
Iceberg at Adobe
Authors: Shone Sadler, Romin Parekh, and Anil Malkani.

Adobe Experience Platform is an open system for driving real-time personalized experiences. Customers use Adobe Experience Platform to centralize and standardize their data across the enterprise resulting in a 360-degree view of their data that can then be used with intelligent services to drive improved experiences across multiple devices, run targeted campaigns, classify profiles, and leverage advanced analytics.
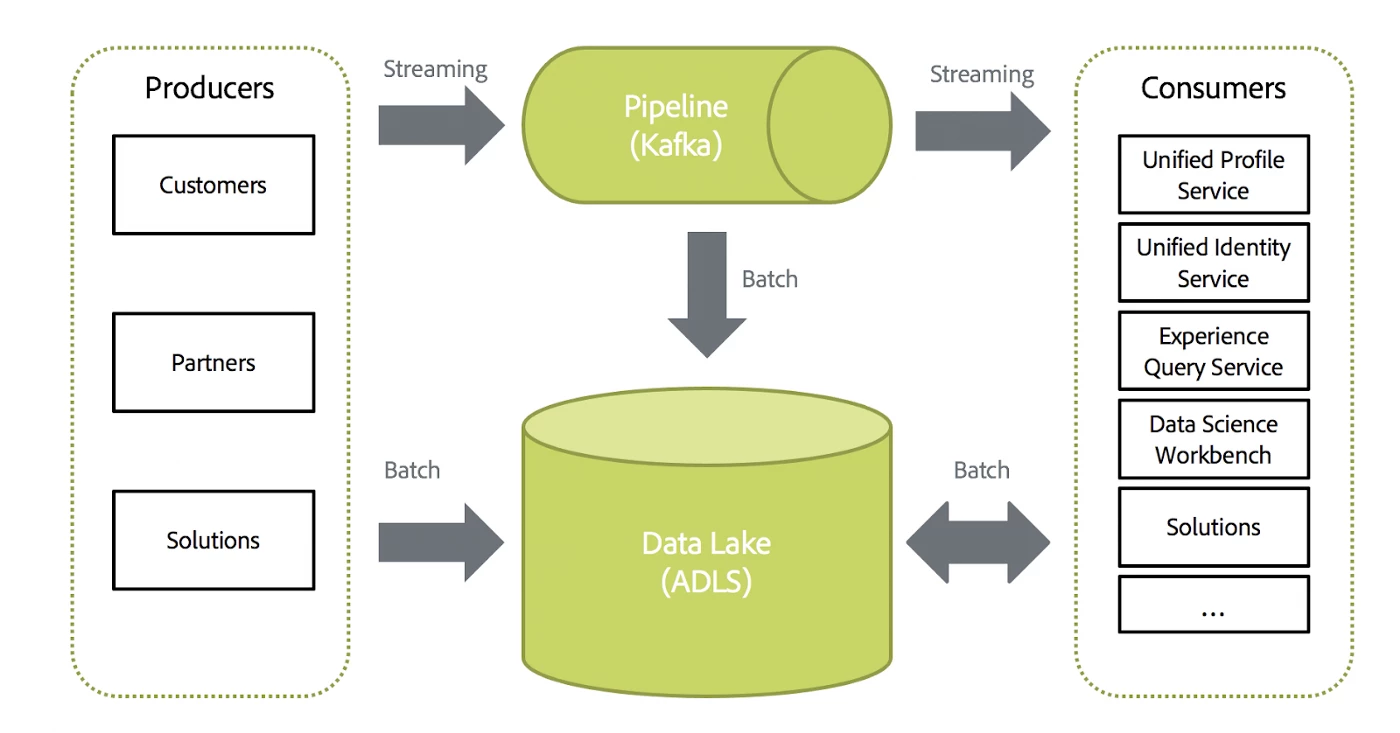
Adobe Experience Platform is the infrastructure capable of processing exabytes of data. Its architecture is designed on a Lambda architecture for the efficient and large scale processing of both streaming and batch workloads. Our customers, partners, and Adobe solutions send their data with minimal latency and eventual consistency within the Platform. Once data is ingested in the Data Platform it can be both acted and reported on.
Data Lake
Adobe Experience Platform Data Lake is the source of truth for downstream consumers in need of historical analysis. All data ingested into the Data Platform eventually lands into the Data Lake.
While Data Lake is currently processing ~1 million batches per day, which equates roughly to 13TB of data and 32 billion events, this load will necessarily scale several orders of magnitude as more Adobe solutions and customers migrate onto Adobe Experience Platform in 2021.
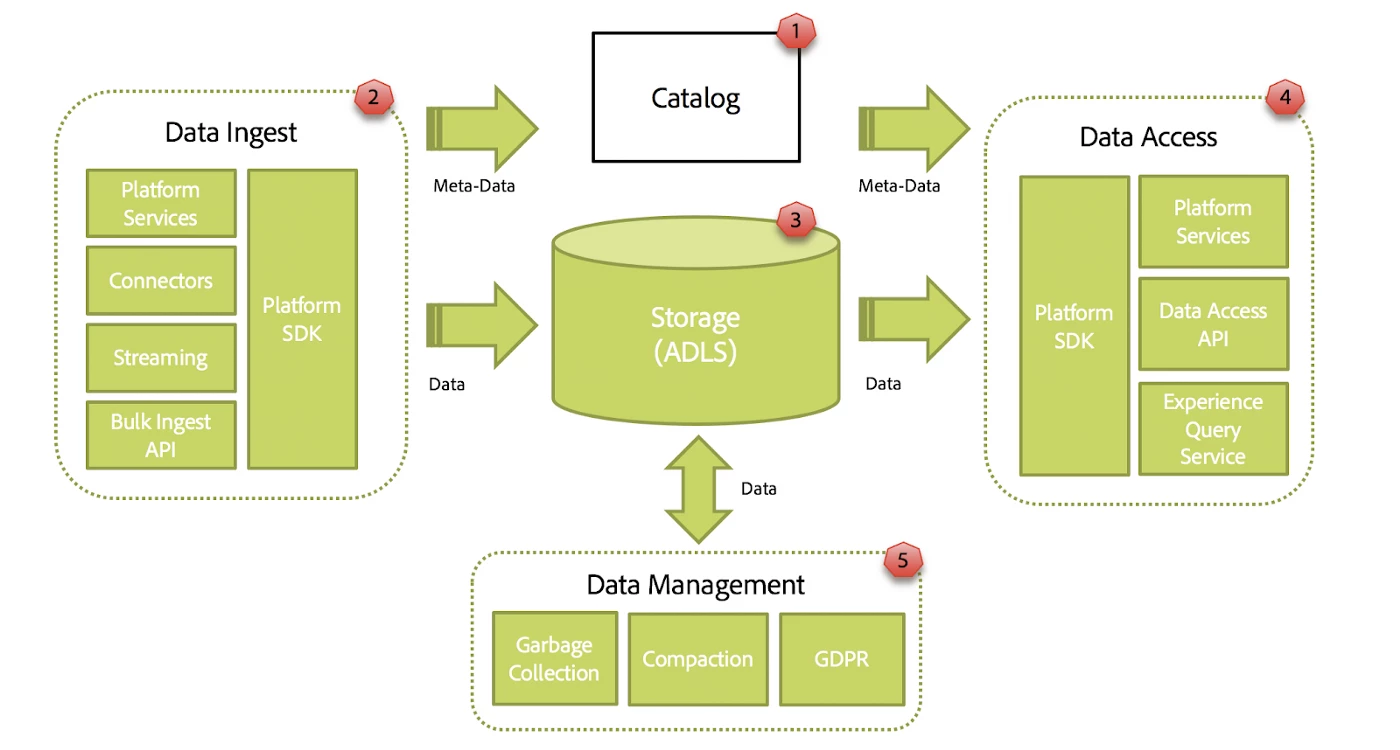
The Data Lake can be broken down into the following areas illustrated below.
