
Introducing Adobe Experience Platform Sandboxes
Authors: Pallavi Kotkar, Anuj Shah, Imtiaz Ahmed, and Liviu Cismaru

Companies often run multiple digital experience applications in parallel and need to cater to the development, testing, and deployment of these applications while ensuring operational compliance. Adobe Experience Platform is built to enrich digital experience applications on a global scale. We built a sandbox infrastructure to meet our customer, developer, and partner needs. This blog details our approach, architectural highlights, and what’s next.
Adobe Experience Platform helps brands to build customer trust and deliver better-personalized experiences by standardizing customer experience data and content across the enterprise, enabling an actionable, single view of the customer. Customer experience data can be enriched with intelligent capabilities and governed with robust data governance controls to use data responsibly while delivering personalized experiences. Experience Platform makes the data, content, and insights available to experience-delivery systems to act upon in real-time, yielding compelling experiences at the right moment.
Experience Platform with its access control capabilities and the sandboxes that allow for data and operational isolation enables customers with the right instrumentation for security and data governance, as they work to deliver real-time experiences through our open and extensible platform.
Experience Platform governance capabilities are built with an open and composable approach for brands to customize and use in the way they want. The API-first approach provides extensibility to integrate the features into custom applications and existing tech stacks. Adobe customers are provided with a robust set of access control capabilities that allows them to manage access to resources and workflows in the Experience Platform. Data is contained within sandboxes, providing operational and data isolation to support businesses and their regulatory constraints.
Approach
In order to address this need, Experience Platform provides sandboxes that partition a single Platform instance into separate virtual environments to help develop and evolve digital experience applications. Our sandboxes are virtual partitions within a single instance of Experience Platform, which allow for seamless integration with the development process of your digital experience applications.
A single Experience Platform instance supports production sandboxes and non-production/development sandboxes, with each sandbox maintaining its own independent library of Experience Platform resources (including schemas, datasets, profiles, segments, etc). All content and actions taken within a sandbox are confined to only that sandbox and do not affect any other sandboxes.
Non-production sandboxes allow users to test features, run experiments, and make custom configurations without impact on the production sandbox. In addition, non-production sandboxes provide a reset feature that removes all customer-created resources from the sandbox. Non-production sandboxes cannot be converted to production sandboxes.
In summary, sandboxes provide the following benefits:
- Application lifecycle management: Create separate virtual environments to develop and evolve digital experience applications.
- Project and brand management: Allow multiple projects to run in parallel within the same IMS Org, while providing isolation and access control. Future releases will provide support for deploying in multiple regions.
- Flexible development ecosystem: Provide sandboxes in a seamless, scalable, and cost-effective way for exploration, enablement, and demonstration purposes.
Data and Operational Isolation with Sandboxes
Sandboxes in Experience Platform are the fundamental feature for data and operational isolation. Sandboxes help organizations to contain multiple initiatives, production or development-focused, within their own boundaries. With sandboxes, organizations can create distinct virtual environments to safely develop and evolve digital experience applications, with full control on what sandboxes are available to specific users or groups of users. Global multi-brand organizations can capitalize on sandboxes and contain their market or brand-specific digital experience activities within the boundaries of distinct sandboxes.
Sandbox Actions and Sandbox Lifecycle
To start trying out Adobe Experience Platform features you can create a sandbox. If you have turned a few knobs and experimented with a few of the features and want to start over to try something different you can Reset the sandbox. This operation resets the sandbox to the initial state. After you are done playing around and no longer need the sandbox, you can Delete the sandbox.
User Actions on Sandbox:
- Create Sandbox: Create a new Sandbox.
- Reset Sandbox: Resets the same sandbox to the initial clean state.
- Delete Sandbox: Deletes the sandbox and the sandbox cannot be recovered.
