
Iceberg Series: ACID Transactions at Scale on the Data Lake in Adobe Experience Platform
Authors: Filip Bocse (@fbocse), Gautam P. Kowshik, Costin Ochescu, and Shone Sadler (@shone_sadler)

With the first blog of the Iceberg series, we have introduced Adobe’s scale and consistency challenges and the need to move to Apache Iceberg. We also discussed the basics of Apache Iceberg and what makes it a viable solution for our platform. Iceberg today is our de-facto data format for all datasets in our data lake.
Although Iceberg is designed for slow-changing datasets our system operates in a high-throughput ingest environment. In the second blog, we have covered our challenges and the solutions we found to accommodate our ingestion throughput requirements.
Read performance optimization was key to the usability of our platform. The third blog focused on how we have achieved read performance using Apache Iceberg and compared how Iceberg performed in the initial prototype vs. how it does today and walked through the optimizations we did to make it work for AEP.
For every data management system besides reading and writing data, you have to account for data restatement operations too. In this article, we are going to cover the challenges and our solution to the use-cases fulfilled through data restatement operations.
Data Restatement
Data restatement is about mutating data through DML operations (update, delete).
A batch related to data restatement is a chunk of data realized as one or more input files sent by a producer that is promoted into a data lake as a single transaction. This refers to the property of having either promoted the data in its entirety or failing it in its entirety.
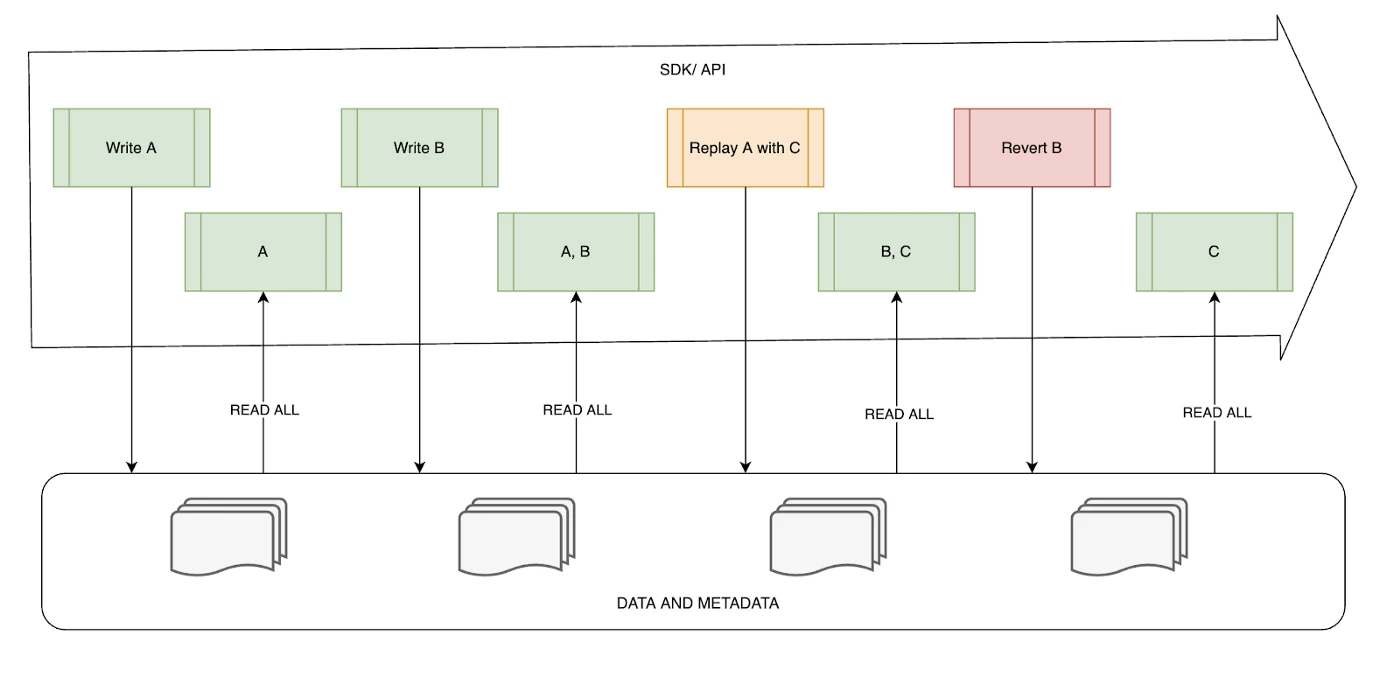
Clients can monitor the status of their batches using Adobe Experience Platform’s UI and/or through Catalog’s APIs. In the case of our data lake system, the data ingestion and data restatement APIs are batch-centric. Today, the only way to express data restatement is through batch replay and batch revert operations (more details in the first article).
