
Adobe Experience Platform Pipeline Cost Management: A Case Study
Authors: Daniel Marcus and Douglas Paton

In this post, we discuss how we analyzed the cost of operating Adobe Experience Platform Pipeline to reduce unnecessary costs. We break down our process for identifying areas where we were overspending. And we look at how we automated the process to help streamline cost governance for Adobe Experience Platform.
It wasn’t that long ago that Adobe Experience Platform Pipeline was a modest Kafka implementation that served as a message bus for the marketing cloud.
In 2014, that was the case. Pipeline was transmitting about 500 million messages a day and was deployed in five data centers — two in the United States, two in Asia Pacific (APAC), and one in Europe, Middle East, and Africa (EMEA).
Six years later, Pipeline is a different beast. It’s still a great low latency message bus, but it’s much more than that. It provides capabilities for developers to do the streaming computation, to analyze, aggregate, transform, and enrich data on the fly. It is truly a “One Adobe” service, spanning multiple Adobe clouds. We now process up to 100 billion messages a day, across 13 data centers.

Growth between 2018 and 2019 alone was 500%, which was exciting. But this kind of growth was not without its downsides. One of the biggest challenges we found ourselves facing was the overspending that came with this high level of growth.
Even when we look at factors like organic growth and data center build-outs, which lead to a natural increase in operating expenses, we were still spending too much.
Breaking down expenses
The first thing that we needed to do was take a look at where our money was being spent. When we look at expenses by region, we found that most of the money was being spent in the US, with about 10% each in both the APAC region and in EMEA. As you’ll see, this would help us guide our cost-cutting measures after we figured out the next piece of the puzzle: what were we spending the money on?
We found that our spend on cloud infrastructure was dominated by Azure (Figure 1). When we broke it down even further we found there were four main categories where our spending was the highest (Figure 2). These were storage (57%), compute (18%), transit/networking (22%), and third party products and other miscellanies (3%).
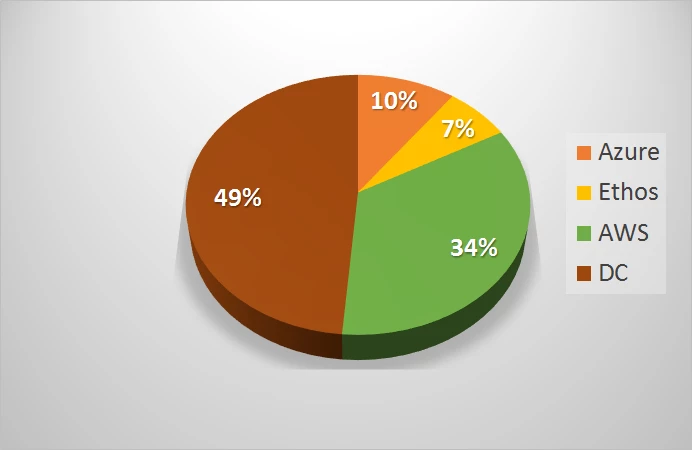
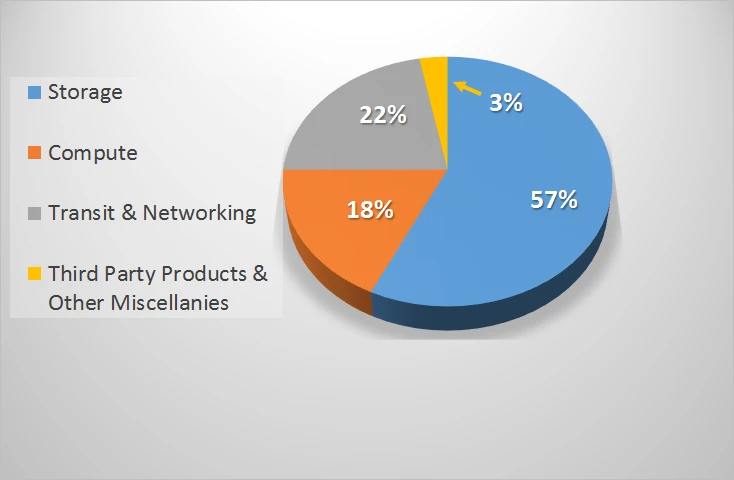
This painted a very clear picture of not only where our money was being spent, but also where we were most likely going to find places to trim spending.
Coming up with a plan of action
Once we knew the breakdown of how we were spending our money, we needed to come up with a plan for reducing that spend. Our brains were the most important tools we had during this phase — domain knowledge and common sense. We knew the architectural soft spots, moments that we planned for that didn’t play out the way we expected (planning for traffic that never showed up, for instance).
Here’s the approach we took:
- Observation and analysis — We took a close look at our KPIs and resources boundaries. For example, if I’m CPU bound and I have storage optimized VMs, there may be opportunities there.
- Tools — Azure and AWS both have tools to help spot unnecessary spend. They have their limitations but can give you a reasonable zeroth-order cut at spend reduction opportunities.
- Custom tools — Adobe has built a toolkit for AWS that identifies storage, VM, and database rightsizing opportunities. And it also automates remediation. It has been used successfully with Adobe Campaign and we have used it to great effect in the Pipeline AWS footprint. We are currently adapting it to Azure.
When we did this, we were able to identify things like VM rightsizing, cluster downsizing, abandoned block storage, abandoned snapshots, overprovisioned storage, and Azure storage class.
