



This conversation has been locked due to inactivity. Please create a new post.
This conversation has been locked due to inactivity. Please create a new post.
Why the sample size calculator over estimates the sample needed? With fewer visitors than the estimated, the results are conclusive.
For example:
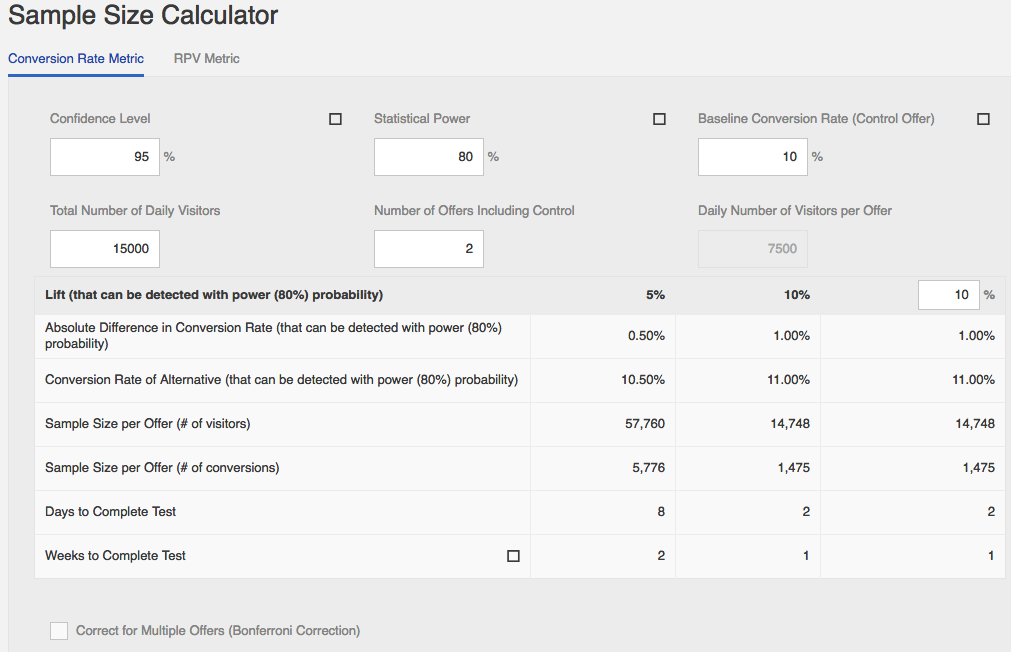
80% power, 95% Confidence level, baseline conversion of 10%, 2 offers, and 1000 daily visitors, the calculator says that you will need:
a sample size of 14,748 visitors to detect a lift of 10%.
However, with 10,000 visitors per offer, you can detect a lift of 10% with a 98,89% Confidence Level.
Thank you in advance for your help.
Solved! Go to Solution.
Views
Replies
Total Likes

Hi Rohit, I'm a product manager on Target and let me try to address your concern. First and most importantly, the sample size calculator does not provide an estimate. It stipulates the minimum sample size required in order to guarantee that your false-positive rate (ie inverse of Confidence) is bounded. Which means that if you desire a 95% confidence (or 5% false-positive rate), you MUST wait until this sample size has transpired in order to guarantee that only 1 out of 20 times (ie 5%) will a test yield a false-positive. Only after the test has crossed the sample size, a user should look at the Confidence-value and ascertain that it is indeed above 95%. If the confidence-value after the sample side has been acquired is below 95%, this means that at a 95% threshold for significance, your test in inconclusive. If all of this didnt make sense, here is a simple 3-step workflow to do AB-testing correctly:
1. Compute the sample size with desired significance (say 95%) and most accurate guesses for "Baseline CR", "Minimum detectable lift". If you have more than 2 experiences, dont forget to apply Bonneferroni correction.
2. Wait until each experience has acquired this sample size.
3. Evaluate only at this point, whether the Confidence value shown in the Reports is above 95%. If its not, your test is inconclusive and you do not have a winner for this test.
I understand this is something you may not have done before, but our years of analysis have shown that if users dont wait until the sample size, their tests are 56% likely to find a false-positive (ie a 'winner' that actually performs worse than control in reality).
Hope that helps!

