
Digging into Adobe Experience Platform’s Experience Data Model to More Fully Understand the Power of Real-time Customer Profile
Authors: Eric Knee, Klaasjan Tukker, and Jody Arthur

To truly understand how Adobe Experience Platform’s Real-time Customer Profile helps enterprises develop an accurate 360-degree view of their customers, one must first understand Adobe Experience Platform’s Experience Data Model (XDM). This post will provide insights into XDM and its relationship to Real-time Customer Profile to help you more intuitively use Adobe Experience Platform to deliver personalized customer experiences in real-time.
Delivering good customer experiences depends on having a full and accurate profile of your customer. Adobe Experience Platform makes that possible. However, the first step in building a profile is understanding the data you have to work with. Data comes from a myriad of sources and in many different formats making it a challenge for enterprises to use it to their full advantage when developing their profiles.
Adobe Experience Platform eliminates this problem with its Experience Data Model (XDM), which helps enterprises leverage data from many different sources to create continually enriched profiles for use in delivering better and more personalized customer experiences.
In order to understand how profiles work in Adobe Experience Platform, it is important to first develop an understanding of XDM. You can think of XDM in two different ways. There is XDM as a system and XDM, the model (Figure 1).

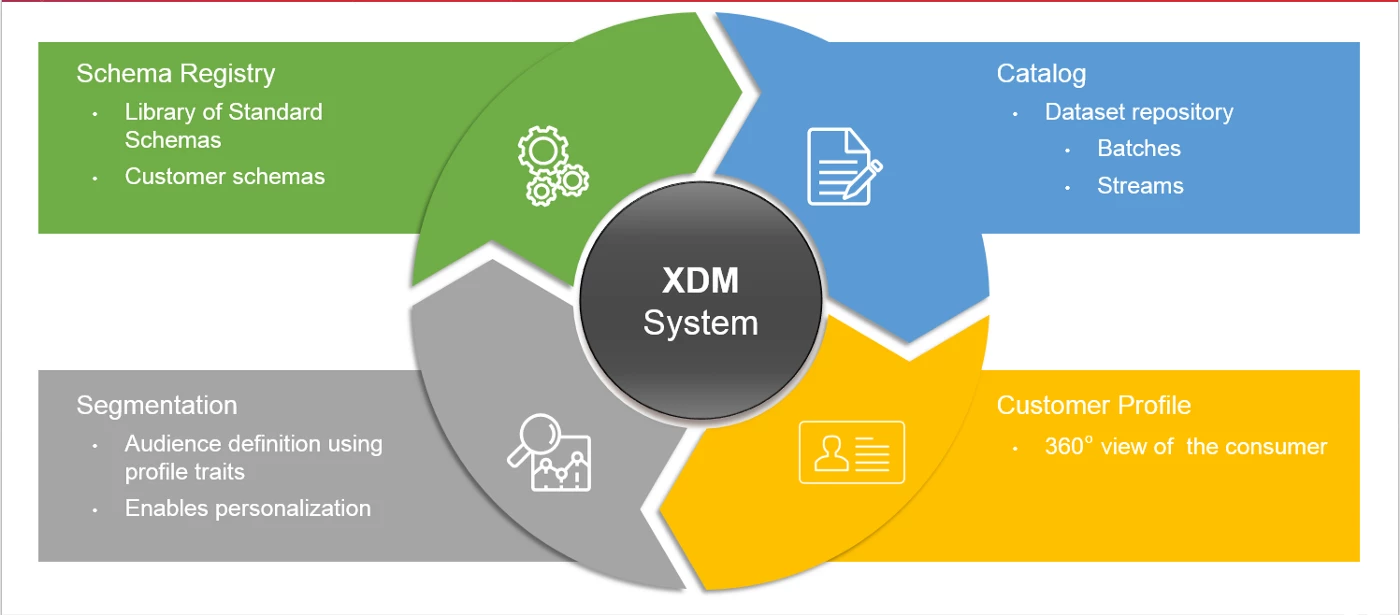
XDM as a system drives and supports all of the components that make XDM work (Figure 2). The schema registry provides a library of standardized schemas and allows for customers to include their own. The catalog is where the data is stored whether you are bringing it in as streaming data or as a batch. The system also supports segmentation on top of the data to define audiences and enable personalization and, ultimately, the development of customer profiles.
XDM as a model allows us to standardize different data sets, bringing meaning to previously undefined data and allowing it to flow freely across Adobe Experience Cloud Solutions and external systems. This makes the data from many different sources reusable and extensible for use across various marketing channels as well as for data science and machine learning.
The four types of building blocks that support XDM
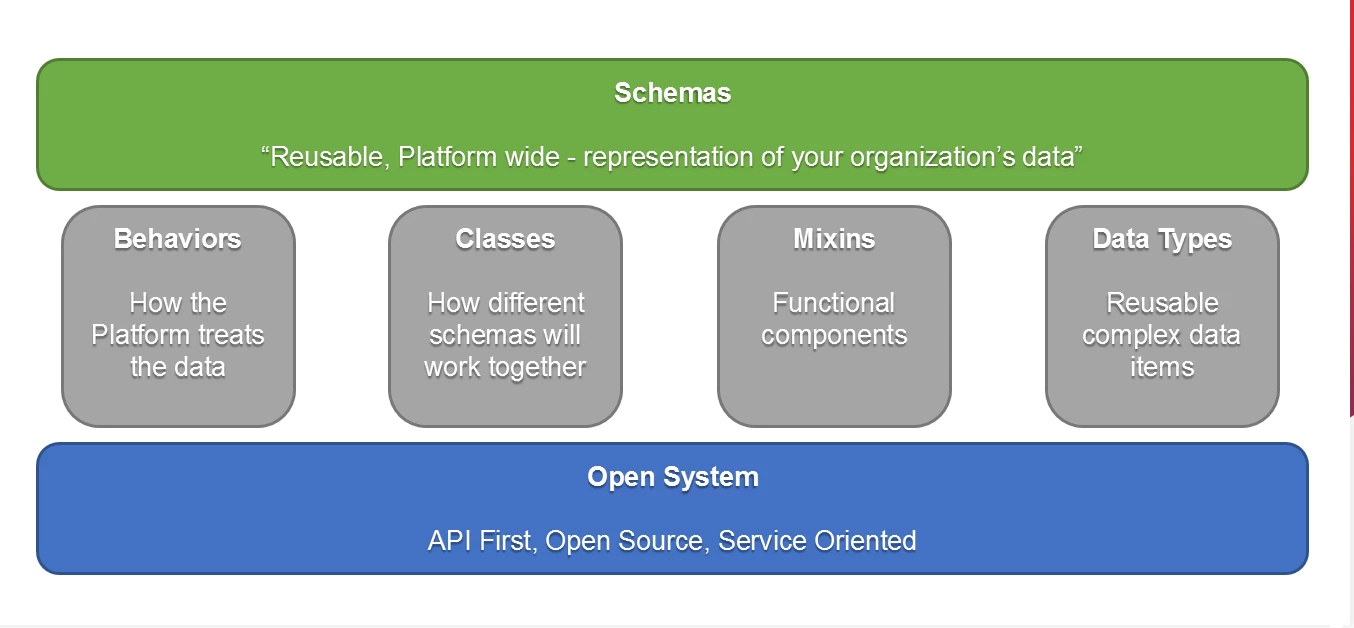
XDM provides a common language for the experience businesses today. XDM as a system provides the infrastructure, data semantics, and workflow in Adobe Experience Platform, all powered by standard schemas. The easiest way to understand the role XDM plays within the platform is to view it as a set of schemas with reusable components, which are layers of the four different types of building blocks that support XDM (Figure 3):
- Behavior — How the platform treats your data.