Catalog
Adobe Experience Platform’s Catalog service provides a way of listing, searching, and provisioning a DataSet, which is Adobe Experience Platform’s equivalent of a table in a Relational Database. When a client wishes to send data to Adobe Experience Platform, it will start by provisioning a DataSet in Catalog providing information such as name, description, schema, and data governance configuration (e.g. permissions). Schemas in Adobe Experience Platform are instances of Experience Data Models (XDM). XDM is an open-source initiative to capture domain-level digital experiences through the use of JSON Schema.
DataSets fall into four categories:
- Record DataSets: A record dataset assumes that each row has a unique Id value used to identify an entity. Record DataSets are used to upload Dimensional data (e.g. Product Catalogs) that will be joined with TimeSeries datasets explained below.
- Profile DataSets: A profile dataset assumes that each row has a unique “identity” value used to locate/update an entity. An identity value is unique to an entity, typically an individual person. Examples include login ID and/or loyalty ID which are referred to as known identities. Other identities, such as cookie IDs and/or visitor IP addresses, that single out a device without identifying a person using it are Unknown or anonymous identities. Profile Datasets are used when uploading CRM-like data with a mix of identities and other properties that typically are joined with TimeSeries datasets.
- TimeSeries DataSets: A time-series dataset contains immutable, event data that represents some context at a point in time. A typical example would be clickstream data, a detailed log of how a user navigates through a site.
- Adhoc DataSets — Any dataset which doesn’t fit into one of the standard shapes discussed above can still be described and managed as a custom, ad-hoc dataset. Such datasets can be ingested into and queried like any other datasets on Data Lake.
Customers use a mix of these datasets to drive personalized experiences.
Data Ingest
Producers can write to the Data Lake in either streaming and/or batch mode. Streaming clients write messages to an HTTP endpoint that forwards messages to Data Lake via a Kafka infrastructure. Spark Streaming application subscribes to those messages and outputs them to Data Lake in 15-minute intervals. Alternatively, clients can send data in larger batches by either using the bulk ingest API within Adobe Experience Platform directly or using one of a number of Adobe Experience Platform Connectors that are available for integrating with external third-party systems.
In either case, the following behaviors are applied when promoting data in Data Lake.
- Validation: We ensure that the data published conforms to the XDM schema specified for a DataSet. Data that doesn’t conform is side-carted for analysis and further diagnosis.
- Transformation: We convert data that doesn’t match the underlying schema exactly, accounting for minor differences in the data-type where lossless transformation is possible (e.g. from String to Int). For more advanced transformations, clients can leverage a data prep component to apply more complex transformations to the underlying data (e.g. field mapping, string manipulation, and numeric functions).
- Buffering/Compaction: When we receive high-frequency small files, Data Lake will begin buffering and/or compacting data before making it available downstream.
- Partitioning: We necessarily divide data into slices on disk for more efficient processing.
- Exactly-Once-Guarantee: We ensure that data is promoted to Data Lake once and only once. i.e. data will either be written to Data Lake or the related transaction failed with actionable feedback. Data will not be duplicated.
- Restatement: We ensure clients can re-write and delete data that has been previously sent.
Data Storage
At the center of Adobe Experience Platform’s Data Lake Architecture is the underlying storage. Data Lake relies on a Hadoop Distributed File System (HDFS) compatible backend for data storage, which today is the cloud-based storage provided by Azure, i.e. Azure’s gen2 Data Lake Service (ADLS). Azure’s ADLS Service provides the secure, scalable, high performant, and fault-tolerant storage infrastructure needed to help manage our customer’s data.
The data format used for storage is Parquet, an open-source column-oriented data format designed for Big Data systems. Parquet stores binary data in a column-oriented way, where the values of each column are organized so that they are all adjacent, enabling better compression. The Parquet format is especially effective for queries that read a subset of columns from a “wide” table containing many columns. Since only a subset of columns is read, I/O is minimized.
Data Lake also employs different partitioning strategies based on the type of data being stored to optimize queries in the Data Access Layer. e.g. for TimeSeries DataSets, data is partitioned by day making it efficient for queries that filter by time.
Data Access
Adobe Experience Platform Query Service is a high-performance, distributed, query engine. Adobe Experience Platform Query Service is tuned to querying data on the Data Lake that has been collected by touch-points enabled through Adobe’s Digital Marketing Solutions. Using Adobe Experience Platform Query Service users can slice and dice their experience data using standard SQL syntax and create materialized views of their data using Adobe Experience Platform Query Service’s “Create Table as Select” (CTAS) feature. The data collected by Adobe Solutions, enriched by Adobe Experience Platform Services, such as Real-time Unified Profile Service, and transformed by using Data Prep and/or Adobe Experience Platform Query Service can be egressed by clients using the Data Access API. Finally, the easiest way to interact with data on the Data Lake is by leveraging solutions such as Adobe Analytics and Campaign that will allow customers to perform analysis and personalization based data managed within Data Lake.
Data Management
Data Lake has a number of maintenance operations that will be applied to at rest data including:
- Compaction: Data often becomes fragmented over time due to late-arriving data and restatements, restatements/updates, and/or small files sent by producers. As a result Data Lake will trigger a compaction process when necessary to optimize data for reading. Compaction will merge smaller files into large ones where possible to minimize the IO incurred on reads.
- Garbage Collection: Data needs to be hard-deleted from disk at some point in time due to either an explicit delete applied by a client and/or data implicitly falling outside of the configured retention period. Data Lake employs a soft delete/tombstone strategy, whereby data will be marked for deletion, making it inaccessible for new queries. An asynchronous Garbage Collection process is responsible for hard-deleting the data from the disk at a later point in time.
- GDPR: General Data Protection Regulation (GDPR) and similar privacy laws mandate that Data Platform both reports back personal data to customers and users as well as deletes such data when requested.
Adobe Experience Platform SDK
Core to Data Lake is a lightweight library, Adobe Experience Platform SDK. While it is small in stature, it plays a key role in the architecture. Adobe Experience Platform SDK abstracts upstream producers and downstream consumers from the underlying table and/or storage format being used in the Data Lake. Having this abstraction in place allows us to more easily plug-in support for a different table and/or storage formats when necessary.
Why Iceberg?