The user actions lead to the following state transitions in the sandbox:
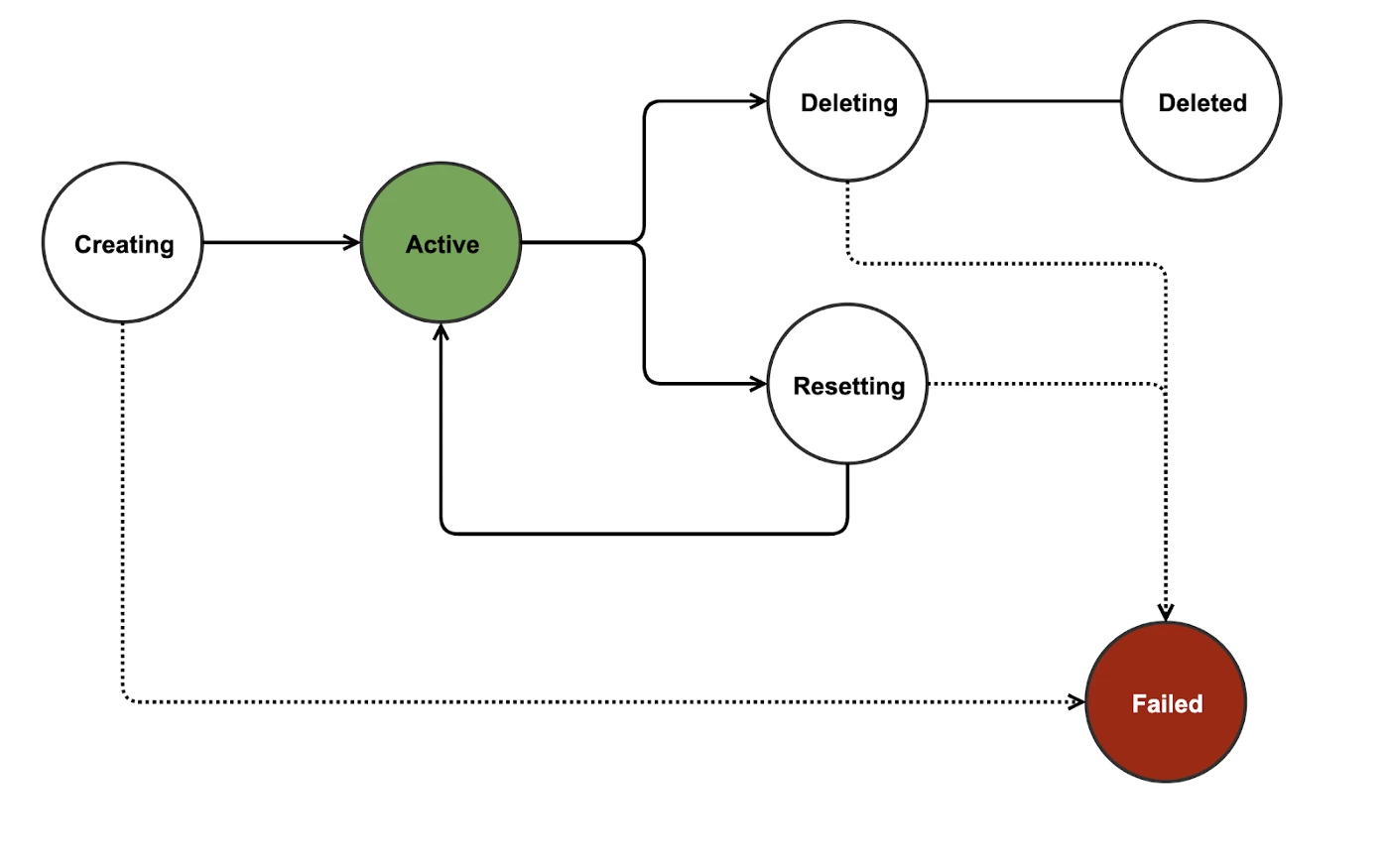
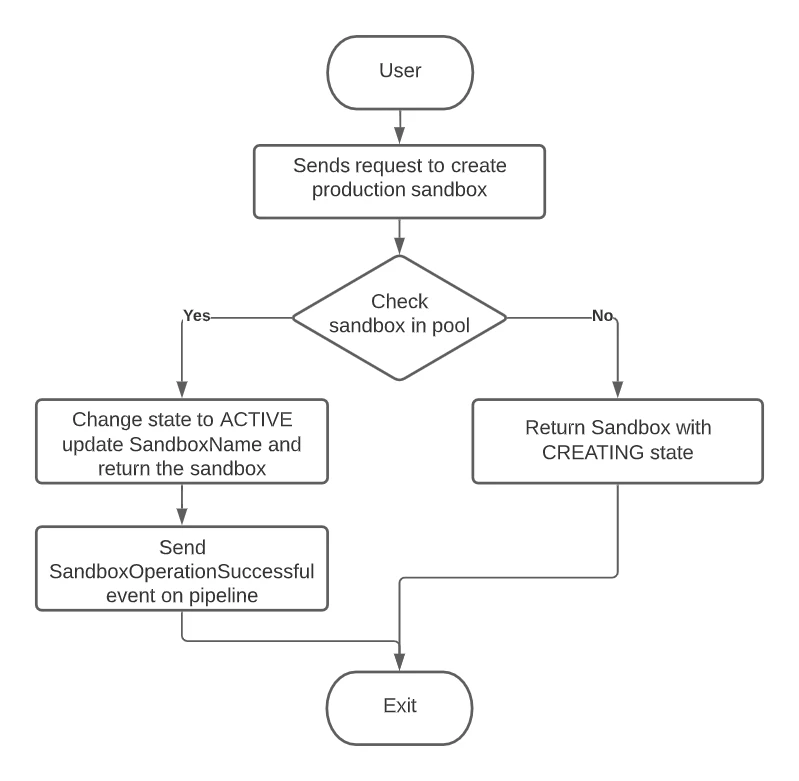
When the user hits the Create Sandbox button, the user request is validated. After the user request is validated, the sandbox transitions to a creating state. After the Sandbox is successfully created by the sandbox management service, the sandbox state is changed to Active.
