
Massive Data Processing in Adobe Experience Platform Using DeltaLake
Authors: Yeshwanth Vijaykumar, Zhengping Wang (@zp_wang), and Jayna Patel

In this blog post, we are going to go over how the data lake house architecture at Adobe Experience Platform combines with the Real-time Customer Profile architecture to increase our Apache Spark Batch workload throughputs and reduce costs while maintaining functionality.
Adobe Experience Platform enables you to drive coordinated, consistent, and relevant experiences for your customers no matter where or when they interact with your brand. With Adobe Experience Platform Real-time Customer Profile, you can see a holistic view of each individual customer that combines data from multiple channels, including online, offline, CRM, and third-party data. It allows you to consolidate your disparate customer data into a unified view offering an actionable, timestamped account of every customer interaction.
Architecture Overview
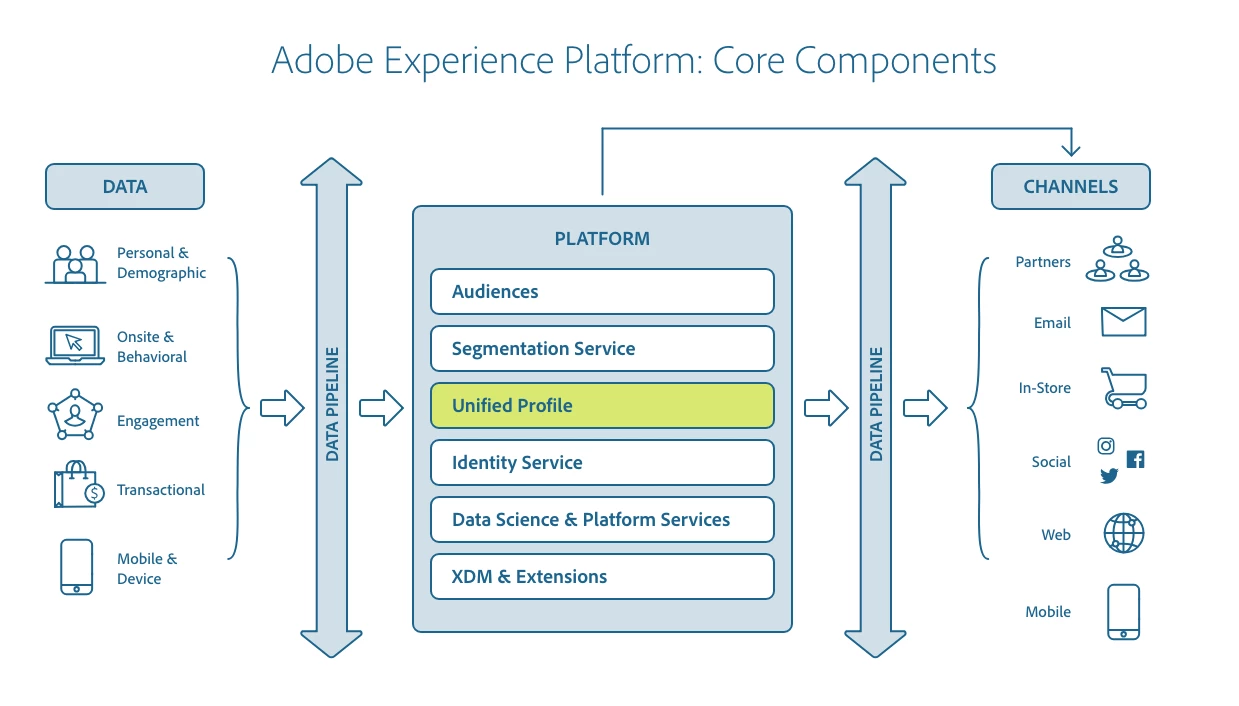
Given that the Adobe Experience Platform assimilates data from various sources, Real-time Customer Profile acts as the central hub ingesting data from different data sources; it stitches data together with the Adobe Identity Service and ships the data to various marketing destinations to enable new experiences.
The relationship between Adobe Experience Platform Real-time Customer Profile and other services within Adobe Experience Platform is highlighted in the following diagram:
Focus Area: Scan and Query Access Pattern
When data is ingested into Profile Hot Store (Azure Cosmos DB) from various sources, each mutation to the profile store generates a change feed message sent on a Kafka Topic. We want to create a merged view of the Real-Time Customer Profile on the data lake which will enable us to write queries to segment the population into useful targetable audiences. Running such queries on the hot store is extremely expensive and not optimized due to the following reasons
- Spark parallelism is dependent on the number of partitions on the hot store.
