
How to Set Up a Kubernetes Clusters with Helmfile
Authors: Constantin Muraru and Jody Arthur
This post provides code examples of how Adobe Experience Platform uses helmfile in Kubernetes to streamline the installation and management of infrastructure applications needed to support large-scale deployment of applications.
Kubernetes is one of the most widely used and popular open-source container management systems among data-driven enterprises today. At Adobe, we use Kubernetes for a wide range of tasks that power Adobe Experience Platform. To meet the needs of our internal use cases, we build Kubernetes clusters and make them available to our internal customers for the deployment of their applications. One example is Adobe Experience Platform Pipeline, which uses Kafka to provide a single enterprise-level message bus for transferring data between different applications within Adobe Experience Platform. Pipeline operates through a simple web service on top of the Kafka service and is deployed using Kubernetes.
Due to the huge volumes of requests received each day, Pipeline requires a level of resilience that can only be accomplished with the use of several infrastructure applications. This post will demonstrate how we set up our Kubernetes clusters with helmfile to deploy those infrastructure applications needed to support Pipeline and use cases within Adobe Experience Platform.
Setting up a Kubernetes cluster for success
Getting the Kubernetes cluster up and running with the control plane live and worker nodes ready to handle the load is only the first step in setting up our Kubernetes cluster for a successful deployment. We must also ensure that the system is ready to meet all the infrastructure-related requirements necessary to provide the resilience it needs to deploy applications at scale.
For example, we need the ability to monitor the applications we deploy, to have backups and auto-scaling in place, and to be able to search through the logs if something goes wrong. Fortunately, there are plenty of tools available to help meet these and other important infrastructure requirements. And, many of them an associated helm chart available, including:
- Prometheus with grafana for monitoring
- Fluent Bit for collecting logs from different sources, unifying and sending them to multiple destinations
- Velero for backing up Kubernetes cluster resources
- NGINX Ingress Controller for load balancing on the Kubernetes cluster
- Spinnaker for continuous integration and continuous delivery of applications
- External-DNS for syncing Kubernetes services with the DNS provider
- Cluster Autoscaler to automatically resize clusters based on the demands of the workloads we are running
All of these tools are important to ensuring the successful deployment of our applications. The question is, how do we deploy them in the Kubernetes cluster? And, if we need to spawn more Kubernetes clusters, how can we set the system up to install these infrastructure applications in a reliable, maintainable, and automated way?
We explored three different ways to accomplish this, including:
- Building an umbrella helm chart
- Using Terraform helm provider
- Using the helmfile command-line interface
We explored the use of an umbrella helm chart for installing our infrastructure applications but quickly found it to be too limiting for our needs. Using a single umbrella helm chart wouldn’t allow templating on the values we need to specify with each chart in order to configure the helmfile to accommodate the different cloud environments in which we deploy our applications.
We had been using Terraform helm provider to deploy our infrastructure applications in Kubernetes as a way to define the components we need to deploy on a different cloud provider such as AWS or Azure. For example, we might want to create a new server, conduct load balancing, or generate certificates for HTTP connections. However, we found that Terreform is very tightly coupled with whatever cloud service we were using for our applications which made changing the way we deploy our infrastructure applications across different cloud providers difficult. While most companies use a single cloud provider, Adobe Experience Platform has different use cases in which our applications might be deployed across either AWS and Azure. Given this, we needed a tool that would allow us to distinguish between these two cloud environments to deploy our applications on the fly within the same Kubernetes cluster without having to manually change the code to meet the different requirements of each. To meet this need, we began exploring the use of the helmfile command-line interface to deploy the infrastructure applications necessary to support our use cases.
Examples of our helmfile setup in Kubernetes
Helmfile allows us to deploy helm charts within Kubernetes. A helm chart is simply a collection of files that describe a related set of Kubernetes resources. We start with a basic helmfile structure, inspired by Cloud Posse’s GitHub repository, in which we have a main helmfile that contains a list of releases (helm charts) that we want to deploy.