- Classes — The different ways that schemas interact with each other when they are brought into profile.
- Mixins — Prepackaged, reusable components that help accelerate schema design.
- Data Types — Reusable components on a very granular level.
Every schema is built from these four components, which are built on top of an API-first, open-source repository to provide public access.
Datasets vs. Schemas
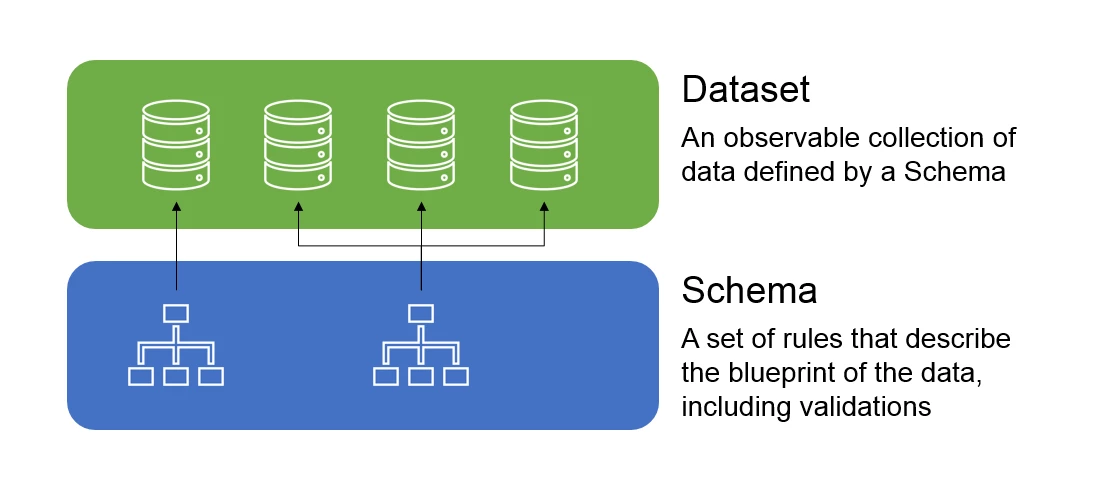
Within Adobe Experience Platform, we use two different but related concepts when we talk about data (Figure 4). One is the dataset itself, which is an observable collection of data that you are bringing into the system. And, the second is the schema. Every dataset is defined by a schema. The schema sets the rules and describes the data, its structure, and the validation that has to happen when it is used. A schema can be reused across many datasets while a single dataset can have only one schema.
Fundamentals of Building in XDM
The following sections will tell you what you need to know to be successful in designing schemas for use in Adobe Experience Platform’s Real-Time Customer Profile Service. The goal here is to help you understand how your schemas will work in Profile before you invest your time in building them only to find they do not work as expected.
Schema Composition
Schema composition is based on a behavior. Recall from Figure 3 that behaviors describe how Adobe Experience Platform treats the data for the purposes of schema composition. When you are composing a schema for your dataset, you will describe it as either a record-based schema or a time-based schema based on the nature of the data.
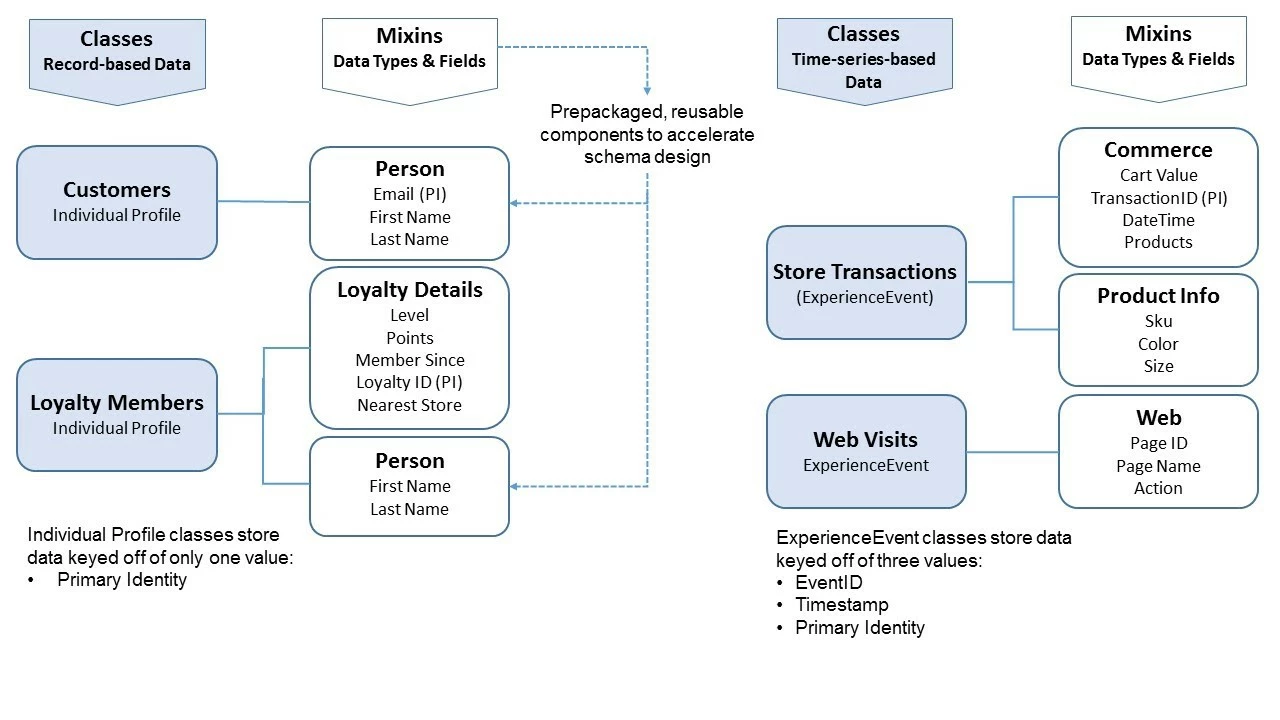
Classes describe how the different schemas will work together. Like the behavior you choose for your schema, the class you choose will be based on the nature of your data. While there are many classes available to you within Adobe Experience Platform, there are only two that are of interest to us in building profiles. These are Individual Profile, which applies to record-based data and ExperienceEvent, which applies to time-based data (Figure 5). These two classes allow Real-Time Customer Profile Service to build a one-to-many relationship between different schemas.
