
Adobe Experience Platform Identity Graph is the Foundation for the Unified Profile
Authors: Priyanka Sharma, Rahul Biswas, Hari Bhaskaran, and Sandeep Nawathe
This article provides conceptual and deployment information about how we are unifying fragmented identities in systems of interaction through Adobe Experience Platform identity services.
Improving experience has become a ubiquitous business strategy. Great experiences are the new currency of brand loyalty. Consumers expect more personalized and contextual experiences. However, in Adobe's 2019 Consumer Content Survey, 82% of consumers say they've received content from brands that isn't personalized, and 38% of consumers say this happens constantly or frequently.
Delightful consumer experiences that incite return engagement(s) tend to have a common denominator: The journey is frictionless between the various channel and device touchpoints. Consider Forrester Group's earlier prediction – the average consumer will have 13 or more touchpoints with a brand before a conversion event takes place.
Understanding where a single consumer is in their journey (often among a myriad of disconnected touchpoints) so you can deliver them the next-best experience remains difficult for brands because each unauthenticated touchpoint generates a unique "identity" or profile. To complicate things further, a new and separate "identity" is generated by each system that delivers an experience. Disconnected identities or profiles make real-time experiences challenging due to the huge amount of data processing involved.
A single consumer's "identity" can be spread across disparate applications of engagement such as brick-and-mortar stores (PoS), web, mobile, email, IoT, and any other devices they may own. Further, the interaction data keyed off consumer identity is siloed in enterprise systems such as CRM, ERP, DMP, CMS, and marketing automation. These disconnected identities are a barrier to achieving a holistic view of the consumer to serve the next-best experience. Effective management of identities via linking, resolving, governing, and actioning is time-consuming, process-heavy, and difficult.
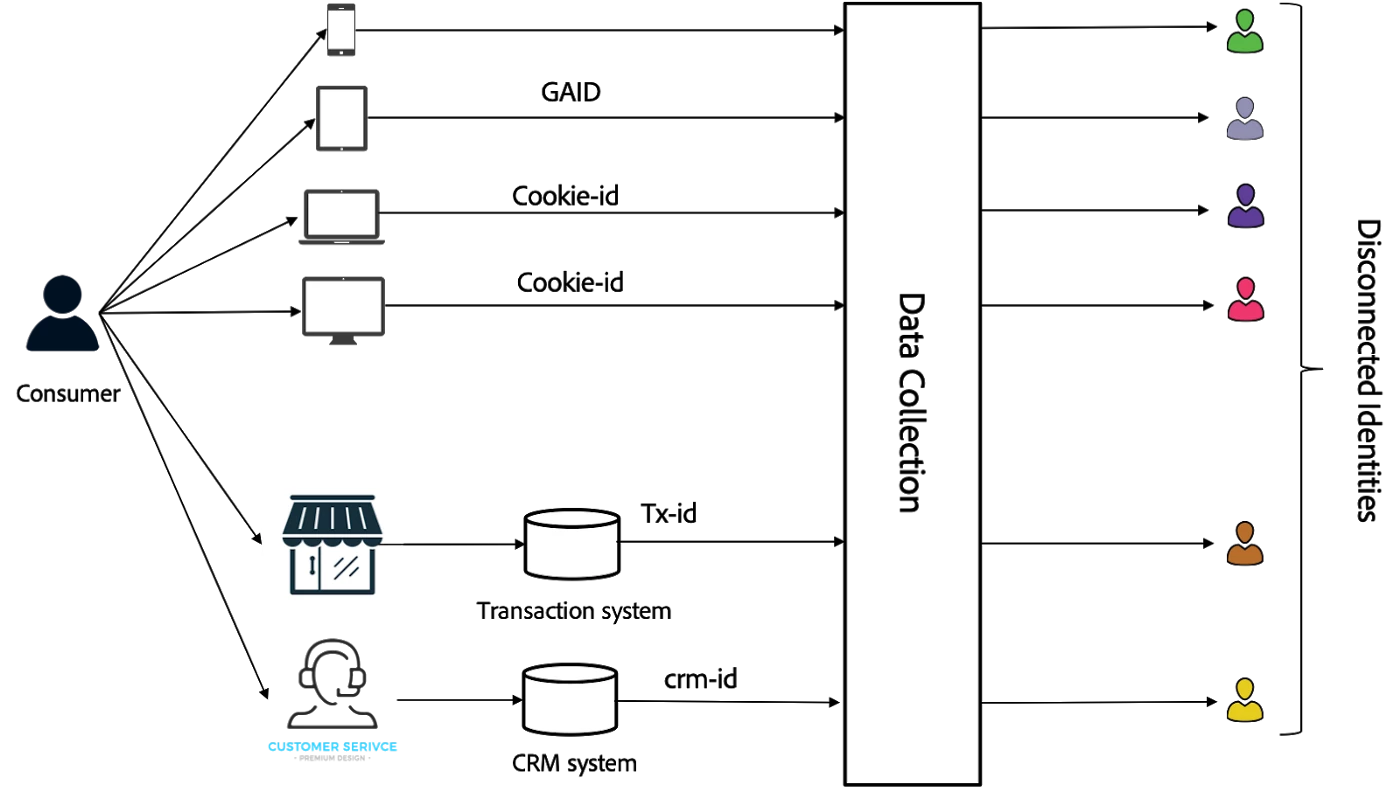
Adobe Experience Platform identity graph and privacy
The Adobe Experience Platform identity graph extends Adobe's commitment to privacy. Data controllers – the vendors who are the stewards of their customer data – need to have complete control over their consumers' data to honor regulations such as GDPR. A key part of this is the ability to control the identity of the data subject and the relationships between identities. Adobe, as a data processor, has launched platform services to help customers with their experience data governance.