Managing analytical datasets using standard Spark at the scale that our customers operate at has proven to be a challenge for the following reasons:
-
Data Reliability
- Lack of Schema enforcement can lead to type inconsistency and corruption.
- Failed Spark jobs can result in partial results being read downstream.
- Concurrent Readers and Writers often result in conflicts and data loss.
-
Read Reliability
- Massive tables result in slower directories and file listing — O(n).
- Data restatement results in inconsistent reads.
- Coarse-grained split planning results in inefficient data scans due.
-
Scalability
- Dependency on a separate metadata service risks a Single Point of Failure.
- Metadata needs to be evicted, compacted, and rewritten to scale planning.
Until recently we had been attempting to solve these big data problems with homegrown solution that evolved internally. Meanwhile, we kept our eye on projects such as Apache Iceberg, an open-source table format for managing analytical datasets that addressed many of these problems out-of-the-box.
Moreover, we saw the Iceberg community moving forward into areas of interest to us and our use-cases, such as:
- Row-level deletes and upserts
- Merge-on-Read
- Time-Travel
- Incremental Reads
- Change Data Capture
After performing several successful Proofs-of-Concept internally we started down the path of migrating our underlying table format to Apache Iceberg. Now, we are celebrating the completion of that migration as we write this blog.
Iceberg at Adobe
A design point we deeply appreciated with Iceberg was that it’s simply a Java library that could easily be embedded inside of our current applications or more specifically our Adobe Experience Platform SDK as shown below. This SDK leverages Spark’s DataSource API to plugin different backends. This allowed us to simply plugin Iceberg’s Spark DataSource implementation translating those APIs into Iceberg-specific operations. The additional table metadata managed by Iceberg (described in the next section) is stored co-located with the data in the underlying storage. In ADLS, that location is a sibling directory “meta” relative to the “data” directory.
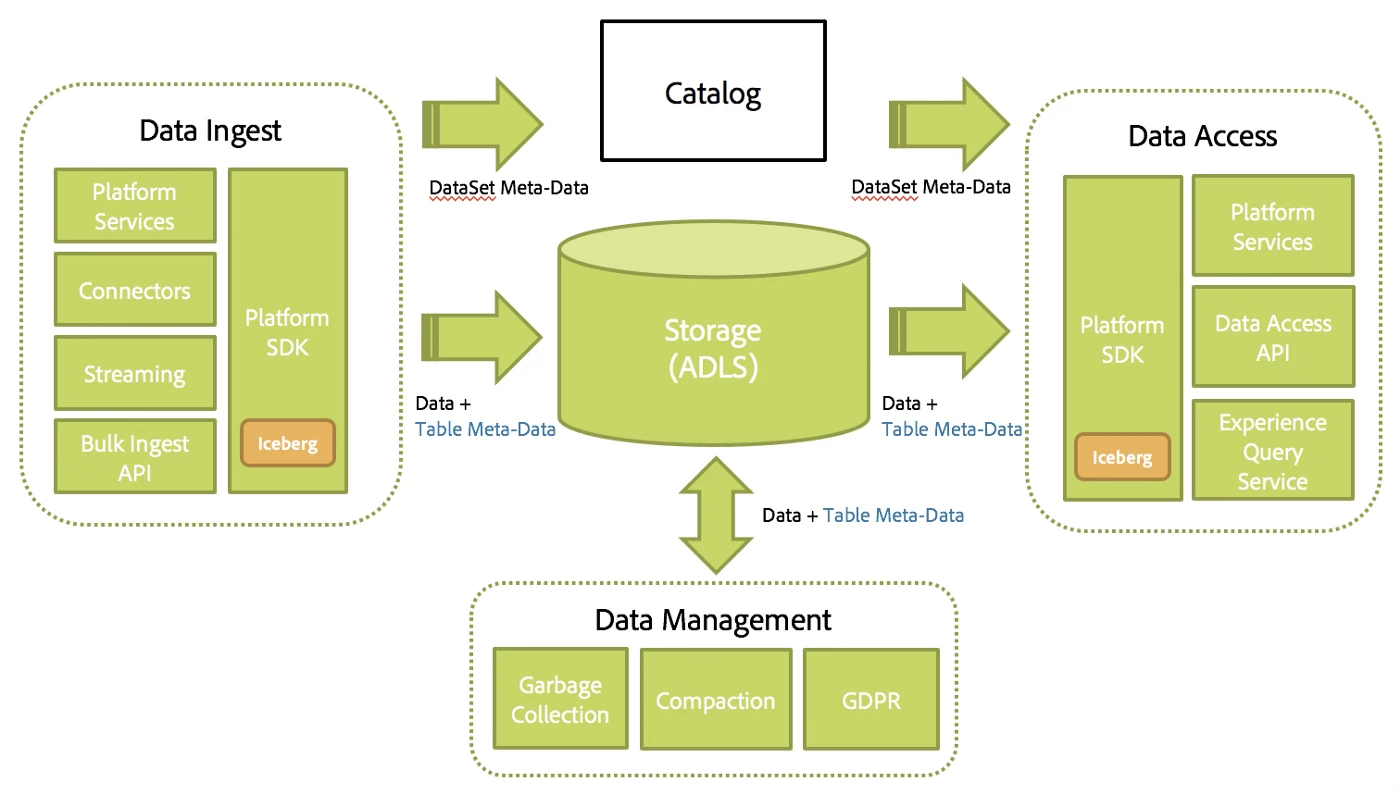
Iceberg’s lightweight design had several benefits:
- No operational overhead in running a separate service
- No risk of a Single Point of Failure
- Naturally scales horizontally with our Spark applications
- Easily abstracted in Adobe Experience Platform SDK
These benefits were multiplied for each producing and consuming service within Adobe Experience Platform.
DataSet vs. Table Metadata
When clients interact with Data Lake they read and write data DataSets based on its unique GUID and/or name. The metadata for datasets is stored in Catalog and is used to configure partitioning behavior, schema information, policy enforcement, and other behaviors within Adobe Experience Platform.
A table is Iceberg’s equivalent of a DataSet and used to store metadata about the data and files on disk. For each DataSet in Adobe Experience Platform we have a complementary Iceberg table stored in ADLS and we automatically map schemas expressed using Experience Data Model (XDM) into Iceberg schemas.
When Producers write data to Data Lake they use batches. A batch is a chunk of data realized as one or more input files sent by a Producer that is promoted into Data Lake as a single transaction. Clients can monitor the status of their batches using Adobe Experience Platform’s UI and/or through Catalog’s APIs.
Today, an Adobe Experience Platform dataset can be viewed as a collection of batches as shown below.