- Hot Store partitions have throughput limits which means having more cores than partitions of the Cosmos DB does not increase parallelism and will lead to incessant 429s and retries.
- Multiple group-by clauses causing extensive shuffle workload on the Spark Cluster.
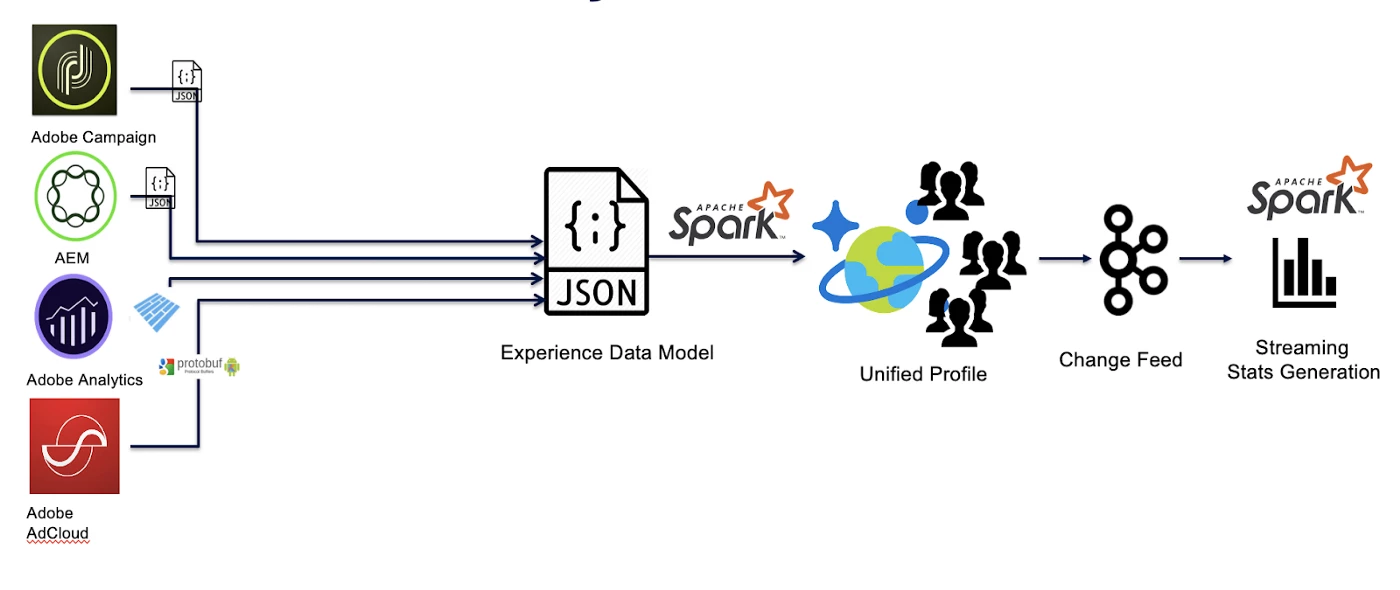
What are we storing?
Multi Source — Multi Channel Problem
Various sources be it Online/Offline contribute data into the Adobe Experience Platform. Data can flow as batches or be streaming in nature. An example of streaming data would be clicks, and page views flowing in as soon as the event happens. Data from each source can have its own schema and each source can have a different frequency. As a system we need to be able scale up and handle these various load types during ingestion.
