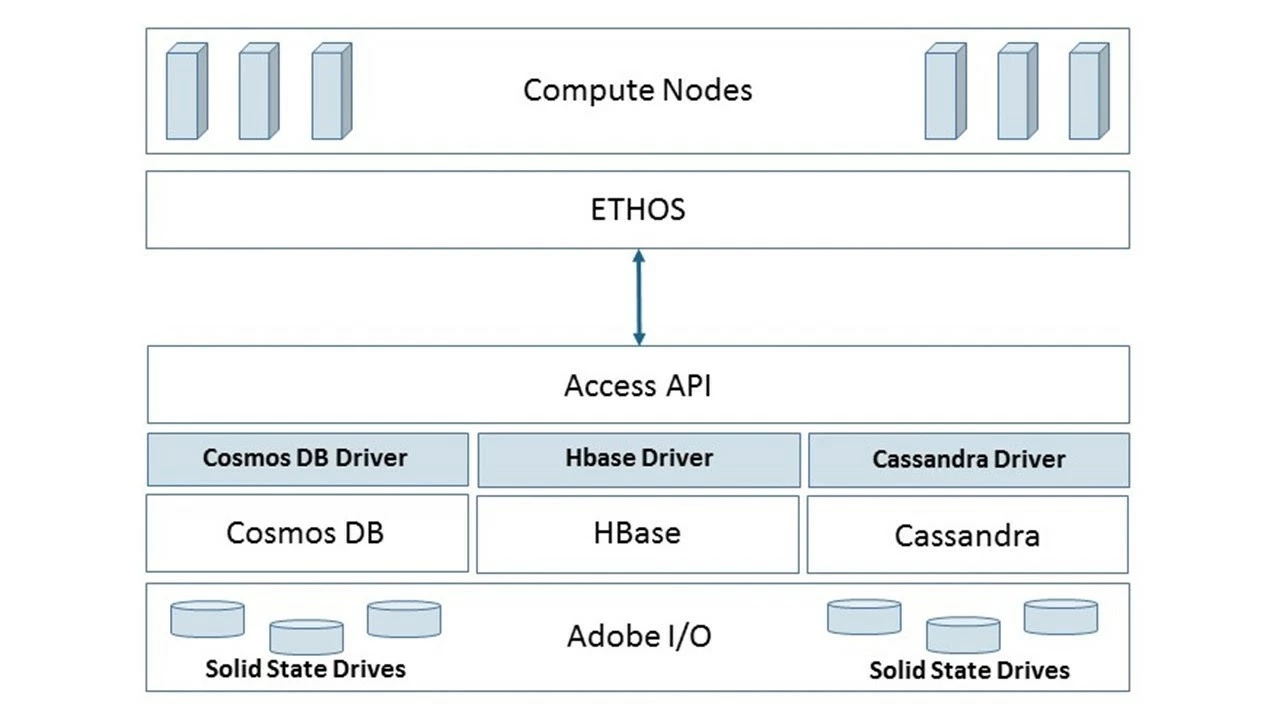
The Unified Profile store uses a database-neutral approach similar to Microsoft’s Open Database Connectivity (ODBC) or Oracle’s Java Database Connectivity (JDBC) interfaces. Its architecture uses drivers for Azure CosmosDB, Apache HBase, and Apache Cassandra to provide uniform access API (Figure 6). CosmosDB provides built-in independence of scaling for I/O and computing requirements, while HBase and Cassandra clusters still need additional work to achieve this goal.
Accessing the Unified Profile for Segmentation
The profile store also provides a robust set of APIs under Adobe.IO which allow enterprises to use their existing technologies to perform basic create, read, update, and delete (CRUD) operations in the profile store as well as create meaningful projections of the profiles for consumption.
Adobe Experience Platform’s Profile Query Language is an XDM-compliant query language designed for batch segmentation and real-time segmentation needs by combining the constructs of SQL and time-series event processing. The way Profile Query Language deals with XDM schemas is similar to how SQL deals with relational schemas in that streaming events are XDM-compliant time-series events. This design choice allows a query written in Profile Query Language to run as a real-time streaming query with profile augmentation. This ability to combine batch segmentation and streaming segmentation keeps audience segments up to date in real-time.