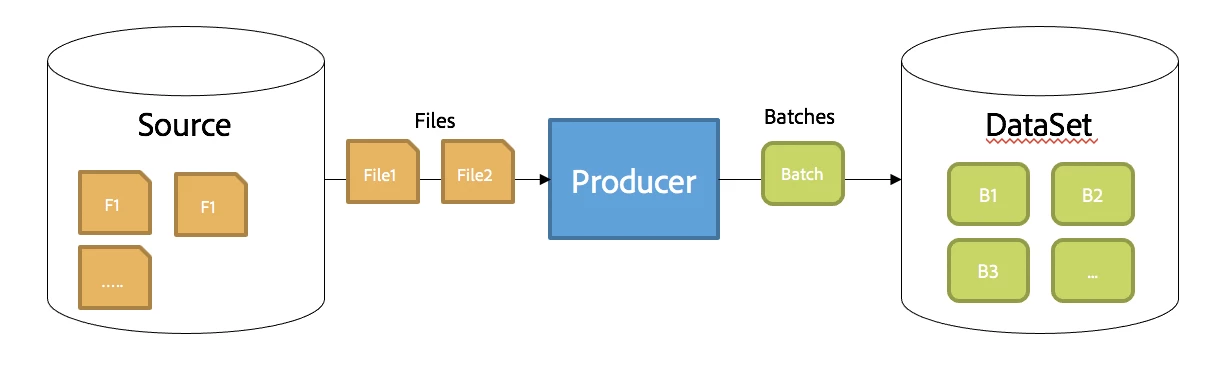
Accordingly, As part of the integration with Iceberg we needed to map the concept of a Batch in Adobe Experience Platform to the concepts within Iceberg.
Snapshots
Adobe Experience Platform Batches map well to snapshot’s in Iceberg. While an Adobe Experience Platform Batch represents a chunk of data that is committed to a DataSet, a snapshot in Iceberg represents a committed write operation. A DataSet can be seen as a linear progression of snapshots over time as shown below. Each time a Producer writes a Batch a snapshot is generated and the DataSet progresses forward.
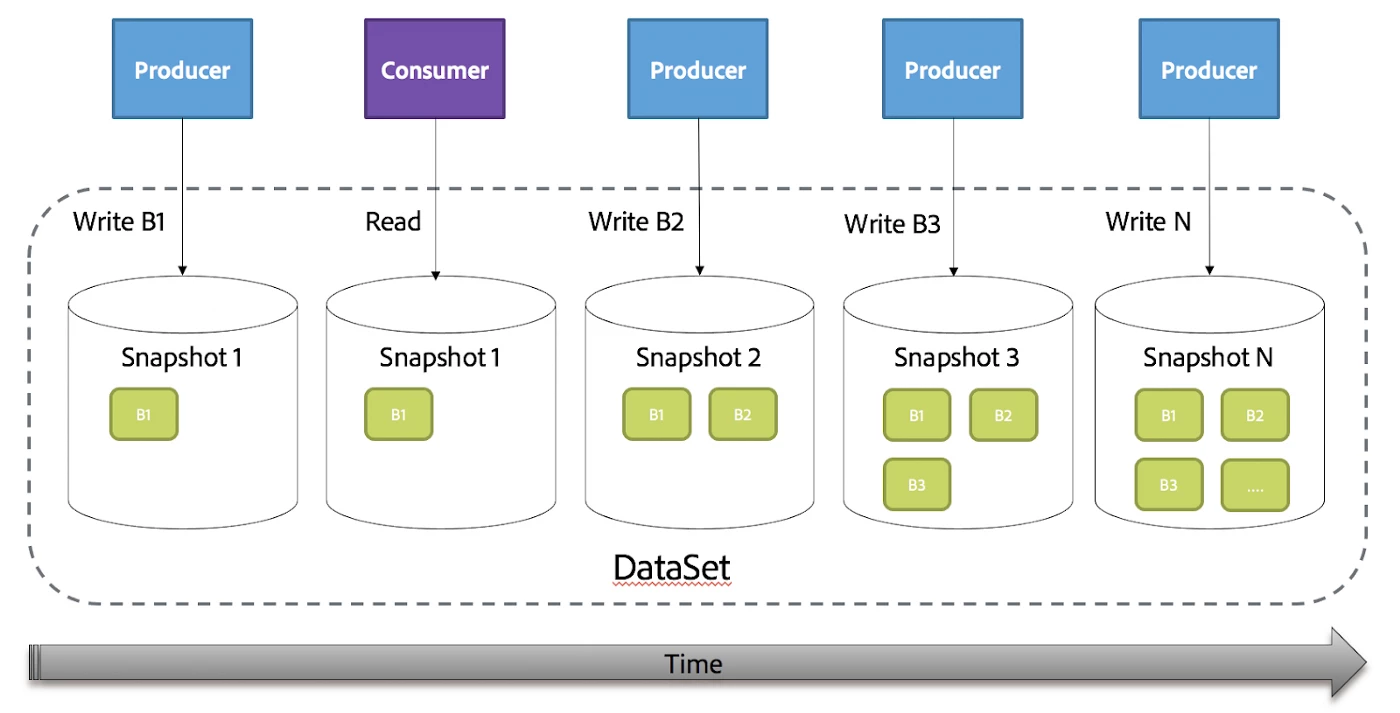
By default consumers querying data from a DataSet see the latest set of active Batches in that DataSet or rather a snapshot in Iceberg (i.e. snapshot N above). A snapshot can result from a Producer writing a Batch or from internal Data Management operations such as Garbage Collection and/or GDPR.
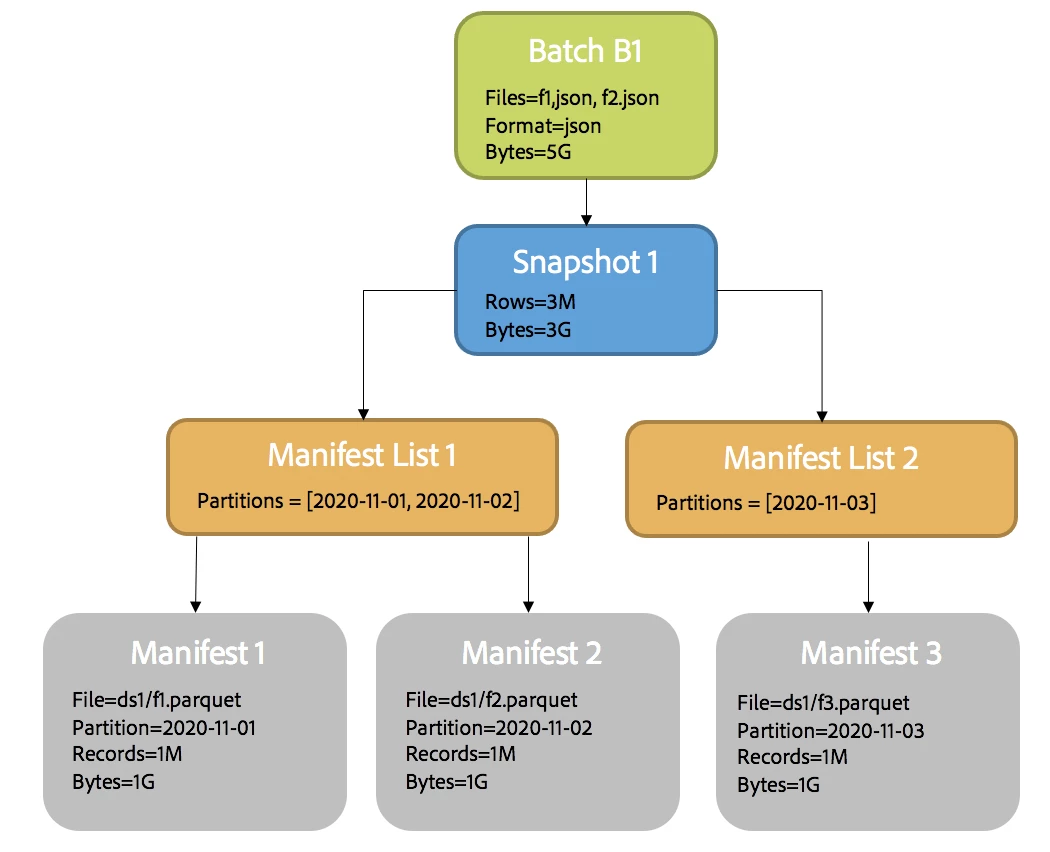
Manifest Files
Drilling further into Iceberg metadata we can see that each parquet file output to an Adobe Experience Platform DataSet is tracked by a manifest file in Iceberg. A manifest file is a metadata file that lists a subset of data files that make up a snapshot.