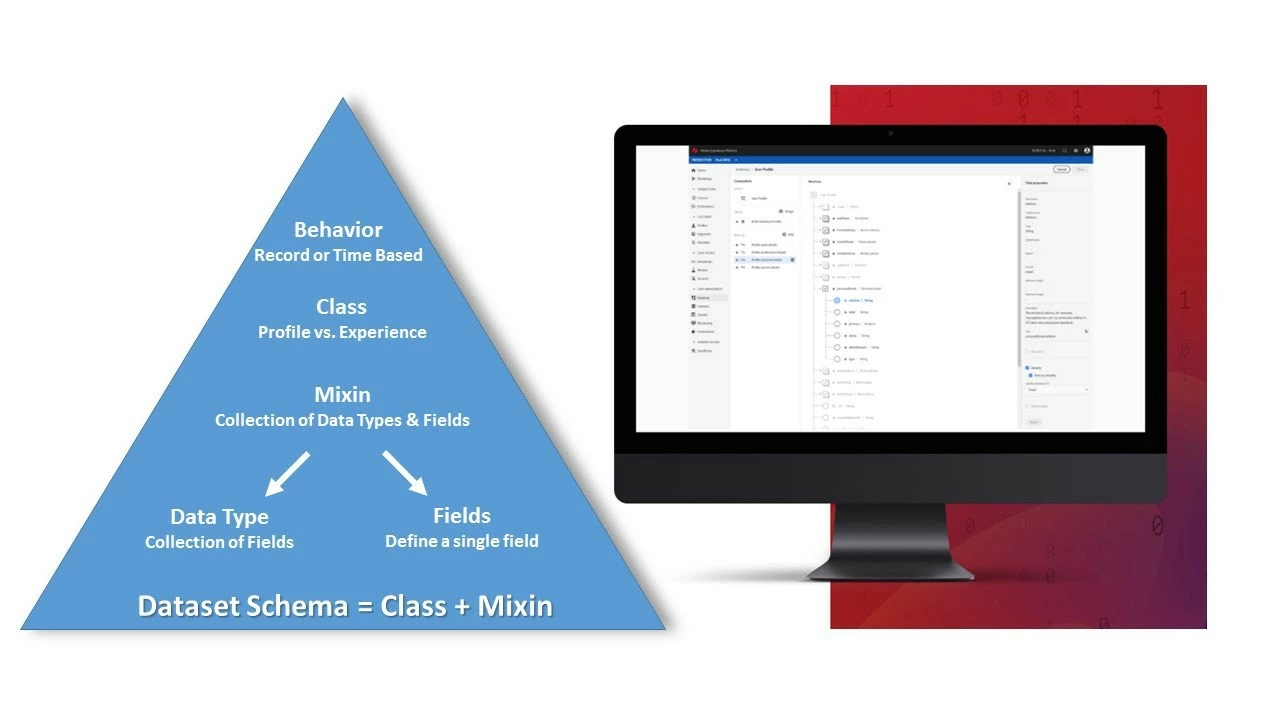
Every schema has to also be composed with at least one Mixin, which contains a collection of view data types and fields. Mixins are reusable components provided in the XDM system to help you define the data types and fields that you want in your schema and to then package them in a way that makes sense for your use as a platform customer. Adobe Experience Platform provides a number of prepackaged schemas. However, you can also build your own reusable Mixins based on your unique data set and schema building needs (Figure 6).
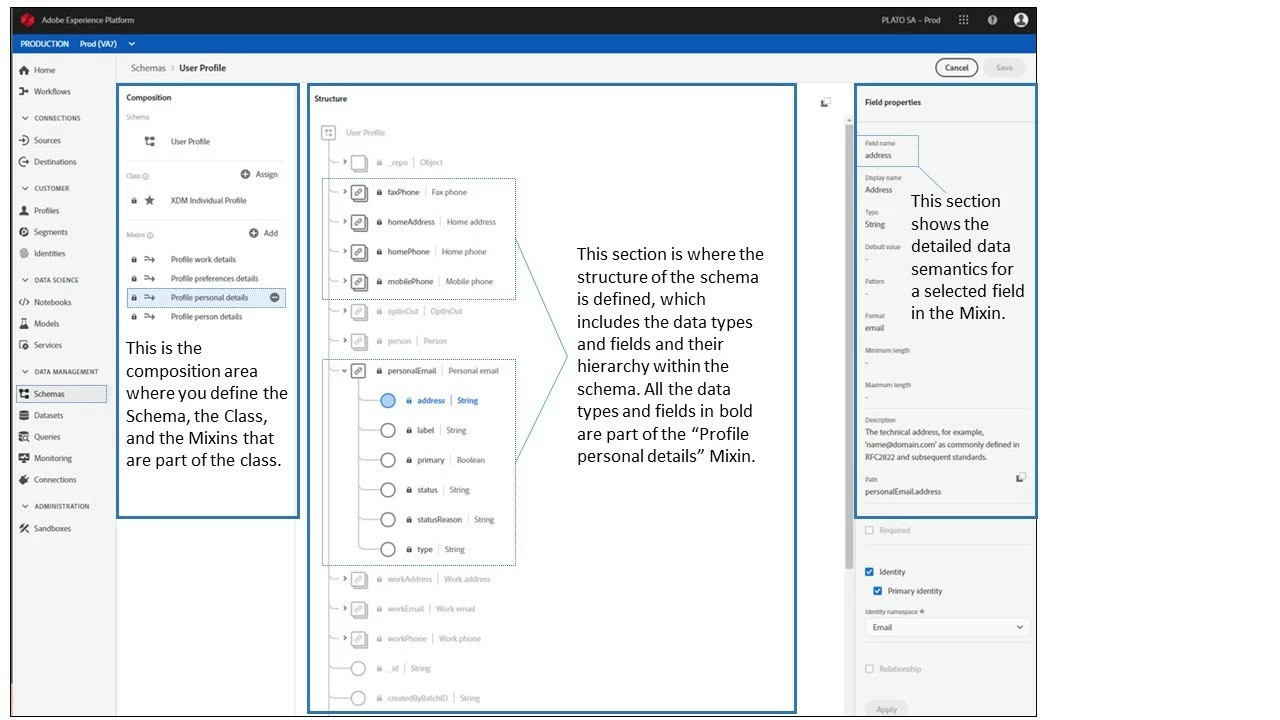
Composing schema in XDM is similar to working in a typical relational database management system (RDBMS). For example, if you know how to design in SQL or Oracle, you will find XDM to be fairly similar but with these new things called Mixins and Data Types (reusable components), which are not part of a typical RDBMS (Figure 7).