Figure 7 illustrates the segmentation architecture of the Unified Profile system, which supports both batch and streaming segmentation. Profiles are read by a batch segmentation job and passed on to Spark job for PQL query processing.
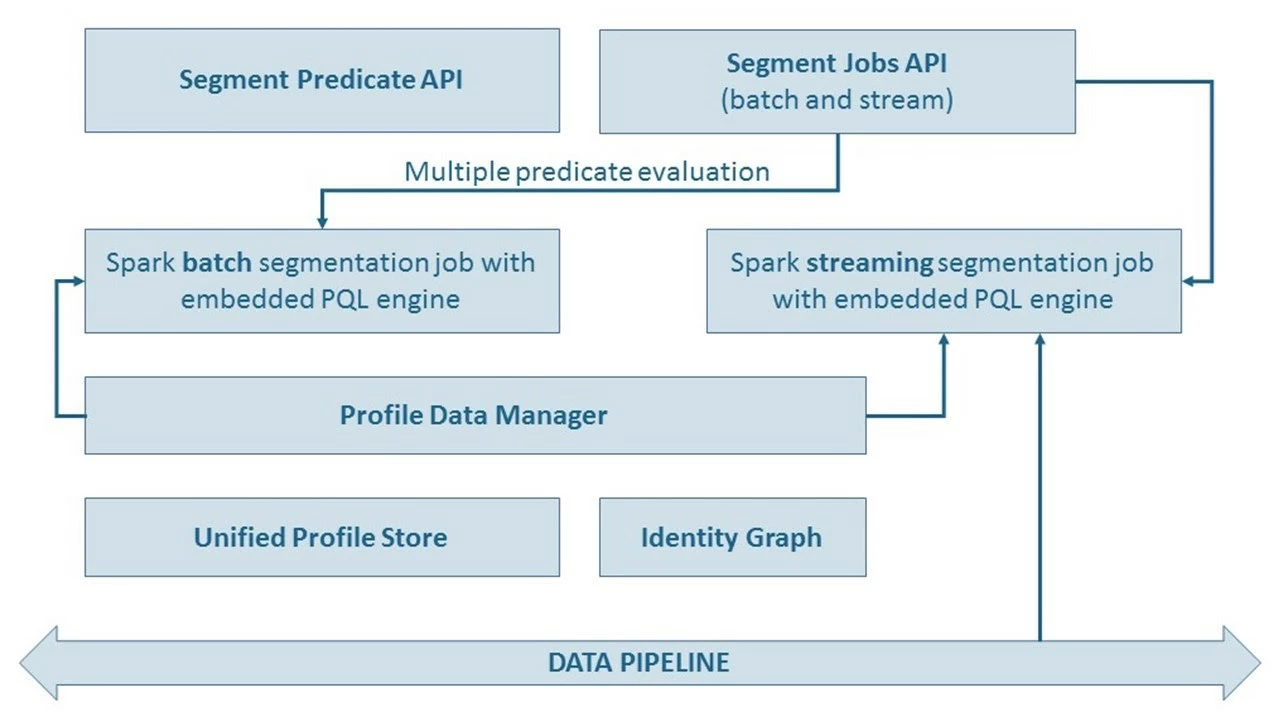
Real-time stream data ingestion starts in distributed data centers (the Edge). Streaming ETL processes the data and publishes XDM-compliant data on the Pipeline. A lightweight augmentation client enriches this XDM-compliant, real-time event with Unified Profile lookup. The enriched data is passed on to Spark job for PQL query processing.
Adobe Experience Platform’s Unified Profile system design and architecture is built on Microsoft Azure for elasticity and scalability with an approach designed to eliminate inefficiencies and create a platform for the next level of innovation. Our approach combines the best features of CDPs, DMPs, CRM data, and goes beyond to unlock entirely new use cases. One such example would be in the area of events management. At Adobe Summit 2019, using registration information, our team built a Unified Profile for more than 2,000 attendees. And, with an RFID chip in their badges, we were able to use the streaming data from their activities to send personalized messages, such as recommendations for specific presentations, during the event based on the sessions they were attending.