Manifests track the following data points:
- Format and Location: Necessary for locating and reading data files after planning is complete.
- Lower and Upper-level Bounds for Partition Values: When query planning and determining what files to read, Iceberg uses min/max partition values to cherry-pick manifests. This ensures out-of-bounds manifests are completely skipped and our query processing engine does not waste cycles reading those files.
- Metrics for cost-based optimizations: Includes file-level stats (e.g. row count) and column-level stats (e.g. min value, max value). These stats help our query processing engine group tasks in an optimized manner and skip files where possible during query planning.
These additional data points enable optimizations in Iceberg such as partition pruning, file-skipping, and predicate pushdowns to the snapshot and manifest level. This coupled with columnar storage format like Parquet, makes data access significantly more lightweight and faster in Adobe Experience Platform.
Manifest Lists
A Manifest List is a metadata file that link manifests with the snapshots that make up a table. Each manifest file in the manifest list is stored with information about its contents, like partition value ranges, used to also speed up metadata operations and query planning. The manifest list acts as an index over the manifest files, making it possible to plan without reading all manifests.
The following diagram illustrates the relationship between batches and Iceberg metadata. The example batch, B1, was written by a producer and made up of 2 input files of time series data (partitioned by date) containing 5 Gigabytes of unpartitioned JSON data. As B1 is promoted and written to Adobe Experience Platform’s Data Lake it is parsed, validated, transformed, compressed, partitioned, and written out to disk. Adobe Experience Platform’s Platform SDK now delegates it’s write operation to Iceberg’s DataFrame writer, which not only writes the JSON data to disk (compressed and partitioned) but also a) writes table metadata (snapshots, manifests, and manifest lists) and b) commits both the data and metadata to Data Lake in an atomic transaction.
Data Restatement
Simply appending new data to a DataSet in any Data Lake is the simplest of operations, yet a necessary one. Data restatement (mutating data) on the other hand has been a challenge on Data Lake due to issues in supporting multiple concurrent readers and writers on the primitives of distributed files systems like HDFS, ADLS, and S3.
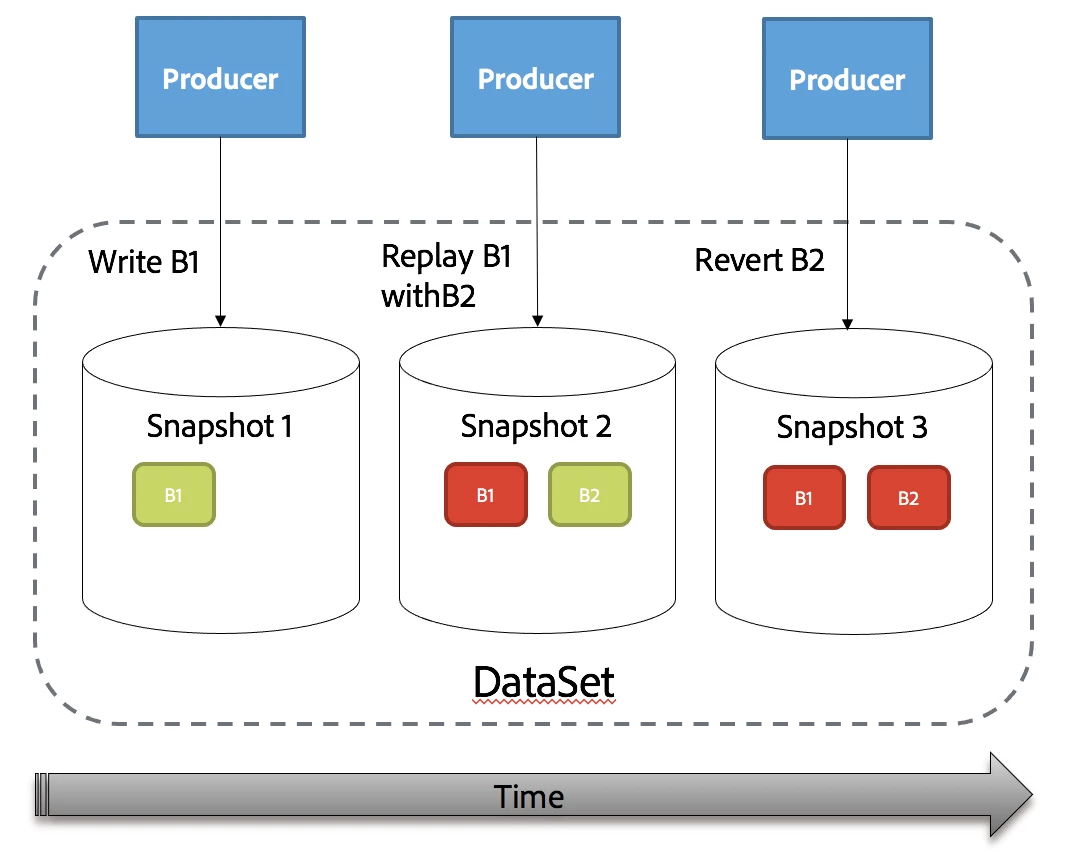
In Adobe Experience Platform’s Data Lake producers can restate data using its Bulk Ingest API to either replay batches (replace an existing chunk of data with a new chunk) or revert batches (deleting an existing chunk of data).
Both restatement operations (replay and revert) are illustrated in the diagram below.
The order of operations is as follows:
- First, Producer Writes B1
- Second, Producer Replays B1 with B2
- Finally, Producer Reverts B2
At the end of these operations, we expect to have an empty DataSet.
What makes this challenging is applying these mutations in light of having N number of readers and writers operating on-top of that data in parallel. The types of problems we expect to see are:
- Failed Spark jobs can result in partial results being read downstream.
- Concurrent Readers and Writers processing the same data causing conflicts and data loss.
- Inconsistent reads.
