
(Part 1) Solving the Conundrum of Disparate Data and Different System Architectures to Build a Truly Unified Profile
Authors: Sandeep Nawathe and Jody Arthur

This is the first post in a two-part series that explores the challenges inherent in developing a 360-degree view of the customer. In this post, we describe the digital components a business needs to develop a holistic understanding of the customer and the difficulties associated with pulling them all together in the current solution landscape. In Part 2, we will present a new approach to unifying disparate data sources and system architectures to develop a Unified Profile that is actionable in real-time.
To be successful, enterprises have always strived to provide the best customer experience. With the rise of digital technology, proactively understanding a customer’s interests has been a key approach for businesses seeking to deliver personalized experiences that engage and delight their customers. And, customers expect this today. They have come to expect relevant material across all their interactions with a brand that optimizes their experience before and after the sale.
Over the past few years, technical solutions such as customer relationship management (CRM), email service providers (ESP), data management platforms (DMP), and customer data platforms (CDP) have focused on building an understanding of customers’ interests. This understanding is commonly referred to as the customer profile, and using this profile to provide a better experience is known as personalization.
Customer data is the key ingredient in building an accurate customer profile, and the ability to leverage that data is critical to providing the best customer experiences. Yet, despite the ever-growing abundance of customer data, enterprises today still struggle to fully leverage all the relevant data they have to deliver truly personalized experiences.
