
Using Akka Streams to Build Streaming Activation in Adobe Real-Time Customer Data Platform (Part 2)
Authors: Bianca Tesila, Nicolae-Valentin Ciobanu, and Jenny Medeiros
This is the second of a two-part series in which we explore how to build and roll out data-intensive applications to production using Akka Streams. In this follow-up post, we outline a few key features that we implement for efficient streaming activation within Adobe Experience Platform, along with a use-case that shows these features in action.
In part one of this Akka Streams series, we presented a simplified version of an Adobe Real-Time Customer Platform application that continuously fetches profile updates from an Apache Kafka topic and dispatches them as HTTP requests to an endpoint.
By the end of the post, we had defined our stages, types, and fault handling. The next logical step would be to roll out this Akka Streams application in production, except we first need to ensure the application meets the three acceptance criteria laid out in our previous post:
- Asynchrony: streamline performance and use computing resources efficiently.
- Backpressure: consume data without overwhelming our systems — or those of our partners.
- Resilience: establish safeguards so the application can continue to perform when faced with failure.
In this post, we will outline the Akka Streams features that helped us meet these requirements for a robust streaming activation pipeline in Real-Time Customer Data Platform. We will also share an activation use-case that highlights how these features facilitate smooth and efficient data streaming.
Introducing asynchrony for performance
Before delving into the value of asynchronous boundaries for building scalable, resilient, and efficient distributed systems, we will first define a fundamental concept known as “Actors.”
Actors send messages between independent units of computation and provide a higher level of abstraction that makes it easier to write concurrent and distributed systems. For this reason, actors are the backbone of Akka Streams.
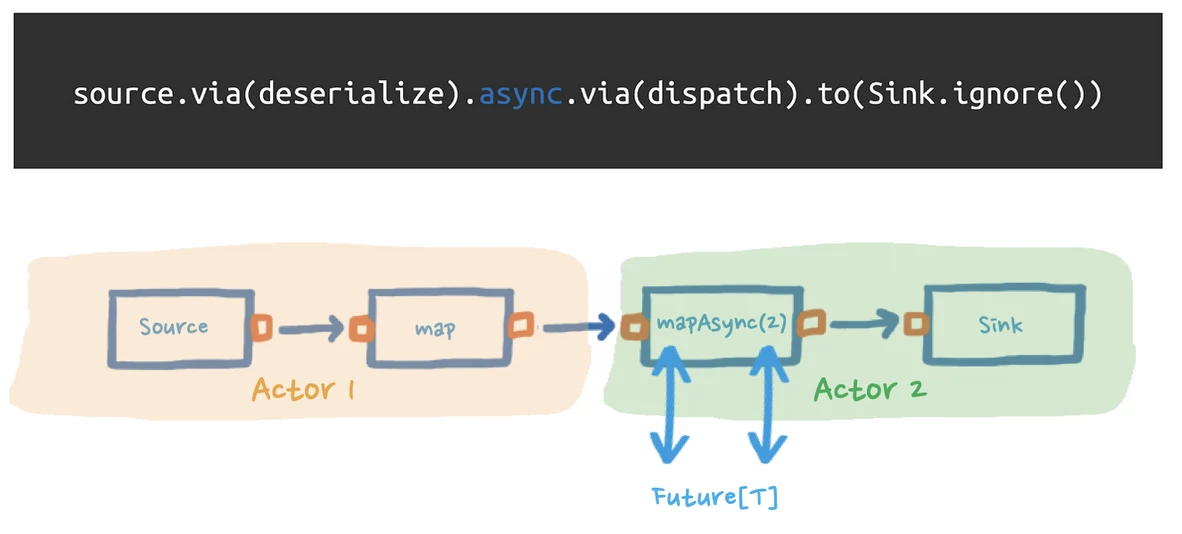
In our <example application>, we have a single stream that is executed by a single actor, as shown in the figure below.
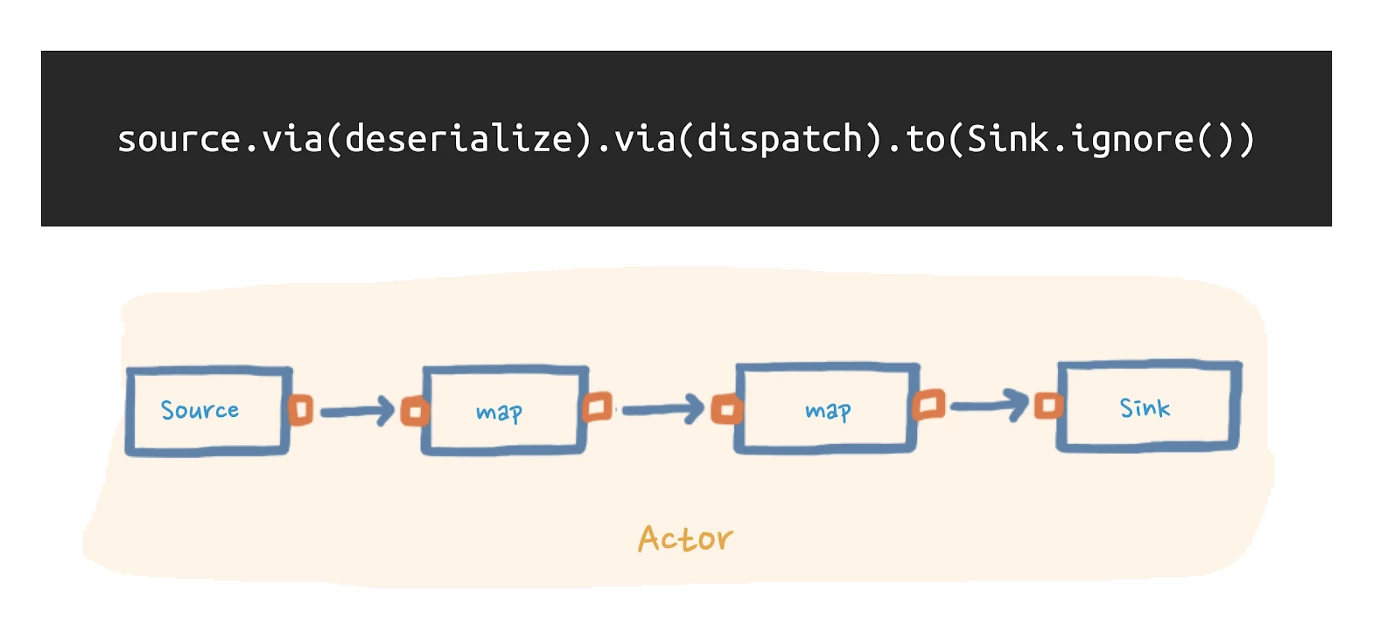
If we were to run this app at scale, however, the vast number of messages our actor would need to process would put a cork in the overall performance. That is unless we introduce asynchrony and parallelism.
