
Stream Processing at Scale within Adobe Experience Platform
Authors: Alexander Falca, Constantin Scacun, Eleanore Jin, Douglas Paton

This blog is next in the series of how Pipeline powers Stream Processing in the Adobe Experience Platform. We take a deeper technical look into how we approached Stream Computing and unlocked it as a service for our clients.
Introducing Adobe's streaming compute framework: Smarts
Adobe Experience Platform Pipeline processes roughly 15 billion events a day. While this is an impressive number from a technology point of view, each one of these events needs to be processed in a way that is meaningful to our customers. The problem was that the sheer volume of events creates a huge amount of manual work for people.
Along with the manual aspect of the work, it was virtually impossible to do any of the work, without the involvement of a developer who could produce the code necessary to properly process and filter the events. This created a situation that was burdensome and time-consuming for our customers.
This led to customers asking us how we could enable our customers and developers to easily process these events, and how to lower operational burden and let them focus on business logic. We've listened to these questions and now we have a solution: Smarts.
Smarts is Adobe's Streaming Compute framework based on Apache Beam.
With Smarts, users can rapidly create data flow apps by allowing dynamic operations on messages in a topic through an intuitive step-based workflow. Currently, Smarts is used within Adobe Experience Platform to power all Real-Time Customer Data Platform workflows.
Why Apache Beam?
Apache Beam provides a unified programming models for defining both batch and streaming data processing pipelines. It also has support for a variety of languages that are popular in Adobe. At a high level, Apache Beam can be split in programming and execution models.
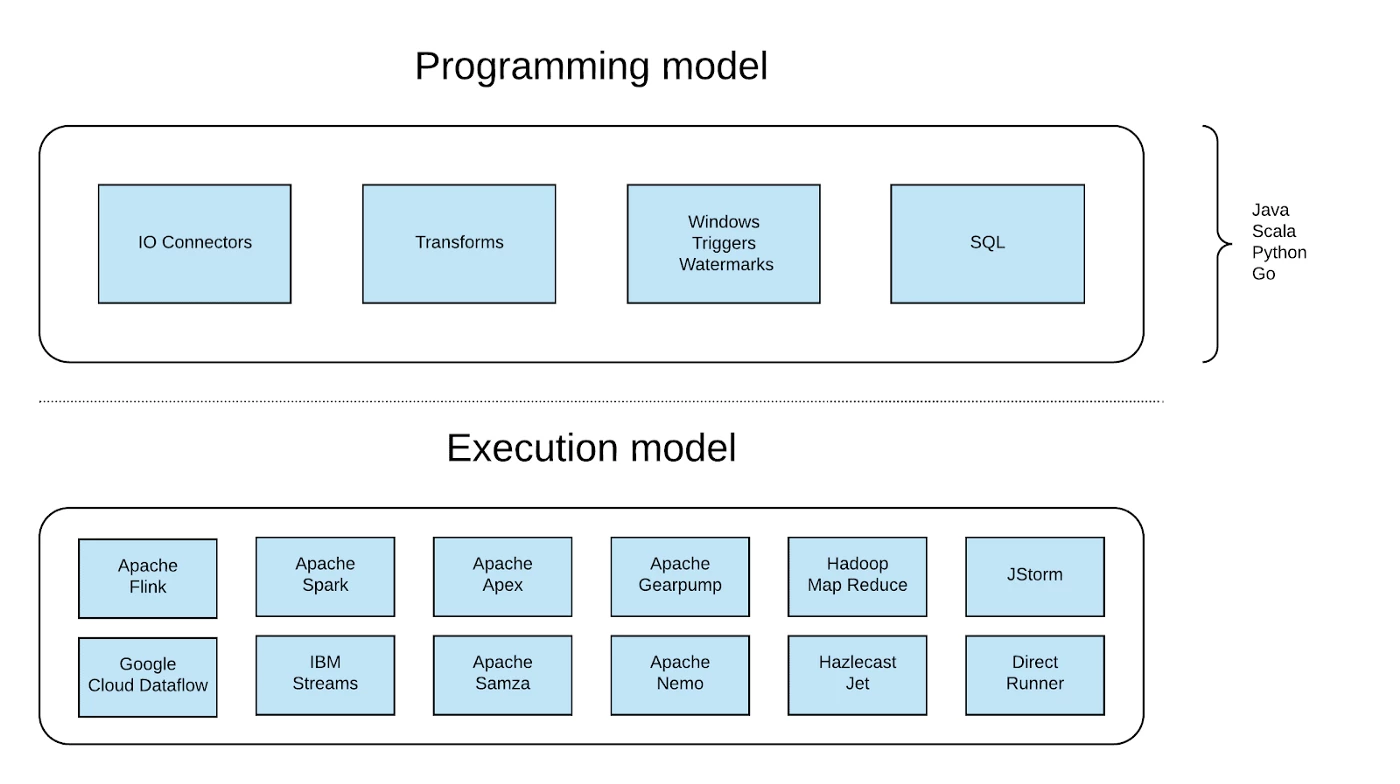
The Programming Model is very rich in provided abstractions. The I/O connectors are file-based for messaging and databases, and provided support for more than 25 connectors right out of the box, including Apache Kafka, AMQP, MQTT, File, and Avro.