Iceberg employs an elegant and proven design to these problems, Multi-Version Concurrency Control (MVCC). Producers create table metadata files optimistically, assuming that the current version will not be changed before the Producer’s commit. Once a Producer has created an update, it commits by swapping the table’s metadata file pointer from the base version to the new version. Readers use the snapshot that was current when they load the table metadata and are not affected by changes until they refresh and pick up a new metadata location. Iceberg’s MVCC enables Adobe Experience Platform to achieve serializable isolation in a distributed environment, where each mutation is treated as if it was executed serially and readers are not impacted by changes until they refresh.
The diagram below illustrates the impact on Iceberg metadata for the batch replay operation above, where B2 replaces B1, with the added assumption that a single row (in partition 2020–11–02) has been deleted from the data.
Figure 8: Iceberg Snapshots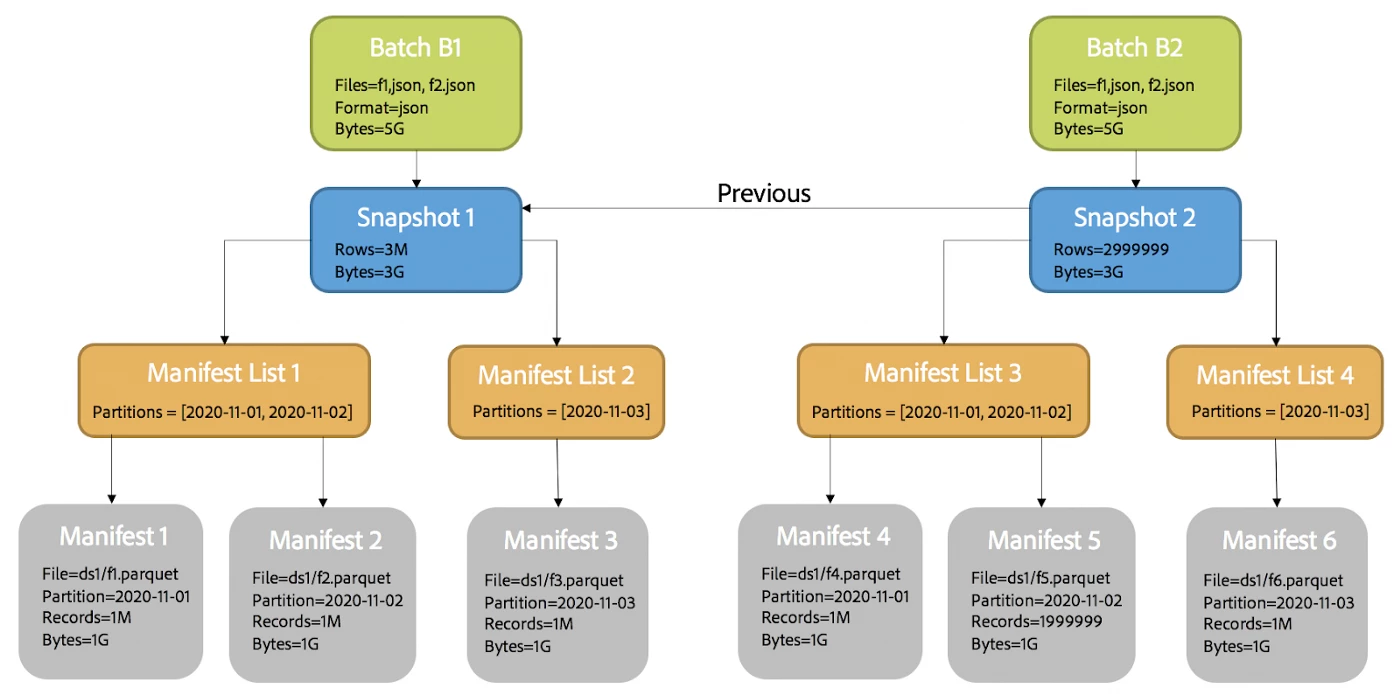
Table metadata is stored as JSON. Each table metadata change creates a new table metadata file that is committed by an atomic operation. This operation is used to ensure that a new version of table metadata replaces the version on which it was based. This produces a linear history of table versions and ensures that concurrent writes are not lost.
The atomic operation used to commit metadata depends on how tables are tracked and is not standardized by Iceberg. However, there is a default implementation for File System tables stored on HDFS like backends such as ADLS. In the case of Adobe Experience Platform the implementation of atomic commits in Adobe Experience Platform relies on the rename operation in ADLS, which is guaranteed to be atomic if overwrite is set to true.
Time-Travel and Incremental Reads
Beyond the reliability features described above Iceberg also brings a number of useful features such as Time Travel and Incremental Reads, enabled through its use and management of table metadata. Time-Travel is the ability to make a query reproducible at a given snapshot and/or time. Incremental Reads is the ability to query what has changed between two snapshots and/or times.
Through the history maintained in Iceberg’s metadata, we are able to support the following types of queries in Data Lake.
Querying By Snapshot (i.e. Time Travel)
Querying a specific version of the table:
SELECT * FROM dataset VERSION AS OF {SNAPSHOT_ID}
Querying a specific version of the table:
SELECT * FROM dataset VERSION AS OF {ISO_8601_DATETIME}
Querying for Deltas (i.e. Incremental Reads)
Querying table for changes between snapshot versions:
SELECT * FROM dataset VERSION BETWEEN {START_SNAPSHOT_ID} AND {END_SNAPSHOT_ID}
Querying table for changes between start snapshot version to the current latest version:
SELECT * FROM dataset VERSION SINCE {START_SNAPSHOT_ID}
Querying table for changes that arrived between timestamps:
SELECT * FROM dataset VERSION BETWEEN {START_ISO_8601_DATETIME} AND {END_ISO_8601_DATETIME}
Querying table for changes that arrived after TIMESTAMP:
SELECT * FROM dataset VERSION SINCE {START_ISO_8601_DATETIME}
The above syntax shows types of queries that can now be expressed with DataSets backed by Iceberg tables. In the example below, we show how such queries can be used.
Note: The syntax for both Time Travel and Incremental Read features allows for either Timestamp or Snapshot based predicates. Due to the distributed nature of writes, there is a risk of time drift. As a result, the use of Snapshot Ids is best practice when accuracy is a requirement.
Example
In this example, a fictitious Adobe Experience Platform customer, ABC, is using Adobe Analytics to collect click information (page and identity) from its website and forwarding it to a “Clicks” dataset in Adobe Experience Platform. Note, the identity information is tracked using Adobe Experience Platform’s Identity Service, which provides universal and persistent visitor Ids that can be tracked across Adobe Experience Platform solutions.
Ingesting Clicks
At time T0 Adobe Analytics collects and sends a single batch for ABC to the new Clicks DataSet. The batch is stored with the batch id of B1.