Hi,
The sample calculator gives an estimate on the amount of time and traffic based on the variables provided. Since this is an estimate and not an accurate number the chances of this meeting the actual results for a campaign are less likely. There is a high probability of a campaign reaching the expected lift much earlier or much later depending on the nature of the campaign and components being tested within the campaign.
Hope this helps!
Thanks,
Rohit
Views
Replies
Total Likes
Thank you for your reply Rohit
The point is that the sample calculator always over estimates the amount of traffic needed to reach conclusive results, this also happens using others size calculators.
Views
Replies
Total Likes
Hi Rohit, I'm a product manager on Target and let me try to address your concern. First and most importantly, the sample size calculator does not provide an estimate. It stipulates the minimum sample size required in order to guarantee that your false-positive rate (ie inverse of Confidence) is bounded. Which means that if you desire a 95% confidence (or 5% false-positive rate), you MUST wait until this sample size has transpired in order to guarantee that only 1 out of 20 times (ie 5%) will a test yield a false-positive. Only after the test has crossed the sample size, a user should look at the Confidence-value and ascertain that it is indeed above 95%. If the confidence-value after the sample side has been acquired is below 95%, this means that at a 95% threshold for significance, your test in inconclusive. If all of this didnt make sense, here is a simple 3-step workflow to do AB-testing correctly:
1. Compute the sample size with desired significance (say 95%) and most accurate guesses for "Baseline CR", "Minimum detectable lift". If you have more than 2 experiences, dont forget to apply Bonneferroni correction.
2. Wait until each experience has acquired this sample size.
3. Evaluate only at this point, whether the Confidence value shown in the Reports is above 95%. If its not, your test is inconclusive and you do not have a winner for this test.
I understand this is something you may not have done before, but our years of analysis have shown that if users dont wait until the sample size, their tests are 56% likely to find a false-positive (ie a 'winner' that actually performs worse than control in reality).
Hope that helps!

Views
Replies
Total Likes

This also makes me wonder if it's a good idea to include a copy of the control experience as a sort of embedded A/A test within my A/B/n tests. True, an extra traffic toll, but also a way to common-sense-check the test results.
Views
Replies
Total Likes
Hi Chintan,
Thank you for your answer, it helps a lot.
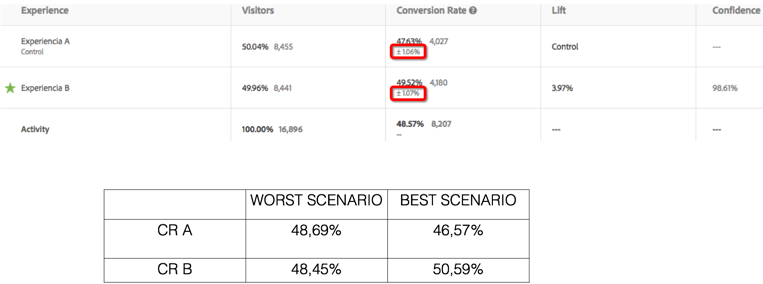
If I understand well, we only should look at the confidence level when the sample reach the minimum sample estimated by the calculator. My question then is, Why target is telling us that there is a 99% confidence level, when the sample isn't enough?
Thank you, best regards.
Views
Replies
Total Likes
Hi,
Target does not take the sample size into account because target reports provide the actual performance of experiences in reports. Thus here the confidence number is a reflection of actual conversion rates captured by the system in the back-end and then plotting them to come up with a confidence number.
Chintan, Correct me if my understanding is wrong.
Thanks,
Rohit
Views
Replies
Total Likes
Hi,
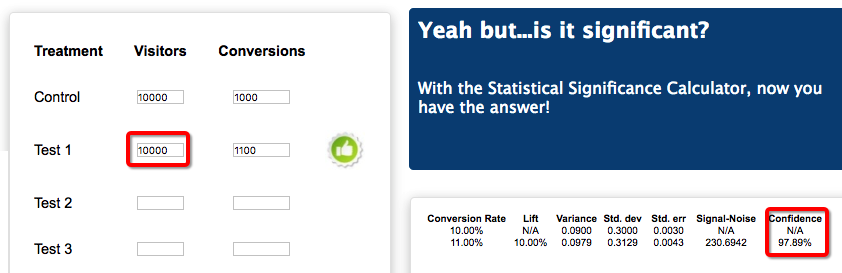
For instance, the following data, represents a test with 97% confidence level:
Variation A: 5000 visitors - 250 conversions
Variation B: 5000 visitors -300 conversions (20% lift)
but if we try to estimate which is the sample needed to detect a 20% lift, when the baseline conversion is 5%, the experiment consists in 2 variations, setting a 95% confidence level and 80% statistical power. The calculator says that you will need: 8,155 visitors per sample. (When the truth is that with 5000 visitors you will reach more than 95% statistical confidence)
Views
Replies
Total Likes
Hi, this is because Target is a tool and it can be used however the user desires. More specifically, Target doesnt know the test's sample size and so it continues to show Confidence even when the value is not valid.
Dear miguelm62125791, I'm sorry to say your reasoning is not correct. The science of AB-testing is complex, nuanced and highly-specific; without going into too much detail all I can tell you is that even if the UI shows 99.9% confidence it doesnt mean absolutely anything (as in, it doesnt mean that you have a 0.01% false-positive rate) if the minimum sample size has not been achieved.
Views
Replies
Total Likes