Unified Profile Service creates a bridge to connect offline and online known customer profiles as well as online anonymous customer profiles while providing a strong privacy regulation framework. The Unified Profile serves as a centrally accessible source for all Adobe Experience Platform. It provides a rich history of behavioral and interaction data and, like the rest of the platform, is extensible allowing enterprises to easily connect to external third-party solutions. With Unified Profile, the long sought-after 360-degree view of the customer is now possible.
References
- Part 1
- Unified Profile — https://www.adobe.com/experience-platform/real-time-customer-profile.html
- Customer relationship management (CRM) — https://www.gartner.com/en/information-technology/glossary/customer-relationship-management-crm
- Data management platforms (DMP) — https://theblog.adobe.com/digital-marketing-101-series-dmp-dictionary/
- Customer data platforms (CDP) — https://www.cdpinstitute.org/cdp-basics
- Adobe Experience Platform — https://theblog.adobe.com/new-adobe-cloud-platform-way-manage-experience-data-scale/
- Experience Data Model (XDM) — https://www.adobe.com/experience-platform/experience-data-model.html
- Adobe Experience Platform Pipeline — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/creating-adobe-experience-platform-pipeline-with-kafka/ba-p/432437
- Identity Graph — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/adobe-experience-platform-identity-graph-is-the-foundation-for/ba-p/432439
- Profile Query Language (PQL) — https://www.adobe.io/apis/experienceplatform/home/profile-identity-segmentation/profile-identity-segmentation-services.html#!api-specification/markdown/narrative/technical_overview/segmentation/profile_query_language.md
- Adobe I/O — https://www.adobe.io/
- Edge computing — https://theblog.adobe.com/customer-experience-lives-on-the-edge/
- Data Usage Labeling and Enforcement (DULE) framework — https://experienceleague.adobe.com/docs/experience-platform/data-governance/home.html
- General Data Protection Regulation (GDPR) — https://gdpr.eu/
- California Consumer Privacy Act of 2018 (CCPA) — https://oag.ca.gov/privacy/ccpa
- Scalable data ingestion — https://experienceleague.adobe.com/docs/platform-learn/tutorials/data-ingestion/understanding-data-ingestion.html
- Adobe Experience Platform Edge — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/streamlining-client-server-integrations-with-adobe-experience/ba-p/431602
- Adobe Experience Platform Launch — https://www.adobe.com/experience-platform/launch.html#
- XDM schemas — https://www.adobe.io/apis/experienceplatform/home/xdm/xdmservices.html#!api-specification/markdown/narrative/technical_overview/schema_registry/xdm_system/xdm_system_in_experience_platform.md#xdm-schemas-and-experience-platform-services
- Data governance — https://experienceleague.adobe.com/docs/experience-platform/data-governance/home.html
- Merge policies — https://experienceleague.adobe.com/docs/experience-platform/profile/merge-policies/overview.html
- Identity Service — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/adobe-experience-platform-s-identity-service-how-to-solve-the/ba-p/431607
- Key-value pairs — https://docs.adobe.com/content/help/en/audience-manager/user-guide/reference/key-value-pairs-explained.html
- GDPR Central Service — https://www.adobe.io/apis/experienceplatform/gdpr/docs.html
- Microsoft Azure — http://azure.microsoft.com/en-us/
- Open Database Connectivity (ODBC) — https://docs.microsoft.com/en-us/sql/odbc/microsoft-open-database-connectivity-odbc?view=sql-server-ver15
- Java Database Connectivity (JDBC) — https://docs.oracle.com/javase/7/docs/technotes/guides/jdbc/
- Azure CosmosDB — https://docs.microsoft.com/en-us/azure/cosmos-db/introduction
- Apache HBase –https://hbase.apache.org/
- Apache Cassandra — http://cassandra.apache.org/
- Spark — https://spark.apache.org/
Originally published: Mar 27, 2020