In order to serve access or delete request, the customer needs an accurate, up-to-date, and a highly secure central repository that serves as the outline for all linked identities. Additionally, the data needs to be collected, returned, or deleted upon request. Adobe Experience Platform identity graph provides the underlying infrastructure to make this feasible. Moreover, data-subject preferences, such as opt-in, consent and opt-out are core features of the identity graph storage and compute layers and are part of the design considerations from the beginning. The identity graph also provides seamless integration of a customer's internal data-subject identifiers and links them to Adobe Experience Platform's identity counterparts in a safe, secure, and controlled way.
Adobe Experience Platform identity services
A single consumer can have many identities scattered across a single brand's systems. To address this, the Adobe Experience Platform identity graph links any identities in a brand's technology stack by performing identity resolution for an individual consumer. These identities can be online identities such as cookie IDs and device IDs, or offline identities such as email IDs, loyalty card numbers, or CRM IDs. This enables a company to deliver consistent, connected experiences by referencing a single, unified profile of the consumer. By linking disconnected identities and eliminating the latency caused by manual data management, delivering the next-best action based on all the data available is possible. Adobe Experience Platform is architected to scale and adapt to interactional data as it continues to grow in unprecedented volume.
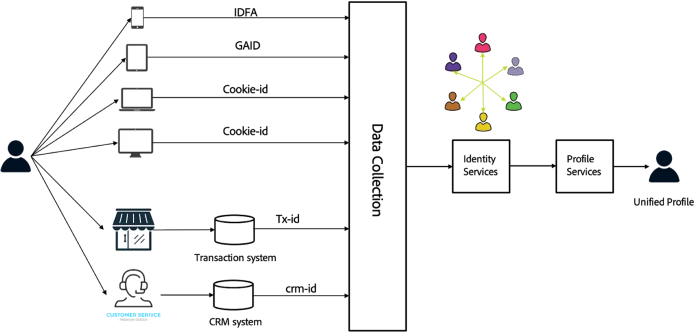
Adobe Experience Platform approach to identity services
Adobe Experience Platform identity graph is built by algorithmically discovering identity relationships between two sources of data:
- Online data: Event logs created by consumer activity on digital properties such as websites, mobile apps, gaming consoles, and household devices.
- Offline data: Consumer profile information feed imported from an enterprise's technology stack such as CRM, ERP, and data lakes.
The discovery of identity relationships among the different sources of data requires a combination of deterministic and probabilistic algorithms.
The deterministic algorithm approach is based on an assertion of relationships between two or more identities done upstream before any algorithmic processing takes place. In the online data, this assertion is done in a consumer interaction such as a consumer login on the website. This asserts that the anonymous IDs and known IDs belong to the same person. The deterministic algorithm ensures high fidelity of identity relationships by filtering bots and identifying shared devices and logins. In the offline data, the relationship assertion is made implicitly by the presence of multiple identities in a single consumer record, or of one or more common identities across multiple records. For example, a CRM will automatically generate a customer ID when a record is created. However, the "contact," or record of the consumer, contains other identities based on email address, social handles, and loyalty card number. The identity graph links all identities found in a single record, as well as identities across multiple records that belong to a single consumer.
The probabilistic algorithm approach is based on using strong signals identified through heuristics and machine learning models to predict multiple identities that are related to the same consumer. The Adobe Experience Platform identity graph uses a combination of IP addresses and temporal data to establish a relationship between identities found in online consumer event logs. This approach also uses heuristics on detecting DHCP IP address resets by internet service providers and preventing identities from separate households from being linked together.
A combination of the two approaches is used for computing the Adobe Experience Platform identity graph to provide a balance between precision and scale. This approach combines the deterministic approach as a base, then expands the identity graph conservatively using the probabilistic approach.