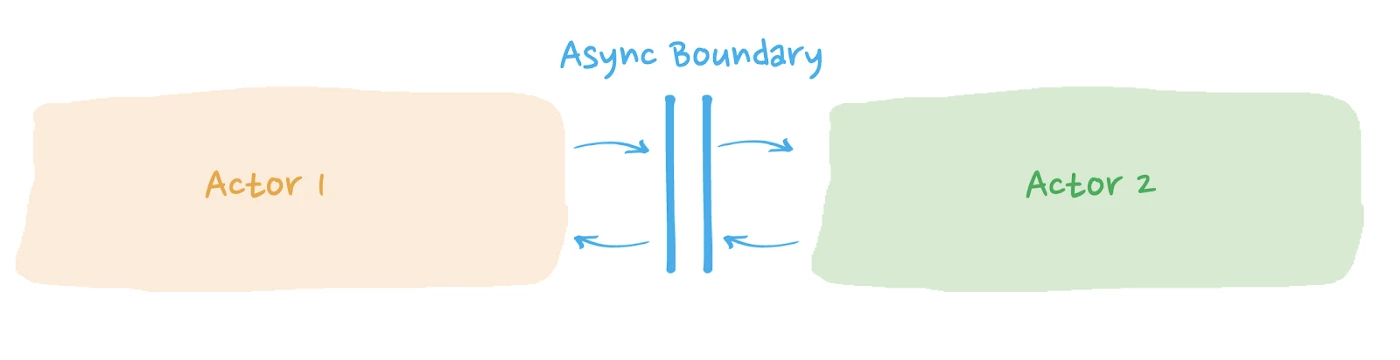
One way of doing this is by introducing an async boundary between the stages of the stream. Essentially, the Akka Streams API inserts a buffer between every processing stage to amortize the overhead message passing among different actors.
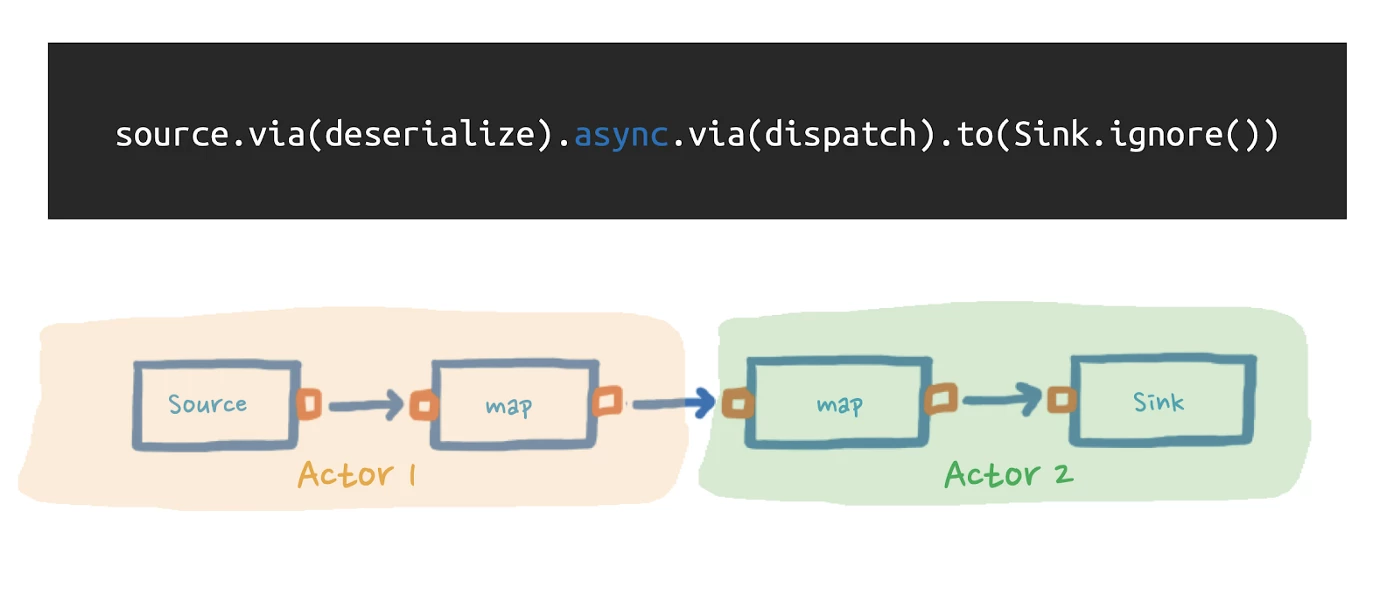
In our application, we needed to introduce an async boundary between the processing of our incoming data and the actual dispatch function. This way, we could efficiently consume data and deal with failures within one actor, while leaving the other actor to communicate with the external endpoint.
