
Automated Upgrade Testing: A Process to Test and Validate Software Upgrades
Author: Baubak Gandomi

One of the subjects I have been interested in is how do we automatically validate the successful upgrade/migration of an application. Upgrading is one of the biggest pains in many organizations, and the validation of it is even more complex. This is usually because there are so many elements and steps involved in such a process. Another big problem with issues found during upgrades is correctly finding the cause of the problems and reproducing them. This has been a challenge that we set out to address at Adobe Campaign. This process is now standard validation for the Adobe Campaign product releases.
We will describe the different methods for automating upgrade tests, and how we can highlight issues that are purely related to upgrades.
Nomenclature
To avoid any misunderstanding we will be using the following nomenclature:
- Upgrade: The process of changing a deployed version N (Source Version) for software to another version M (Target Version), for migration.
- System Under Test (SUT): The system you are testing.
- Source Version: The version (or revision) of the product before you upgrade to a later version.
- Target Version: The version (or revision) to which you want to upgrade.
Issues to be Solved
The problems we have detected when testing upgrades are the following:
- How do we make sure that the problem is related to the upgrade, and is not inherent in the product?
- How can a problem be clearly identified and reproduced?
We cannot really identify all causes related to upgrades, but in our attempts at categorizing them we have come to narrow the problems into two categories depending on the deployment of the product:
- System Related Issues: Problems that show up due to requirements related to the upgraded system.
- Data Related Issues: Issues that are manifested on a system with and due to data
The solutions in this article will address both issues, however, the major challenge lies in data-related issues. Therefore we put more emphasis on data-related solutions.
System Related Issues
We do get a lot of upgrade issues due to new requirements and dependencies in an upgraded system. These could be issues that relate to conflicting metadata as well as environmental issues such as conflicting drivers, servers, and resources. Usually rerunning your normal tests after an upgrade will find such issues.
Data Related Issues
This case is the most relevant, and common. It is also the hardest to test and to manage. The traditional way this is tested is by having a system that is regularly upgraded and tested. The problems we have detected in such cases are:
- Problems that should up during the upgrade process itself.
- Data incompatibility such as issues such as index failures, primary key problems.
- Failing workflows and processes causing issues where a workflow or processes started before the upgrade which cannot be continued.
- Loss in functionality due to data processing in which old data causing a loss of functionality when processing new data. An example would be problems arising when you re-analyze an image or a document.
Testing and Automating Upgrade Tests
Although the solutions provided in this document will primarily focus on detecting Data related issues, we are quite certain that system issues will also be detected with these processes.
In order to address the issues above we identify three categories of checks:
- Upgrade process validation.
- Validation of standard workflows on an upgraded system.
- Validation of unfinished workflows that started before the upgrade.
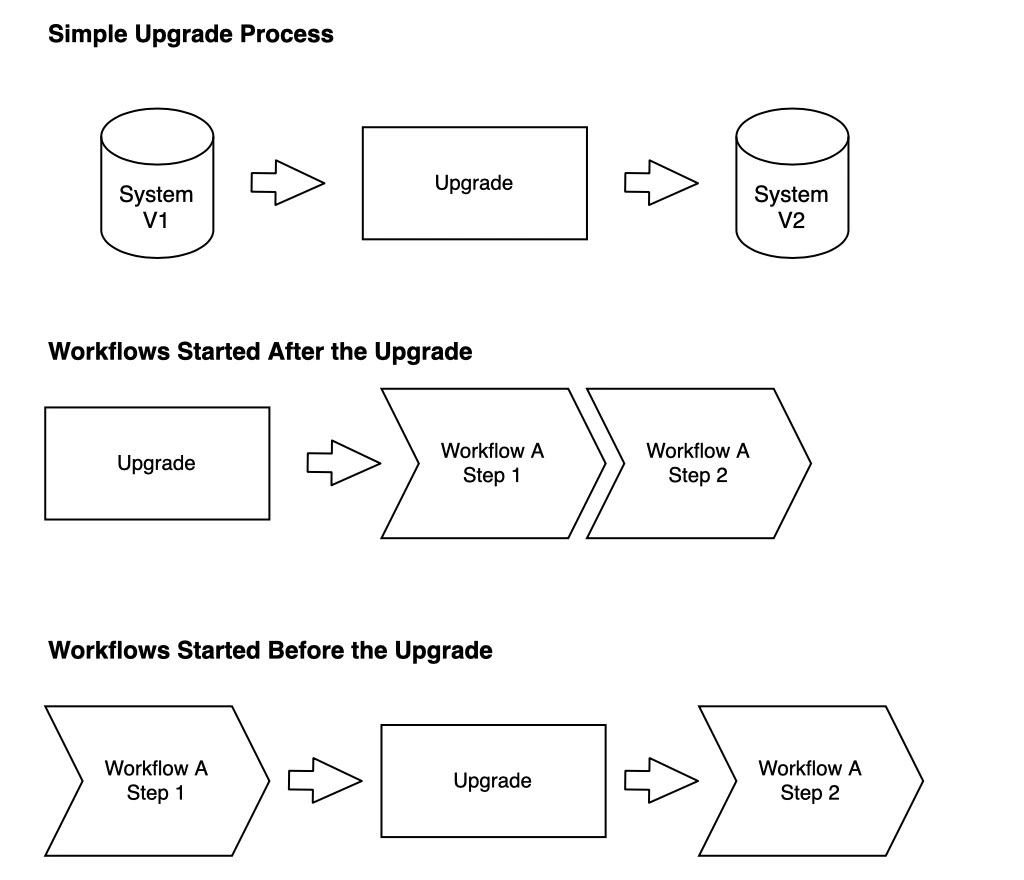
The first two are quite straightforward, as they are fairly standard, and do not really constitute a challenge, except in the process automation itself. An upgrade process will either fail or not. We can go more in-depth in the tests, however, we think it deserves its own article. Testing scenarios work after an upgrade is also quite simple as it consists of simply executing your tests after an upgrade.