The data sent within a single batch may be spanning across multiple partitions. A partition is a specific property of the data that we choose to rewrite the data by. Say for example the client sends over a file that contains thousands of entries belonging to only three distinct dates, we will proceed and split the data by that column. This column is also known as a partition column. It will result in the writing of three distinct data files each containing rows for only one particular date value.
Iceberg stores the particular scalar values for each of the partitions of each of the data files it tracks so it does a great job at finding very fast the data files that qualify for queries that filter on specific partition column values.
Each batch operation has a unique identifier and can be used to trace data in our system for reading, deleting, or restatement (via a new batch) through the Platform APIs.
There are multiple reasons for data restatement and to name a few of the important ones:
- Customers patching their data (i.e. fixes)
- Accommodate compliance regulations that may have serious legal and financial implications unless implemented properly (i.e. GDPR)
- Accommodate system data operations that account for storage optimization and/ or faster access patterns (i.e. data compaction)
Restatement Challenges
Scale requirements
- The average number of batch replay operations is ~3 thousand per day (peaking as high as 18,000).
- The average processed rows are ~10 billion per day which amounts to ~2.5 terabytes of data.
- The distribution of batch replay operations is heavily skewed to a few high throughput datasets (one particular dataset absorbing ended up absorbing 15 thousand replay operations during the previously mentioned spike).
- Current usage projections indicate that we need to plan for 100s of thousands of restatements for any given dataset in the next year or two.
- All the metrics presented here are gathered based on a 30 days interval.
Suboptimal scheduling
To compensate for the lack of atomic commits one approach was to attempt to coordinate multiple writers to sequentially operate on the data — but this introduces constraints dictated by general challenges of resources and costs scheduling in computing and optimizations require complex solutions.
Suboptimal performance
To support data restatement operations we used to rely on a copy on write approach that led to costly write amplification edge-cases as our data operations landscape grew in size and complexity.
The copy-on-write approach we initially had considered to implement data restatement involved (potentially heavy) data processing.
As data was being pushed by clients it was also being rewritten by system jobs such as compaction which targeted read path optimizations. A side-effect of compaction was that it was aggregating rows with the same data characteristics (i.e. partition values) but with different external characteristics (i.e. ingestion batches).
Apache Iceberg
Apache Iceberg is an open table format for managing huge analytical datasets.
By managing an analytics dataset we are considering challenges such as having to support multiple CONCURRENT WRITERS and having to support ACID CHANGES so readers are not affected by partial or uncommitted changes from writers as well as other general read/write reliability and scalability concerns like schema enforcement, scalable scan planning, and partitioning pruning.
You can think of Iceberg as software that for each data change you make COMMIT it will create a new and immutable table VERSION containing the correct data files reflecting your change as well as the history of previous data changes SNAPSHOTS.
Subsequent readers can access the data reliably since data files and metadata are immutable.
As writers commit new changes Iceberg will keep on creating new and immutable table versions.
There are currently two versions of Apache Iceberg.
- Iceberg format version 1 is the current version. Dubbed Analytic Data Tables defines how to manage large analytic tables using immutable file formats, like Parquet, Avro, and ORC.
- Iceberg format version 2 is a work in progress. Dubbed Row-level Deletes aims to add support for encoding of row-level deletes enabling new capabilities like delete or replacement of individual rows in immutable data files without rewriting the actual files.
Motivation
Apache Iceberg version used by Adobe in production, at this time, is version 1. With this version of Iceberg, we found support for data overwrite/rewrite use-cases were available but they solely relied on data file-level operations. You can explore more details for these APIs such as OverwriteFiles or RewriteFiles.
Our use-case is required to support restating only a subset of rows in a data file. This meant that data replacement operations were still going to face issues when concurrent jobs would attempt to restate rows from different source batches but effectively targeting the same data files.
What would happen is that only one job would succeed at a time and determine all other conflicting jobs to retry causing write-amplification side-effects, accounting for wasted compute, and increasing the risk of failure on the right path.
We concluded early that our use-cases didn’t match the support we got from those APIs and we started to evaluate alternative implementations that would entail support for data restatement without the need to rewrite data files on the write path.
The result of that exploration work was the Tombstone Extension.