In this post, we describe all the digital components businesses need and the difficulties associated with pulling those components together to build a holistic understanding of the customer needed to deliver personalized experiences. We also explore the current solution landscape to compare different solutions in terms of their ability to deliver real-time customer experiences at every touchpoint, including one-to-one marketing, customer support, sales, and advertising.
Fundamental building blocks for building a holistic customer profile
In order to deliver real-time personalized experiences, enterprises need a current and complete data store for customer attributes and behavioral data that systems of activation can easily query for different use cases.
In addition to a data store, any single system that promises the ability to provide real-time customer experiences would need the capability to ingest data from many different sources, to resolve those data sets to build a customer profile, and a place to store that profile for easy segmentation and instant activation. Given the rapidly changing consumer privacy regulations and how they vary geographically, a robust system of data governance is also critical (Figure 1). In the following sections, we’ll take a closer look at each of these components.
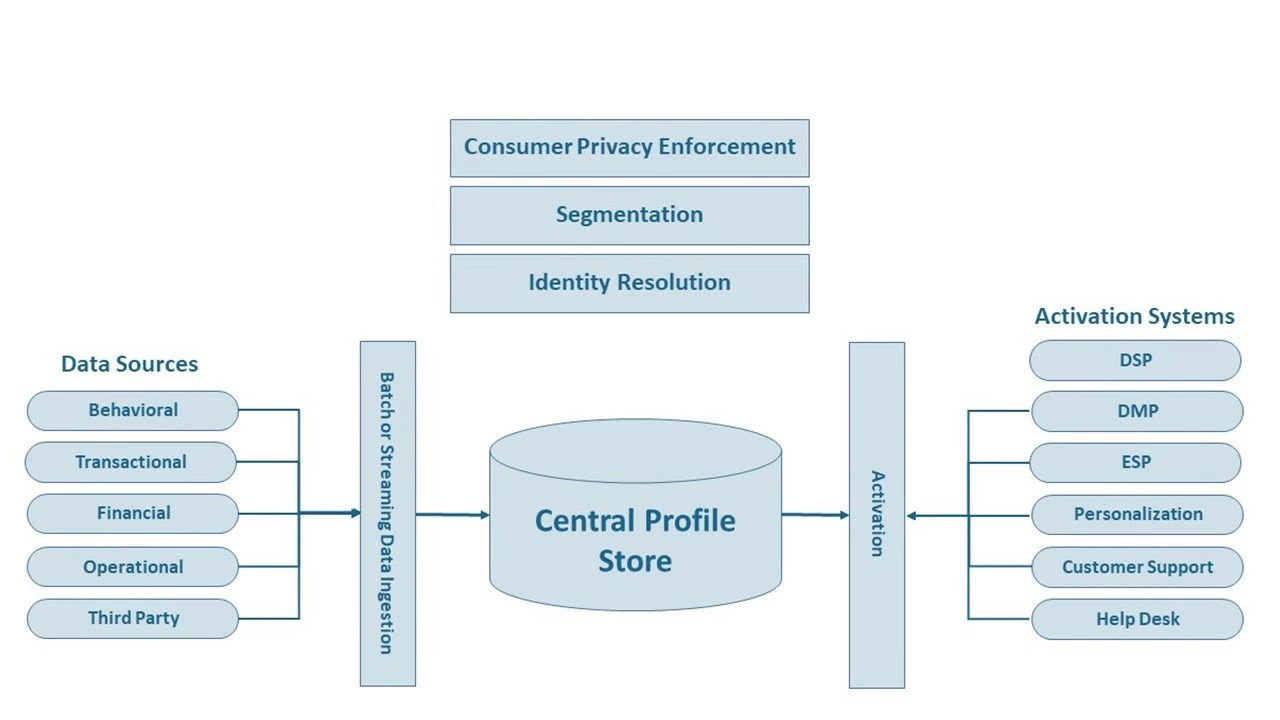
Data ingestion
Enterprises today have more data than ever before but still struggle to use it effectively to deliver personalized experiences to their customers. This data might consist of CRM data, e-commerce transactions, offline transactions, loyalty program data, behavioral data from mobile devices, web or emails, social interaction data, and so on (Figure 2).