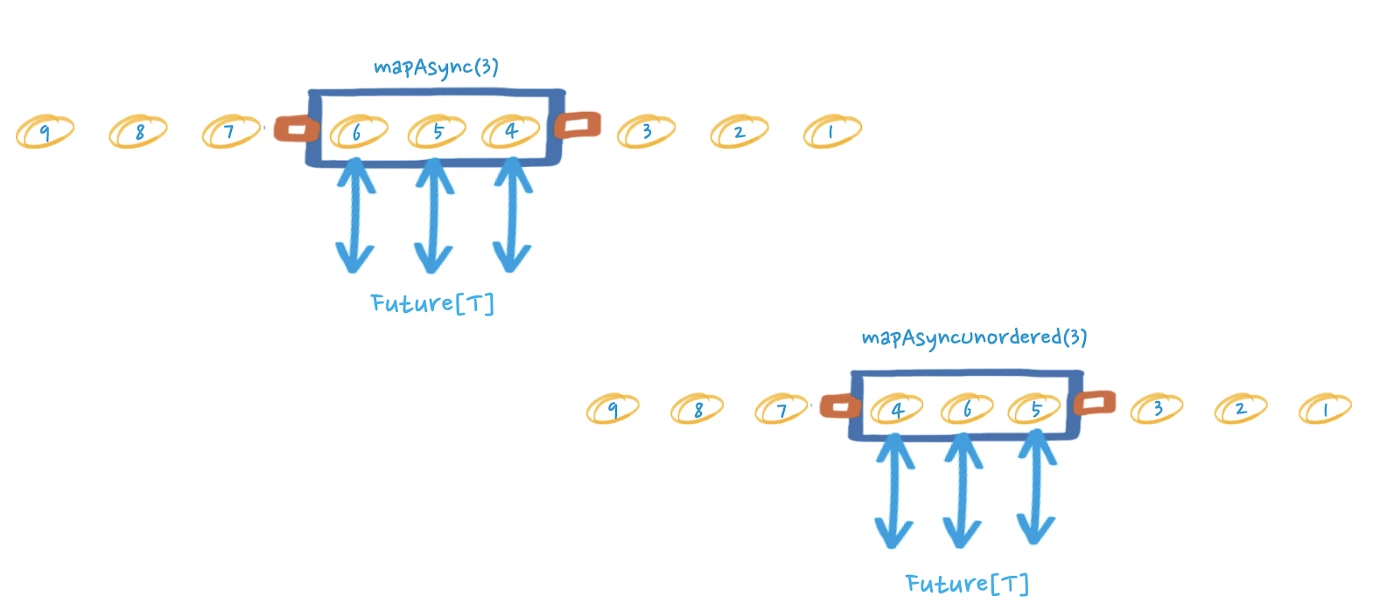
Although async boundaries are not the only way to achieve asynchrony. We can also wrap the communication with the external endpoint in a Future — a placeholder object for a value that may not yet exist. We then used the flow stages mapAsync/mapAsyncUnordered, which manages the completion of the contained Future.
A key difference between mapAsync and mapAsyncUnordered is that the former preserves the order of the input messages (see figure below). This means that the result of a Future will not be emitted downstream until the result of the Future preceding it has been emitted. As such, we can expect the performance to be impacted if any requests take longer to be processed.
In light of this, to optimize our application’s performance we leveraged yet another capability of Akka Streams: explicit user-defined buffers.
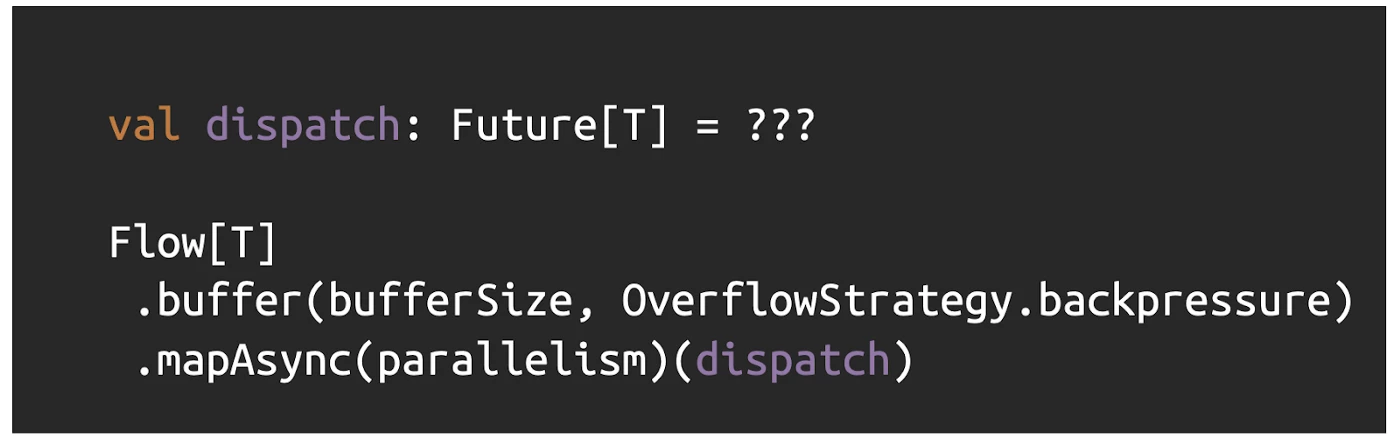
With these buffers, we can queue more requests to be performed as well as decouple adjacent stages to maximize throughput and use our resources wisely.
Backpressure to the rescue
Our next requirement was to carefully consume incoming data so as not to overwhelm our systems, let alone partner systems. For this, Akka Streams comes with built-in backpressure, which is a mechanism that prevents a consumer of events (the subscriber) from getting overwhelmed by the publisher of events.
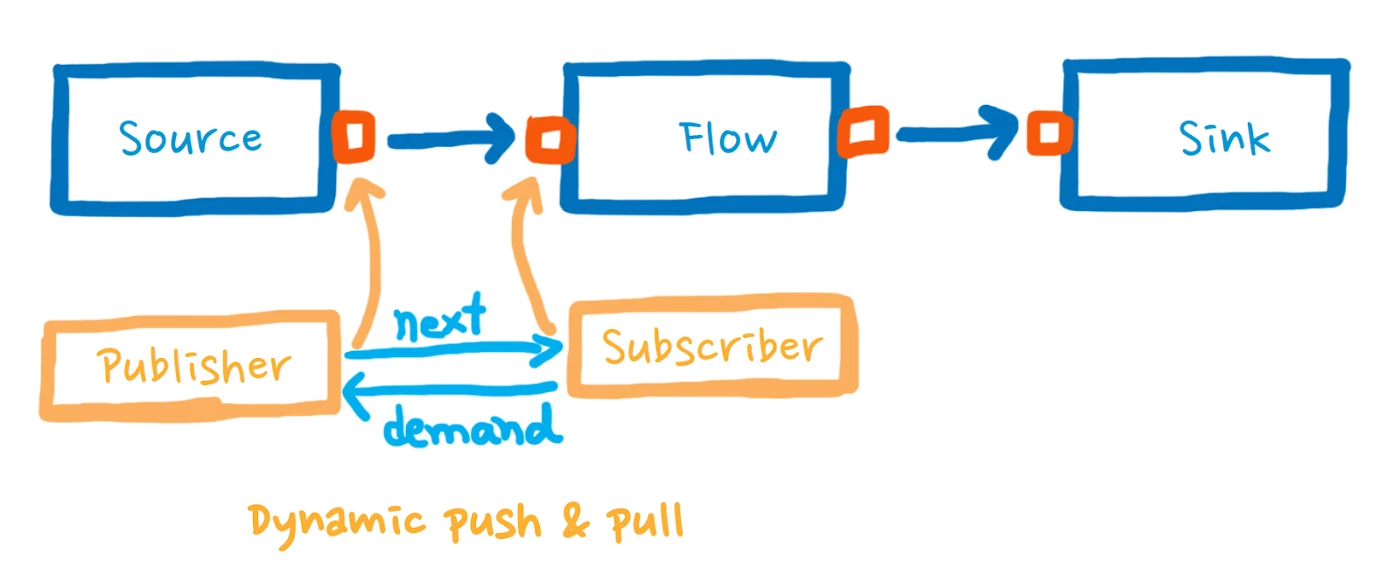
In Akka Streams, each pair of connected stages can be seen as “publisher” and “subscriber,” from left to the right. A subscriber, which always has a bounded buffer, demands from the publisher as many messages as it can buffer at that moment, while the publisher makes sure to not exceed the requested amount.
