
Richer Data, Smarter Journeys : Why Dataset Lookup is the key to next-level personalization in AJO
- September 22, 2025
- 0 replies
- 4454 views
Marketers Need Enriched Data to Personalize Journeys
Marketers today aren’t just sending emails—they’re building personalized customer moments. Think about it:
-
A recipe card or setup guide landing right after a purchase, tailored to the exact product in the “Buy” event.
-
A coupon nudging new homeowners or parents to spend more in categories like Garden, Furniture, or Kids.
-
An abandoned cart reminder that doesn’t just say “come back,” but shows the actual items left behind—complete with name, price, and image.
For these communications to feel personal and relevant, the content must be fueled by the right data at the right time. Journey authors need reliable, real-time access to product catalogs, instructional content, and transaction details—not just what’s stored in a customer profile.
Why Profile-Based Lookups Became an Anti-Pattern
Embedding large datasets directly inside customer profiles may seem convenient—but it quickly becomes a scaling bottleneck. Profiles are partitioned by customer ID, so repeated lookups create hotspots, exhausting throughput and triggering throttling errors.
The CosmosDB Bottleneck
-
Journeys fetched enrichment data by embedding catalogs, SKUs, and instructional content directly in CosmosDB profiles.
-
Partitioning by profileId meant all queries for a customer hit a single logical/physical partition.
-
Repeated reads multiplied load, consumed all RUs, and triggered 429 throttling errors.
-
Non-profile datasets stuffed into profiles bloated documents, leading to expensive reads and brittle operations.
Outcome: Campaigns slowed or failed, p99 latency spiked, and journeys struggled to deliver timely, personalized experiences.
The Solution: Aerospike + Dataset Lookup Activity
To address these challenges, enrichment data was moved out of CosmosDB profiles into Aerospike, a hash-partitioned, single-key optimized store, accessed via the Dataset Lookup Activity.
How It Works
-
Balanced traffic: Hash-partitioning prevents hot partitions.
-
Single-hop lookups: Queries go directly to the node owning the key.
-
Batching & caching: Multiple SKUs or items fetched efficiently, with deduplication.
-
Clean separation: Profiles stay lean; enrichment datasets scale independently.
Runtime Details: How Dataset Lookup Activity Enriches Journeys

The Dataset Lookup Activity allows journeys to fetch real-time enrichment data during execution, without overloading the profile store.
-
Node Configuration
-
Select the dataset containing product catalogs, instructions, or transactional metadata.
-
Define lookup keys using journey context (e.g.,
cart.items[].skuorpurchase.productId). -
Choose which fields to retrieve for downstream use (name, price, image, category, etc.).
-
-
Execution Flow
-
Journey triggers the Dataset Lookup Node.
-
Node sends the lookup keys to the lookup service, which queries Aerospike:
-
Single-key lookups go directly to the node owning the key.
-
Batch queries efficiently fetch multiple items in one request.
-
TTL caching reduces repeated queries for the same key.
-
-
The results are returned as a JSON array.
-
-
Enriching Journey Context
-
Retrieved data is stored in the Journey Context.
-
Available for downstream nodes for:
-
Conditional checks: e.g., spend per category > $100.
-
Personalization: e.g., showing SKU-level details in an abandoned cart email.
-
Custom actions: e.g., triggering coupon delivery.
-
-
-
Expression Editor & Personalization
-
Use the journey’s Expression Editor to transform, filter, or aggregate dataset results.
-
Example: aggregate category spend or filter SKUs by availability.
-
Complex business logic runs without touching the profile store, keeping journeys fast and scalable.
-
Why It Matters:
-
Real-time enrichment with up-to-date catalogs and SKU data.
-
Eliminates hot partition issues and RU exhaustion.
-
Supports high-volume concurrent journeys with minimal latency.
-
Enables advanced use cases like abandoned cart recovery, post-purchase instructions, and category-based segmentation.