Unions are read-only schemas that aggregate the fields of different schemas of the same class for use in Real-Time Customer Profile Service (Figure 8). Schema unions are class-specific, meaning they function differently depending on the nature of the data, which is how classes are defined.
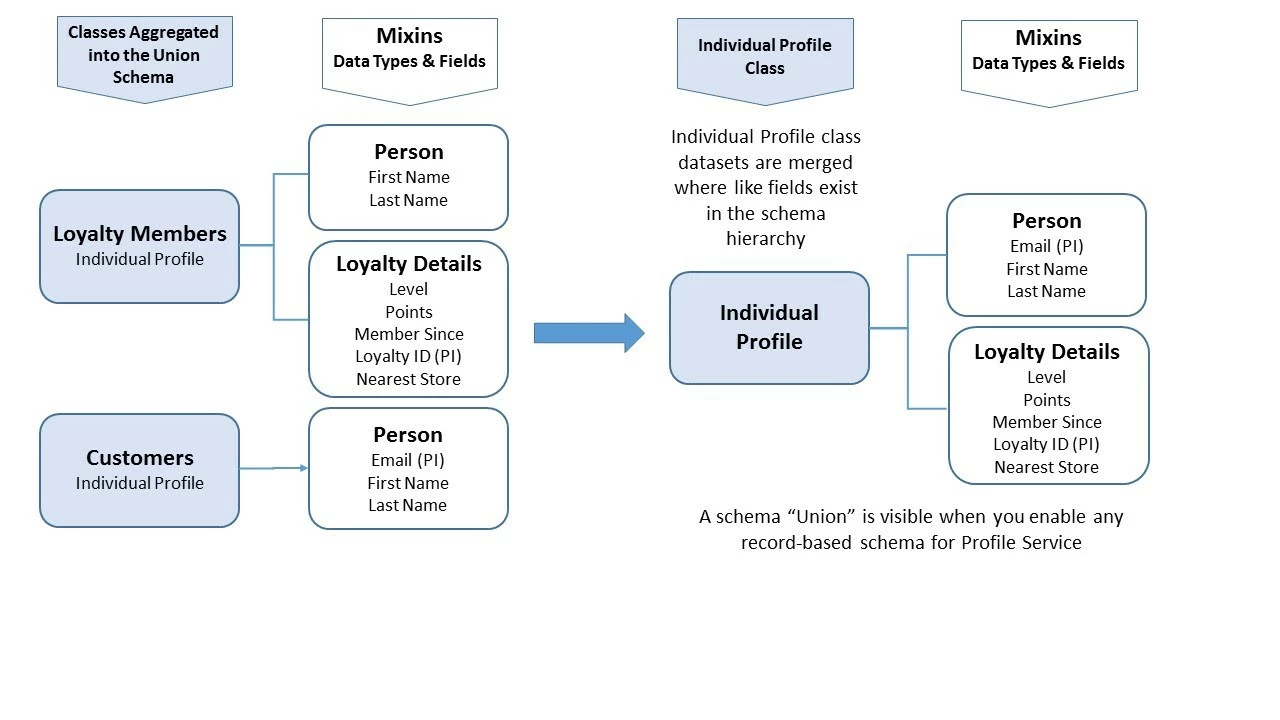
On an individual profile (record-based) class, the union will aggregate all the fields in all the mixins. However, fields that are named the exact same and which exist at the same place within the hierarchy of the schema are removed through deduplication. For example, if a person’s name appears at the same hierarchy in both datasets, but they are spelled differently, the union will only keep one value based on the merge policies you have set.
ExperienceEvent classes don’t operate or behave the same way in Profile as an individual class. Unlike the data in an individual profile class, the data in an ExperienceEvent class doesn’t union, it just appends. Fields that are named the same and appear within the same hierarchy will be repeated because experience events are time-based. Each event represents a discrete moment in time. Therefore all the fields associated with it at that moment must be retained in order for the record to have meaning. This is why the behavior is so important to understand.
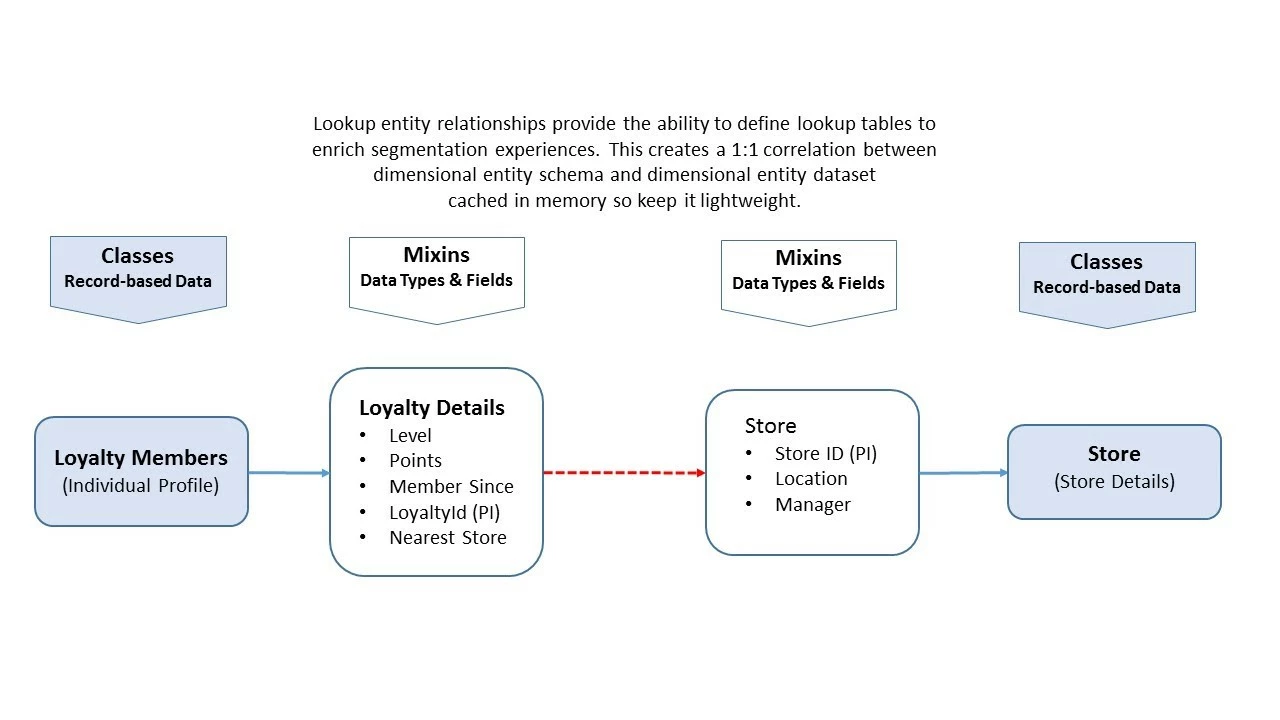
Another important concept within XDM is the multi-entity relationship. A multi-entity relationship makes it possible to define a relationship between two schemas for use in Profile Service. Figure 9 provides an example of a loyalty profile, which in this case illustrates a one-to-one relationship. In this example, the loyalty profile has a schema that contains information about the customer, and the schema for a favorite store. Instead of creating a store field and putting the name, location, and manager name of that store all within the definition of the loyalty profile and having to repeat that for millions of profiles, we instead create a lookup table. With this approach, we define a store schema of a different class and use that within profile service, put all the look-up data in there, and build a link to the loyalty profile with a foreign key relationship the same way as we would for a traditional RDBMS. Then, if the hotel manager’s name changes, rather than having to update millions of profiles, all we have to update is a single record in the lookup table.