The key to the publisher not overwhelming the subscriber is establishing a continuous push and pull. Since this mechanism is already baked into Akka Streams, we only had to intentionally preserve backpressure when defining custom graph stages.
Error handling for resilience
In our <previous post>, we mentioned that error handling in Akka Streams can be as simple as adding specialized stages that take care of failure events downstream without disrupting the entire workflow.
But there will always be errors that require additional attention. For our application, we will consider two major scenarios: if the source stream fails, and if the underlying hardware fails.
When the source fails
What happens if we cannot fetch data from the Apache Kafka topic to begin with? While we could wrap this failure into another type of event and keep trying to fetch data, this implies sending even more requests to an already unresponsive Kafka.
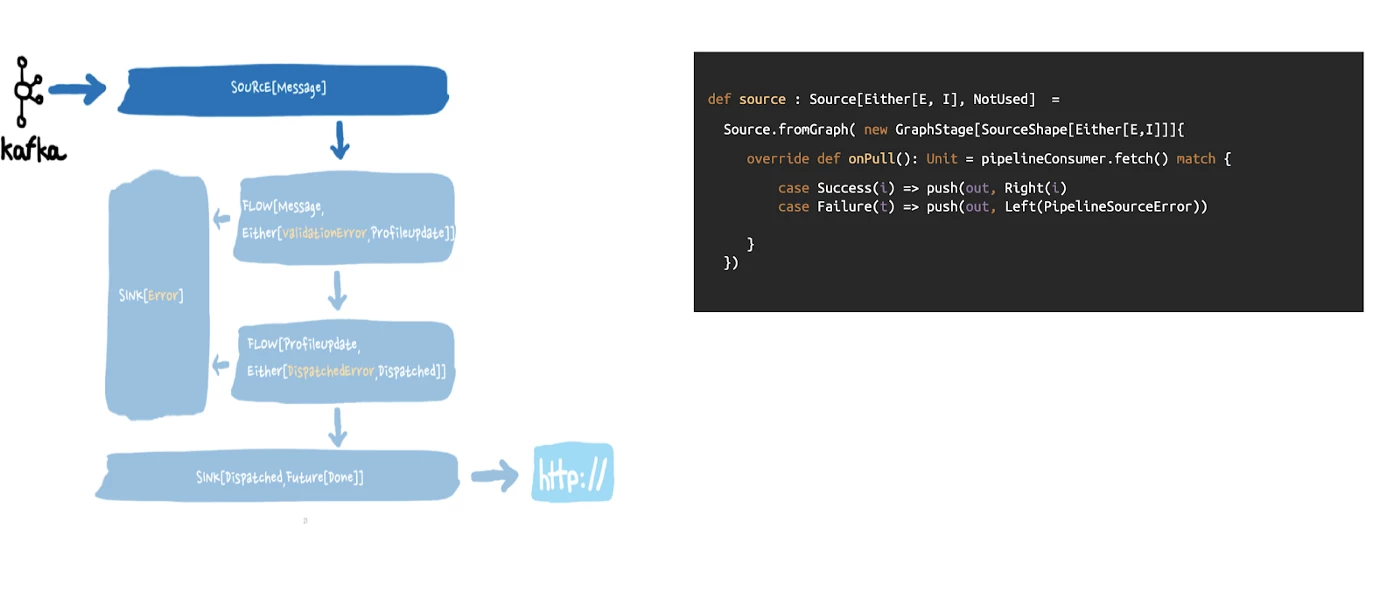
The only remaining option is to stop the stream, but that begs another series of questions, such as how to restart it and when.
For this, Akka Streams provides the ability to define supervision strategies. We can define a strategy to oversee either a specific stage or the entire stream and get triggered when a runtime exception attempts to interrupt the execution. This then provides us with three options: stop the source, resume it, or restart it.
In our case, we chose to define a supervision strategy for the source stage and restart it when interrupted, but with exponential backoff. This ensures we do not overwhelm the Adobe Experience Platform Pipeline API, which we are using to fetch data from Kafka.
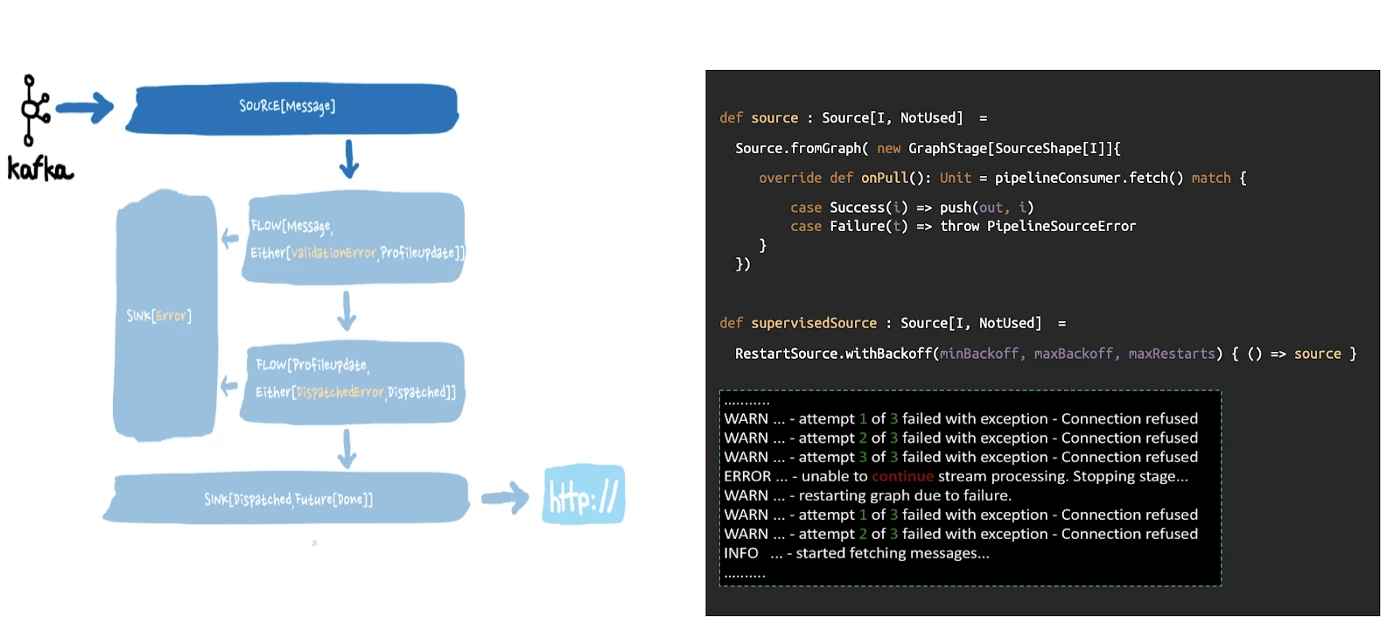
If the restart attempts fail, we let the application shut down gracefully using KillSwitch, which allows the completion of stream stages from outside the stream (e.g. within the shutdown hook).