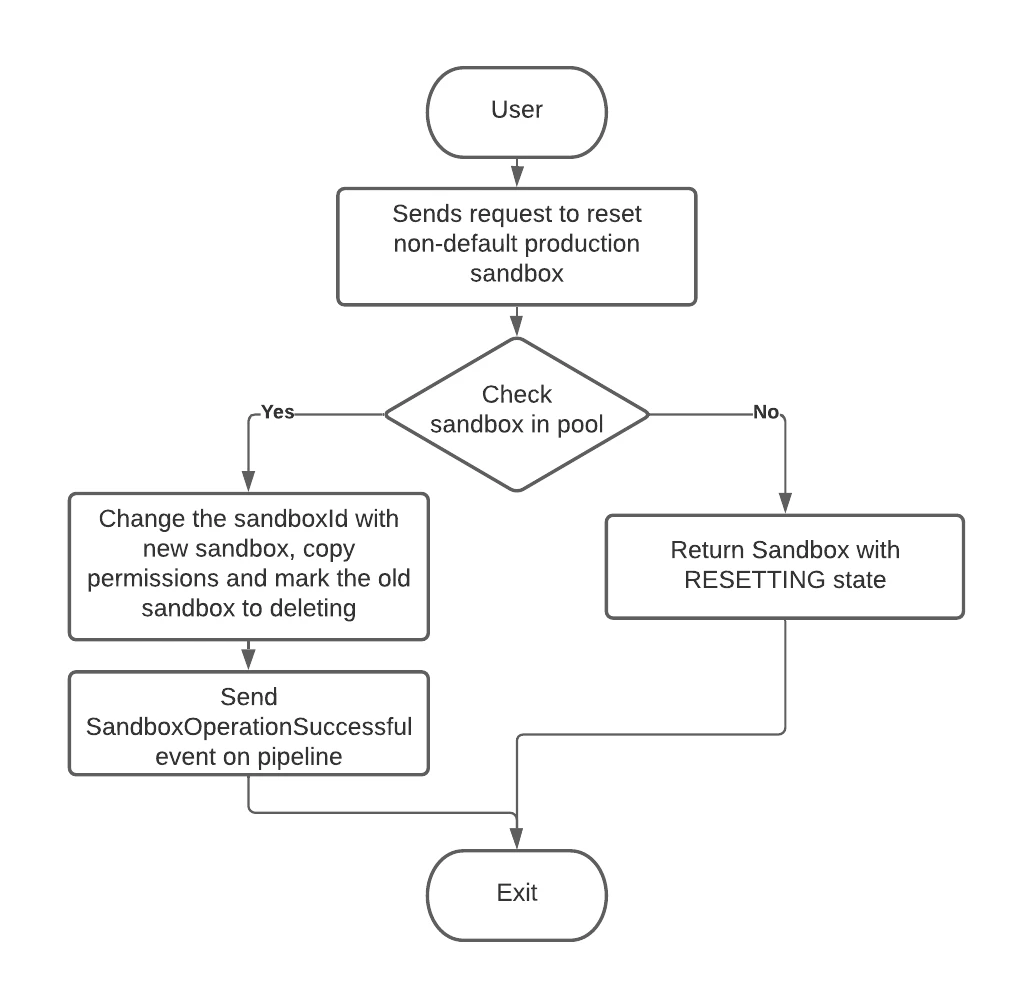
When the user requests to Reset the sandbox, it is transitioned into Resetting state. After the sandbox management service successfully resets the sandbox, the sandbox state is updated to Active. If the reset fails, the sandbox is restored to the previous state.