In order to build a holistic customer profile, a system needs the ability to ingest first-party and third-party data, as well as data from various enterprise repositories, all of which have their own unique data model. And, with big data getting bigger by the second, data ingestion capabilities must also be scalable. Most systems handle ingestion in batches. However, for real-time use cases, streaming ingestion is required.
Whether batching or streaming data into the system, it will need to use extract, transform, and load (ETL) technologies to unify disparate data sets so they can be used to build a profile. Data cleansing and preparation and building enterprise data models are also part of the ingestion process.
Identity resolution
Ingested data comes from a variety of sources, and each data source has its own definition of customer identity for each record (Figure 2). To build a holistic customer profile, all the individual identities, fragments of a profile created through all the consumer’s different interactions with a brand, need to be matched to each other (Figure 3). Historically, for first-party data with known identities (e.g. CRM data and other offline records), this has been accomplished through a process often referred to as deduplication, data merger, or survivorship.
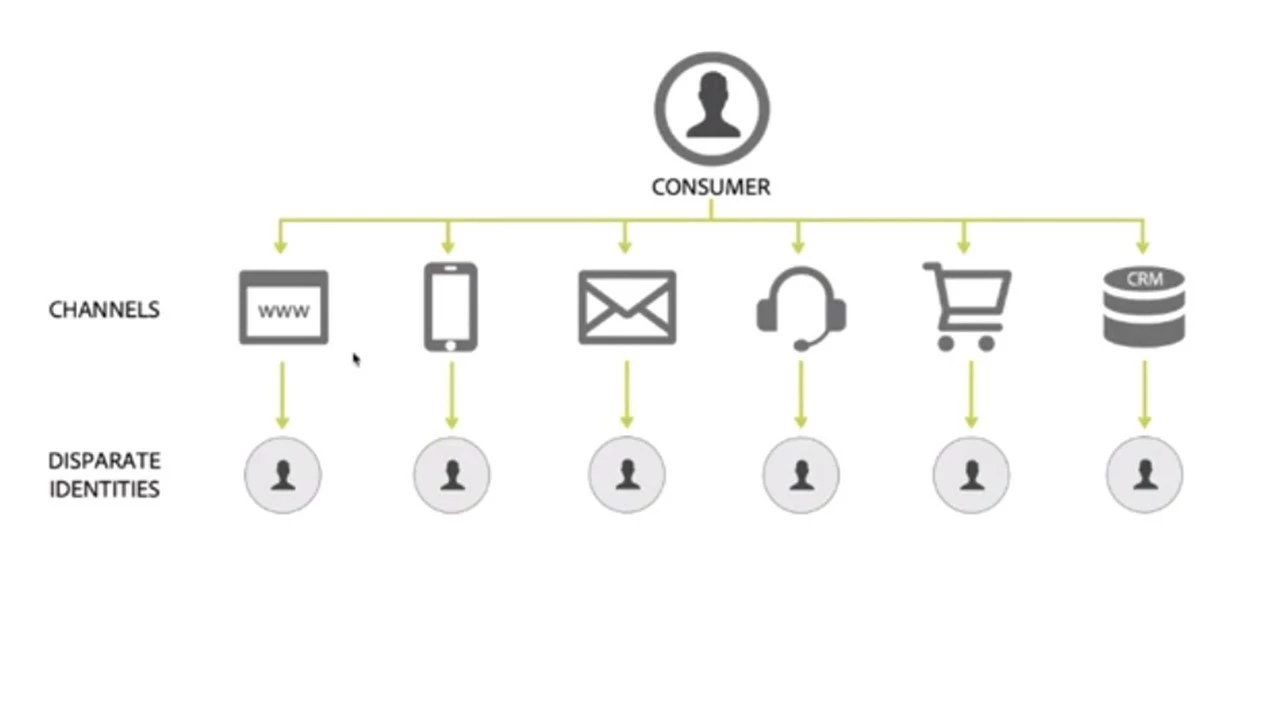
For online behavioral data records, identities are often anonymous cookies. Mobile and the Internet of Things (IoT) also have their own definition of identities, which are usually device IDs. Matching these types of identities requires new techniques.
Today, an identity resolution needs to combine traditional methods for matching data from offline sources with the deterministic and probabilistic algorithms (e.g. cookie matching techniques) in order to match both known and anonymous identities for a truly holistic customer profile.
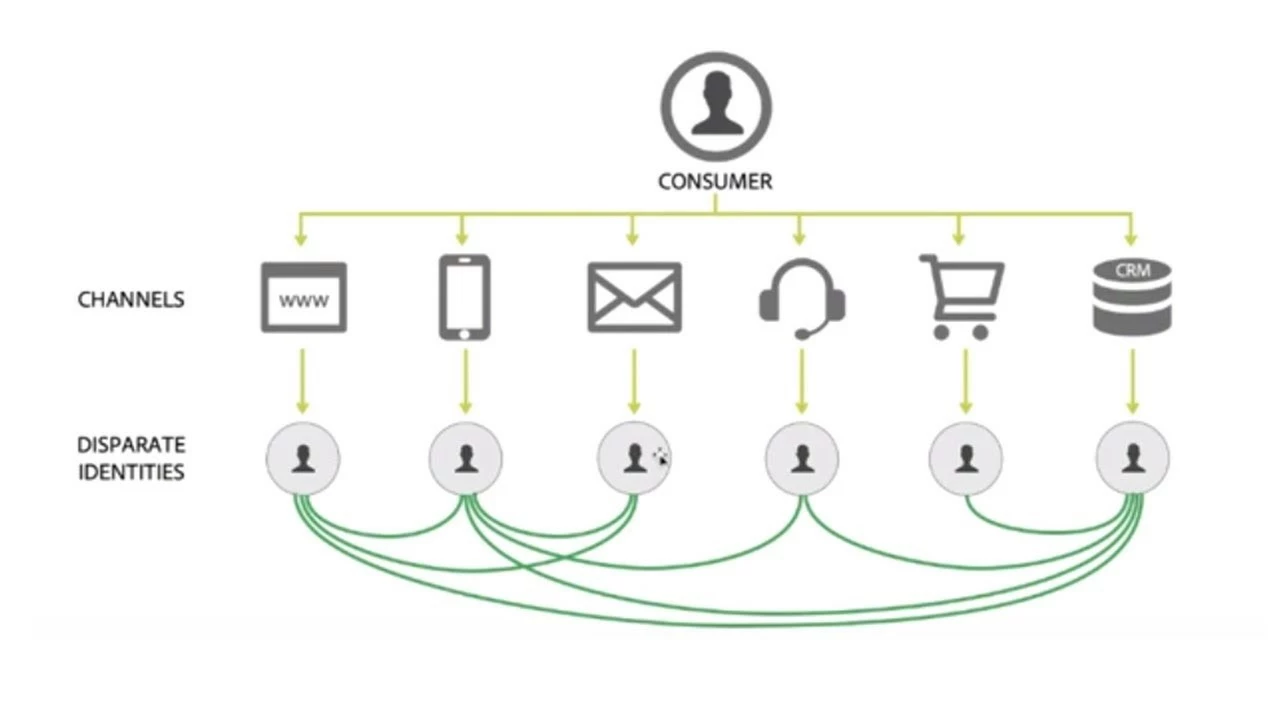
Once identity matching is complete all the interconnections of these identities can be displayed as an identity graph. This identity graph can be used to stitch customer profiles across disparate sources.
