

Modeling One to Many in XDM on Adobe Experience Platform
Authors: @danny-miller , Shruti Jagtap, Douglas Paton

In this blog, we look at how modeled a one to many relationships in XDM for Adobe Experience Platform. We discuss the options we had for modeling and the surprises that came up along the way.
This blog details a single implementation or customization on Adobe Experience Platform. Not all aspects are guaranteed as general availability. If you need professional guidance on how to proceed, then please reach out to Adobe Consulting Services on this topic.
One-to-many (1:M) relationships are everywhere these days. We sign up for things using different names, email addresses, and user names depending on the product or service we’re using. We create a whole host of mini-profiles that all point back to us.
This creates a situation where multiple profiles online can all be attributed to a single person. The challenge is that most 1:M profiles end up looking very similar to Figure 1.
Not surprisingly, something like that can be fit into a standard relationship model. Translating a 1:M relationship into the Experience Data Model (XDM) on Adobe Experience Platform is something of an art form. Everything in Figure 1 can be related back to a single person, someone who has value as a customer. With the right data modeling in place, it’s possible to gain a deeper understanding of that person’s preferences, products they’re likely to purchase, and services they may need, among other things. And it’s possible to make highly targeted offers to those customers based on that information.
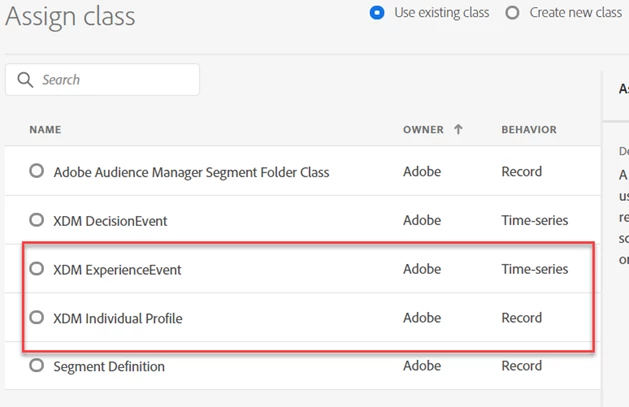
Within XDM, there are a couple of options for storing 1:M data. We can use record data (XDM Individual Profile) or we can use time-series data (XDM Experience Event). In general, storing the information as a profile is a single identity (one person), while events are actions that have some business value (someone purchased product X, for example). As we’re modeling the data, we try to keep everything as one of those two types.
How we went about creating 1:M models
Our basic approach for modeling 1:M boiled down to three different options. We could use Multiple Distinct Attributes, Arrays, or Events. Let’s take a closer look at each of these options:
- Multiple Distinct Attributes — This is something of a brute force approach. It works, but it is very rigid. There is one column for everything. Any time new information needs to be added, the whole schema needs to be updated. As an example, if someone has five phone numbers and the schema only allows four, we’d need to modify the schema to add the fifth number.
- Arrays — Arrays give you the ability to define a set of attributes for each instance in the array. The schema does not need to be modified every time new values come in, but a whole new array is needed for each update.
- Events — With events, there is an easy to understand, highly flexible schema to work with. We can have a specific schema for each event, which allows us to introduce and manage schemas independently from one another as well as the profile. Each event can have its own dataset as well allowing for each source system to feed in data independently from other events.
Games owned vs. games played
A good way to understand how we model 1:M is by comparing the idea of games owned and games played and purchased. Video games are a good way to visualize the 1:M idea generally because a lot of the time, the identity we use to buy the game, is different from the identity we use to play the game, which is different from the identity we use to talk about the game on social media. But everything routes back to a single person. Having a Unified Profile and identity graph helps bring all this together.
The original idea was to model games owned as an array. This made sense in that an array represents the current state, which is “I own these games.” Upon further investigation, we asked, what do you want to do with this information? The answer was, “I want to email people who play game Z.” This was a switch in context from owned to played. So we backtracked what “owned” meant into two pieces of information:
- Purchases
- Usage
Since both of those data points were technically events, we had to think about switching our context from an array “current state” to events “point in time behavior” and infer ownership (if we needed to at all). We also noticed that sometimes the model we were using had to be changed because of data feed limitations.