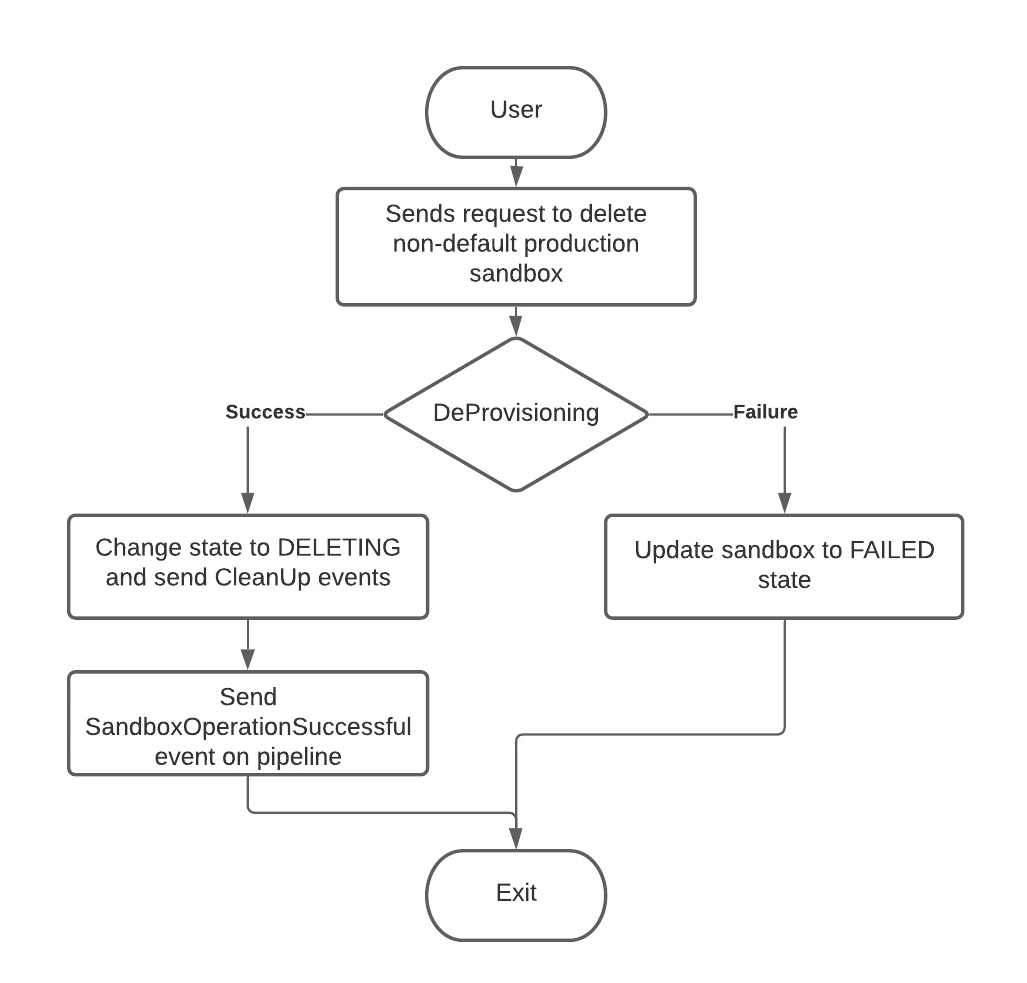
When the user requests a Delete for the sandbox, the state is changed to Deleted immediately and the user can no longer see or access the sandbox.