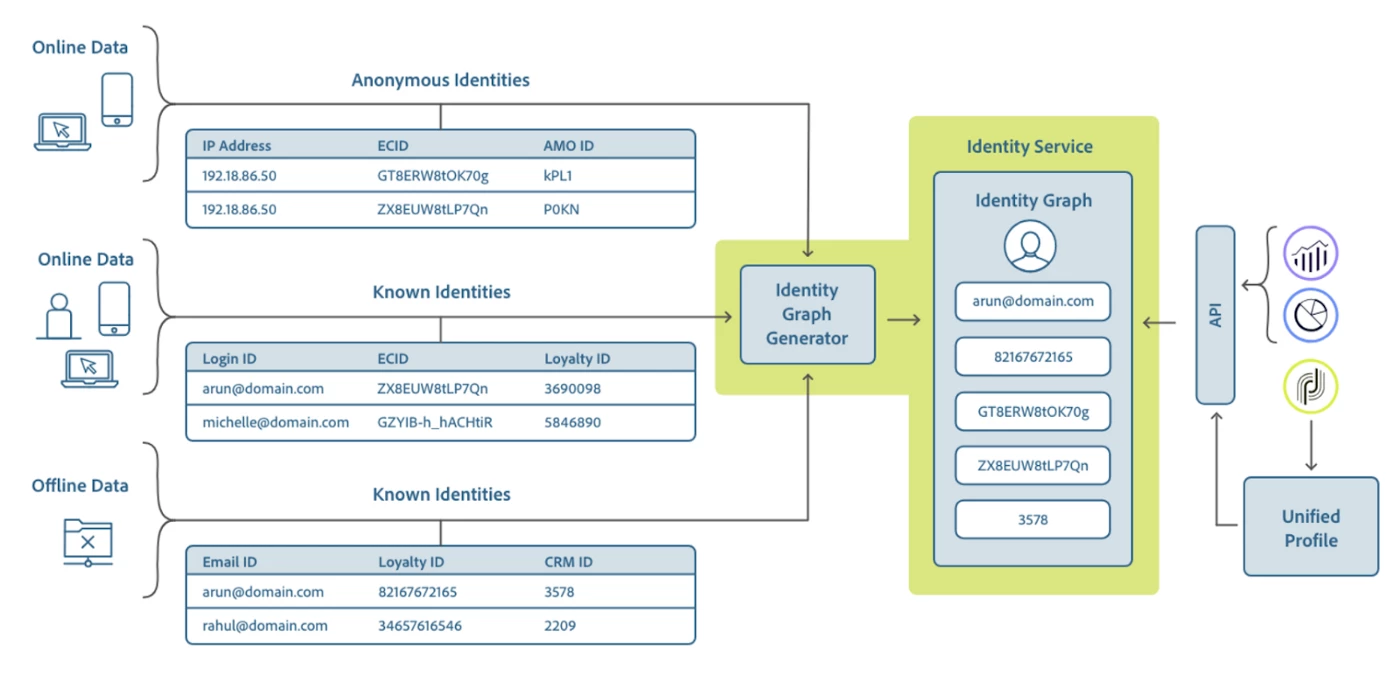
As the data makes it into the Real-Time Customer Profile, the data is simultaneously ingested by the Unified Identity Service which manages the creation/updation and deletion of linkages between various identities as shown in Figure 3.
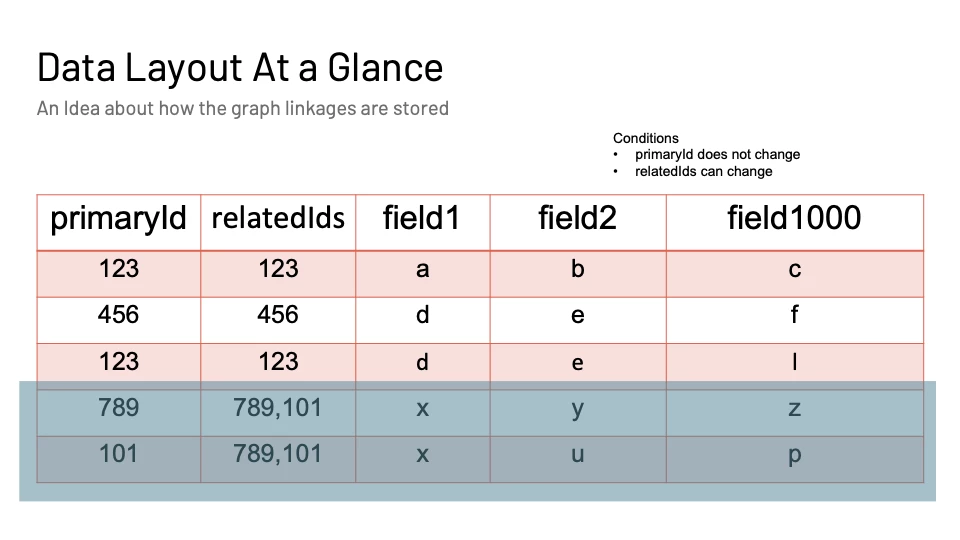
Data Layout At a Glance
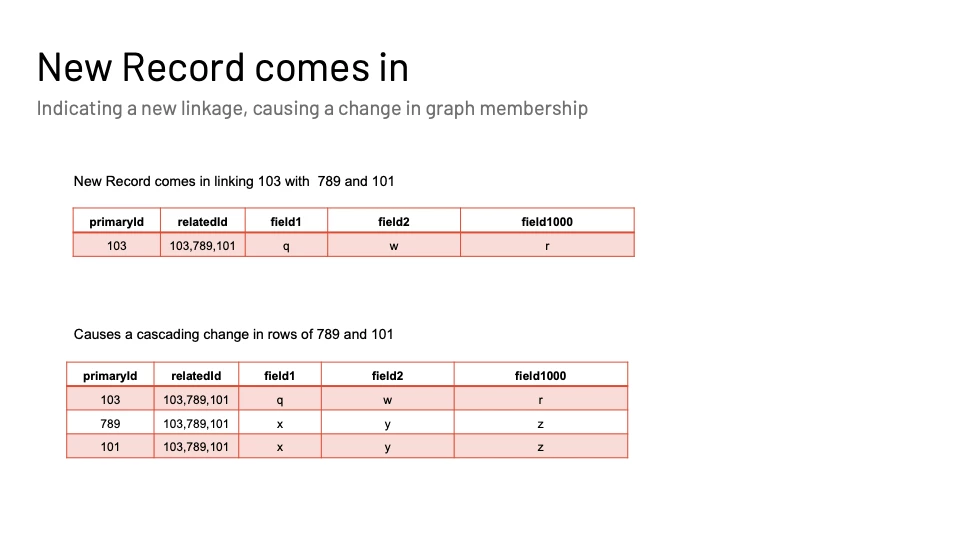
Before we go into optimizing our workload, let us take a look at a toy data example as shown in Figure 4. In the table, consider each entity having a primaryId. Any event generated by the entity will have the primaryId sent. Along with that if there is any extra information about the linkages, we will get the relatedIds that will also be populated. Focusing on the last 2 rows, we see that ids 789 and 101 are linked to each other. This tells us ALL records pertaining to 101 or 789 need to have linkage information. Fields 1 to 1000 are data fields indicating some attribute about the event recorded in that row.