Profile Store
When identity resolution is complete, the data assets need to be loaded in the profile store. In order to efficiently handle real-time streaming workloads, the profile store must be made available near the point of action, making it important to give careful consideration to how distributed access of profiles and data synchronization will be achieved.
A profile store requires a well-crafted data model, one that serves the needs for a large number of use cases involving various ingested datasets such as demographic data, CRM data, online clickstream data, offline and online transaction records, and so on. And, in addition to data ingestion, it must also support a number of different operational workloads, including:
- Single profile lookups
- Operational store
- Point lookup for interactive workloads
- Machine learning workloads
- Batch segmentation workloads
- Real-time lookups and updates for streaming segmentation
The choice of a data model has a significant impact on the performance characteristics of the system for such workloads. Within the traditional relational database model, there are two basic types of processing systems, Online Transaction Processing (OLTP) systems, and Online Analytical Processing (OLAP) systems. OLTP databases are built to accommodate relatively simple workloads related to updating, inserting, and deleting data. OLAP databases are built to extract data for analysis (i.e. querying the data).
Both of these approaches have some advantages and disadvantages. For example, with the traditional relational database model, analytical workloads do not perform well against an operational data model. Conversely, operational workloads do not perform well with warehouse schemas.
As profile data becomes richer, the profile record size grows, and this growth poses a significant challenge when trying to meet all operational loads with one approach. A profile store must have the ability to handle both types of workloads, which means that to meet the requirements necessary to build a holistic customer profile, we now have to think beyond the traditional relational database.
Segmentation
Segmenting customers into audience groups is one of the most common workloads for profile stores. Segmentation is often performed as a batch job that executes queries, generally, about every 24 hours. While this frequency appears to be the industry standard, it results in delays and thus lost opportunities because new data that enriches the profiles for better personalization isn’t picked up by the queries until the next batch. For example, marketers always want to put users that abandon their carts into a segment and send them an email right away. However, when those users aren’t added to the abandoned cart segment until the next batch job, it is often too late to attract them to come back and complete their purchases.
Segmentation delays can be eliminated by using real-time segmentation, which can act on a stream of events that contain behavioral data. This process removes delays and unlocks the opportunity for enterprises to act immediately when they receive new data. Today, segmentation is still largely performed on data that is collected in one place from various data centers. But, streaming data is collected at different data centers across the world. In order for segmentation to happen in real-time, it needs to be performed where the data streams are coming in. While this kind of large-scale data distribution and computing is critical to real-time segmentation, it introduces a new set of challenges for the system to ensure the necessary data consistency and synchronization.
In the past, the use of human intelligence was the only way to author segmentation queries. Now, recent advances in machine learning have opened up the fascinating possibility of auto-segmentation. However, like streaming data, this introduces many of the same challenges that come with computing at high scale because the workloads necessary for auto-segmentation can be substantially larger than human-generated workloads.
Activation
In order to deliver personalized customer experiences at the right time and in the right channel. To accomplish this,
Enterprises today must work with many different activation systems to help them deliver personalized customer experiences at the right time and through the right channels. These include email service providers (ESPs), demand-side platforms (DSPs), data management platforms (DMP), analytics, and so on.
For example, an ESP might be used for outbound email, short message service (SMS), and push notifications. In this case, activation refers to enabling audiences that were previously created from a central customer profile repository into an ESP subsystem and using it to facilitate personalization based on the consistent view of the customer profile that the repository provides. In cases where these activation systems are external software-as-a-service (SaaS) offerings, an application program interface (API) is required to access the profiles in the profile store.