This helps transform and represent processing logic with per-element transformations (filter, map, flatmap) and allows for aggregations (count, max, mix, among others) as well as custom-written transformation.
It also provides functionality for windowing, triggering, and watermarks to use the ability to divide elements based on things like timestamps to help define when results are emitted to the step and for dealing with data that arrives late.
Finally, Beam SQL allowed for querying of bounded and unbounded data using SQL statements.
Execution model supports a variety of processing engines, called Runners. Beam pipelines are converted into engine native applications/programs and submitted for execution. Not all features are supported by each Runner, most complete ones are Apache Flink, Apache Spark, and Google Data Flow. See the capability matrix: https://beam.apache.org/documentation/runners/capability-matrix/
Extensions to Apache Beam
Smarts introduces extensions to Apache Beams capabilities, focusing on some unique features important to Adobe.
Extensions to the programming model
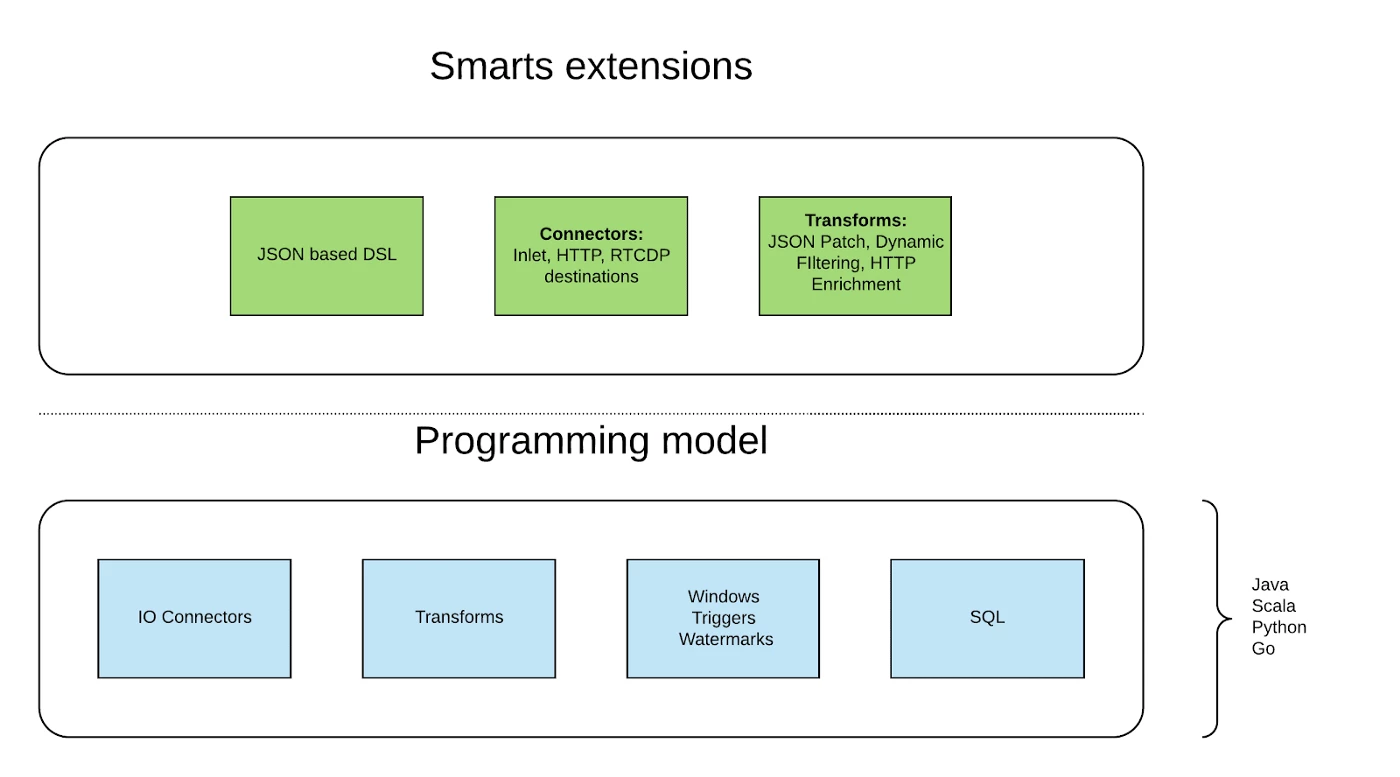