Since this is a dynamic system, we want to see how the data evolves as new data flows in. Especially when changes in linkages happen. Figure 5 shows an example where a new event came in for an id 101, interestingly enough it also contains linkage information showing it is linked to 789 and 101! This causes a cascading change in the records that have come before.
While some eyebrows might get raised on this update amplification. This is a sane way to optimize for the groupBy clause we need for our bread and butter use case as explained in the next section.
Access Pattern to optimize for in detail
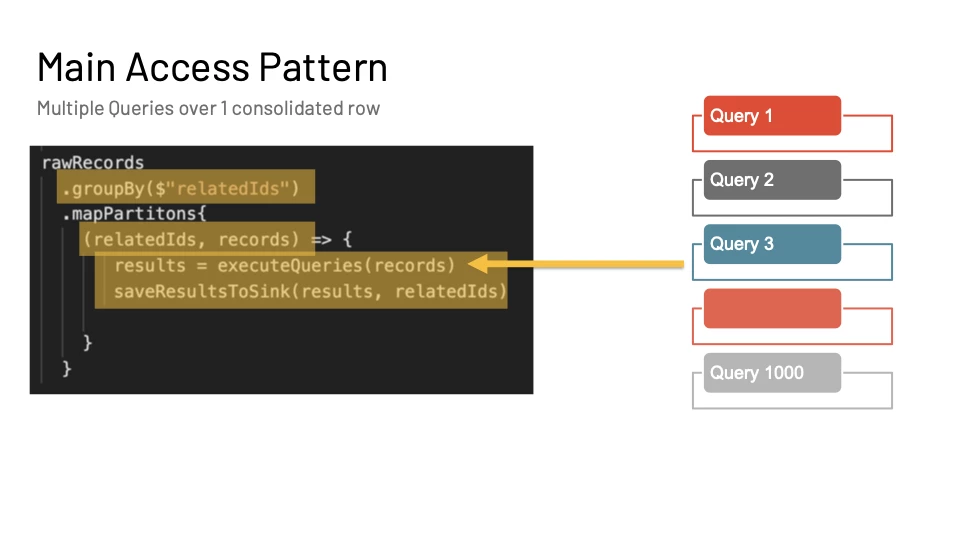
Figure 6 goes over an access pattern where we want to run a bunch of queries over a merged view of the entities. From our previous examples, the merged view of the entity with primaryID 101 would be the assimilation of all events of the relatedIDs also. So the merged view would have ALL events of ids 101, 789 and 103.