Consumer data privacy enforcement
Customer profiles often contain sensitive data, also known as personally identifiable information (PII). By enabling the use of this data, an enterprise also risks its misuse. When a profile is used out of context or without an understanding of the opt-in and opt-out requirements associated with the profile, an enterprise risks annoying customers and potentially violating privacy laws.
The indiscriminate use of PII should always be prevented. However, one of the challenges in doing so is that privacy regulations vary based on different geopolitical regions, and they evolve over time. Further complicating matters is the fact that compliance with privacy regulations is mandatory while compliance with current best practices may not be. This is why a central profile store must be built upon a robust privacy framework that can handle the ever-evolving landscape of consumer privacy.
The current solution landscape
In recent years, the ever-growing expectation for relevant, timely, and engaging customer experiences has enterprises in all industries seeking technologies to help them meet that demand. Delivering real-time personalized experiences to their customers depends on enterprises having a holistic understanding of the customer, a truly unified profile that continuously weaves together behavioral and attribute data to create a 360-degree view of the customer.
There are several technologies available in the current solution landscape, including CRM systems, DMPs, CDPs, DSPs, ESPs, personalization engines, customer analytics tools, and so on (Figure 4).
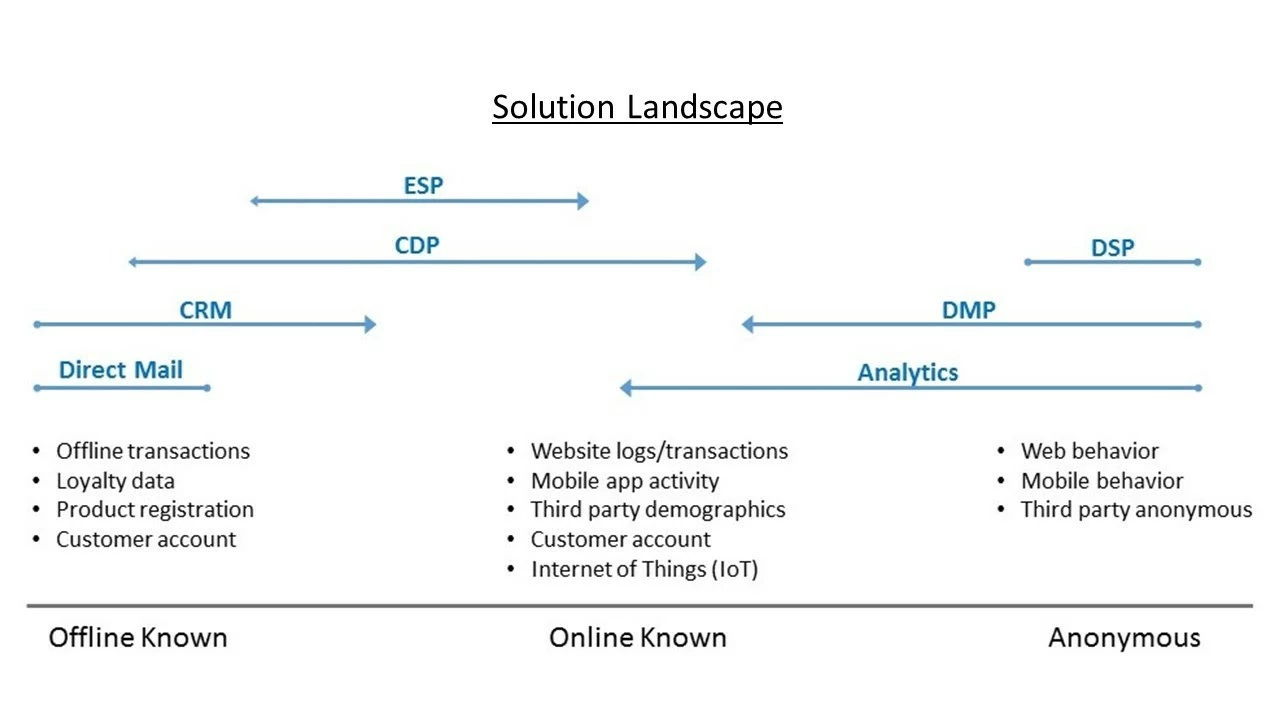
All of these solutions address various parts of the challenges associated with developing a holistic customer profile, and many have overlapping capabilities.
