

Cost Efficiency in Adobe Experience Platform Pipeline's Public Cloud Spend: An Iterative Optimization Framework
Authors: Jaemi Bremner (@Jaemi_Bremner), Yaksh Sharma, Sumit Kumar M, and Nipun Nair (@nipunn49017381).

This is a follow-up to our previous blog about public cloud cost management for Adobe Experience Platform Pipeline. The previous blog covered an overview of Adobe Experience Platform Pipeline, a breakdown of expenses, a plan of action, and the need for a cost governance program.
We recognize that both technology vendors and our enterprise customers (CIOs and IT organizations) have been faced with public cloud cost management. Building upon that, we focused on defining a cost optimization framework that establishes an iterable approach with sustainable long-term impact. In this blog, we will share our progress on how we reduced annual public cloud COGS spend by 40% without incurring any downtime.
Goals
We began by defining the following goals which would serve as our guiding principles as well, to the cost savings approach.
- Rightsizing our public cloud infrastructure: We wanted to ensure that our public cloud footprint is as lean as possible without sacrificing performance and functionality. We achieved this by minimizing overprovisioned infrastructure and increasing resource utilization.
- Changing a live distributed system without downtime: The focus here was to implement infrastructure and configuration changes with minimal impact to the clients using our production Kafka clusters. Our team ensured this by operating on a subset of Kafka brokers at a time iteratively.
Once we had established clear goals, our next step was to outline a cost optimization framework with a three-phased approach.
Approach
Phase 1: Understanding public cloud spend
The initial focus for Adobe Experience Platform Pipeline was on providing functionality and performance, with costs as an afterthought. Since it migrated from bare metal servers with long procurement cycles and 3 times the capacity needed for optimal utilization, the same philosophy of overprovisioning to buffer poorly defined traffic patterns was taken into the public cloud realm.
This led to production environments running at less than 10% utilization. It simply wasn’t designed to take advantage of the ease of scalability on the public cloud.
Another major contributing factor was excessive provisioning for anticipated use-cases. Pipeline was scaled up well in advance to handle traffic volumes that were 10 times in size as existing use-cases. There were multiple production-scale environments built-in AWS for such use cases with dozens of brokers and PBs of storage.
Application-level self-servicing was also enabled for client provisioning and administration of Kafka topics.
Phase 2: Identifying the biggest cost drivers
Having a clear understanding of the spend patterns led to identifying the biggest cost drivers, which of course were the massively overprovisioned sites for overly optimistic traffic projections resulting in underutilized Kafka clusters.
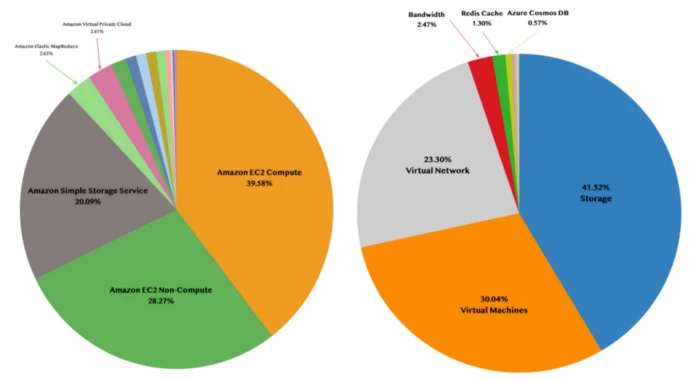
From a resource perspective, most of the spend was covered under:
- Storage
- Virtual Machines
- Virtual Network
- Other miscellanies
Phase 3: Defining a cost action plan
With the biggest cost drivers outlined, we enumerated a list of actionable tasks as our next steps:
- Reducing the spend for the biggest cost driver i.e. storage, virtual machines, and network.
- Revisit current and upcoming traffic patterns with product & engineering teams based on usage data.
- Increase resource utilization up to 70%, which is more suited for the public cloud.
- Build robust automation for scaling horizontally.
- Revisit and reduce data retention.
- Track cost variance using custom Tableau dashboards.
While executing on this cost optimization plan, we ran into certain challenges. Here is an overview of issues that we faced and how they were managed.
Challenges and Solutions
Identifying the correct resource type
The first challenge was to identify the correct resource types (Disks, VMs, and Container sizes). The solution for this came from within our Cost Governance Program. As part of a dedicated task force, an efficiency engineering toolkit was developed for AWS and AZURE sites. It analyzed utilization over time and recommended rightsizing for resources based on metrics like CPU utilization, server load, network load (Bytes IN/OUT), disk capacity, and I/O operations along with utilization spikes. In addition to right-sizing recommendations, we also purchased Reserved Instances to cover 90% of the usage and these were adjusted monthly based on changing requirements.
Changing a live system with minimal customer impact
The second challenge we encountered was to change a live system with minimal customer impact and dealing with any client issues while doing so. We handled this issue using the following approach:
- We migrated all the leader partitions for topics from a subset of brokers.
- We stopped the drained Kafka brokers to make recommended disk and VM configuration changes. As some legacy clients were sensitive to leader migrations, we had to educate them about handling such issues with Kafka’s inbuilt retry mechanism and tuning producer/consumer configurations like request timeouts and
linger.ms. - For critical use cases, we minimized the impact by moving leader replicas to a specific set of brokers where the configuration changes were already in place.
Changing infrastructure provisioning code in place for a live environment
The third challenge we had was changing infrastructure provisioning code in place for a live environment and to keep it in sync for ad-hoc changes. Terraform was used to provision both AWS and AZURE infrastructure. To overcome the problem, we added new Terraform modules for managing disk attachments and used them to add extra disks; and then cleaned up the old disks and attachment code after the changes were complete. It was only feasible for smaller Kafka clusters as it led to the next problem.
In the end, we had to deal with cost spikes while making changes to large clusters. With our flat infrastructure provisioning code, the changes like new disk attachments were applied to the whole cluster at once. This caused a spike in our daily run-rate as we could only safely work on a small subset of brokers in parallel. We resolved this problem by using custom Python/Bash scripts to do ad-hoc changes to 3 brokers at a time and removing old disks before working on the next set of brokers. This helped stabilize our daily spend run-rate in a downward trend. Further, ad-hoc changes were imported into Terraform to keep it in sync.
Application enhancements for further cost reduction
Having dealt with the challenges while implementing the infrastructure changes, Pipeline’s engineering team continued to look into other avenues like application design to further reduce our public cloud cost footprint.
The team revisited application design and architecture to be cost-effective by optimizing certain aspects from a few years ago like the removal of unused shadow topics used for replication. This helped optimize our broker usage by bringing down CPU utilization of VMs as each Kafka broker now needed to handle a smaller number of partitions. We also standardized application deployments on Kubernetes and rightsized these deployments to increase container utilization.
The Pipeline team also addressed a major network expense incurred during repeated consumption of the same data, by creating a virtual view to optimize network bandwidth. More in a later blog!
Results
The Pipeline team was able to bring down its public cloud cost footprint by 40% while growing 30% YoY, focusing not only on established fundamentals of operational optimizations but taking it a step further by revisiting its application needs.