In order to get the merged view, we need to first groupBy the relatedIds field. Once we do that, we get the list of records within the aggregation context and we are able to execute queries on top of them.
Problems To Account For:
- Currently, this workload is run off the NoSQL hot store. While we are able to parallelize well and have an efficient scan pattern over the hot store, we are still limited by the number of partitions given by the HotStore
- That means immaterial of the amount of firepower we have in our Spark Cluster, we cannot go beyond the store’s layout. If we do decide to parallelize within a given partition of the store, we will start hitting partition-based throughput limits
- For Nested Field, we use JSON schema semantics to define the data coming into the Adobe Experience Platform. We have a heavy mix of extremely nested fields and arrays that complicates Spark processing.
- Every tenant has a different schema, meaning we need to worry about schema evolution on a per-tenant basis.
- Scale: Tenants have 10+ Billion rows, PBs of data in total, and Continuous 100k+ request per second peaks.
What is DeltaLake?
Quoting directly from the horse’s mouth: DeltaLake docs
“Delta Lake is an open source project that enables building a Lakehouse architecture on top of data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes, such as S3, ADLS, GCS, and HDFS.”
Specifically, Delta Lake offers:
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts and deletes: Supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
DeltaLake in Practice

Figure 7 shows some examples of usage of the delta lake. The most common use case of trying to save as a parquet file becomes as easy as doing a dataframe.write.format(“delta”).save(“path/to/data”). More importantly, the example showing the upsert of newData a data frame into an existing oldData data frame is an important one since it shows the potential of now being able to modify a parquet-based file. The SQL compatible bindings are just the icing on the cake.
Writer Worries and How to Wipe them Away
DeltaLake is not a magic solution. We still need to take certain design precautions to avoid pitfalls.
Concurrency conflicts

The table above gives a good idea as to what operations conflict with each other. Take away is that appends are safe with a multi-cluster writer. We DO need to take precautions in spite of the optimistic concurrency control provided by DeltaLake in the case of UPDATE DELETE issued from multiple Spark jobs.
Column size
When the individual column exceeds 2GB, we see degradation in writes or OOM.
Update frequency
- Too frequent updates cause underlying filestore metadata issues.
- This is because every transaction on an individual parquet causes CoW,
- More updates => more rewrites on HDFS
- Can lead to too Many small files !!! This makes metadata management and all other subsequent operations expensive.
DataFlow with DeltaLake
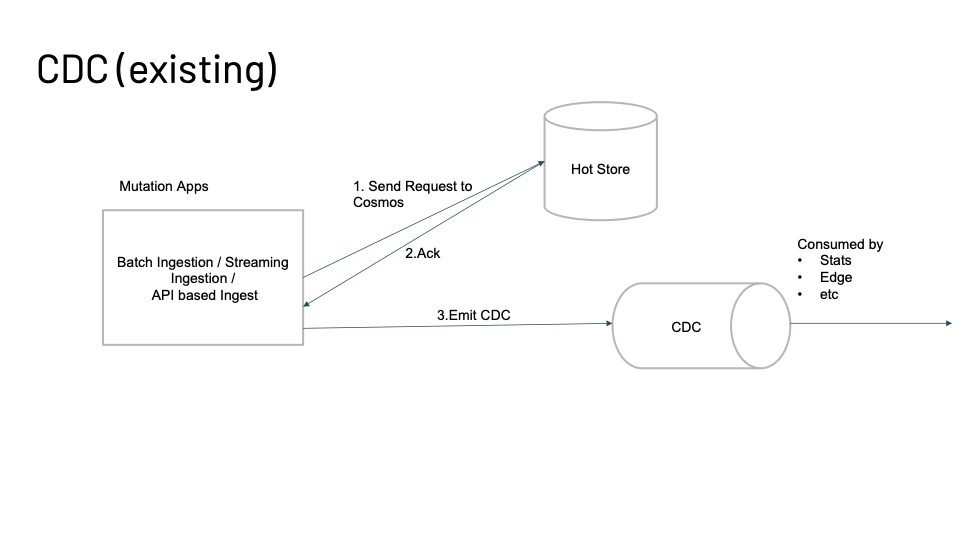
Figure 8 shows how every application that makes a mutation/change on the Real-time Customer Profile Store waits for the Hot Store to ACK the change and then emits a change feed message on the CDC topic. Each message on the CDC topic captures what action was performed (PATCH/PUT/DELETE) along with the payload of the change and various other metadata like source of the data, record type, and timestamp if it’s an event or record that is a function of time.