Note: Row-level support was still in the early phases as the specification was just being introduced to the community at that stage. Striking a balance between performance and functionality can be difficult. The community has been pushing to deliver the support for row-level operations for a while and the results are showing for this major milestone. You can also read more about Iceberg v2 here.
Tombstone Extension
A tombstone is the information that identifies one or more deleted rows.
Tombstone is our internal implementation of a merge-on-read strategy to fulfill our data restatement use-cases.
The following section will cover the implementation details of this extension but we should mention that this is not a public API for our customers, they operate with simpler, more efficient abstractions through our SDKs and APIs (Batch Replay/Revert and GDPR).
Adobe applications that run data restatement operations in the Data Lake use our Platform SDK which has the following documented Data Source options.
dataFrame
.option(DataSetOptions.orgId, "<customer.organization>")
.option(DataSetOptions.batchIdsToReplace, "<customer.batch>")
.option(DataSetOptions.batchReplacingReason, "replace")
.save("<customer.dataSetId>")Design Principles
To extend Iceberg to support our data restatement use-cases we laid out some basic requirements:
- ACID compliance
- Efficiency
- Scalability
- Design for convergence to Iceberg v2
- Prioritize on lowering the risk of failures on the critical path of the write operations
What we got from Iceberg’s protocol and design:
- Data files are immutable
- Metadata is immutable (versioned)
With Apache Iceberg we can rely on consistent snapshots of the entirety of the metadata describing the data files for any given point in time, so having a solid guarantee of the snapshot isolation level provided by Iceberg was a great foundation to build on.
For implementing data restatement there are basically two viable options:
- COPY ON WRITE (rewrite data on the write path): No processing required on the read path
- MERGE ON READ (write metadata on the write path): Some processing on the read path data to prune the soft-deleted rows. Some asynchronous processing to optimize for latency and data size.
Having the use-case of high frequency commits that overwrite only a few transactions at a time going with COPY ON WRITE we would have basically ended up with potential write amplification edge cases and also a lot of pressure on the critical path of write operations from system tasks (data and metadata optimizations).
What we considered as the basic design principle for the extension was that all data and metadata operations should be append-only.
- APPEND: Append new data.
- DELETE: Append metadata on how to identify deleted data.
- DATA RESTATEMENT: Append both data and metadata on how to identify deleted data.
So we chose to explore the possibility of a MERGE ON READ strategy to back the implementation of a data restatement over Iceberg’s protocols and APIs.
MERGE ON READ
Going with MERGE ON READ was a better fit for our use-case which required us to accommodate multiple concurrent data restatement operations since this meant basically turning data restatement operations into basic metadata append operations. These are additive in nature and provide a lot of room in terms of parallelization and further optimizations. The design is based on various other implementations for similar support and it is more familiar when explained using terms such as tombstone or soft delete.
In basic terms this strategy involves three distinct operations:
- WRITE PATH: Support atomic commits of data and tombstones to identify soft-deleted rows.
- READ PATH: Support pruning of soft-deleted rows and provide a correct view of data.
- VACUUM: We need to account for the fact that deleted rows wouldn’t get removed from the system immediately (during the write operation) but only later, by a separate process, this will optimize for latency and cost of both read and write paths.
WRITE PATH
At the lowest level, tombstone data is maintained in immutable files (Avro).
Snapshots continue to pass on their tombstone reference to newer snapshots along as the tombstone set isn’t altered. A new tombstones file is created when a change of tombstones happens (replay, delete, and vacuum). It is then used as a reference by the latest snapshot.
Tombstones are represented as a pair of a column identifier (i.e. for Iceberg it is the field id) and a corresponding value (for our use-case is the batch id we are restating). We also store particular metadata to optimize operations such as data optimization that are running on a different execution path than read or write paths.

id: Contains the actual value of the tombstone.namespace: Used to group alike tombstones (the tombstone field id value).addedOn: Tracks tombstone recency.evictBy: Tracks eviction requirements.meta: Stores metadata for other functional requirements (i.e. incremental deletes).
One key aspect was to preserve the originating snapshot id for each of the tombstones we set on the dataset. This metadata is critical for the incremental read of deleted rows feature in that it provides strong guarantees in preventing data duplication issues and provides a correct representation of the deleted rows when we materialize upon request.
At the representation level of Iceberg, each snapshot points to at most one tombstone data file that contains all the data needed to identify the soft-deleted rows contained by the data files present in the snapshot.
If the snapshot is a basic append snapshot then it will inherit a reference to its parent snapshot own tombstone data file (in Figure 3 see API for “Append D”).

