
Rate Limiting in Pipeline: High Quality of Service at Millions of Requests/Second
Authors: Sazzad Hossain, Nipun Nair, and Doug Paton

In this blog, we explain how Adobe's Pipeline service solved a noisy neighbor problem on its HTTP API to protect Adobe Experience Platform from inadvertent or malicious overuse. We explore the options we had and take a deep technical look at the solution we decide to implement.
Adobe Experience Platform Pipeline service currently handles one hundred billion messages daily, in near real-time, across Adobe's Experience Cloud workflows (which includes products like Audience Manager, Adobe Analytics, Adobe Campaign, Adobe Target). We introduced Pipeline in a prior blog. By means of a quick recap, Pipeline is a high throughput API layer that provides the streaming foundation for the rest of the Platform services, akin to a silent superhero.
But as an old saying goes "with great power comes great responsibility". The Pipeline API service needs to guarantee that a single rogue client cannot exhaust its capacity thereby impairing the SLAs for other clients. Maintaining fair share among thousands of integrations while protecting the Pipeline streaming service from (unintentional) denial of service is, therefore, a top priority.
A real example of scaling challenge
The AEP Pipeline service handles over 100 Billion transactions a day across many solutions. There are instances triggered by social events like the Super Bowl where our system experience very heavy spike in usage from select clients. One such incident of a spike resulted in a client creating 10x more requests into Pipeline than usual, which resulted in cascading slowdowns across the systems. That incident prompted us to rethink our API design by introducing a rate-limiting feature that is fair to all our tenants.
Limitations to consider before jumping to a solution
Although as much as want to introduce a limiting solution, we have some restrictions that are not easy to deal with.
- Our API calls has a very high throughput meaning a single user can make 10K requests/sec to the Pipeline service
- Rate limit has to work across the whole cluster not just on a single node in a cluster
- Applying the limit should not add latency to processing of API calls as we have a strict SLA to maintain on the API calls which is in lower sub-second range. It means that we can't impact the API calls to check the limit
- Rate limit has to be applied in multi-type deployments. Pipeline service is deployed in disparate environments like bare metals, AWS, Azure, K8s, etc. where the load balancer is not unique so that we could apply the limit at the load balancer level
- The limit can be applied based on multiple conditions which are not always possible on a load balancer. For example, applying a limit based on the combination of who is using the API, what it is the target of API calls, etc.
- The limit can potentially be applied across multi-cluster to track single user activity. This can't be done on a single load balancer as there are dedicated load balancer per cluster
To accommodate all the requirements, we could not find a ready-made solution that fits our needs. So, we opted for a system design where the rate limit component will run on each node on a cluster but will gather the data from all the other nodes in a cluster or across clusters to make a cluster-wide or multi-cluster wide decision. To coordinate the data from all the nodes across clusters, we have chosen Redis as our storage to store time interval data.
How our solution to the problem evolved
Balancing Latency vs Accuracy – a system design dilemma
While designing the rate limit architecture, we had to compromise on what we wanted to achieve. We want accuracy without impacting latency which is virtually impossible which is like in the computer architecture "When multiple threads are adding values to a counter, give me a perfect result of the add without synchronizing" which is impossible to do. We have a similar situation where we want to get an absolute count of all the requests across the nodes in a cluster in real-time without blocking the incoming requests. So, our goal is not to attain an accurate count across a cluster, rather achieve no impact in latency with an acceptable margin of error of accuracy of around 20-30%. It means our rate limit result can be off by that margin which is acceptable for us given we don't add any latency to the APIs.
Solve the simpler problem first
We wanted to look at the problem from a simpler perspective. First we decided how we can apply a limit on a single node and the solution seemed very easy. There are many popular algorithms like sliding windows, token buckets, etc which can give you accurate counts at any moment of time. We also have to look at how rate-limit data will be stored and updated easily. Given all the consideration, we decided to use a sliding window algorithm where we store time window like 1 second for each client is represented as a Redis key.