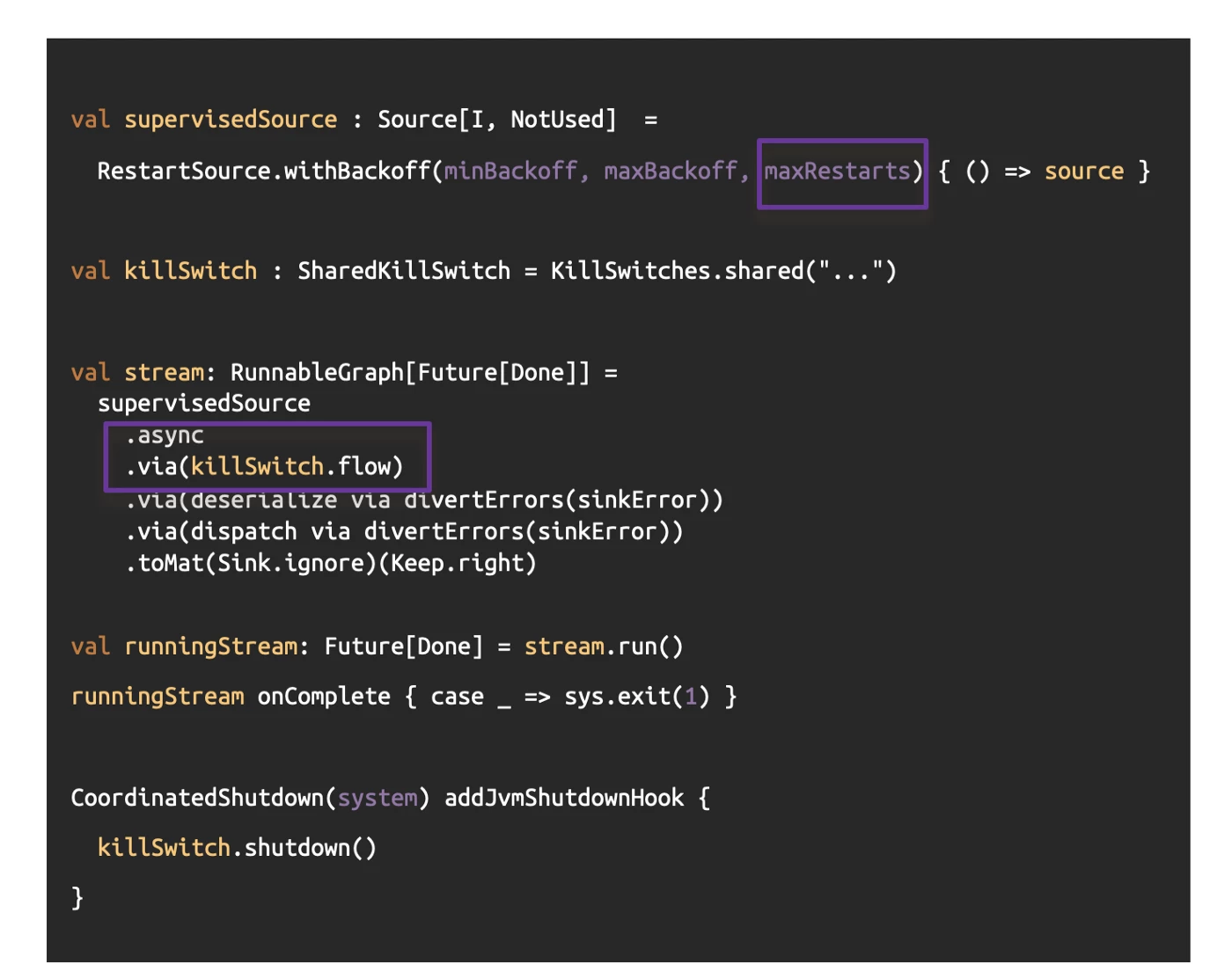
As shown in the code above, we have a supervision strategy that restarts the source with a backoff and a capped number of restarts. Once the maxRestarts has been exceeded, the stream will stop.
If anything else interrupts the stream, we call killSwitch.shutdown(). The killSwitch.flow() introduced after the source takes care of completing its downstream and cancels its upstream. As a result, we make sure that all in-flight messages are processed before returning from shutdown().
When hardware fails
KillSwitch works well when we have control over the shutdown process, but what happens if the underlying hardware fails? What delivery guarantees can we provide?
In our application, we use two different systems for passing messages: Amazon Simple Queue Service (SQS) and Apache Kafka. Both systems have a way of marking a message as being processed (committing it). For SQS, we can delete the message, whereas for Kafka we can commit the offsets.