While all of these solutions have at least a minimal notion of a customer profile, DMPs and CDPs focus specifically on customer profiles.
At a high level, based on how DMPs and CDPs are often described, one might think that they perform the same functions. These solutions do help brands build customer profiles for use by downstream systems. However, not all customer profiles are created equal, and there is little overlap in the use cases that these two solutions enable. When examining the details of customer profiles and the use cases they support, their distinguishing characteristics and value become very apparent.
Customer Data Platforms
The primary purpose of a CDP is to unify an enterprise’s first-party data about known customers to build customer profiles. CDPs handle first-party data sources, such as online transactions, offline transactions, CRM data, behavioral data, loyalty databases, email clickstream, and other auxiliary datasets such as product catalog, store locations. CDP profiles also contain all PII, including email addresses, mailing addresses, full name, and birth dates. CDPs help enterprises drive personalized marketing at scale and can be incredible tools for nurturing customer relationships and increasing customer retention.
Here are some examples of the use cases that CDPs can drive:
- Identifying high-value, in-store customers for sending personalized emails and offers and suggesting new options based on their online behavior
- Assuring airline passengers during check-in that their previous experience with a baggage loss was an anomaly and will not happen again
- Greeting your customers by their first name during a branch visit or a customer service call
- Building micro-segments of audiences using precise demographic data and in-store transactions
CDPs allow a marketer to build precise micro-segments of known customers by using first-party data and purchased datasets. Through their use of PII and other first-party identities such as web cookies, CDPs can offer near-perfect match rates during activation allowing for highly targeted campaigns. CDPs also enables the distribution of these micro-segments to multiple activation systems, such as direct mail, email, website personalization, and push notifications to facilitate personalized interactions with the customer.
Data Management Platforms
In contrast to CDPs, DMPs build anonymous profiles by collecting clickstream data for websites and using tags to infer user behavior over time. This behavior is stored as attributes or traits in a user profile. Many of the DMPs available today do accept offline data, such as CRM data. However, the PII is anonymized before being stored in the profiles. In a DMP, attributes collected in this way can be combined to build segments of anonymous audiences, and the segment membership is often stored in the profiles for efficient lookup.
In a DMP, the anonymous identity of the user often manifests as a cookie in the user’s browser. Many of the DMPs on the market today are third-party systems that use tags for a website or mobile clickstream data collection. Using tags has important implications on DMPs because web browsers are increasingly disallowing third-party cookie tracking. These third-party tracking restrictions create orphaned user identities (cookies) that result in poor match rates during activation.
DMPs were originally built to generate audiences for advertising on publisher sites and have since expanded to support DSPs, which are designed to purchase and manage advertising from multiple ad sources through a single interface. In contrast to CDPs where the interaction channels are often controlled by the enterprise, with a DMP, advertising typically happens on media owned by external publishers, which results in restrictions on PII usage.
While CDPs and DMPs can be used to build customer profiles that can be activated in a variety of ways, DMPs do not allow for the personalization necessary to meet the demands of today’s consumers. Based on their ability to ingest and incorporate PII, CDPs do offer the ability to offer personalized experiences. However, they require strong governance and few CDPs on the market today do not provide the architecture necessary to deliver those experiences in real-time.
In Part 2 of this series, we’ll take a closer look at the architecture needed to support all these components and facilitate seamless interaction to help enterprises deliver real-time personalized experiences.
References
- Part 2
- Customer relationship management (CRM) Systems — https://www.gartner.com/en/information-technology/glossary/customer-relationship-management-crm
- Data management platform (DMP) — https://theblog.adobe.com/digital-marketing-101-series-dmp-dictionary/
- Customer data platforms (CDP) — https://www.cdpinstitute.org/cdp-basics
- Data deduplication — https://www.gartner.com/en/information-technology/glossary/data-deduplication
- Identity graphs — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/adobe-experience-platform-identity-graph-is-the-foundation-for/ba-p/432439
- Online Transaction Processing (OLTP) systems — https://en.wikipedia.org/wiki/Online_transaction_processing
- Online Analytical Processing (OLAP) systems — https://en.wikipedia.org/wiki/Online_analytical_processing
Originally published: Mar 19, 2020