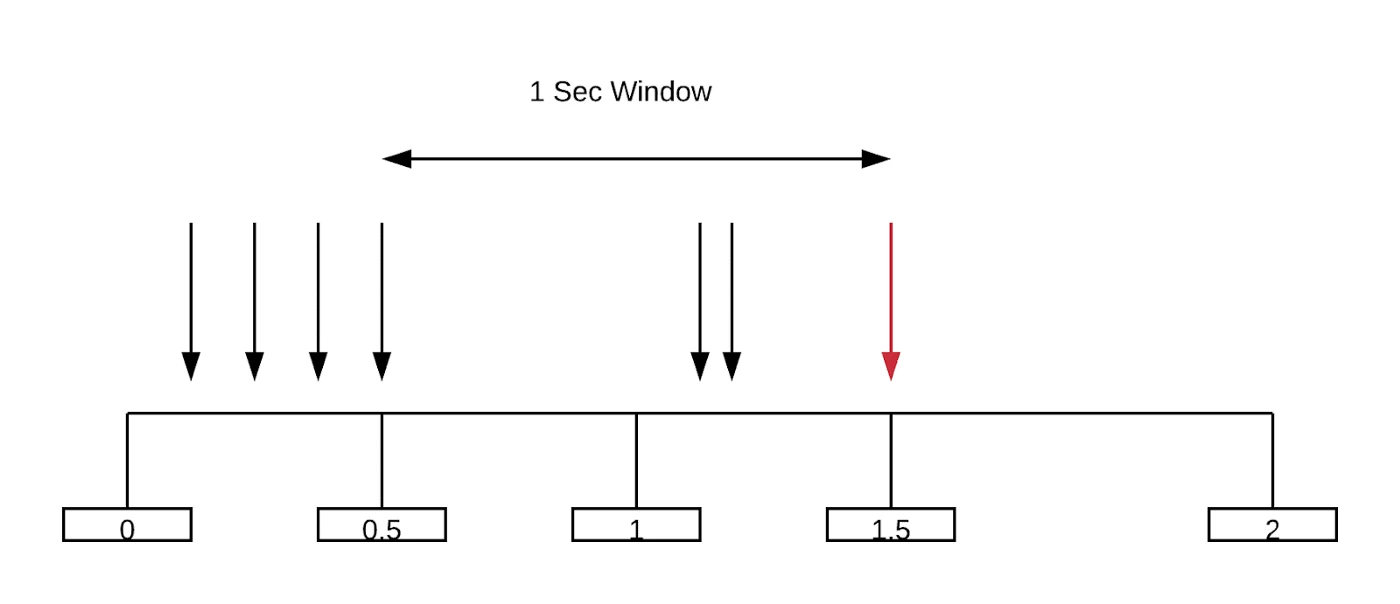
To explain a scenario, let's imagine you have a request that's coming at 1.5th second. You already had stored the number of requests from 0 to 1 second as 4 and you already counted the value from 1 to 1.5th as 2 second which is stored in the key of 1 to 2. The way the count for the time window between 0.5 seconds to 1.5 seconds is calculated for a request at 1.5th second is like below
Current Count at 1.5th sec = 1 + Values of 1 sec Window
= 1 + Values of 1 to 1.5th sec + Average values of 0.5 second
= 1 + (Values of 1 to 1.5th sec) + ( Values of 0 to 1 second * (1-0.5)/(1-0)
= 1 + 2 + 4*0.5
= 5
Solve the bigger problem next
In reality, tracking a client and its target on a single node does not solve our problem. Our case warrants that we need to look at the whole cluster and sometimes across the cluster. We found that if we can still use a single node solution but expand it to multiple clusters then our problem is resolved. It means that we need to calculate the values of a 1-second window across the cluster and each node should be able to calculate that locally. To do that, we came up with an architecture like the below
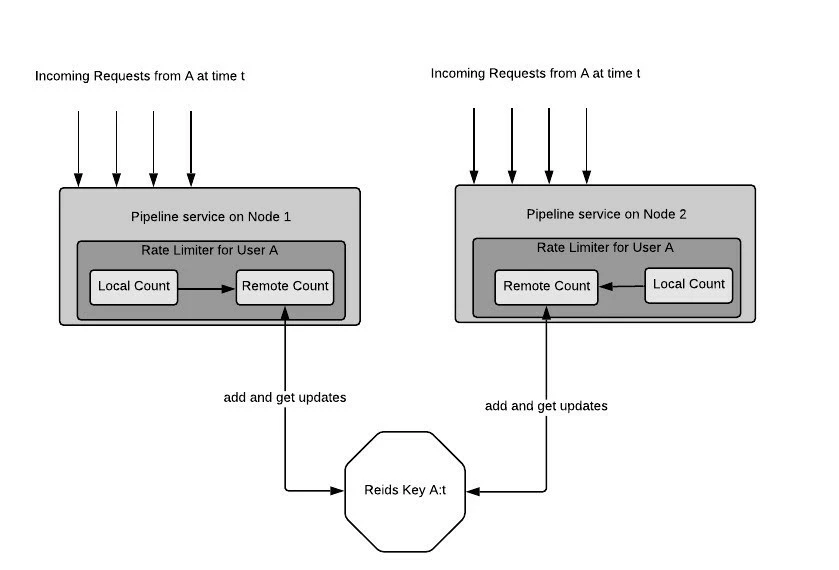
There are some properties of the architecture in Figure 2
- The calculation happens locally on each node of Platform Pipeline service. There is no central node that does the calculation. It means the algorithm is resistant to any node failure
- There is one entry per time window per client as a Redis Key
- The architecture allows one module (Local Count in Figure 2) to track all the requests coming to that particular node
- A sub-module (Remote Count in Figure 2) frequently(e.g 5 times in 1sec) takes a snapshot of Local Count. The way Remote count does this is as follows
- Get the latest value of Local Count and set it on Remote Count
- Set the Local Count to 0
- Remote Count appends the value that it retrieved at 4.a to the remote Redis key and gets the updated value for that key
The more frequent this step is the greater the accuracy will be:
- The architecture accounts for a node joining and leaving in the cluster which means at any moment of time, it accounts for all the nodes in calculating the current count
- The architecture does not block every incoming request except for step 4.