Depending on where we commit the message, we can easily implement the following messaging delivery semantics:
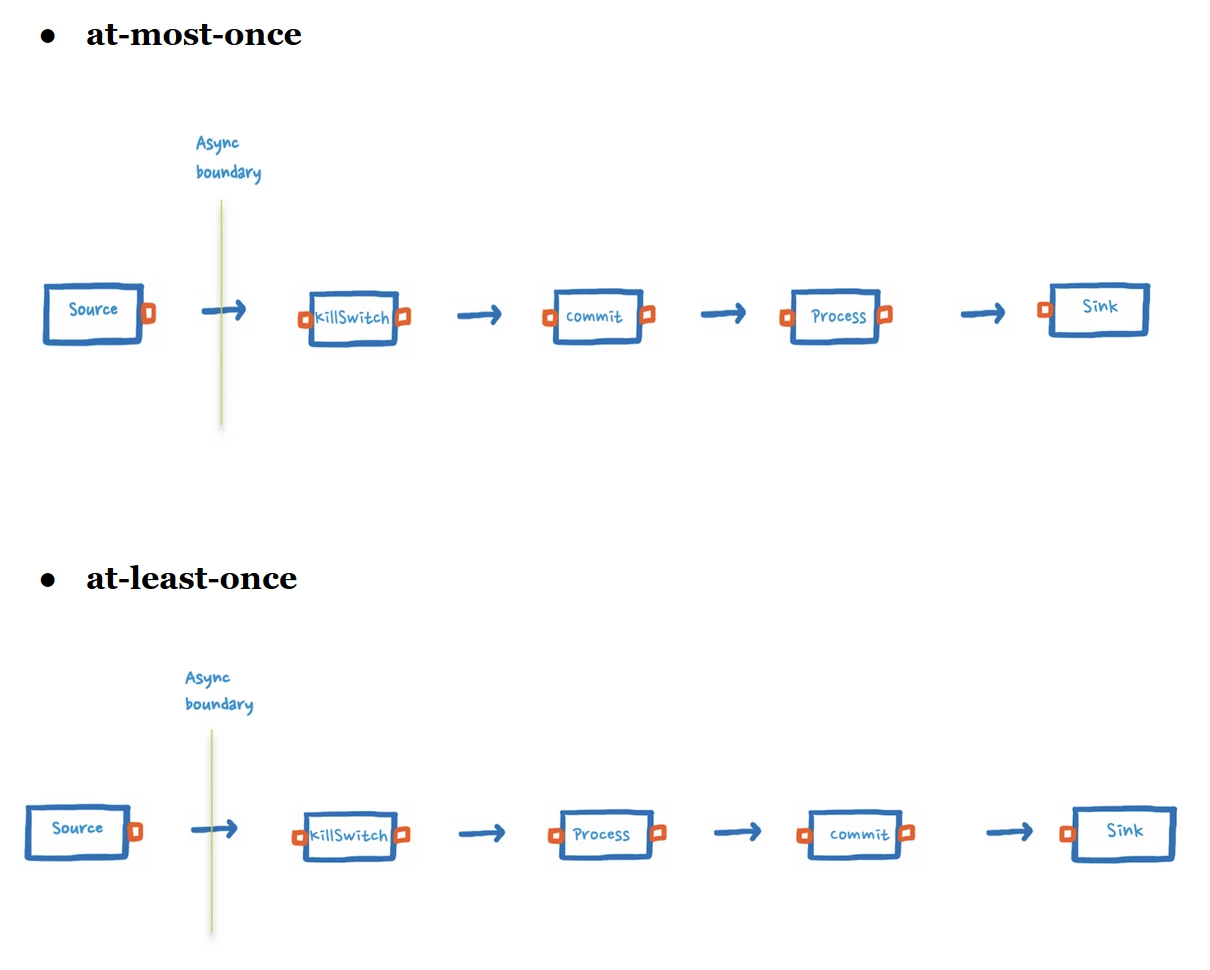
In both cases, we separated the source and the KillSwitch with an asynchronous boundary. Without this, the source and the KillSwitch will run in the same actor and, if a source is blocked while waiting for messages, the KillSwitch might not complete the flow.
By committing messages as soon as they pass the KillSwitch, we can guarantee that messages will not be lost in the case of a graceful shutdown.
Activation use-case: performance tuning
Now that we have revised the Akka Streams capabilities that enable our application to perform smoothly in production, let us now turn our attention to an actual application written using the same flow as our example.
At a high level, this new application is comprised of the following stages:
- Source reads messages from Kafka
- Deserialization
- Group the events based on a set of rules
- Perform lookups to enhance the events
- Serialization
- Sink

With a tremendous amount of data streaming through Real-Time Customer Data Platform, we set a target of one million events per second — an ambitious goal considering the flow includes steps that are CPU-intensive and I/O-intensive.
Since we use Kubernetes to deploy our applications, we began by deploying a pod to production. First, we tested the functionality, then we tested the performance. During this initial test, the pod was able to process about 60,000–70,000 events per minute. Based on our target of one million events per second, we would have needed somewhere around 1000 pods.
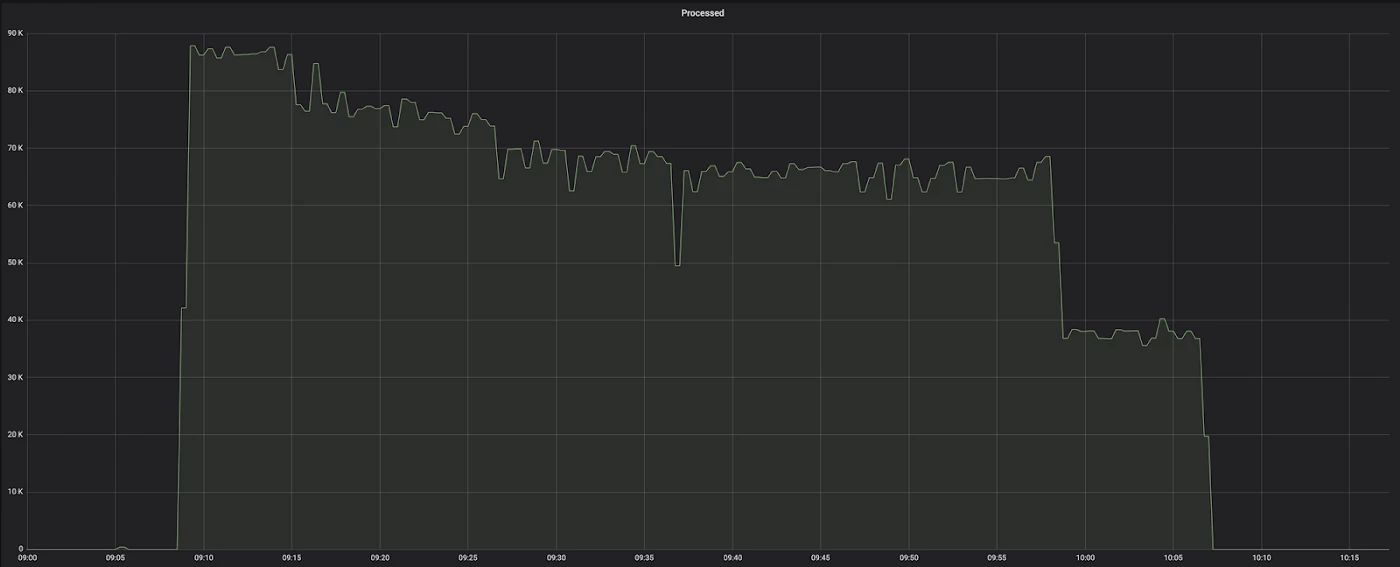
So, we disconnected the source from the rest of the processing flow. This pushed the source to read ~700k, which is 10x more than before. But there was still room to improve the initial application.