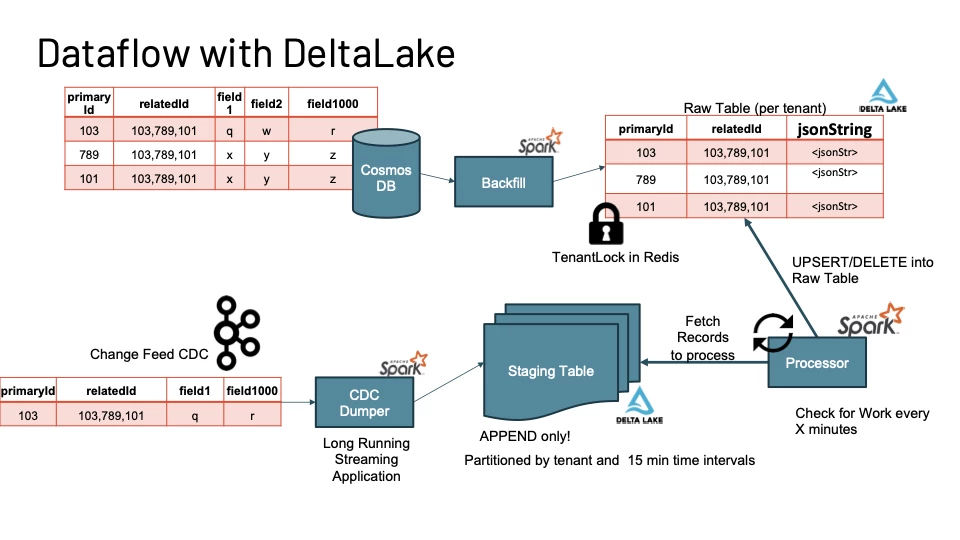
We will utilize these change feed messages to recreate a row by row copy of the Cosmos DB Hot Store on the data lake. As shown in Figure 9, we have a long-running Spark Structured Streaming Application called the CDC Dumper that consumes the change feed notifications that writes to a multi-tenant global Staging table in a APPEND ONLY mode. This ensures that we can expand on the parallelism of the CDC Dumper process without having to worry about write conflicts that we looked at in the preview sections. The Staging table is also a delta lake table which is partitioned by the tenantId and 15 minute time intervals.
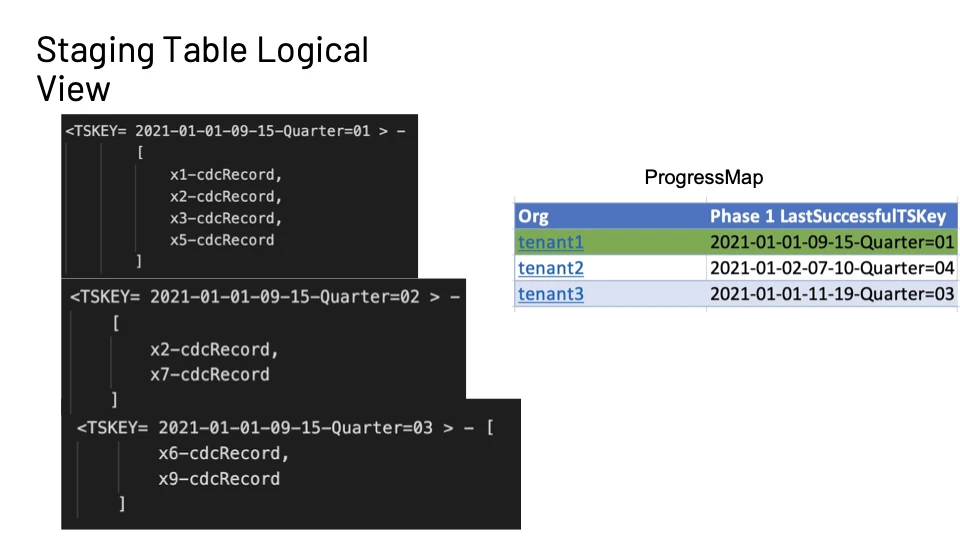
Figure 10 shows a logical view of how the staging table holds onto records within the time intervals. We also have a ProgressMap that is held on Redis to communicate how many records per tenant were written vs processed.