Criterias to set limit
It's not that we can set limits just based on the client identities. The way the limiter configuration module is developed is that it can look at the different conditions being met to decide whether to allow a request or not. So, for example, we can say that "a customer which is using a certain topic" needs to be limited. Our limiter can track the customer and also the topic that it is using to pump the data into. The time window is also customizable to second, minute and even a day.
Outcome of applying the limiting solution
After going through the phases of developing our in house solution, we ultimately deployed the feature in limited sites to measure our goal. Ultimately, we had 2 essentials goals in mind
- Customer should not realize any latency impact
- Our accuracy has to meet certain thresholds
Accuracy
A client is configured to allow 2000 requests/sec per cluster and the cluster where we enabled the rate-limiting has 35 nodes. We found that when the rate limit is enabled, each node was allowing around 70 requests/sec totalling ~2400 requests/sec for that cluster. This results in a 20% more request that we intended for. But this is within our acceptable margin of error and the accuracy could be improved by increasing the syncing of the remote module more frequently described in the architecture.

Latency impact
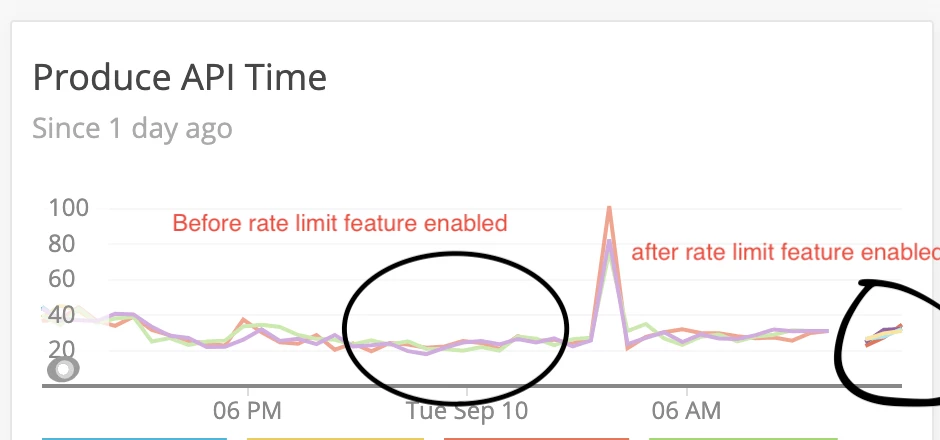
Virtually no latency impact was realized in the API calls after enabling this feature on the cluster. From the image below we can see we enabled the feature around Sept 10th,2019 at 8 am where you can see a gap of data. The latency before the feature was enabled and afterward is still around 40 ms. The spike that you see is our occasional spike which is due to heavier load and which is what we actually want to prevent through the rate limit.
Although we achieved what we wanted, we found that the limiter still suffers from millisecond-level bursts which lowers the accuracy. We have a couple of ways that are yet to be explored
- Increase the syncing frequency by the Remote Count module with Redis when the limit configured is nearing. E.g if you have set a limit of 100, then sync 2 times in a second when the client is at requests 80 and increase the frequency to 4 times toward the end. With this, if a customer is doing burst, then he will suffer latency at the end but the limit will be more accurate
- Punish the next time slot, if the previous time slot is crossed, lower the limit in the next slot. So, if a client made 120 requests when it is allowed to make 100, then in the next cycle reduce the allowance to 80. That way the limit will be averaged out over time.
The next step for API Rate Limiting on Adobe Experience Platform
Our main goal for this project was to protect the Pipeline service from being overloaded by noisy neighbors, offer a fair share among different solutions who uses our service and last but not the least provide better system stability. The next steps for us will be to reduce the impact of bursts on the algorithm and further improve the experience for our users.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Feb 27, 2020