The internal state transitions within Sandbox Management Service are as follows:
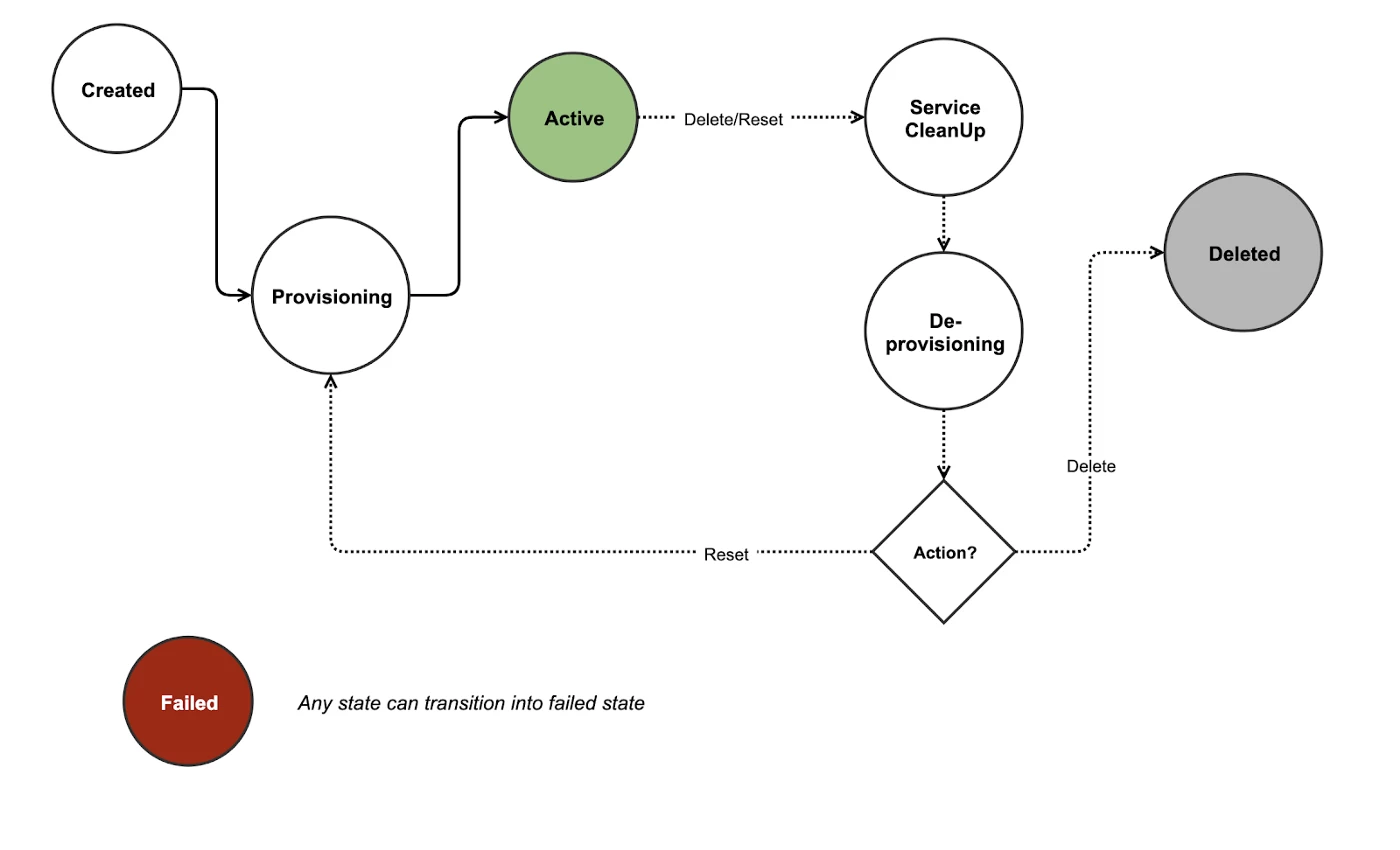
The internal state of the sandboxes managed by the sandbox management service is more tightly linked to the provisioning process and orchestration with the component services. It tracks the user requests and the resources provisioning workflow. After the user requests for a sandbox, Sandbox Management Service internally transitions the sandbox to provisioning state till the provisioning is complete and the Sandbox can be moved to Active state. Similarly, for resetting, the service internally changes state to Resetting till the reset process is complete. For Delete, the resources need to be cleaned up for any data and records before the resources can be safely deleted/deprovisioned. Thus, the sandbox state is first changed to CleanUp, followed by Deprovisioning , and eventually Deleted. If at any point the processes fail, the sandbox is directly transitioned to Failed state.
The internal sandbox states are designed to be useful in multiple ways:
- Rate Limiting: Sandbox Management Service tracks the number of user requests that are still being provisioned and the sandboxes that have not yet reached
Activestate. This helps set limits on the number of user requests that can be made to create sandboxes while there are still requests in-flight for sandbox creation by the same user. The same is applicable for the Sandbox reset operation. - Monitoring and Alerting: Sandbox Request Manager Service which is the standalone service for monitoring our Project & Application Lifecycle Management (PALM) infrastructure tracks the number of requests which are in an interim state and uses it to measure the performance and latency in the system. This helps detect any anomalies in the service or raise alerts on the bottlenecks in the system that can be resolved to avoid any incidents. More details on the Sandbox Request Manager are described in the following section.
Let’s dive into approaches we took in architecting Adobe Experience Platform sandboxes.