The exception to this rule is snapshots created by the VACUUM operation. These summaries will point to two tombstone metadata files:
- One containing the active tombstones (if any tombstones are left after vacuum).
- One containing the vacuumed tombstones.
We stash the vacuumed tombstone information this way so we can later materialize the deleted rows (snapshot also persists the deleted or replaced data files that resulted from the vacuum operation).
READ PATH
We provide an abstraction layer on a customized Data Source implementation (aka “Platform SDK”) to run data processing operations in our system.
In the context of Iceberg, a tombstone metadata file is a specific file that is stored alongside standard snapshot metadata. At a low level when the SDK reads the data we also perform an “anti-join” operation between the data and the available tombstones available for that same snapshot. The anti-join operation will effectively prune the soft-deleted rows and the result is the correct view of the data.

VACUUM
This process removes soft-deleted rows and corresponding metadata (tombstones) mainly to:
- Optimize storage cost: Data is deleted by the customer but still preserved by the system.
- Improve read performance: Pruning tombstones impacts read performance and latency.
We sort the data by the tombstone column in order to avoid a full table scan on each run. The result of this optimization is that when scanning for data files that may contain deleted rows we get an accurate reading of the data files that match that predicate and successfully skip those data files that don’t contain any tombstone rows.

Following the details in Figure 5 the process consists of the following sequences:
- Users upload data as source batches that potentially span across multiple partitions.
- Data is actively being buffered and partitioned by business event time (
timestamp). - Data is sorted by source batch in each of the timestamp partitions. These source batch values are employed at a later stage to delete or restate the data.
- Write to parquet data files. We use Iceberg which preserves the upper and lower limits of the source batch column.
The resulting upper and lower limits for the tombstone column for data files presented in Figure 5 would be as follows:
- Data file for partition 11–08–2020 (blue) would result in two distinct data files registering tombstone column values ranges as [A,B] and [B,D] respectively.
- Data file for partition 18–05–2020 (yellow) would result in two distinct data files registering tombstone column values ranges as [B,B] and [C,D] respectively.
- Data file for partition 14–05–2019 (red) would result in two distinct data files registering tombstone column values ranges as [A,B] and [D,D] respectively.
At a low level, this is a brief human-readable description of how Iceberg maintains upper and lower bounds for each column in the Avro metadata files.
A visual representation of how upper and lower bounds are tracked by Iceberg (internal representation). Considering all the rows of source batches A, B, C, D, E, and F are written to a single data file then Iceberg will encode the range of the source batch column (i.e. field id “3”) by preserving A and F.
"lower_bounds": {
"array": [
{
"key": 3,
"value": "A"
}
]
},
"upper_bounds": {
"array": [
{
"key": 3,
"value": "F"
}
]
}METRICS
Vacuuming relies on these tombstone METRICS:
- Total tombstone count
- Added tombstone count
- Deleted tombstone count
"tombstone.file" -> "file://..."
"tombstone.metrics.added.count" -> "100"
"tombstone.metrics.deleted.count" -> "0"
"tombstone.metrics.total.count" -> "158"We store the tombstone metrics in the snapshot summary along with the path to the Avro file that contains active tombstones. A tombstone snapshot is specifically generated for a vacuum operation. Here is an example:
"tombstone.file" -> "file://..."
"tombstone.metrics.added.count" -> "0"
"tombstone.metrics.deleted.count" -> "100"
"tombstone.metrics.total.count" -> "58"
"tombstone.vacuum.file" -> "file://..."
"tombstone.metrics.vacuum.count" -> "58"Besides the active tombstone file and metrics, it also records a path to a file that we use to store the values of all the vacuumed tombstones as well as a basic metric of their count.
This was required to be able to provide additional functionality like incremental read of deleted rows.
PROCESSING
Here is a summary of several distinct processing phases of vacuuming:
SCAN: Find data files that match the tombstone predicate (contain soft-deleted rows).PURGE DATA: Removes soft-deleted rows.PURGE METADATA: Removes soft-deleted metadata (tombstone).COMMIT: Creates new snapshot.
There were certain considerations we have made over when and how we would run vacuuming:
- Run ad-hoc vacuum per dataset when needed (leverage metrics).
- Run a partial vacuum over full vacuum (leverage metadata).
We wanted to find a solution for a low-touch (unattended) process that would schedule vacuum operations for datasets that accrue too many tombstones and which may encounter performance issues.
We implemented this by leveraging a Spark Structured Streaming application that tracked the changes throughout the datasets’ respective tombstones metadata and identified which of these datasets was a viable candidate for vacuuming.