Regarding validating workflows that start in one version and that carries on after the upgrade process we have introduced the concept of Phased Testing.
Phased Testing
Phased testing is the method of executing a test scenario/workflow in two different phases. We call these:
- Producer Phase: Executed before the upgrade
- Consumer Phase: Executed after the upgrade
In the context of upgrade testing, the test will have two parts. One part is executed before the upgrade (Producer), and after the upgrade, it continues with the second part of the test I.e the Consumer Phase.
For this to work, the test scenario needs to create and store a marker/token allowing the second phase to identify where the first test left off.
The trick here is for the test to store a token that can be used by the second part of the test, whenever executed, to continue where the first part left off.
In regards to the token the phases work in this way:
- Producer Phase: The test generates/produces the data in the system that is later used after the upgrade.
- Consumer Phase: The test makes use/consumes of data that was generated before the upgrade
When you are in the Producer phase you need to store a token such that it allows you to carry on the next phase of the test where you left off. This could involve the storing of different ids of the elements you will be needing in the Consumer phase.
Example: Imagine you have an application that allows you to create an email, and that sends it to a user. A scenario would have the following steps:
- Create a user
- Create an email (delivery)
- Send email
- Check that email arrives successfully
One would imagine that a phased test would involve steps one and two before the upgrade, and steps three and four after.
Below is a code sample representing the scenario above. As mentioned before we have a Producer and a consumer phase. These steps are each in their “if” statements. ProducerTestTools.produce TOKEN_NAMEstores the token with the given TOKEN_NAME. ProducerTestTools.consumeTOKEN_NAME will fetch the value of the token with the name TOKEN_NAME.
(groups = { TestGroups.UPGRADE, TestGroups.DELIVERY })
public void testEmailDelivery_Upgrade() {
// This is the step before upgrade, we create a email delivery
if (PhasedTestTools.isProducer()) {
log.info(“Here is producer before Upgrade”);
// Create a profile and a delivery
JSONObject delivery = deliverySchema.createConfiguredDelivery(
“tyrone@slothrop.com”, “Regarding Rainbows”,
“Hello Are they affected by Gravity?”);
// Store the delivery name
PhasedTestTools.produce(“testEmailDelivery_Upgrade_deliveryName”,
delivery.get(“name”));
log.info(“Start Upgrade”);
}
// This is the step after upgrade, we find the created delivery before and
//prepare/send the delivery
if (PhasedTestTools.isConsumer()) {
log.info(“Consumer Stage”);
// Fetch the delivery name created before PU
String deliveryNameNew = PhasedTestTools
.consume(“testEmailDelivery_Upgrade_deliveryName”);
// Find the delivery
JSONObject delivery = deliverySchema.getDeliveryObjectByName(deliveryNameNew);
// Send the delivery
deliverySchema.sendDelivery(delivery);
// Verify the delivery is actually sent to the given recipient
List<Message> l_retreivedMails = EmailClientTools.fetchEmail(
“tyrone@slothrop.com”, ”Regarding Rainbows”);
assertThat(“The message was not sent or could not be retrieved.”,
l_retreivedMails.size(), is(equalTo(1)));
Message l_retreivedMail = l_retreivedMails.get(0);
assertThat(“The given email as the proper subject”,
l_retreivedMail.getSubject(),
is(equalTo(”Regarding Rainbows”)));
assertThat(“The given email should have correct recipient”,
l_retreivedMail.getRecipients(RecipientType.TO)[0]
.toString(), is(equalTo( “tyrone@slothrop.com”)));
}
}
}At first, we are in the producer phase. In there, we create an email delivery to tyrone@slothrp.com with a title Regarding Rainbows. We store the email information in a token with the title testEmailDelivery_Upgrade_deliveryName. After the upgrade, we enter the consumer phase. In that phase, we retrieve the email delivery stored in the token testEmailDelivery_Upgrade_deliveryName. Then we send the email and check that everything went smoothly.