This is where using events and adding games played into the equation helps. When you do this, you not only know what games were purchased, but you then have data around what games are being played on what devices and how much time is being spent on those games. The profile becomes more complete and you have the ability to then make targeted offers based on that usage.
Some patterns that we’ve noticed
While we were working on this we noticed that M:1 relationships tended to end up being multi-entity (lookup) relationships. This created a situation where we could go beyond the profile with additional data based on things like products, stores, game details or other non-profile classes. This allows us to create segments based on that data, which could be based on something like details found within a video game, for example.
With 1:M relationships, they ended up as either arrays or events, as we’ve discussed. What we noticed was that arrays could have multiple values for the current state (multiple newsletter subscriptions, for example). But, to add to or remove from the array, you need to restate the entire array (which may be a challenge).
Events, we noticed, were identifiable because they had timestamps in the source system. They had an advantage in that they could have events added without the need to pass in previous events. But this could put more of a challenge on how you build segments.
What is interesting when dealing with arrays is that when you’re updating the same user’s profile from the same dataset, the array gets replaced. But, when you update the same user’s profile from two different datasets, the array gets concatenated based on the two datasets. This means that instead of replacing everything, it keeps both. This concatenation was something that we hadn’t expected and was, in fact, a question asked by the client.
Managing multiple personalities and merge policies
As we’ve already mentioned, people tend to use a lot of different identities, or multiple personalities, as they use different products and services. This could be something as simple as signing up for one product using the name “Doug” and another using “Douglas”. Or, it could be more complex, like using different phone numbers or email addresses across a variety of platforms.
This is fine when business units keep their own separate user profiles or if they have a mobile device management (MDM) program in place to reconcile these multiple profiles into one master profile. But if you want to maintain a consistent marketing touchpoint with the customer, you need to consider using merge policies to gather up these various profiles into one unified profile. For example: if each business unit (BU) is capturing data independent of each other and that BU wants to continue to use its version of the profile, Adobe Experience Platform needs to preserve it and provide it back to the BU. Merge policies help here.
Merge policies can be challenging to maintain as you create more and the number of datasets grows. They are applied to each segment, so you will need to remember to select the correct one for each segment built. As an aside, this may mean you end up creating segments with the same rules but with different merge policies.
The next steps in modeling 1:M relationships
The next step for us is to figure out additional use cases for modeling 1:M. We know we will encounter 1:M and M:1 relationships in every implementation we encounter, so we are looking to take things to the next level. We are looking for patterns beyond the basics. We’re looking for patterns for use cases, industries, custom classes, and ramifications when building segments or activating to external platforms. Each of these decisions when modeling the data has both upstream and downstream impacts. The data model is the core and if we don’t get it right, it will cause issues.
We also have to answer a fairly interesting question around just how much historical data we need. Is it necessary to capture and store the entire history of one person across the customer ecosystem or do we really only need to know the current state? Since the goal is typically activation from a marketing perspective, knowing the entire history isn’t necessarily critical. Behavior over a year ago is less valuable than recent behavior. In many cases the current state is more important for determining how to manage the relationship.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Resources
- Experience Data Model (XDM) — https://www.adobe.com/experience-platform/experience-data-model.html
- Adobe Experience Platform — https://www.adobe.com/experience-platform.html
- XDM Individual Profile and XDM Experience Events — https://www.adobe.io/apis/experienceplatform/home/xdm/xdmservices.html
- How to Capture Latest Experience Event in Adobe Experience Platform and Learn Dynamic Segmentation at the Same Time — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/how-to-capture-latest-experience-event-in-adobe-experience/ba-p/430941
- Merge policies — https://experienceleaguecommunities.adobe.com/t5/adobe-experience-platform-blogs/how-to-capture-latest-experience-event-in-adobe-experience/ba-p/430941
Originally published: Mar 12, 2020