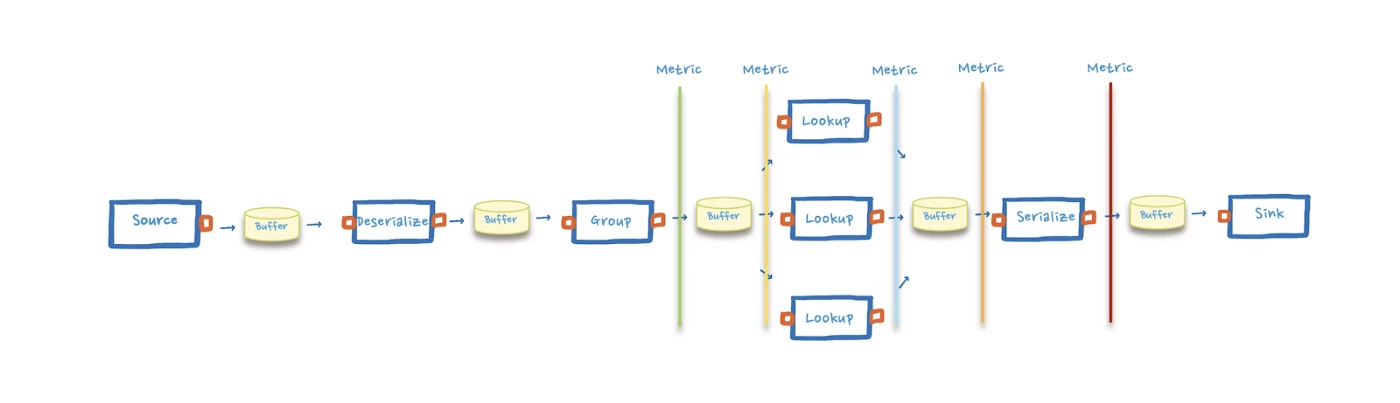
Next, we reconnected the source to the rest of the processing flow and checked the CPU and memory pressure for the application. Since we did not find anything in those metrics, it appeared there was a bottleneck in our processing pipeline. Subsequently, we added asynchronous boundaries and larger buffers between each component.

Our first suspect was the lookup, so we increased the maximum concurrent connections used. We also added metrics that tracked the number of messages that passed through specific points.
We then checked the results and, even though the overall performance did not improve, we could now pinpoint the bottleneck. The graph below shows how all the buffers before that problematic step started increasing due to backpressure until they reached their maximum size.
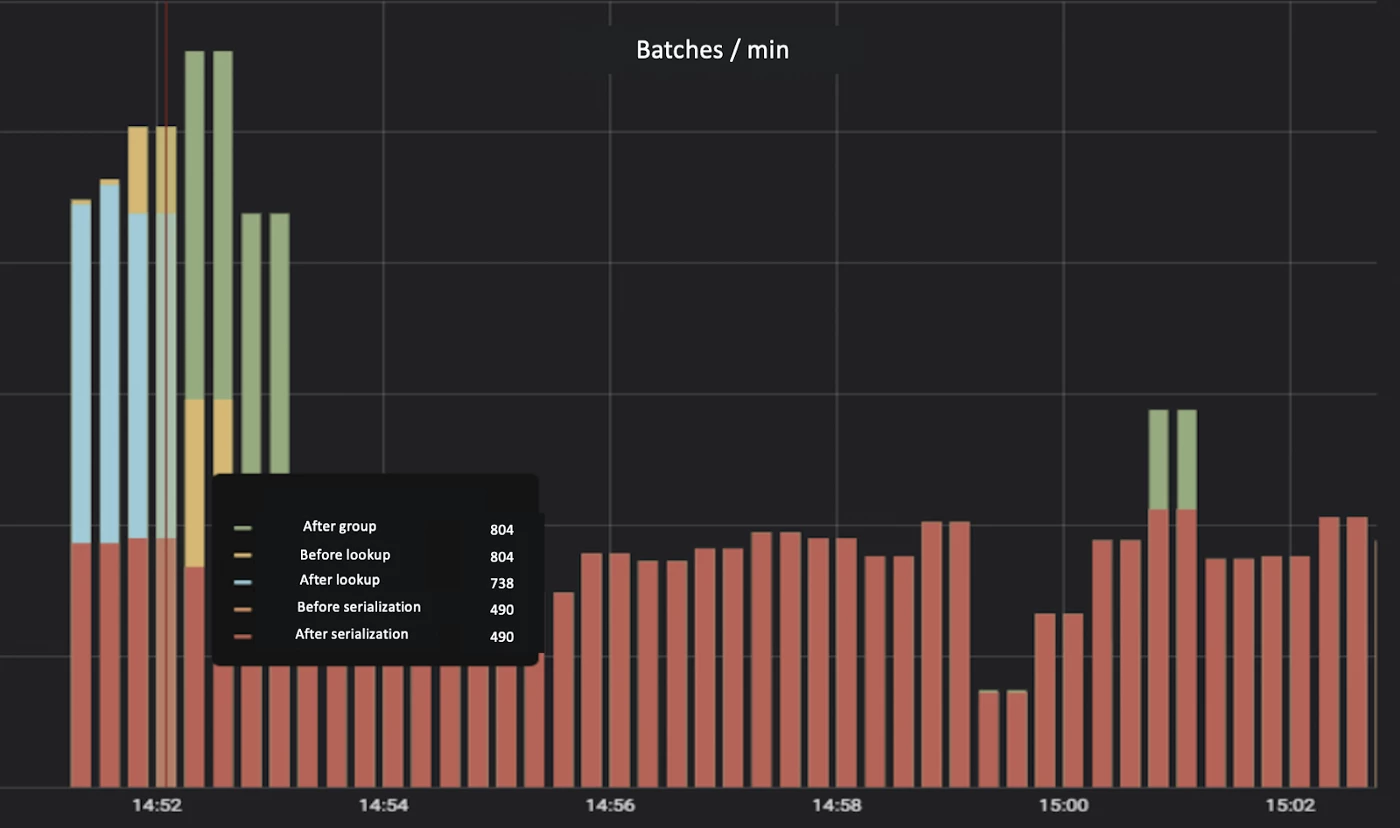
Now that we have identified that the bottleneck is the serialization step — a CPU-intensive task — we relieved the pressure on this step by increasing the parallelism to distribute the workload.