Sample Use Cases
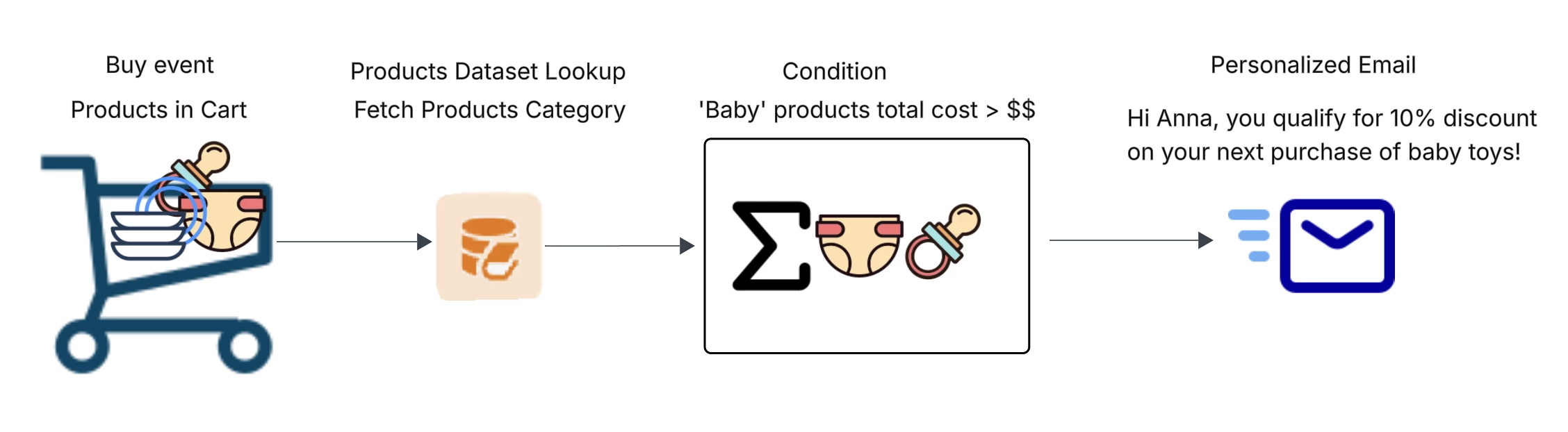
Here’s how the new architecture transforms real marketing journeys:
A. Category Spend Segmentation (Baby, Garden, Furniture)
Old Cosmos flow: Repeated profile lookups with embedded product data → hot partitions → 429s.
New flow:
-
Cart items written to event.
-
Dataset Lookup Node fetches fields from the dataset using SKU keys.
-
Data retrieved from Aerospike via the lookup service.
-
Results stored in Journey Context for aggregation, conditions, personalization, or coupon delivery.
Impact: Accurate, real-time segmentation without throttling.
B. Product-Linked Instructions (Recipes, Plant Care, Furniture Setup)
Old Cosmos flow: Instructions not profile-enabled → schema hacks or cross-partition queries.
New flow:
-
Purchase SKU triggers Dataset Lookup Node.
-
Lookup service fetches instruction content from Aerospike, including locale-specific variants.
-
Journey enriches context → personalized emails or messages.
Impact: Post-purchase personalization works reliably and scales.
C. Abandoned Cart Recovery
Old Cosmos flow: SKU-level enrichment required embedding large product arrays into profiles → 429s, retries, failures.
New flow:
-
CartAbandoned event triggers journey.
-
Dataset Lookup Node calls the lookup service → batch SKU enrichment from Aerospike.
-
Journey dynamically populates personalized emails with product name, image, and price.
Impact: Higher cart recovery, richer personalization, no risk of RU exhaustion.
The Dataset Lookup Activity transforms how journeys handle enrichment data. By decoupling heavy lookups from the profile store and leveraging a hash-partitioned, single-key optimized system, organizations can:
-
Eliminate bottlenecks and 429 errors, ensuring reliable journey execution at scale.
-
Deliver real-time, SKU- and category-level personalization, powering dynamic emails, coupons, and post-purchase content.
-
Reduce operational complexity, keeping profiles lean while enabling agile updates to enrichment datasets.
-
Scale campaigns predictably, supporting high-volume, concurrent journeys without compromising latency or performance.