SCAN
Vacuuming starts by scanning for the data files containing tombstone rows. The implementation of this scan is offloaded to a Spark Action that basically queries the #files table and finds the data files that contain tombstone rows by joining the tombstones values with the upper and lower bounds of the tombstone column for each data file.
Consider the example of vacuuming ALL tombstones with values from 501 to 600. The sorting guarantees the upper and lower bounds of the tombstone column remain disjunct across the data files.
Without sorting it would mean that the ranges tracked by Iceberg for this column across data files are not contiguous. Scanning for data files based on a discrete value of a tombstone can return a vast number of false-positive matches ending up having to rewrite the entire dataset.

Sorting by tombstone column makes the scanning deterministic since it will generate contiguous ranges across the data files so matching based on discrete values of tombstones will return a drastically narrow set of data files.

PURGE DATA
Once we’ve settled on the data files containing deleted rows we continue with purging the rows matching the tombstone metadata. We apply a left_semi join with the tombstones and prune the tombstone rows.
As an example consider data files generated in Figure 5 and assume vacuuming tombstone value “A”. Here is a deeper dive:
- Looking for “A” to be contained within the upper and lower values of [A,B] [B,D] [A,B] [D,D] [B,B] and [C,D] ranges we identity only two data files.
- One data file containing [A,B] in 11–08–2020 (blue).
- One data file containing [A,B] in 14–05–2019 (red).
PURGE METADATA
Along with vacuuming the tombstone rows from the data file we also have to subtract the tombstones metadata. This operation will generate a new tombstones metadata file with updated metrics and associated with the new resulting snapshot.
COMMIT
So given that there are two possible outcomes of a vacuum operation, we choose the appropriate Iceberg API to commit the change:
- REWRITE FILES: At least one file containing tombstone rows also contained valid rows.
- DELETE FILES: All data files containing tombstones rows don’t contain any valid rows.
Use Iceberg protocol and APIs to perform an atomic commit of both the new data files (tombstone-free rows) and new tombstone metadata as the latest snapshot.
Incremental Deletes
We support incremental reads of appended rows.
=> SELECT COUNT(*) FROM events TIMESTAMP SINCE '2021-01-01 00:00:00';
count(1)
----------
144Incremental reading is supported by providing a temporal range.
=> SELECT COUNT(*) FROM events SNAPSHOT SINCE 8642949070972100074;
count(1)
----------
13608Incremental reading is also supported by providing a temporal or a snapshot range.
We are developing the support to incrementally reading deleted rows. There are two categories of deleted rows that we use to materialize the result:
- ACTIVE TOMBSTONE ROWS (use most recent snapshot identified by the increment): Committed tombstones, not vacuumed yet, actively filtered from queries.
- VACUUMED TOMBSTONE ROWS (that were created in the increment interval): Committed and vacuumed tombstones, no longer actively filtered from queries.
To preserve vacuumed tombstones, the solution was to have vacuum snapshots track two tombstone files: an active tombstones file and a vacuumed tombstones file.
This enabled us to fulfill the materialization of the vacuumed deleted rows by joining the vacuumed tombstones with the deleted data files tracked by Iceberg as part of the vacuum-generated snapshot. Here is the simple formula for materializing all the deleted rows:
deleted rows = active_data_files.join(active_soft_deletes, "left_semi")
.union(vacuumed_data_files.join(vacuumed_soft_deletes, "left_semi"))An important note to this simplified introduction to the solution for incremental deleted rows is that the tombstones accounted for in the previous formula are only the ones that were created on the snapshots that qualify to the increment range. This is a critical aspect for providing no data duplication or data loss guarantees.
Going further
Avenues with high impact for us include extending the current support for tombstone metadata and metrics to accelerate improvements on the read path and the performance of vacuum operations. Here are improvements we are looking at in the near future:
- Encode partitions metadata for tombstones to improve read latency.
- Add support for manual (ad-hoc) vacuuming to accommodate long-tail edge cases.
- Alignment with Iceberg V2 to align with community
- Record level restatement support with Change Data Capture (CDC)
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Related Blogs
- Iceberg at Adobe
- High Throughput Ingestion with Iceberg
- Taking Query Optimizations to the Next Level with Iceberg
References
- Adobe Experience Platform
- Apache Iceberg
- Apache Spark
- Iceberg Table Spec — Version 1: Analytic Data Tables
- Iceberg Table Spec — Version 2: Row-level Deletes
Originally published: Apr 15, 2021