A Processor Spark Job is a long-running batch Spark app that will keep checking if there is any work to be done i.e if any records need to be taken from the staging table and transformed+written into the Destination Delta Lake table which we will call as the Raw table.
The transformations are based on the operation type of the CDC Message itself.
Before starting to process the records for a tenant, the processor will try to obtain a lock for that tenant and proceed only if it is successful. This again is to avoid conflicting UPDATE/DELETE operations from multiple sources.
A key callout is the Raw table stores the values not as Struct Types as is normal with delta lake or parquet but as JSON Strings. We go into detail about this very important design decision in the following section.
Staging Tables FTW
- Multiple Source Writers Issue Solved.
- By centralizing all reads from CDC, since ALL writes generate a CDC.
- Staging Table in APPEND ONLY mode.
- No conflicts while writing to it.
- Filter out bad data greater than thresholds before making it to Raw Table.
- Batch Writes by reading larger blocks of data from the Staging Table.
- Since it acts as time-aware message buffer due to time-aware bucketing.
Why use JSON Strings as the format? Why not Structs?
- We are doing a lazy Schema on-read approach. Since we have a constantly evolving schema that can have field renaming/deletions; we wanted to store the raw data with the full fidelity as it was ingested but at the same time we should not have to issue huge ALTER statements to the delta lake RAW table. This is an anti-pattern and not how delta lake recommends
- Nested Schema Evolution was not supported on UPSERTs in the delta in 2020, caused us to find a temporary alternative and became our main pattern due to the next point
- Nested Schema Evolution on
UPSERTis supported with the latest version of delta lake. For mutable data, we want to apply conflict resolution before upsert-ing. This would be the case where get aPATCHmessage for an existing row. In the Hot Store, we have Stored Procedures at a partition level to handle this atomically.
** An example would be functions resolveAndMerge(newData, oldData).
** Spark UDF’s are strict on types, with the plethora of different schemas per tenant, it is crazy to manage UDFs per org in a multi-tenant fashion for a function like this. The out of the box Spark merge functions were not enough to merge complex structs with each other.
** The other consideration was to write a Native Spark UDF and recompile Spark with it but was deemed too complex as a deployment model on the Databricks SaaS.
** Now we just have simple JSON merge UDF.
** We use json-iter which is very efficient in loading partial bits of JSON and in manipulating them.
- If you don't want to lose all the predicate pushdown, pull out all main push-down filters to individual columns as shown by Figure 11 (Eg.
timestamp,recordType,id, etc.) - Real-time Profile workloads are mainly scan-based since we can run 1000’s of queries at a single time. Reading the whole JSON string from data lake is much faster and cheaper than reading from Cosmos for 20% of all fields.

Data Lake Replication Lag Tracking
Our ingestion pipeline has gone from having a single sink i.e Azure Cosmos DB to having 2 additional pit sinks, the Staging Table and per tenant Raw Table. Instrumentation of the data pipeline gives more confidence to the reader of the data as to understand how consistent their read is.
To aid the end-user and the downstream components, we track 2 types of lag.
CDC lag from Kafka tells us how much more work we need to do to catch up to write to Staging Table. We can see how many minutes/seconds off we are from the time a CDC was produced to it being dumped into the Staging Table.

- Lag on a per-tenant basis.
- We track Max(
TimeStamp) in CDC per tenant. - We track Max(
TSKEY) processed in Processor. - The difference gives us a rough lag of replication and should tell us how long did it take for the message to be created on the CDC topic and be replicated into the tenant’s Delta Lake Raw table.
Performance Time!
In the introductory sections and specifically in Figure 5, we emphasized the update amplification that can occur with our use case. We decided to put that to the test where we observed 2 scenarios as shown in Figure 13. We see impressive UPSERT performance even with a very minimal 24 core cluster.
Two important Databricks-only settings we needed to set to achieve this throughput and latency:
- AutoOptimize: This aims to maximize the throughput of data being written.It will automatically reduce the number of active files it needs to write the data to by doing an adaptive shuffle across Spark partitions. Excellent for Streaming writes use cases.