JSON based DSL — for defining processing pipelines. This provides a lower barrier to entry for non-technical users, allowing them to quickly get started with simple streaming definitions
Connectors — Adobe specific connectors, supporting concepts from like Data Collection, Real Time Customer Data Platform(RTCDP), for example.
Transforms — additional transformation supported out of the box: things like JSON patch and Dynamic filtering.
Extensions to execution model
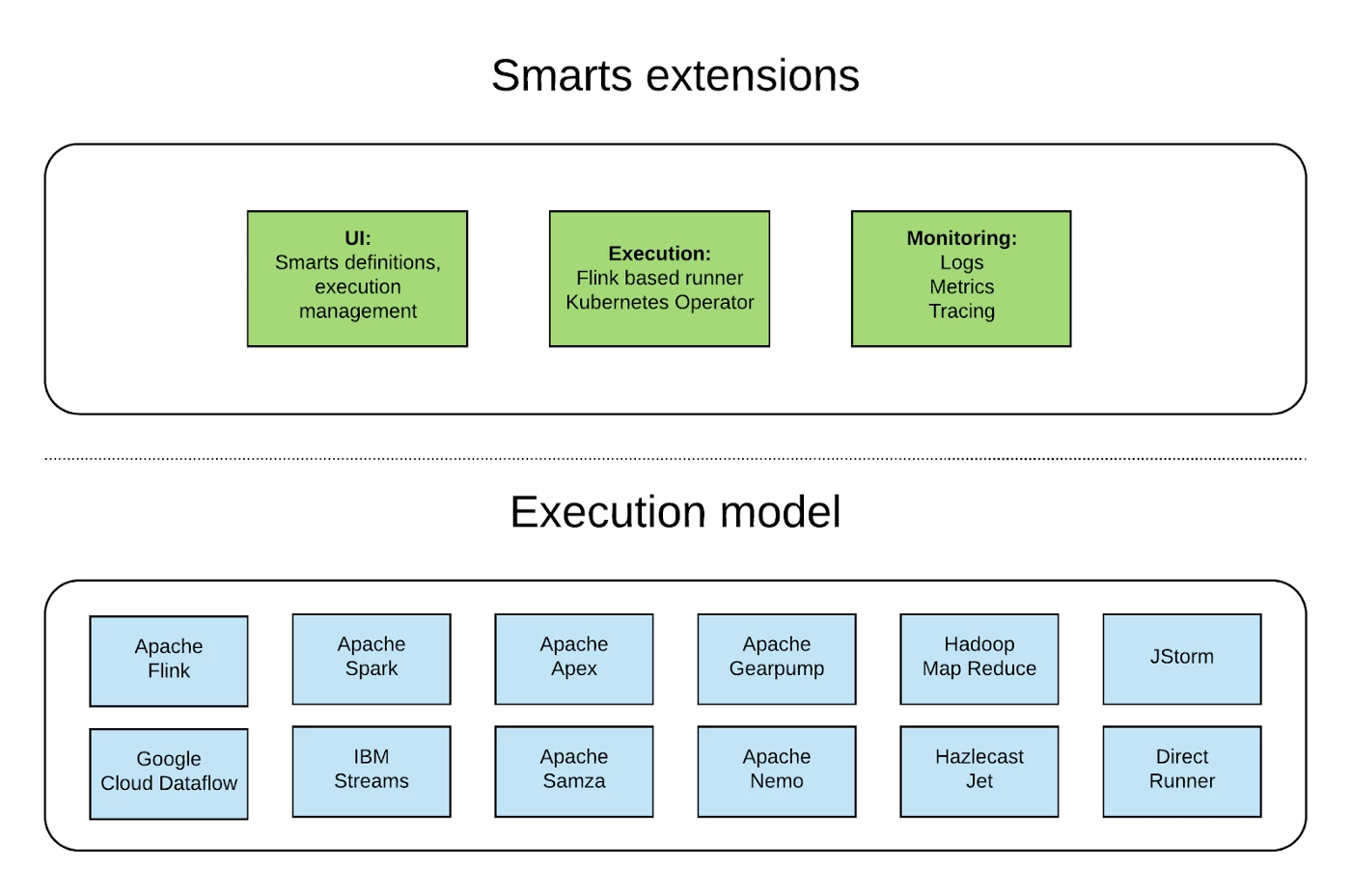
UI — managing Smarts definitions and execution.
Flink based runner — integrated and tuned for our infrastructure. In case you missed it — read this excellent blog post from our colleagues at Adobe that shows why Flink won the race of real-time stream compute frameworks.
Kubernetes operator — easily manages Smarts running instances.
Monitoring — out of the box support for metrics, logs and tracing, integrated with Adobe Experience Platform.
Architecture
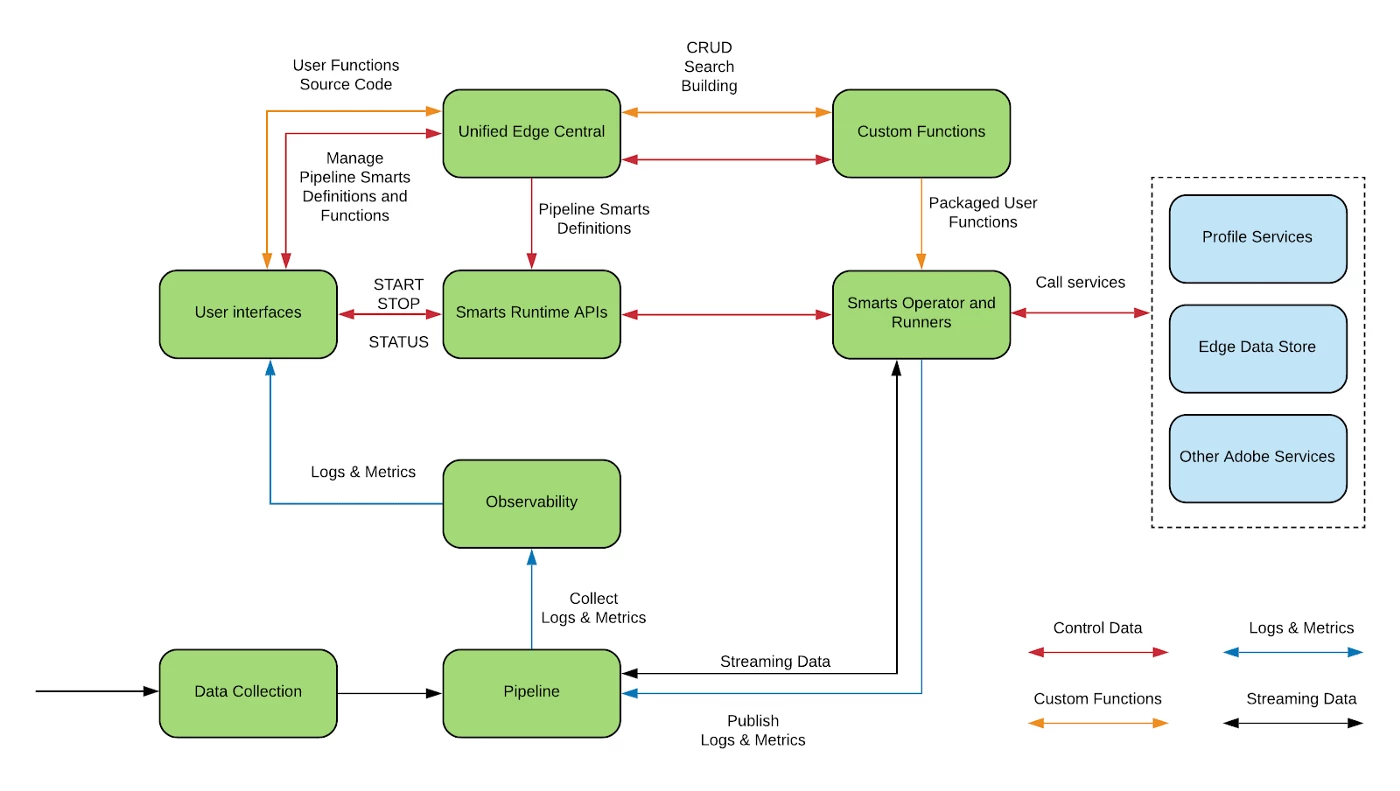
Smarts is comprised of several decoupled microservices and APIs:
- Unified Edge Central — microservice for storing and managing Smarts Definitions. The definitions are saved as a custom JSON DSL (domain-specific language ) that decouples us from the underlying implementation.
- Smarts Runtime API — user-facing APIs for managing the execution of Smarts.
- Smarts Operator and Runner — Operator Framework based microservice for managing deployments of Smarts Runner instances.
Smarts Runner execution flow
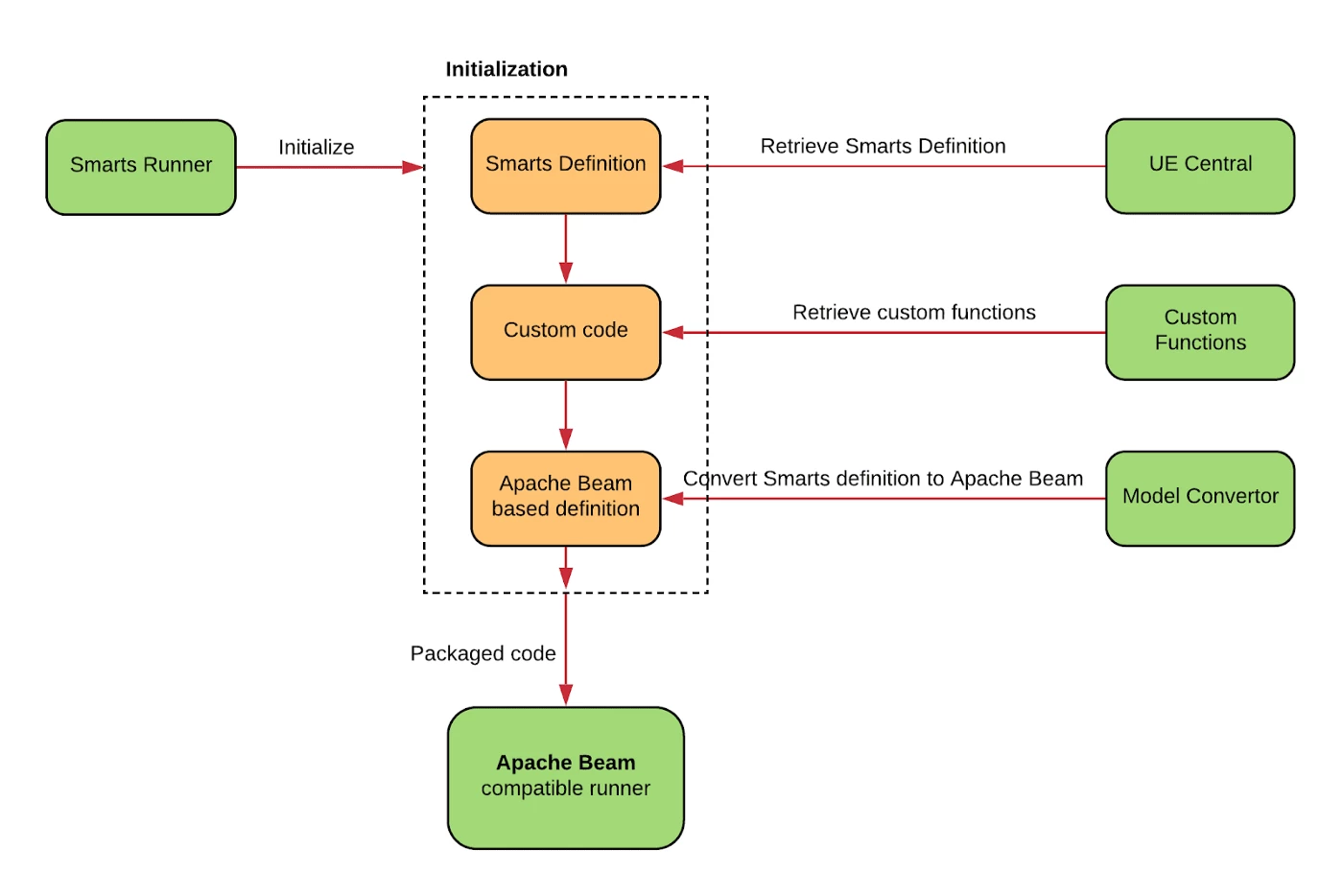
Smarts runtime service brings together deployment artifacts during process initialization. The Smarts definition is downloaded, along with the latest versions of the Smarts Runtime Container and any referenced dependencies.
Any custom functions downloaded from a trusted artifactory location are subjected to security scans before being embedded into the final executable container.
The resulting executable is packaged as a Dockerized process and is directed into an Apache Flink cluster spun up in a dedicated namespace defined by the smarts definition.
Isolation of the processing allows us to scale each Pipeline Smarts process independently and accurately estimate the cost of operating a smarts workflow while being able to meet the stringent security standards for custom code execution.