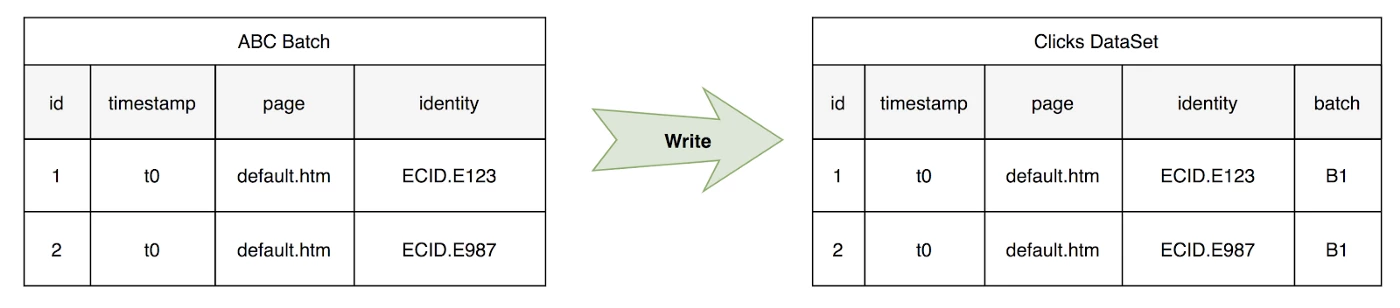
Querying Clicks
At time T1 ABC issues both a snapshot query for T0 and an incremental query since T0.
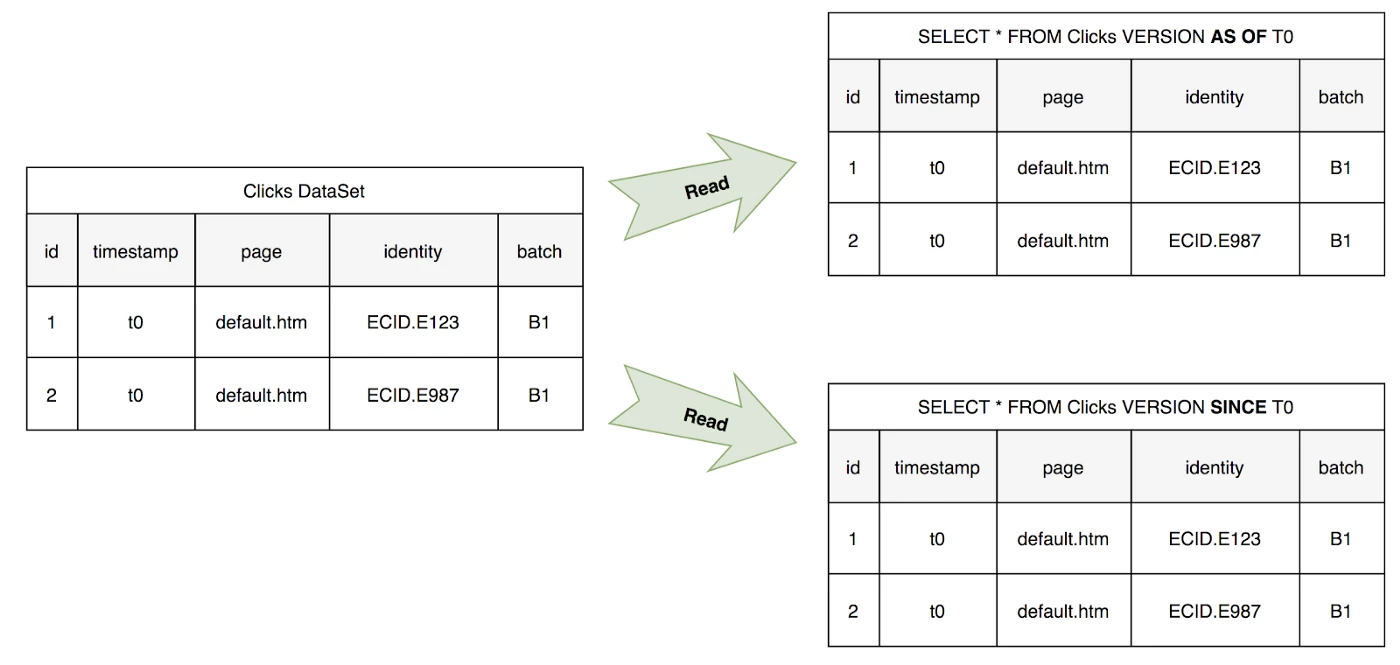
In this case the snapshot query and the incremental return the same results, which is expected.
Replaying Clicks
At time T2 the customer, ABC, restates data due to a misconfiguration in its website’s tagging. The fix results in a restatement of the collected data, i.e. a Batch Replay operation that replaces B1 with B2.
We can see in the illustration below that event 2 is deleted, while a new event 3 is inserted for an autos.htm web page. However, due to the nature of Batch Replay the entire batch B1 must be rewritten (i.e. event 1 must be re-sent along with event 3).
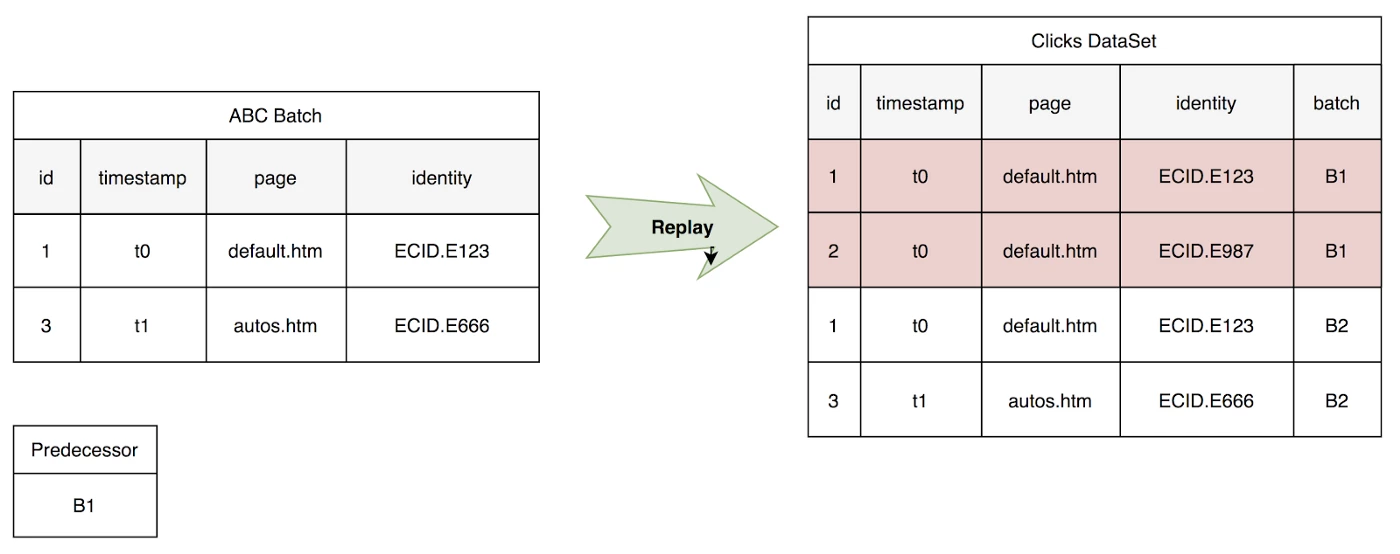
Querying Latest Clicks
Now at the time, T3 ABC issues three queries that we can analyze:
- A regular select
- A snapshot query for T0
- An incremental query since T0
The regular select returns the batch that is currently active in the dataset (i.e. B2). The snapshot query leverages the Time-Travel feature in Iceberg to query the DataSet as of T0 when the active batch was B1 and returns rows with id 1 and 2 respectively. Finally, the Incremental query leverages the commit log in Iceberg to derive the changes that occurred since time T0, including rows with id 1 and 3.