An Upgrade Process That Finds Errors
Now that we have a better understanding of what Phased testing looks like, an upgrade test process will look something like this:
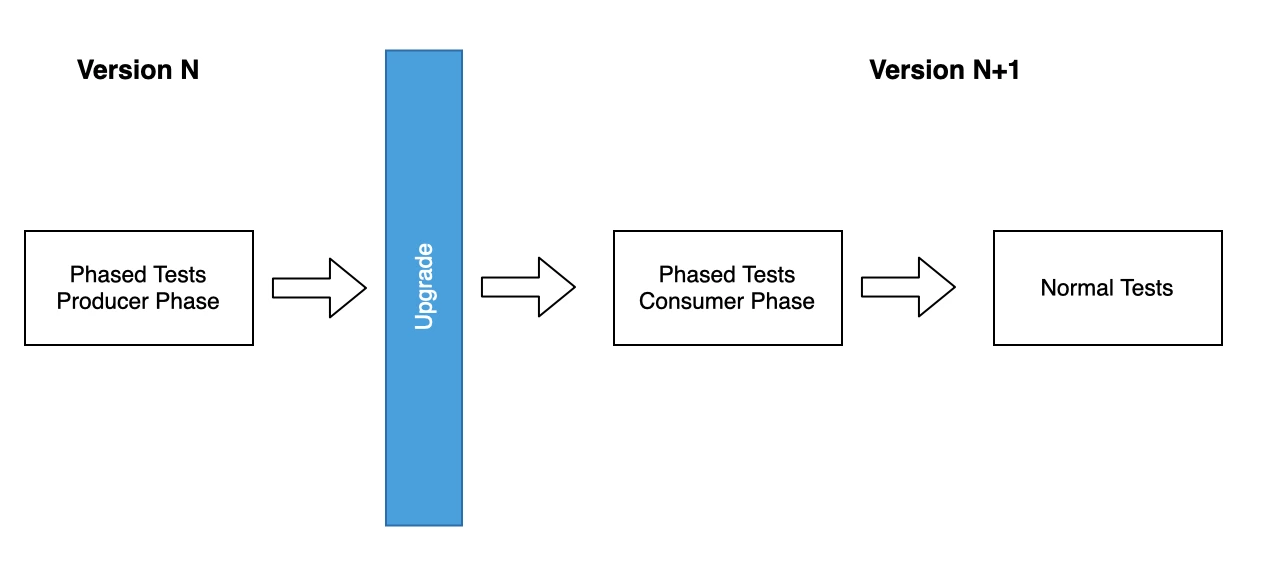
Before the upgrade we will perform Phased Tests in the producer mode. This allows for filling the database.
Once the phased tests have finished we can start the upgrade process. As we mentioned earlier this step can also be considered as a test, wherein its most basic form is its own success. One could include elements of log parsing database consistency checks here, but as we mentioned previously, it is not the focus of this article.
After the upgrade, the phased tests will take off where they had left their work to finish their workflows.
Finally, we perform our normal tests to ensure that there is no loss of functionality due to an upgrade. This could be done in the process above or in a different process, but it needs to be done.
The problem with this process is that we may encounter false positives. How do we know that a test that fails in the upgrade is due to just that? For this, we developed a method called Target Version Benchmarking, which helps you highlight problems that are directly related to upgrades.
Target Version Benchmarking
Target version benchmarking is the method for automatically detecting true upgrade issues in your System Under Test. Although difficult, the challenge of doing upgrade tests is not to automate tests, but to ensure that the tests are really related to Upgrade issues.
For this Target version benchmarking is used to discard noise in an upgrade process.