Each release file in the list is basically a sub-helmfile. The code snippets below provide an example of what the file would look like for the load-balancing tool, the NGINX Ingress Controller.
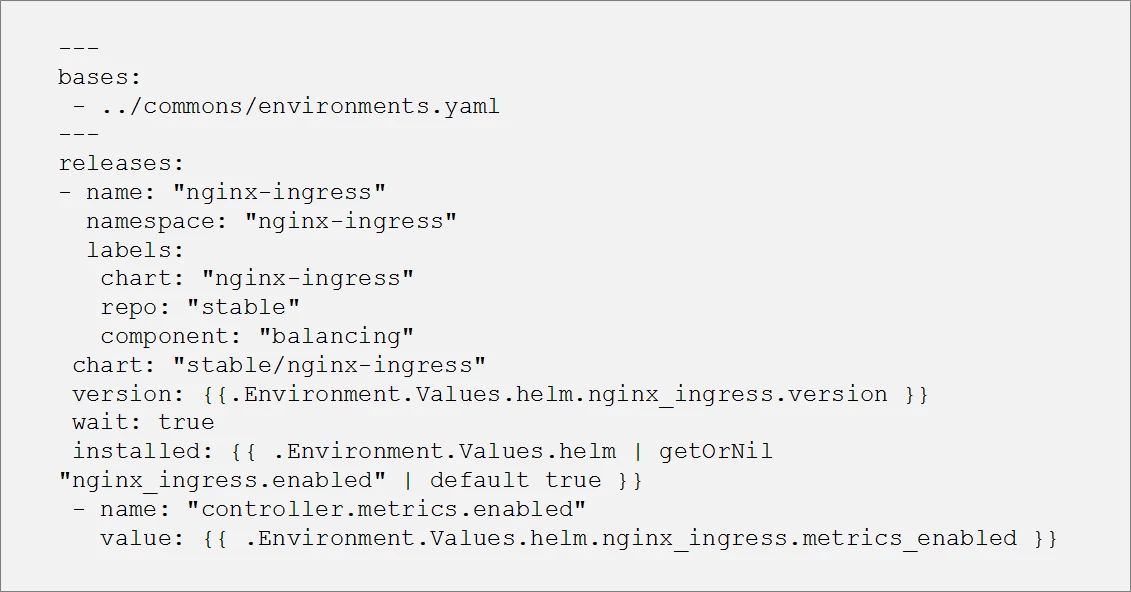
You can see in the example above that we are templatizing the helm deployment for the nginx-ingress chart. The actual values (eg. chart version, metrics enabled) are coming from an environment file:
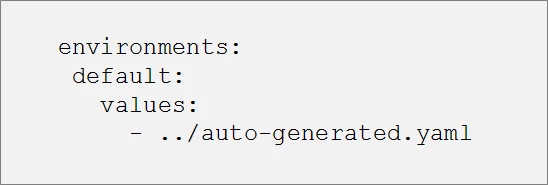
The commons/environments.yaml is the specification for deploying the load balancing tool within Kubernetes. Note that in the example above we are using a single environmental variable, named “default”. However, we could use any number of environmental variables depending on your use case (e.g. dev, stage, or prod) and switch between them. Each environmental variable would have its own set of values, allowing us to customize the deployment even further as we’ll see in the section below.
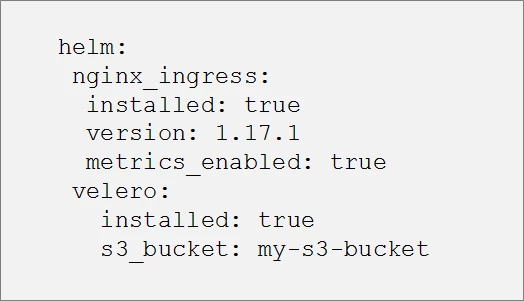
The ability to create a template is particularly useful when there are multiple charts that are common across different clusters. Templatizing the helm deployment avoids the need to duplicate the code in every cluster allowing us to instead encapsulate the code into a single file and apply it to the helmfile. The resulting auto-generated.yaml is a simple yaml file containing the following values:
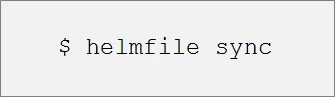
Once all the coding for load-balancing tool and the other infrastructure applications shown in the helmfile.yaml list are in place, we can start deploying the helm charts in our Kubernetes cluster with the following command:
In addition to deploying the infrastructure applications in the Kubernetes cluster, this setup offers an added bonus in that the charts are installed in the order provided in the main helmfile. This is very useful when we have a chart that depends on another one to be installed first (e.g. external-dns after kube2iam).
Unleashing the power of helmfile’s templatization capabilities
One of the most interesting helmfile features is the ability to use templatization for the helm chart values (a feature that helm lacks). Everything we see in the helmfile can be templatized. Let’s take the cluster-autoscaler for example. Suppose we want to deploy this chart in two Kubernetes clusters, one that is located in AWS and one in Azure. Because the cluster-autoscaler hooks to the cloud APIs, we will need to customize the chart values based on the specific cloud provider in which the cluster is located. For example, AWS requires an IAM role while Azure needs an azureClientId and azureClientSecret.
Below is an example we contributed to the GitHub helmfile-examples repository in which we templatize the helm deployment for the cluster-autoscaler chart:

Based on the environment we select to work in, the code above will generate AWS- or Azure-specific values as shown below:

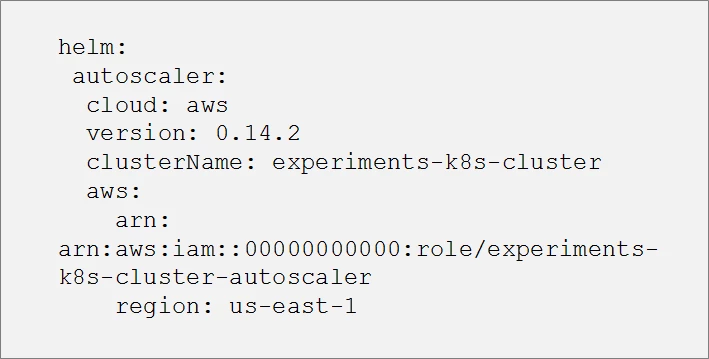
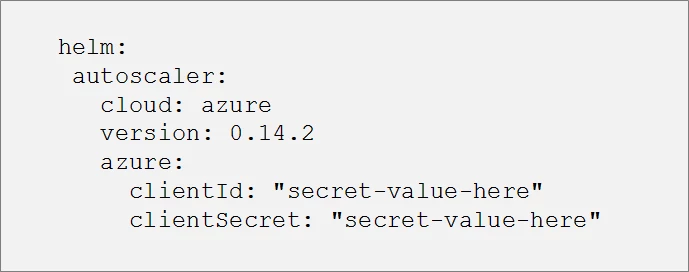
And now, to select the desired cloud provider we can run the following process:

Templatizing the entire values file
We can go even further and templatize the whole values file by using a .gotmpl file as shown in another example we contributed to the GitHub helmfile-examples repository:

The advantage here is in simplification. Some charts contain a lot of values that must be defined in the code. Helmfile can extract all of that information into a single file (a values file), which makes it easier to read the helm file.
We can also define a list of helm repositories from which we want to fetch the helm charts. The stable repository is an obvious choice, but we can also add our own private helm repositories. And, with helmfile’s support for injecting environment secrets to protect access credentials, we can use templatization in order to automatically provide the necessary credentials to run the application:

Building a more secure Kubernetes cluster by running helmfile in a tillerless mode
One of the challenges to using helmfile in Kubernetes is that doing so requires the Tiller daemon to be installed inside the Kubernetes cluster prior to doing any helm charts.
Helm consists of two main components, the helm client and the helm server (Tiller). The helm client allows developers to create new charts, manage chart repositories, and interact with the Tiller. The Tiller runs inside the cluster and interacts with helm client to translate chart definitions and configurations into Kubernetes API commands.
There are a number of security concerns in using Tiller, one of which is that Tiller performs no authentication by default. Using Tiller also adds a level of complexity in terms of setting up the required role and service accounts and the Tiller installation. Fortunately, we can avoid these problems by using the Helm v2 Tiller plugin (also known as Tillerless Helm), which allows us to set up helmfile to run in a tillerless mode. Enabling the plugin will run Tiller locally, making the helm installation more secure by eliminating the need to install the Tiller daemon inside the Kubernetes cluster.
When multiple people try to install charts using this tillerless approach, the helm state information is still being stored in Kubernetes, as secrets in the selected namespace:

The helm-tiller plugin offers a useful workaround for the security issues and extra complexity associated with using Tiller. When Helm v3.0 is released, Tiller will no longer be a part of the package. Instead, all the logic for applying the templatization will reside with the client, which will find the resources needed for the deployment and then make the call for those resources directly to the Kubernetes API.
With the call coming directly from the client, the API will be able to automatically authenticate the client to provide the resources needed. Instead of having access to the entire Kubernetes cluster, the client will have access only to a subset of the resources within the cluster.
While this solves some of the security issues associated with Tiller, it also introduces a new problem, which is templatization across multiple developers. For example, if two developers want to deploy their helm charts with different configurations to the same cluster at the same time, one of them will be delayed. Fortunately, the Kubernetes community has recognized this potential problem and is actively working on ways to resolve it.
If you haven’t already explored the use of helmfile within your Kubernetes cluster, we encourage you to do so. Helmfile has a strong community supporting it and offers templatization capabilities that can significantly extend its power when used with Kubernetes. In addition to the examples we have provided here, you can learn more about using helmfile with Kubernetes here.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Oct 17, 2019