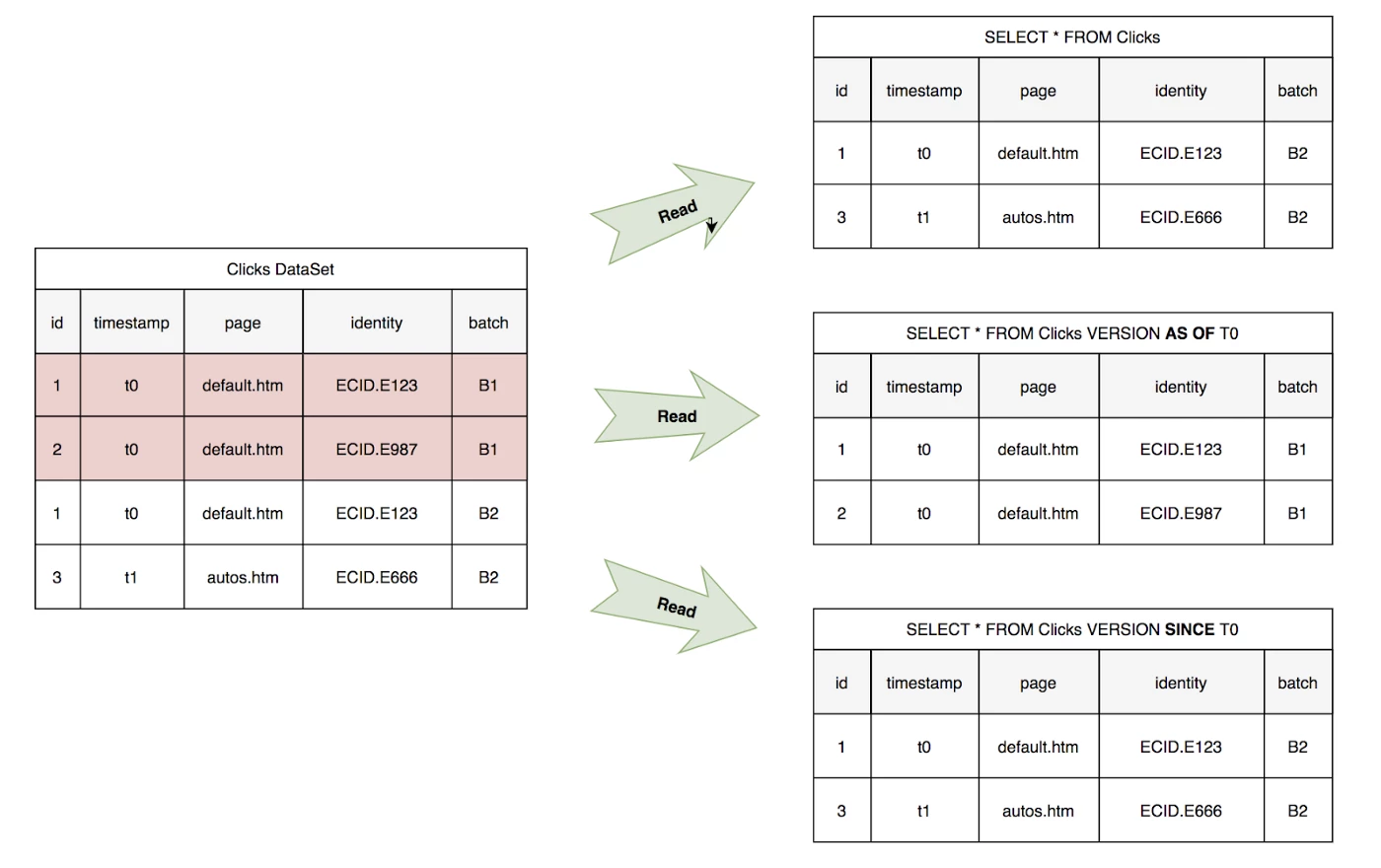
It is important to point out that the Incremental query should ideally return rows that have been deleted along with what has been inserted and/or upserted. An additional metadata field (e.g. changeType), would be needed to signal what rows were deletes vs. upserts vs. inserts. The ability to incrementally read deleted vs. updated or inserted data is not there yet but is on the roadmap.
Our Learnings
First, we explained Adobe Experience Platform’s Lambda architecture at a high-level and where Data Lake and Iceberg fit into that picture. Data Lake is a critical component of Adobe Experience Platform that enables data-driven decisions for our customers and the ability for Adobe, our customers, and 3rd parties to build data-powered products and services. In addition, we outlined a number of challenges we faced in building the 1.0 of Adobe Experience Platform’s Data Lake, including issues around data & read reliability as well as scalability. Then we discussed where Iceberg fits into the Adobe Experience Platform stack (Platform SDK) and how we integrated the concepts within Adobe Experience Platform (DataSets and Batches) with those in Iceberg (tables, snapshots, and manifests). That integration has helped us overcome a number of challenges we had in read/write reliability and scalability. Iceberg’s lightweight design allowed us to easily plug it into Platform SDK without the dependency of another Single Point of Failure (SPOF). Its Multi-Version Concurrency Control (MVCC) capability enables us to restate data safely without concern for partial results, corrupting data, or breaking downstream consumers. Its partition ranges and column level statistics allows us to optimize query planning and execution to an extent not possible before. Iceberg enables a host of new features for us on Data Lake such as Time-Travel and Incremental Reads which we previously lacked a clear path to achieve. Finally, Iceberg is an open-source Apache project, with a vibrant and growing community.
Attempting to cover the details of the integration of Iceberg at Adobe would be too ambitious and overwhelming for a single blog. There were a number of challenges and tradeoffs that needed to be overcome and considered along the way. As a result, we have broken down this story into the following areas that, if interested, you should keep an eye out for the following topics.
- High Throughput Ingestion with Iceberg: Discusses write challenges such as managing high throughput with high-frequency small files.
- Taking Query Optimizations to the Next Level with Iceberg: Discusses read challenges such as attaining vectorized reads.
- Reliable Data Restatement with Iceberg: Discusses data-restatement challenges to support General Data Protection Regulation (GDPR) like use-cases.
- Operationalizing Iceberg: War stories related to migrating and running our workloads at scale on-top of Iceberg.
Our journey with Iceberg is just beginning. Expect to see more blogs follow as we journey into topics such as data replication, incremental pipelines, schema-on-read, advanced insights/reporting, and managing data quality.
What’s Next?
This article is an introduction to the story of Iceberg at Adobe Experience Platform. Subsequent blogs will follow to detail further challenges and learnings.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References