Identities in XDM and Why You Need to Understand Them
Real-Time Customer Profile Service leverages the identity graph in Adobe Experience Platform. Every profile you develop in Profile Service must have a primary identity and is made up of one or more schemas. The key fields within these schemas can be marked as primary or non-primary “identities”. A “Primary Identity” merely tells Profile how to reconcile and store the profile fragments, which are created through all of a customer’s different interactions with a brand through different channels (Figure 10). Both “Primary” and “Non-Primary” identities collectively both works in the Identity Graph and are not treated any differently. The Identity Graph is deterministic in nature meaning the relationships within it are based on the user telling the system which identities should be related in the graph.
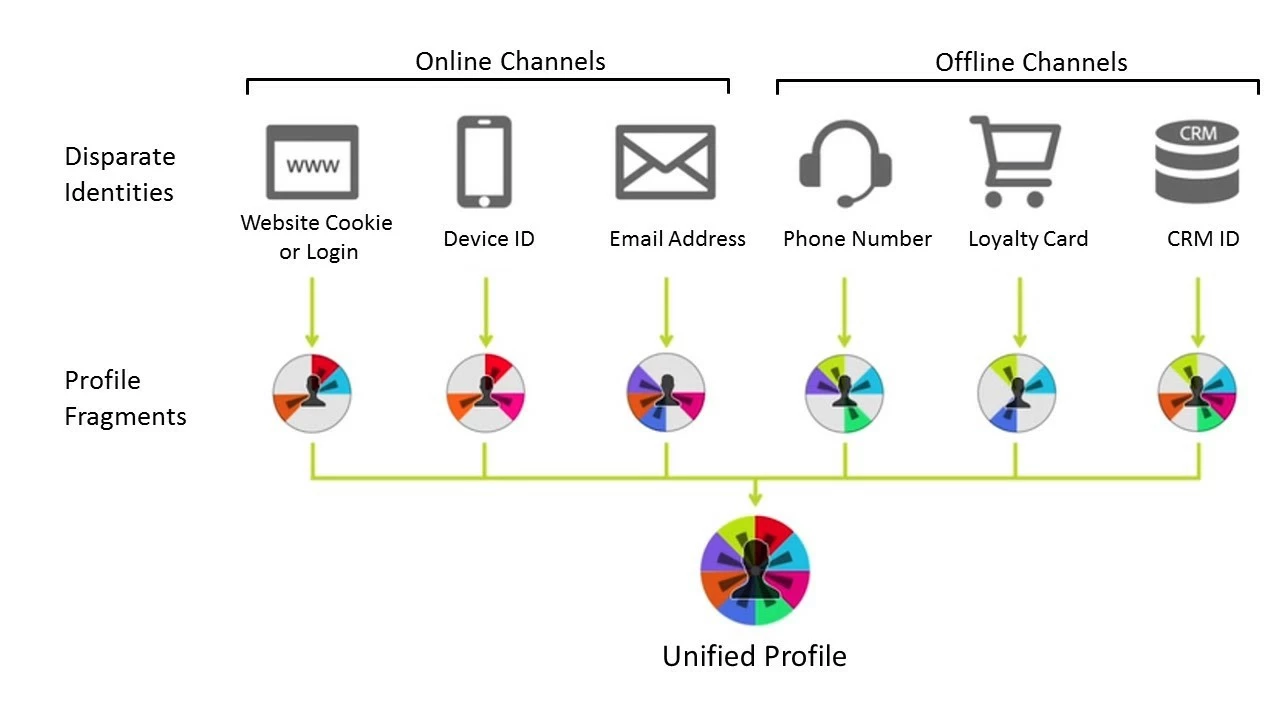
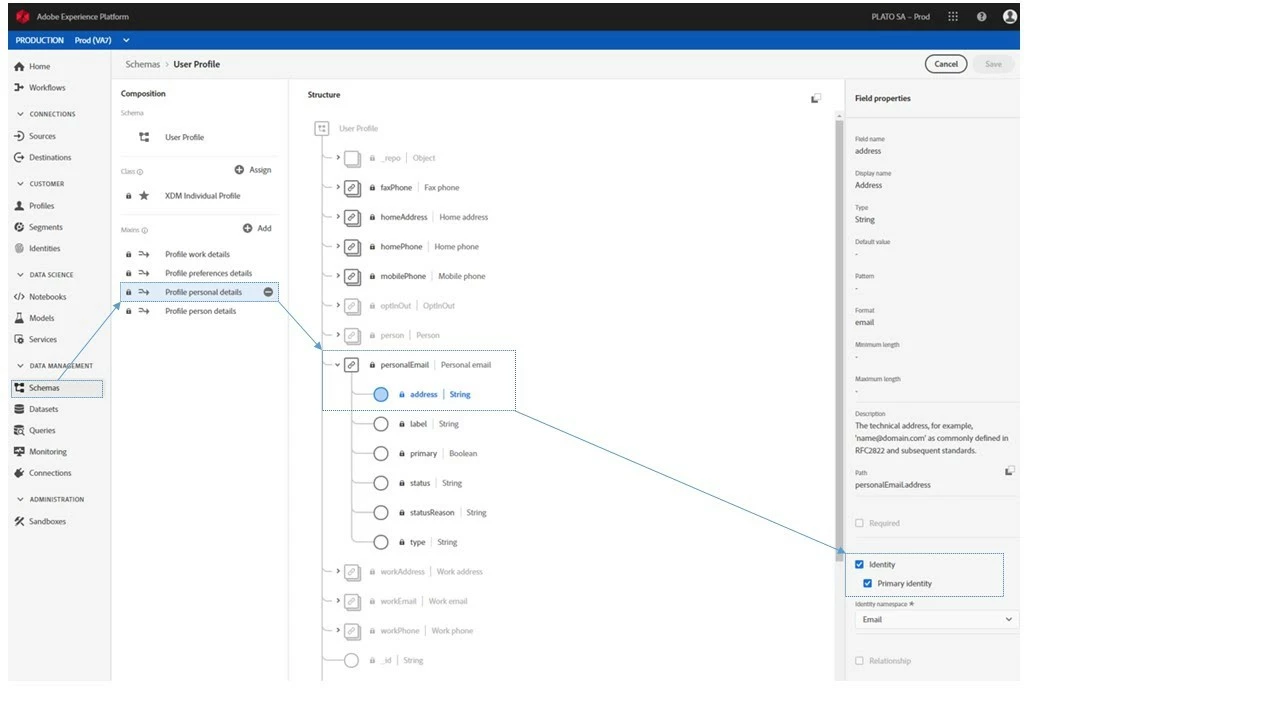
The reason we must choose a primary identity for each data set is because we need to tell Profile how to key, and it will key differently based on the class we are choosing (Figure 11). For an Individual Profile class, profile will ingest and deduplicate the data based on the primary identity before storing it in the system. With an ExperienceEvent class, the data will have both a primary identity and a unique identifier for each event (called the “event ID”) based on the time at which it occurred. The primary identity for ExperienceEvent class data tells Real-time Customer Profile how to create the storage mechanism to store the unique eventID and who it is associated with.