Deterministic and probabilistic approaches have their own pros and cons. The deterministic approach has high precision but lacks scale. The assertions between two identities are reliable, but such assertions are unlikely to be provided at scale as the ratio of activity in an authenticated state to the activities in an anonymous state is low. The probabilistic approach has a high scale, but precision may suffer as we are trying to recreate reality using algorithms and partial data.
Adobe Experience Platform runs a data cooperative for our customers to share anonymized data amongst participating members. This allows customers the scale of data to discover identity relationships they couldn't have discovered with just their own data. Currently, the Adobe Experience Platform identity graph is built using Adobe co-op data, linking 1.7 billion cookie IDs and device IDs into >300 million individual people clusters for North America.
In addition to the Adobe cooperative-based identity graph, we provide enterprises the ability to create private graphs. A private graph is built using a single company's deterministic data and is accessible only to them.
Our challenges and solutions
Although Adobe Experience Platform identity service co-op graph allows customers to achieve data scale they couldn't do on their own, it creates a big data challenge for the identity graph compute infrastructure. The batch processing that generates the identity graph for the Adobe co-op runs at a weekly cadence and processes more than 300 TB of raw logs.
There were three key challenges we solved to make this possible: scale of data, resource allocation, and throughput and latency.
Scale of data
Processing this scale of data requires a distributed compute framework with support for parallelism and fault-tolerance. An Adobe private identity graph typically processes smaller data sets, depending on the size of the enterprise. However, Adobe private identity graph processing also benefits from a similar framework. Adobe co-op and private identity graphs are both built using Apache Spark.
One of the challenges we encountered in running the Spark jobs at the Adobe Experience Platform scale of data was job stalls or failures because of memory and CPU pressures. The memory pressure was resolved by increasing the memory allocation per executor, which reduces the number of executors running per JVM. The CPU pressure was resolved by reducing the number of executor cores, which reduces the number of threads running per JVM.
Resource allocation
Resource allocation was a challenge when multiple jobs were submitted simultaneously. Initial implementations allocated the same number of executors irrespective of the number of records of the offline data to be processed. This caused a large part of the compute cluster to be idle and unavailable while a small job was in progress. With metadata on record size now available, some heuristics based on current processing throughput and the number of records are being used to determine the number of executors to be allocated per job. This has significantly improved our ability to meet processing SLAs.
Throughput and latency
Retrieval of the identity graph requires support for high throughput and low latency. All interactions between services are using RESTful APIs, and identity graph lookups are supported in two forms: batch and single identity-based lookups. Batch lookups are supported at 1,500,000 identity graph lookups in batches of 1000 identities at a 95-percentile latency of 850ms, and single identity graph lookups are supported at 200,000 lookups at 95 percentile latency of 25ms.
This is a significant challenge and was solved through Adobe's proprietary high-throughput, low-latency, data-store agnostic graph manager SDK (InstaGraph). We currently use the Azure Cosmos database as the data store. We evaluated multiple open source graph databases but they did not provide the scale we needed for our SLAs. Therefore we developed our own InstaGraph SDK that uses Cosmos DB.
What's next?
Real-time identity graph
Contextual and relevant experiences are delivered at "just the moment" when each consumer is ready for them. Online consumer activity is collected in real time, but data processing to compute the identity graph is done as a batch process. Using a weekly computed identity graph to execute real-time decisioning means the decisions are being made on potentially stale data. To solve for this, an Adobe-scale, real-time identity graph will be made available to further empower Adobe Experience Platform users.
Refined probabilistic algorithm
Brands also aspire to learn new findings from their data – for example, gaining insights from individual signals that are too weak to conclude or dots that are otherwise hard to connect. Machine learning uses probabilistic algorithms to identify these signals and discover new identity relationships. Expect to see more innovations in this area as we work in close collaboration with the Adobe Research team.
Third-party graph integration
The Adobe Experience Platform values our partners and ecosystem. As a platform service, we will introduce support for third-party graphs from companies like LiveRamp, Drawbridge, and TapAd. This will enable our customers to choose from graphs that are best for their needs. This is our natural progression towards building a thriving ecosystem.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Documentation and Research
- Adobe Experience Platform identity services documentation
- "Predictive Analysis by Leveraging Temporal User Behavior and User Embeddings. CIKM 2018", 10/26/2018
- "Probabilistic Visitor Stitching on Cross-Device Web Logs. WWW 2017", 4/3/2017
- "Higher-order Network Representation Learning. WWW 2018", 4/23/2018
- "Continuous-Time Dynamic Network Embeddings. WWW 2018", 4/23/2018
Originally published: Mar 4, 2019