- AutoCompact: This checks if files can further be compacted, and runs an
OPTIMIZEjob (with 128 MB file sizes instead of the 1 GB file size used in the standardOPTIMIZE) to further compact files for partitions that have the most number of small files.

Now comes the critical part where we execute and test our Main Access Pattern shown in Figure 6 on top of the data in the Delta Lake in the format we have chosen.
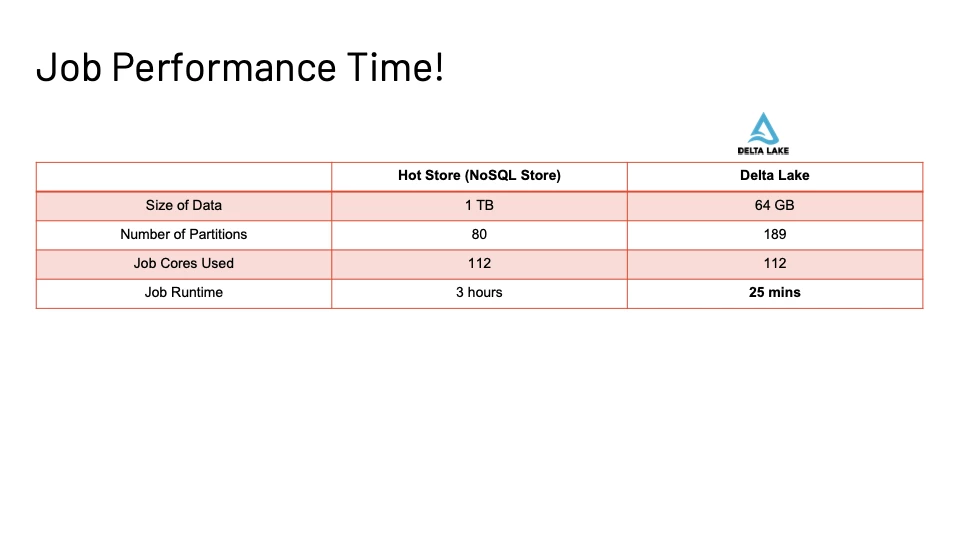
Figure 15 shows the massive change in time taken (80% +) between the exact same workload between the Hot store and the Delta Lake Raw table for a 1 TB load.
The reasoning is due to faster IO from the delta lake for the scan workload along with the compression of data we get from 1TB to 64 GB on the lake. This means we read less data that has more partitions that in turn helps us use the Spark cores in the cluster more efficiently.
Putting Everything Together
The main takeaways are:
- Scan IO speed from the data lake is magnitudes faster
Readfrom Hot Store. - Reasonably fast eventually consistent replication within minutes possible with DeltaLake and Spark structured Streaming.
- More partitions mean better Spark executor core utilization.
- Potential for more downstream materialization and refinement.
- We get an incremental computation framework thanks to the Staging tables.
We expect to share more lessons as we port more scan-intensive workloads to the data lake architecture and continue to evolve this.
Related Blogs
Apache Spark and Adobe Experience Platform
- How Adobe Does Millions of Records per Second Using Apache Spark Optimizations — Part 1
- How Adobe Does Millions of Records per Second Using Apache Spark Optimizations — Part 2
- Streaming Spark EXPLAIN Formatting in Adobe Experience Platform
Real-time Customer Profile and Identity
- Pilot the Overall Customer Experience with Journey Orchestration
- Using Identity Graph Viewer to Validate and Debug Adobe Experience Platform’s Identity Services
- Using Akka Streams to Build Streaming Activation in Adobe Real-Time Customer Data Platform (Part 2)
- Using Akka Streams to Build Streaming Activation in Adobe Real-Time Customer Data Platform (Part 1)
- Journey Orchestration in an Omnichannel World
- Segmentation in Seconds: How Adobe Experience Platform Made Real-time Customer Profiles a Reality
- Adobe Experience Platform’s Identity Service — How to Solve the Customer Identity Conundrum
- Implementing Adobe Experience Platform Real-Time Customer Profile through our “Customer Zero”…
- Adobe Experience Platform Identity Graph is the Foundation for the Unified Profile
References
- Adobe Experience Platform Unified Profile
- Apache Spark
- Databricks
- Delta Lake
- JSON-Iter
- Databricks Auto-optimize
Originally published: Jun 17, 2021