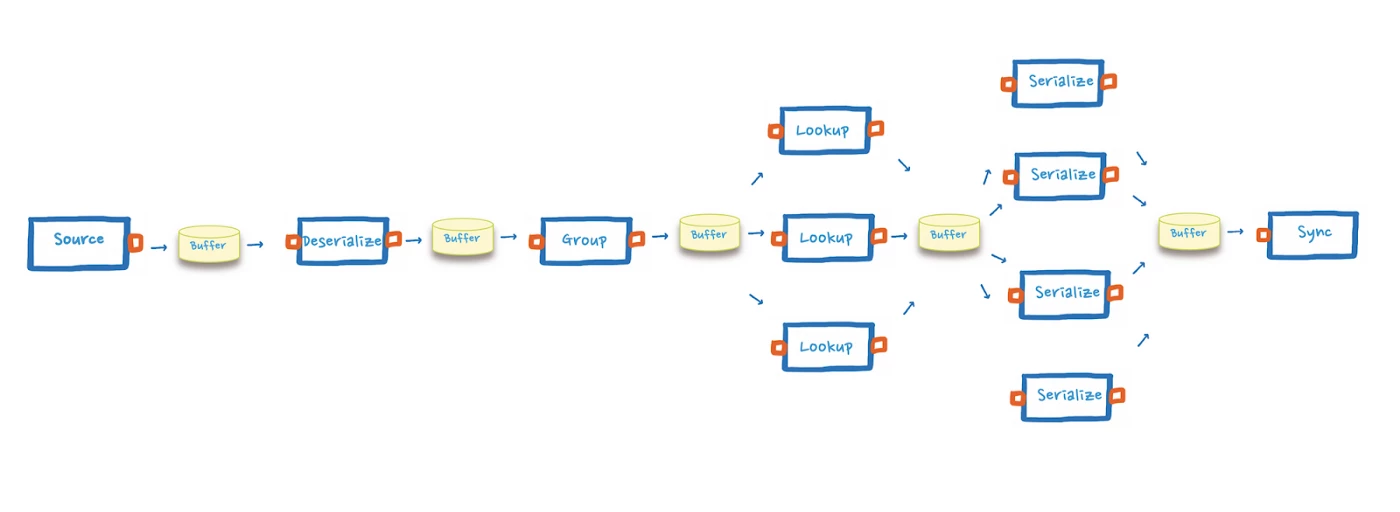
At this point, we were finally able to push the bottleneck further towards the end of the application, until it was completely removed.
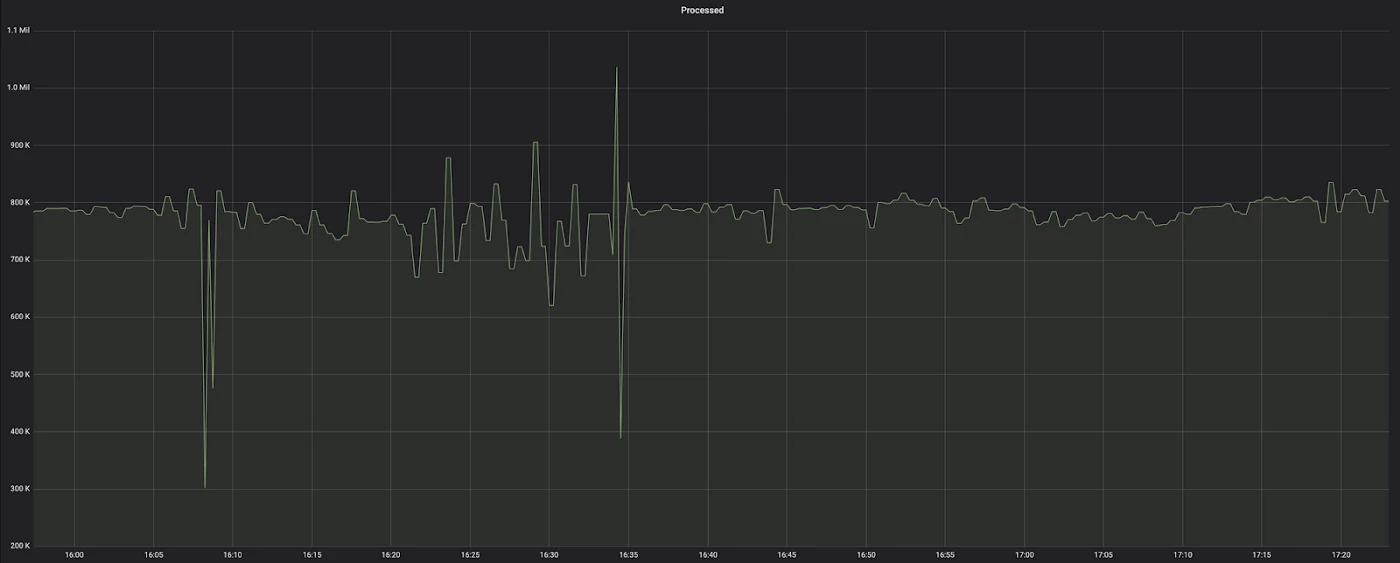
The performance test shown in the figure above reveals that the pod jumped from processing around 70,000 events per minute to 800,000 events per minute. This means that to reach our target of one million events per second, we no longer needed 1000 pods, but fewer than 100 pods.
Closing notes
While our actual Akka Streams implementations are much more involved and complex than what we have presented in this series, we hope to have conveyed how the Akka Streams framework has been pivotal for streaming activation in Real-Time Customer Data Platform.
We also hope our journey underscores the importance of performance testing and monitoring to continuously fine-tune your applications and maximize its potential.
For developers eager to learn more, Akka Streams is backed by a supportive community and offers a generous amount of documentation that, from experience, we can attest will help you accelerate the development of resilient, efficient and scalable Akka Streams applications.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Additional reading
- Akka Streams documentation: https://doc.akka.io/docs/akka/current/stream/index.html
- Adobe Experience Platform Real-Time Customer Platform: https://www.adobe.com/experience-platform/real-time-customer-data-platform.html
- Adobe Experience Platform: https://www.adobe.com/experience-platform.html
- Pipelining and Parallelism in Akka Streams: https://doc.akka.io/docs/akka/current/stream/stream-parallelism.html
- Akka Streams supervision strategies: https://doc.akka.io/docs/akka/current/stream/stream-error.html
Originally published: Jul 23, 2020