Architecture
Our PALM infrastructure consists of 2 core components. This blog will be focusing on one of the components: Sandbox Management Service. The purpose of sandbox management service, as the name suggests, is to manage the lifecycle of the sandboxes and manage the metadata about the sandboxes. It enables the users to create, reset, and delete sandboxes. Sandbox Management Service orchestrates the workflow to provision the required resources for the sandboxes by coordinating with ALL the user-facing services on Adobe Experience Platform. The main components in the Sandbox Lifecycle Management are as follows:
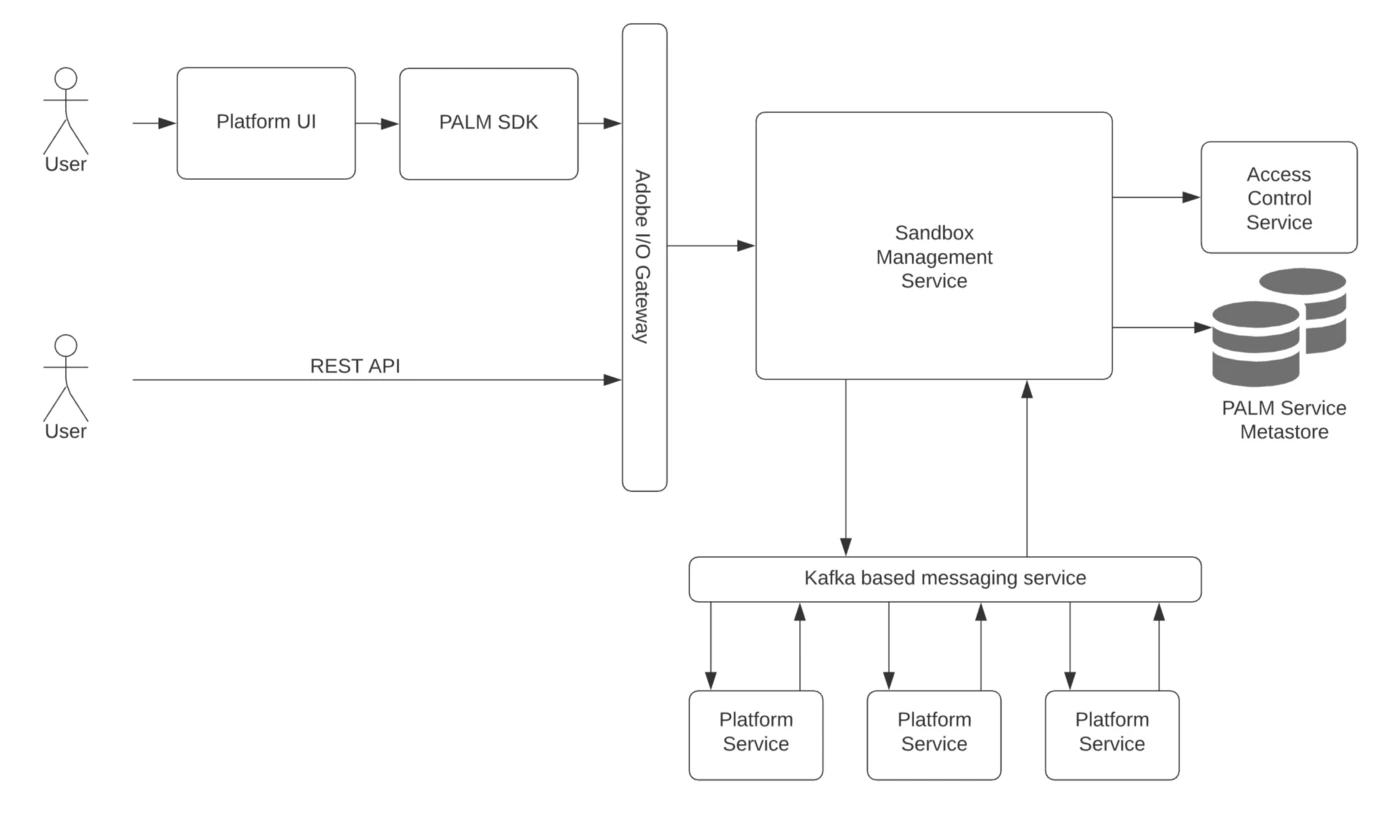
Here are the architecture components in detail:
- Platform UI: Adobe Experience Platform UI is the primary interface to manage sandboxes.
- PALM SDK: PALM SDK is an internal SDK for Platform services and not available to customers. PALM SDK makes implementing sandboxes and access control painless for Platform services by abstracting away the complexities and internal details. It is a client library that provides common sandbox lookups and access checks needed by services. API clients are used to interface with the backend services. It is a lightweight library that can be added as a maven dependency.