One thing that might help to visualize this is a confidence simulator at the URL below. It does a great job of explaining the concept of "reaching confidence" vs "being confident". M
http://destack.home.xs4all.nl/projects/significance/#
Consider this scenario with 100 experiments simulated in an A/A fashion and a sample size of 100k and a p-value of .05.
5 experiments ended as significant (which is what we would expect given a 5% false positive rate) but an astounding 41% in this simulation were significant at some point "during the test".
Target doesn't differentiate between "ended" and "ongoing" so that is why you might see something as significant in the tool, but if the minimum threshhold hasn't been met - that isn't the "end"
Hi,
Thank you for your answer Jason.
Something that really worries me, is how to explain the team who works with Adobe Target, that they should ignore the confidence level shown, unless the sample size and number of conversions reach the number suggested by the sample size calculator. Would not be it easier that AT shows an alert when the sample is sufficient?
Thank you, best regards.
Views
Replies
Total Likes
Great feedback Miguel, and something definitely worth considering. One benefit of the current approach is that it allows you the flexibility to accept your own range of false positives (either via using the calculator or not) via P Value. The more structure in place in the UI around reporting, the less flexibility you would have. But I definitely hear you!
Views
Replies
Total Likes
Hi,
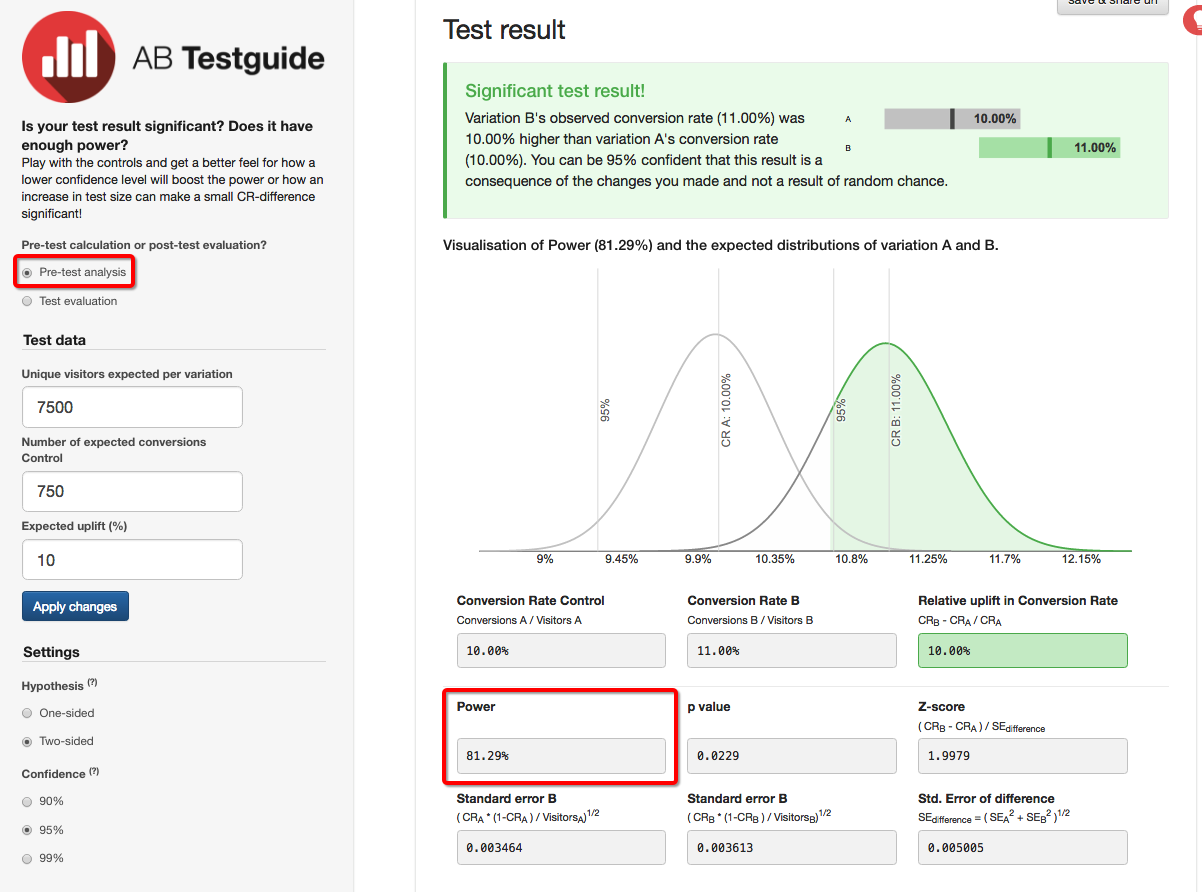
I am still thinking about this. The following Sample Size Calculator seems to be using the same mathematical model to estimate the size as the one used to calculate the significance.
For instance, these values represent a significant test result:
Unique visitors expected per variation: 7500
Number of expected conversions: 750
Baseline CR: 10%
Expected Uplift: 10%

However the Adobe Sample Size calculator, estimates a needed sample of almost the double (14748 visitors per variation)

What is the mathematical model behind the Sample Size Calculator? Because it seems obvious that it is not the same used to calculate the significance level.
Views
Replies
Total Likes

Views
Likes
Replies



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}