Kubernetes operator for Smarts
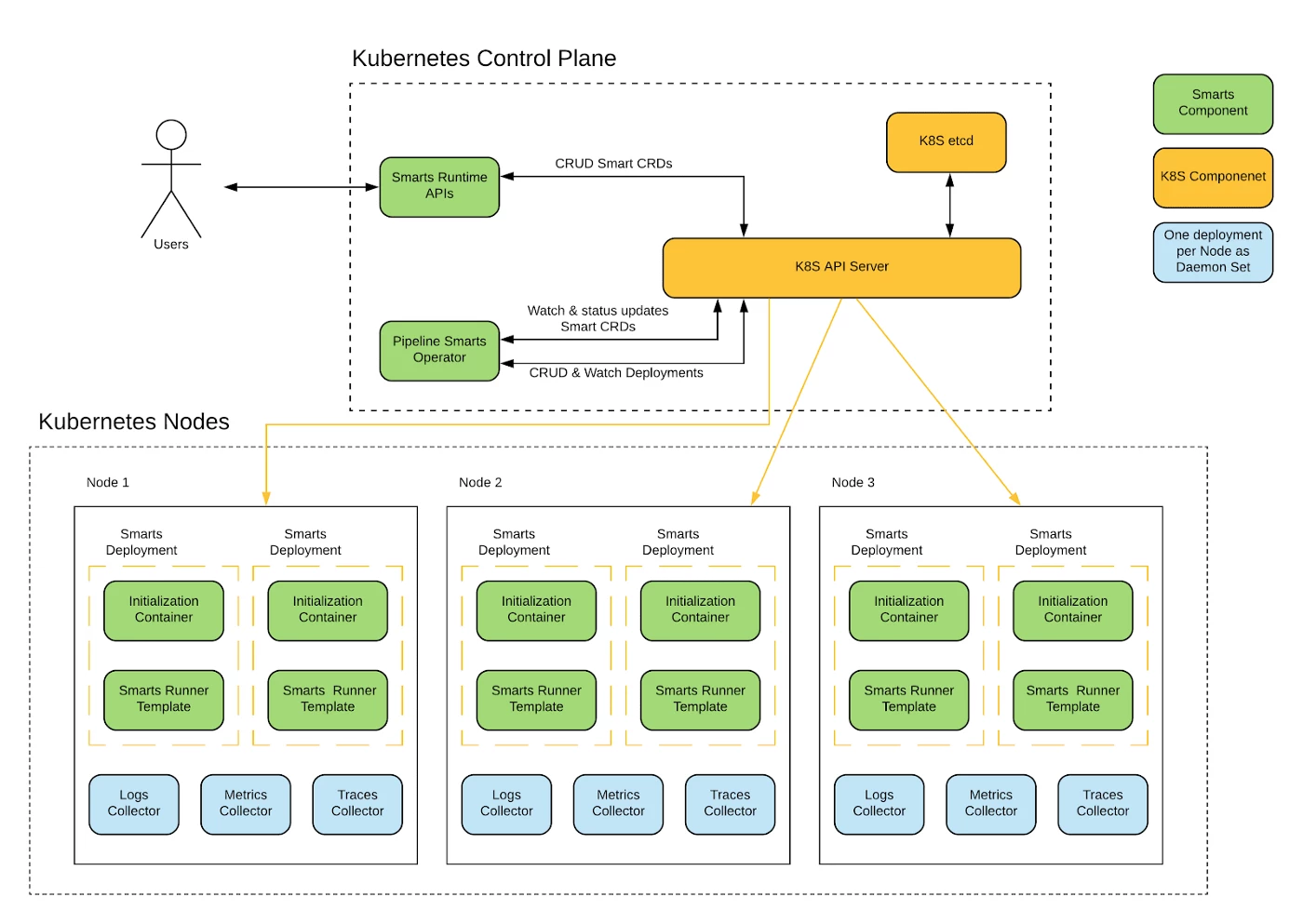
Kubernetes is a natural choice for running containerized workloads, and Smarts exploits the Kubernetes operator framework design. Smarts Custom Resource Definition (CRD) is created by API layer and Smarts Operator encapsulates logic for deploying.
Each Smarts deployment is a set of Apache Flink task and job managers, running in job cluster mode. The Smarts runner template is designed to scale the Flink job managers horizontally based on the workload determined by criteria such as the incoming Kafka topic lag or the CPU utilization in each worker node. There is also an option to scale Flink cluster by simply updating replica count Smarts CRD.
What this means for users
All this new tech has allowed us to simplify the way our users filter their data, it removes the manual aspects of the ETL process, and most importantly, it lets people focus on the data and events that are truly relevant to them. Instead of having to manually dig through their data and bring in a developer, our customers are now able to self-provision. The result is less work, less cost, and more time focused on business logic.