- Sandbox Management Service: Core service for management of the lifecycle of sandboxes. The service was developed on the API First principle and has full REST API Interface support.
- Access Control Service: Service that enables users to control access to the Platform workflows, data, and resources, based on their roles and business needs. It is an important component of our PALM infrastructure. More about Access Control Service to come in the following blogs.
- Provisioning Service: Core Experience Platform service for orchestrating the provisioning of platform cloud resources eg: Data Lake, CosmosDB, and Azure Data Factory.
- Adobe Experience Platform component services: Adobe Services are offered as Experience Platform products and that need to be provisioned for if the user adds those to their license.
As mentioned above, each sandbox maintains its own independent library of Platform resources that includes schemas, datasets, profiles, and segments. This implies that for each Sandbox, all the platform resources need to be provisioned. When the user requests for a new sandbox, the provisioning for each new sandbox is initiated by the Sandbox Management Service as it is responsible for managing the lifecycle of the sandboxes. It registers the user request and then contacts the provisioning service with the details to provide the required platform resources for the user.
Provisioning of the resources is not a trivial process and the time required is in the range of minutes. The communication with the Provisioning Service and Sandbox Management is Asynchronous Event-Based. It is based on Kafkas’ event-based messaging framework.
Challenges
There were five challenges we had to face and address. Below details of our challenges, our approach, and how we solved it.
Single collection for multi-item transactions and Stored Procedures
Several workflows within the Sandbox Management Service require transactional processing since more often than not multiple models need to be created/modified within the same workflow. Here is the documentation from Microsoft Cosmos DB
Here is a simple resources provisioning workflow:
- Update the provisioning status when the provisioning success message is received.
- Update the sandbox status to Active.
- Trigger requests to replenish the pool.
The above workflow provides a guarantee that every time a sandbox is used up from the sandbox pool, it is replenished immediately. This workflow requires multiple records to be updated in a single transaction.
The underlying database used for storing the metadata is Azure CosmosDB which is a no-SQL database. Leveraging the schema-less nature of the database, we use a single collection for storing all the models. Within the same collection, the Record Type field will identify the type to which a particular record belongs to. All the queries run on CosmosDB will have a filter on this field for operating on certain models.
SELECT * FROM c WHERE c.recordType = "record_type_a"
The collection is logically partitioned with a predetermined partition key. CosmosDB supports transactions within a logical partition of a collection using Stored Procedures. We partition the collection based on the partition key such that all of our operations that require transactions are confined within the same logical partition. During the course of execution of the stored procedure, if there is an exception, the entire transaction is aborted and rolled back. Depending on the type of exception Stored Procedure can be retried. This gives us a very powerful programming model for managing transactions in PALM workflows.
JavaScript-based stored procedures are installed on application start-up. While installing the stored procedure the current version of the stored procedure is checked and if it is unchanged the existing stored procedure is preserved. If the stored procedure was updated and the current version of the stored procedure is higher than the installed stored procedure, the installed stored procedure will be updated with the latest version.
Here is the above workflow using Stored Procedures:
List<UpdateOp> updateOpsList = new ArrayList<>();
UpdateOp updateOp1 = new UpsertOp(updatedProvisioningStatusRecord)
UpdateOp updateOp2 = new UpsertOp(updatedSandboxStatusRecord)
UpdateOp updateOp3 = new UpsertOp(newReplenishRequestRecord)
updateOpsList.add(updateOp1);
updateOpsList.add(updateOp)2;
updateOpsList.add(updateOp3);
try {
triggerStoredProcedure(updateOpsList);
} catch {
// retry
}Sandbox Pooling
Sandboxes each have all the platform resources provisioned. After the resources are provisioned permissions need to be applied to the created resources. These two operations need to happen sequentially. It also involves communication and handshake between the platform services during the entire process. The entire end-to-end workflow takes anywhere between 12 to 20 minutes to complete. This is not the best experience for the users who want to try out certain features of the platform or set up custom jobs. The SLT’s are much higher.
SLT targets for the Sandbox Management Service Use Cases we had to solve:
- As an Adobe Experience Platform user, I want to be able to use my newly created sandbox in a maximum of 30 seconds from submitting the CREATE request.
- As an Adobe Experience Platform user, I don’t want to see my deleted sandbox anymore after a maximum of 30 seconds after pressing the DELETE button.
- As an Adobe Experience Platform user, I want to be able to use my resetted sandbox in a maximum of 30 seconds after submitting the RESET request.