A practical look at our plan in action
Now that we know how to approach this, let’s take a look at what happened when we applied to the category we were spending most of our money on, storage, specifically with disk provisioning.
Way back when we used to have a long procurement cycle when it came to building out our bare metal servers. It would take 90 days to get new servers in place. This led to a habit of overprovisioning by 50% whenever we ordered new servers. Since we couldn’t predict these spikes accurately, we overprovisioned to buffer poorly defined traffic ramps.
Out of habit, we continued doing this as we moved our services to the cloud, even though that long procurement cycle no longer existed. Even though we could easily scale up and down with our expected traffic spikes, we didn’t. We kept pushing through with the bare metal mindset.
When we realized that, we looked at where we could remove servers that we weren’t using. We were able to scale down AWS in the Eastern US (a good spot to cut costs, since the US made up 57% of our spend) and in EMEA. We are still in the early stages of this, but we’ve seen solid reductions in costs as a result of these efforts.
Building a cost governance program
The result of all of this was a cost governance program that can help us reduce costs across the board. Let’s take a step back and talk about what a cost governance program looks like. It breaks down into four main categories starting with cost reduction — rightsizing, deleting, downsizing, as examples.
To make this as easy as possible, you need a solid management process. This means automating many of the manual brute force processes you invoked to reduce costs. This is where the custom tools we talked about above come into play. They help identify those areas where it’s possible to reduce spending.
You need to ensure you’ve got a robust reporting program in place that can be easily accessed through a dashboard and allows for auditing and show back. Being able to visualize where the money goes helps curb spending.
And finally modeling. You need to build a robust predictive capability that will allow you to create reliable forecasts based on input primitives like RPS, and scenario game different configurations, third party cost models, and VM types.
Once you get cost reduction under control, your emphasis shifts to the remaining three areas.
A closer look at show back
We found there was a lot of interest in show back, both from our customers and for our own purposes of transparency. Here are the elements of a show back capability. We would like to be able to answer the following questions:
- What is a client’s weekly/monthly/annual spend on Pipeline?
- How is the trend changing over time?
- What does the detailed breakdown of costs look for that client across their topics?
- How are costs attributed across storage, network, and compute?
Here’s an example of what that could look like. In the pivot to continuous cost management, elasticity will be essential Instead of provisioning to anticipated traffic, build to a baseline and be able to scale up and down at will. If for whatever reason, you can’t autoscale based on KPIs, perhaps state management or other reasons, then be sure that you have automated deployments so that you can scale your infrastructure footprint up or down at will.
What we’ve learned from all this, so far
So far the pipeline team has taken down a lot of low hanging fruit (Figure 3). As targets become more scarce, we will have to pivot from reduction efforts to management and automation, which requires a significant engineering effort.
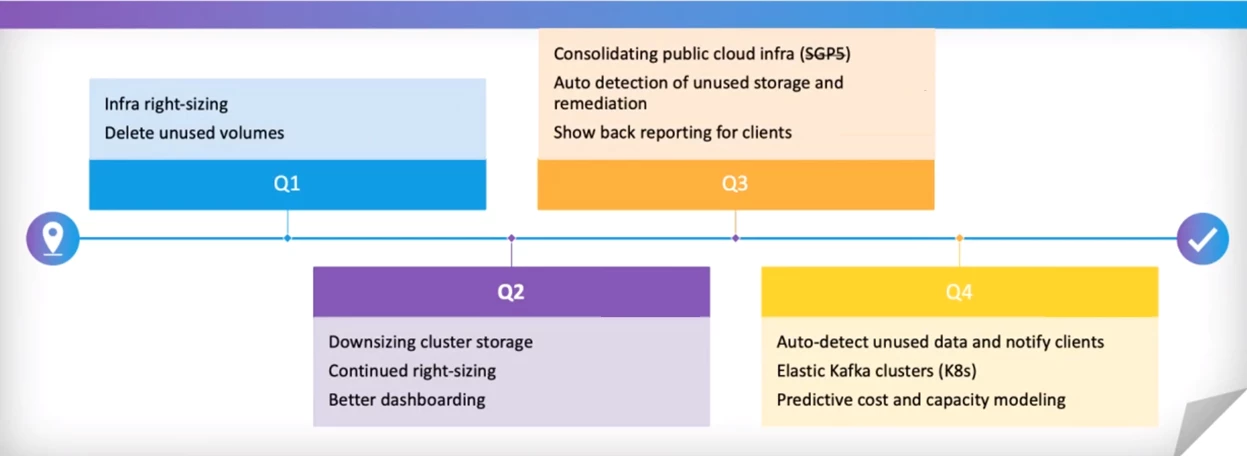
Doing cost governance so it sticks requires a cultural change. We live in a world of nearly unlimited computing resources. We need to better manage that bounty. This means thinking differently about design, architecture, and provisioning.
We need to prioritize elasticity. We need cost considerations to be a major factor in project planning and gating — a prerequisite, not an afterthought. Adobe Experience Platform in general and Pipeline, in particular, are no strangers to embracing major cultural upheavals.
A year and a half ago we embraced DevOps. It was not easy, but the benefits to us as a delivery organization have been tremendous.
We need the same kind of fundamental seismic shift in perspective to manage our costs on an ongoing basis.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Resources
- Adobe Experience Platform — https://www.adobe.com/experience-platform.html
- Kafka — https://kafka.apache.org/
- Azure — https://azure.microsoft.com/en-ca/
- AWS — https://aws.amazon.com/
Originally published: Apr 30, 2020