How to choose primary versus secondary? Primary is purely a semantic that tells Profile how to store data. Both are used to create relationships within the Identity Graph. Any identities you choose for your profile, whether primary or non-primary, are identities in the graph. For example, if you have the same identities within the same records, regardless of whether they are marked as primary or non-primary identities, they will create a relationship in the identity graph. And, anytime those values occur in any other schema, you know they will be related back to that individual. This stitching together of identities is deterministic and will create these relationships where the user has indicated to the system that those two fields should be related in the graph.
Schema Evolution Principles
With a basic understanding of XDM schemas and how they work in identity graphs, we can now turn our attention to how they work in Profile and in general. When you’re working with schemas in a development cycle, it is helpful to know what is and isn’t supported in order to make the development easier.
Many of the same rules that apply to a RDBMS apply to schemas in XDM. For example, you can add fields to a schema and make certain fields mandatory without any negative impact. There are a number of changes that are not supported and would introduce breaking changes in your data, including:
- Removing previously define fields
- Introducing new mandatory fields
- Renaming or redefining existing fields
- Removing or restricting previously supports field values
- Moving attributes to a different location in the tree
These rules only apply to data loaded into the system, and they are automatically enforced by the system. They are necessary because a table and a schema are not the same things. In XDM, we abstracted the table definition from the data to make the system more flexible. When data is ingested into Adobe Experience Platform, it is stored and policed based on the semantics of the schema it references.
For example, if you introduce a new mandatory field to a previously loaded dataset, how do you go back and police all the data that was already loaded where the new field doesn’t exist at all and was never populated? And yet it is a required field? The system cannot enforce this requirement and will block any attempt to make it. Therefore, if any of the changes noted above are needed, you will have to remove the data from the system and start over with a new upload.
The connection between XDM and Real-time Customer Profile
To drive all this home, let’s look at how this actually works in Adobe Experience Platform’s Real-time Customer Profile. Figure 10, illustrates how your data model is represented when it gets into Profile. Real-time Customer Profile is made up of attributes, behaviors, identities and segments (Figure 12). The attributes in Real-time Customer Profile (XDM Individual Profile data) might be a CRM record with first name and last name. Those attributes may also include identities. The behavior data (XDM ExperienceEvent data) in Real-time Customer Profile may also include identities. When segments are built from those identities, they too become attributes of the Real-time Customer Profile.
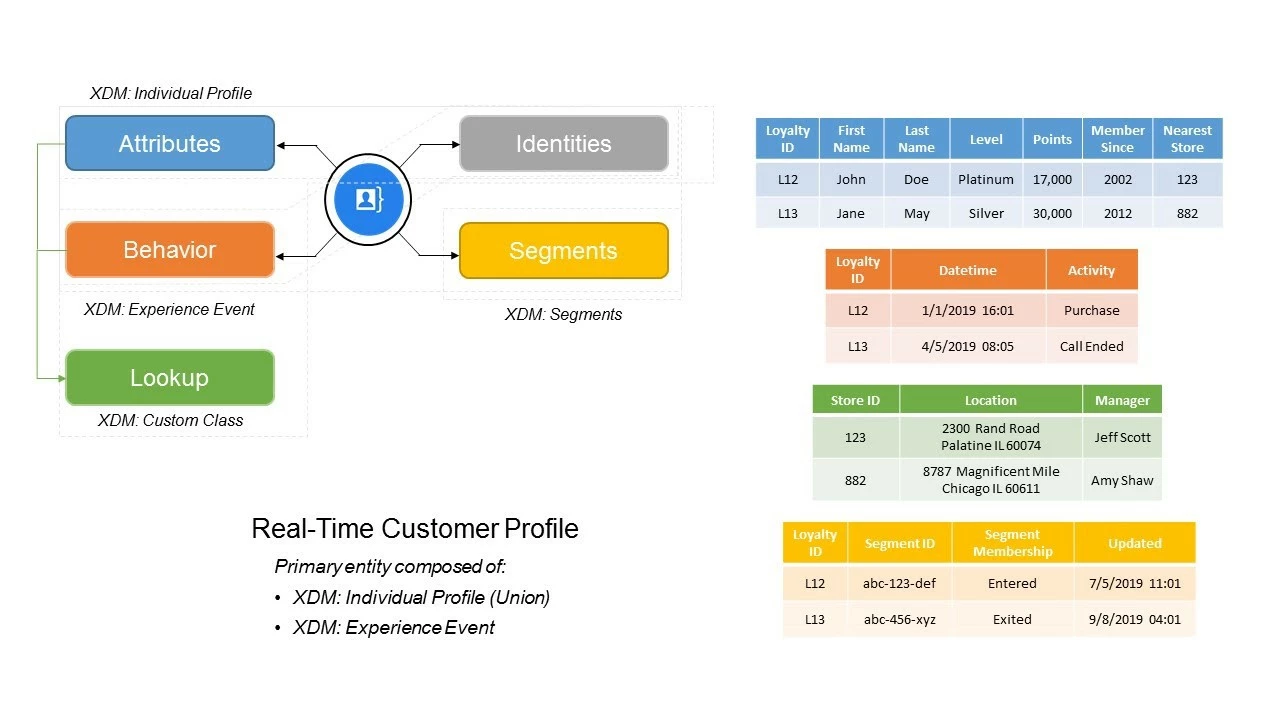
Real-time Customer Profile is composed of a single primary entity, which today works with the Individual Profile and ExperienceEvent classes only. Additional custom classes can be created within XDM but will not participate with the Real-Time Customer Profile. The one exception to this is when creating multi-entity schema relationships. A multi-entity schema is simply record-based class schema that relates to either an Individual or ExperienceEvent class schema and used as a lookup during segmentation.