Smarts brings real-time composability of event streams to all Adobe Experience Platform customers. By bringing computation closer to real-time event streams, our customers are able to react to high-value events immediately — thereby giving them the edge they need to get a significant advantage over their competition.
Conclusion
Where we're going from here
Smarts brings real-time composability of event streams to all Adobe Experience Platform customers. By bringing computation closer to real-time event streams, our customers are able to react to high-value events immediately — thereby giving them the edge they need to get a significant advantage over their competition.
Smarts has proved to be successful in solving a number of use cases we are fOur customers loved the simple and easy way of spinning the streaming processing pipeline, without any programming skills required. We will continue focusing on lowering the entrance barrier, enabling other teams at Adobe developing data processing pipelines.
As we were going through the process of developing this, we noticed that a similar service could use the in-flight processing tools that we had developed. Validation Services had similar needs, and we're in the process of porting our solution over. This way there is no need for any new codebases to eliminate the need to look for a solution, and allows for a better validation process.
To learn more about in-flight processing in Adobe Experience Pipeline, check out our previous blog post on how we built the service.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Adobe Experience Platform: https://www.adobe.com/experience-platform.html
- Adobe Experience Platform Customer Data Platform: https://www.adobe.com/experience-platform/customer-data-platform.html
- Apache Beam: https://beam.apache.org/
- Apache Flink Runner: https://beam.apache.org/documentation/runners/flink/
- Apache Flink: https://flink.apache.org/
- Kubernetes: https://kubernetes.io
- Kubernetes Custom Resources: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
- Kubernetes Operator Pattern: https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
- Google Data Flow: https://cloud.google.com/dataflow/
Originally published: Nov 21, 2019