Key Takeaways

- Start small: Don’t overprovision for use-cases that are not live. In a cloud-first world, scaling up on demand is much faster and significantly more cost-efficient than running resources idle.
- Be cost aware: Design and architect applications with cost first mentality. One size doesn’t fit all, so right size deployments based on actual usage data and have a continual way of tracking costs so that any discrepancies could be caught swiftly.
- Set relevant goals: Reduce complexity to see the bigger picture and focus on the long-term impact of the goals rather than setting a one-time goal to reduce spend.
- Invest in automation: Make sure infrastructure provisioning code is granular and deployments are horizontally scalable. 2-way autoscaling can help deal with irregular traffic patterns in the most cost-efficient way.
- Think outside the box: Sometimes obvious is not the right choice, you might have to increase costs in the short term to decrease them in the long run.
- Learn and share experiences: We ended up creating a culture of cost optimization during our journey, and continue to spread the word within Adobe and externally through blogs like this. If you found this useful, pay it forward by sharing your experiences!
Future goals for Adobe Experience Platform Pipeline
We plan to continually improve processes with a cost-first mentality, starting with onboarding every use case in alignment with cost efficiency practices via Pipeline’s self-service portal.
We will also be reducing the default data retention to one day, and three days with exceptions. Another major undertaking is to make clients cost-aware by providing them access to topic-level costs. We are massively invested in automation and infrastructure code optimizations while completely migrating to container-based deployments in Kubernetes for all the Pipeline services including Kafka.
Finally, we are working towards having robust 2-way autoscaling based on custom usage metrics with right-sized Kubernetes environments for automated cost-effectiveness.
As highlighted in the previous blog post, the fundamental seismic shift for cost management is happening now with the successful establishment of our Cost Governance Program.
We anticipate continued success for this program as teams are embracing the culture of cost first, across the board in Adobe.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetup.
Previous blogs about Adobe Experience Platform Pipeline
- Adobe Experience Platform Pipeline Cost Management: A Case Study, 4/30/2020
- Rate Limiting in Pipeline: High Quality of Service at Millions of Requests/Second, 2/27/2020
- Adopting Modern CI/CD Practices for Adobe Experience Platform Pipeline, 11/4/2019
- How Adobe Experience Platform Pipeline Became the Cornerstone of In-Flight Processing for Adobe, 9/26/2019
- Creating the Adobe Experience Platform Pipeline with Kafka, 10/22/2018
References
- Adobe Experience Platform
- Azure CLI: Tutorial — Manage Azure disks with the Azure CLI — Azure Virtual Machines
- AWS CLI: ec2 — AWS CLI 2.1.27 Command Reference
Originally published: Apr 22, 2021