For example, you have a snowflake schema in which you have a person at the middle with an account entity off to the side, which contains information pertaining to an account that person is a part of. Profile does not directly support the account entity by itself but you can use it as a lookup table for the person in which you say, the person known as ID1 is a part of this account and therefore here are the person’s account details. Real-Time Customer Profile supports only star schema but other related entities can be leveraged via lookup tables to enrich the profile.
Lookup tables in Profile are intended to function like dimensional tables in a RDBMS construct. The purpose is to avoid restating the same attributes over and over again in each Individual Profile or ExperienceEvent. Instead you place those attributes into a lookup table and reference them during segmentation.
Now taking a look at underlying architecture (Figure 13), we see Data Lake and Profile Store. Everything that you design in the system begins in the Data Lake. There is a table for every dataset you load into the system, and Profile works to reconcile those tables based on the class.
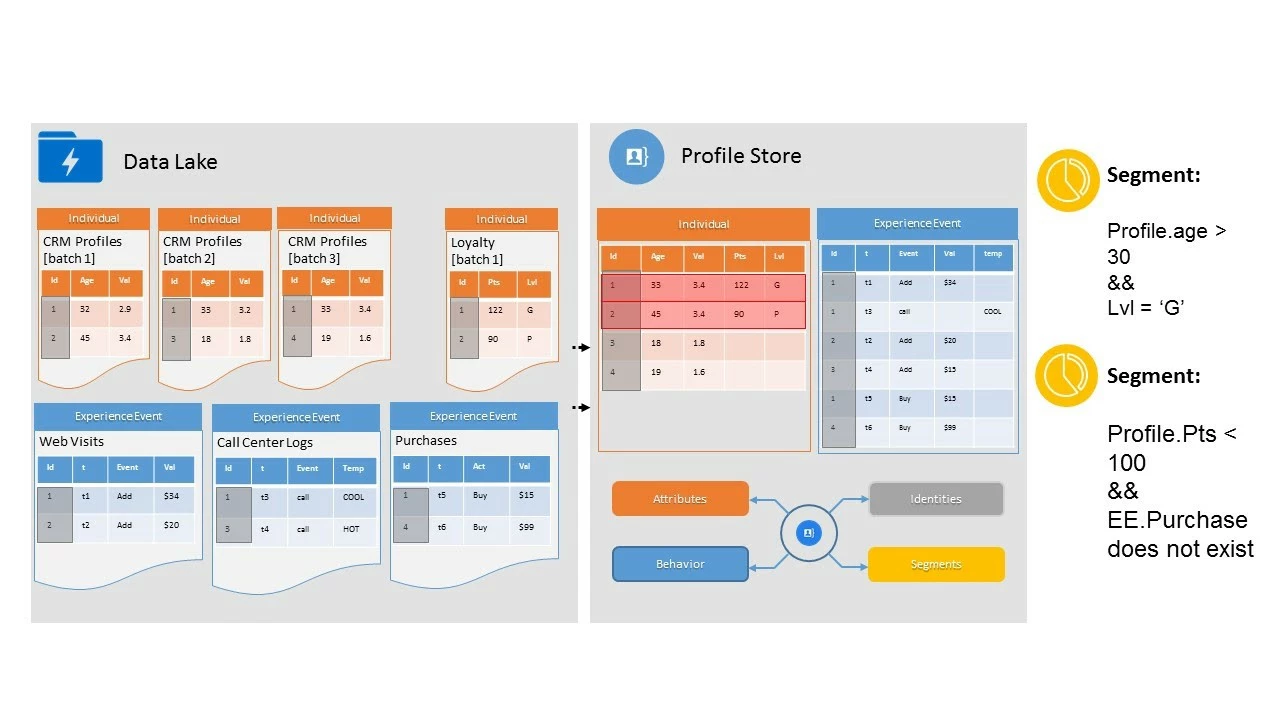
Data Lake contains all the history in your data, including your records-based data and all the changes that have occurred over time as well as all of your events-based data, which is continually flowing into the system. In contrast, Profile Store keeps only the most recent records and events, which allows it to remain agile in its delivery of profiles for real-time segmentation. In the Data Lake shown in Figure 13, we have some example datasets in two different classes all with common identities:
- Individual Profile — In this example, the dataset consists of various batches of CRM profiles, each of which has an ID column as an identifier. We also have a loyalty dataset and some ExperienceEvent datasets. When we look at the Profile Store, we see one Profile for ID1. However, there are four files in the Data Lake, and they all have an ID1 value. So, how did Profile determine which ID1 to keep? This is the unioning and deduplication in action. Note also the difference in the age value between Batch 1 to Batch 2. In Profile Store, we see that the Profile kept the most current age out of the dataset. With two competing values, Profile keeps the most recent value from the most recent batch.
- ExperienceEvent — In this dataset, there is not one line for ID1. Rather, there are three. This is because ExperienceEvent data doesn’t union, it just appends. ID1 is still an identifier, just like the ID1 in the Individual Profile dataset. However, because experienceEvent data is time-based, we will see that ID1 shows up for every interaction that customer has with the brand.
In the Profile Store, there is a primary entity composed of Individual Profile and ExperienceEvent classes. Which works by default works within the Profile Store. For example, we can create a segment using just attributes from the Individual Profile data for everyone over the age of 30 with a loyalty level of “G”. Or, we could create a segment from values in both classes, perhaps for everyone with less than 100 profile points (Individual Profile data) who have not made a purchase (ExperienceEvent data). The Profile Lookup can also be used to provide enriched segmentation by creating multi-entity relationships with other datasets in the Data Lake. All of these components, the Individual Profile, ExperienceEvents, and Lookups work together within the Profile Store to create rich segmentation on demand.
A deeper look into Profile and Identity Graph
Adobe Experience Platform stores many different channel profiles (profile fragments) and then assembles them into a unified view on demand. The Identity Graph provides the foundation for this and Real-time Customer Profile.
In our example, we loaded CRM data and loyalty data into Data Lake as two separate datasets. There is no relationship between them in Profile Service. They just look like a bunch of orphaned datasets. What is bringing them together is the Identity Graph. This is illustrated in Figure 12 where we can see the node cluster being built out in the Identity Graph with the different types of data we have defined as identities in our datasets. When we do an ID lookup on CRMID C44, we can see that there are a bunch of other identities related to it based on different data that has been loaded or streamed into the system.