An upgrade scenario involves the following steps:
- Create an instance of the System Under Test with the Source Version.
- Add some data (optional).
- Upgrade your System Under Test to the Target Version.
- Run your tests.
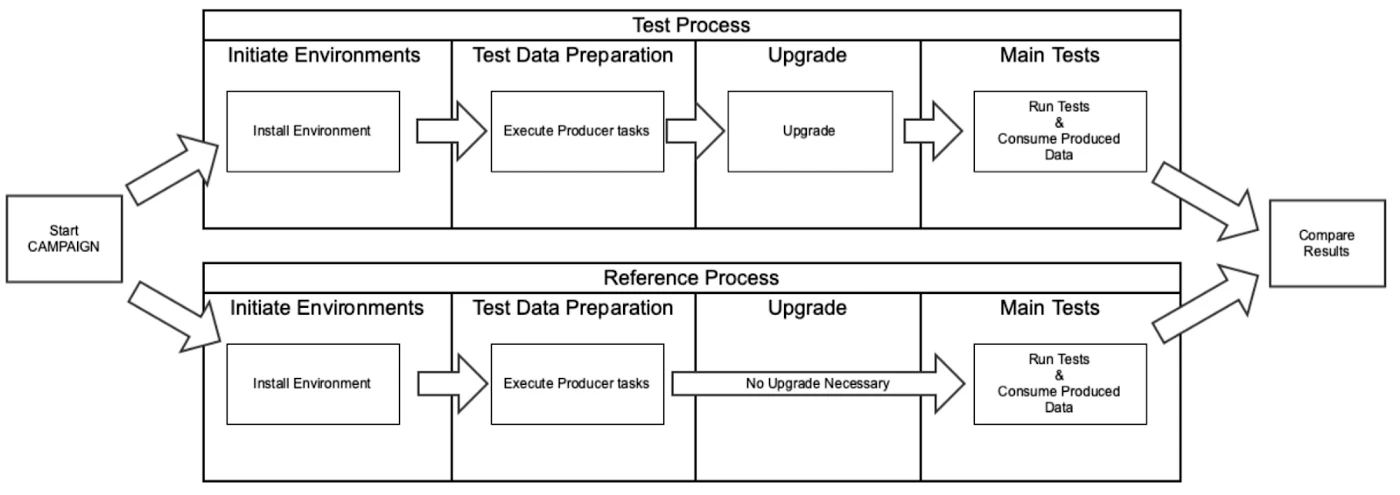
In Target Version Benchmarking we run the process above in two parallel processes.
- Process 1 (Test Process) : Source Version < Target Version
- Process 2 (Reference Process) : Source Version =Target Version
When both processes have successfully terminated, we compare the results. The issues that are found only in the Test Process will be the issues that are directly related to upgrades.
Challenges
We discovered that the process is obviously long and has a lot of steps, but we have been able to keep it running. It also requires an automated upgrade step. This needs to be considered early in your planning.
Another challenge is finding a more intuitive way of separating tests into phases. In our solution, we have been using a standard condition statement to make the distinction, but we believe this process can be made easier.
Finally, the last challenge is the management of tests and their versions. The tests need to functionally exist in the Source & Target versions otherwise it will fail. This is a challenge for how one executes their tests and maps them to versions.
Conclusions
This process has been in production at Adobe Campaign for the last four to five years and is still helping us find issues. This is now also being used by the IT Cloud services to predict problems in major client migrations from one system to the other.
One may correctly argue that, If you have a very stable system with very few errors that you may skip the reference process. This is quite true in many cases where your tests are xUnit tests. However, our experience is that not all systems are suitable or even have xUnit tests. In many systems, the complexity is too high for simple tests xUnit functional tests. This would be the case where you perform an analysis of a compiler or a system like sonar where the objects that are created may vary between versions. Even in xUnit test systems you may still need to quickly qualify your errors, and treat them accordingly.
I would also like to add that, keeping a client-like System for manual upgrade testing is still valid, and is necessary. It may be done semi-automatically, but not completely so. This is still useful, as it will still help us find issues, but this is more in the domain of exploratory. It will be a great help in discovering undetected issues. We could imagine implementing something similar to the phased testing for client data. A system that randomly picks workflows and follows through with them. That again is something we feel deserves its own article.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up for future Adobe Experience Platform Meetups.
Related Blogs
- Transactional Coverage — a Functional Approach to Detecting Test Gaps
- Problems with Code Coverage when Assessing Functional Tests
Originally published: Mar 11, 2021