This is made possible by the definition of identities, which create relationships that Identity Graph can use to match up profile fragments and identities from different tables on the fly, using merge policies to define how the profile will be assembled (i.e. which values are used and which will be ignored). In Figure 14, you might notice that the merged view for Loyalty Id 122 shows the First Name as “Bob” while the Loyalty View, the First Name is “Bobby”. In this example, a merge policy was set to use the value in the CRM dataset instead of the value in the Loyalty dataset in the Profile Merge when those values differ.
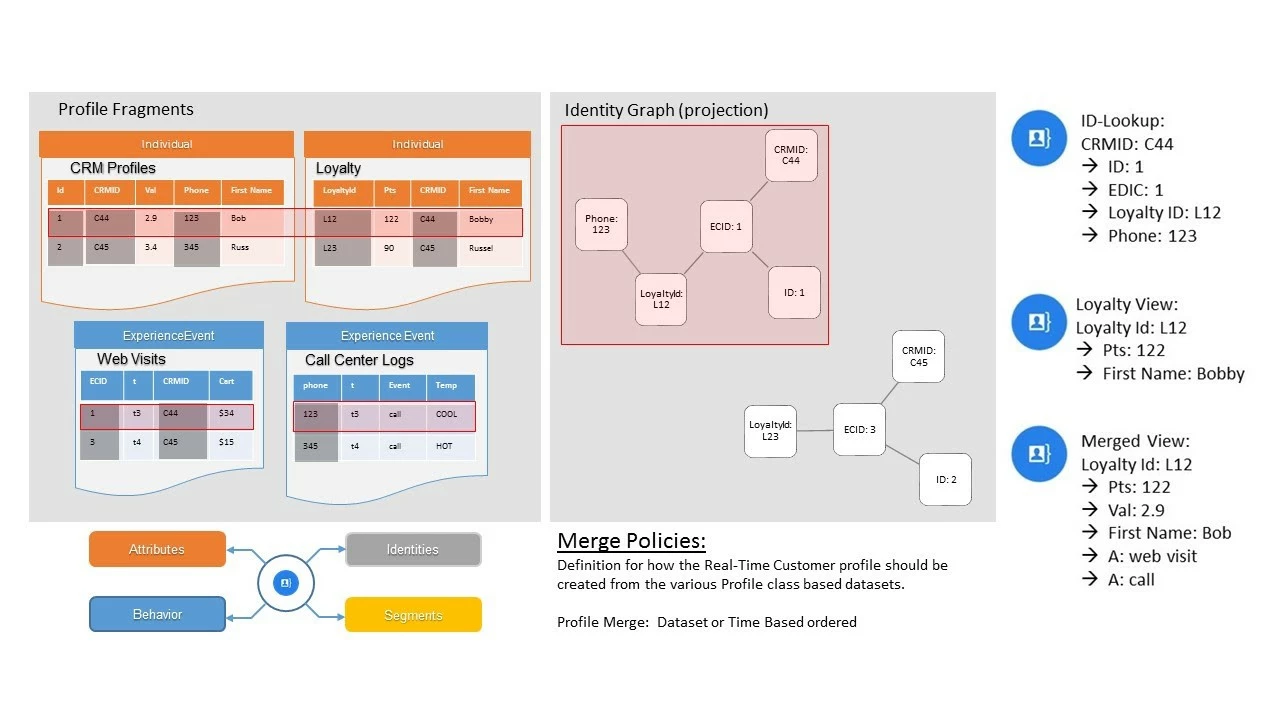
Profile stores all of the fragments of a profile in a fragment tower for each one of the datasets shown in the Data Lake and assembles the data on demand. In contrast to other profile stores that use ETL, which is slow and laborious, to create a single record for each Real-time Customer Profile. In Adobe Experience Platform, the Real-time Customer Profile is composed of many different profile fragments that are assembled together on-demand using the Identity Graph.
Parting thoughts…
When working with profiles, think of Real-time Customer Profile not as a replacement of a master data management (MDM) system. Profile is meant to provide a lightweight and actionable profile for use in marketing. The end goal of Profile is not to recreate your data warehouse. Rather, the goal is to get actionable data that your marketing teams can use. Real-time Customer Profile provides the architecture to assemble all the data you need on-demand and in real-time. The Data Lake provides the storage you need while Real-time Customer Profile allows you to curate the data you need to build rich profiles that allow you to deliver highly personalized customer experiences in real-time.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Resources:
- Adobe Experience Platform — https://www.adobe.com/experience-platform.html
- Adobe Experience Platform Experience Data Model (XDM) — https://www.adobe.com/experience-platform/experience-data-model.html
- Schema Registry — https://docs.adobe.com/content/help/en/experience-platform/xdm/home.html
- Schema Registry API Developer Guide — https://docs.adobe.com/help/en/experience-platform/xdm/api/getting-started.html
- Experience Data Model: The Rosetta Stone of the Experience Business (a white paper) — https://www.adobe.com/content/dam/acom/en/experience-platform-highlights/pdfs/adobe-experience-platform-data-model.pdf
- Adobe Experience Cloud Solutions — https://www.adobe.com/experience-cloud.html
- Adobe Experience Platform XDM on GitHub — https://github.com/adobe/xdm
- Real-time Customer Profile overview — https://docs.adobe.com/help/en/experience-platform/rtcdp/profile/profile-overview.html
- Basics of Schema Composition — https://docs.adobe.com/content/help/en/experience-platform/xdm/schema/composition.html
- Data Behaviors in XDM — https://docs.adobe.com/help/en/experience-platform/xdm/home.html
- Mixins — https://docs.adobe.com/help/en/experience-platform/xdm/api/create-mixin.html
- Classes — https://docs.adobe.com/content/help/en/experience-platform/xdm/home.html
- Unions — https://docs.adobe.com/help/en/experience-platform/xdm/api/unions.html
- Merge Policies — https://docs.adobe.com/help/en/experience-platform/rtcdp/profile/profile-overview.html
- Define a relationship between two schemas using the Schema Registry API — https://docs.adobe.com/help/en/experience-platform/xdm/tutorials/relationship-api.html
- Identity Graphs — https://docs.adobe.com/content/help/en/experience-platform/identity/home.html#identity-graphs
- Adobe Experience Platform Identity Graph is the Foundation for the Unified Profile —
- Understanding and Using Identity Graph — https://docs.adobe.com/content/help/en/platform-learn/tutorials/identities/understanding-identity-and-identity-graphs.html
- Merge Policies User Guide — https://docs.adobe.com/content/help/en/experience-platform/profile/ui/merge-policies.html
Originally published: Jul 16, 2020