The three conditions above should be true for both UI and API calls. To meet the SLTs Sandbox Management Service maintains a warm pool of pre-provisioned sandboxes. The provisioned resources do not have any data/ assets in them till the user actually starts using the sandbox. The provisioned resources thus do not cost anything till they actually start being used by the user. Sandbox Pooling gets triggered in 3 scenarios:
- When the customer is first provisioned for Adobe Experience Platform
- When the max number of sandboxes allowed is increased for the customer.
- When user creates/ resets a sandbox, to replenish the pool
Note: With pooling we achieved reduction is user sandbox creation time from between 12–20 minutes to 30 seconds i.e the wait time for sandbox creation is reduced by 97.5%.
The size of the sandbox pool depends on the maximum number of sandboxes the user is allowed to create. After the users have used up all the sandboxes in the pool they are either automatically throttled by the exhausted pool or the rate-limiting checks by the sandbox management service. Having multiple redundant checks helps keep the system in check and prevents the provisioning mechanism from getting overwhelmed.
Added advantage of Sandbox Pooling
Pooling also guards against provisioning mechanism failures. This is achieved because the pooling service always maintains the warm pool of a designated number of sandboxes and it always looks at pending user requests when a sandbox becomes available in the pool. The user requests to create Sandboxes will never fail but hangs in creating state at worst for a few minutes if the pool is exhausted till the pool is replenished. When the provisioning completes for the pool replenishment the pooling mechanism looks in the database to check if there are any pending user requests and they are served. And as soon as a sandbox is used up from the pool, the pool replenishment process is triggered. Thus, the sandbox pooling has helped bring down the sandbox provisioning failures to almost ZERO percent.
Although provisioning failures might still occur and affect the pool replenishment mechanism. This is taken care of by the recovery process built in the sandbox request manager service. Sandbox Request Manager Service does this by periodically looking at failed provisioning requests for pool replenishment and retries the provisioning on scheduled intervals. More details on how the Sandbox request Manager Service does this is described in the section dedicated to Sandbox Request Manager Service.
Monitoring and Recovery Infrastructure
Sandbox Management Service is built to be robust and our PALM infrastructure makes it more reliable with a specialized monitoring and recovery mechanism described below.
Watchdog Service
The nature of the sandbox life cycle involves dependency on multiple services and several steps. At every step of the life cycle, there are chances of sandbox misstep which can lead to failures and bad customer experience. To mitigate those caveats we have our own infrastructure service which maintains the sanity of the sandboxes and fixes the failures. Watchdog service is an executor service where a job can be scheduled and duration can be set for its recurrence.
The sandbox metadata is stored in Cosmos DB and it’s the source of truth for the sandbox state. The sandbox management service is backed by the Cosmos DB, all the transactions and sandbox states are maintained in the database. The watchdog service polls data from the database and identifies the monitoring scenarios. Based on the outcome several metrics are calculated and sent to observability where alerts are triggered. Metrics dashboards are set up on Grafana where a holistic view of the service is observed. The dashboard showcases several charts and bar graphs which helps the service owner understand the operations and performance of the service. Alerts are set up on an internal alerting service that uses Prometheus alert rules to maintain all the alerts.
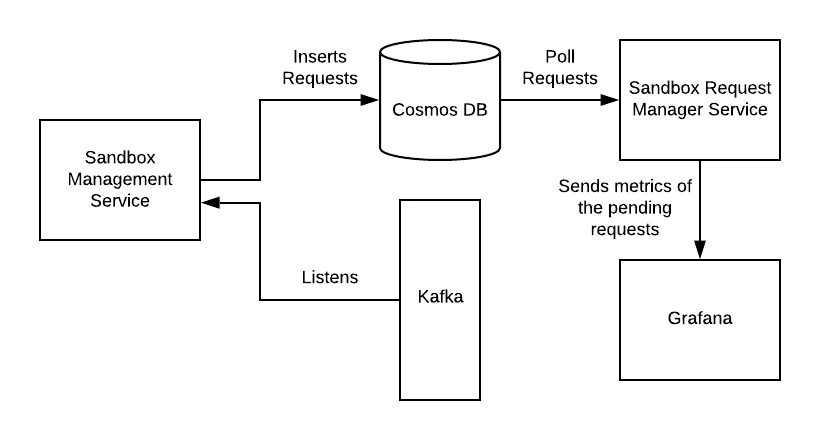
Scenarios:
- Sandboxes stuck in the intermittent state: The workflow of the sandbox state change requires sandbox job requests with tasks, these tasks are actions that are required to be performed by other services in order to promote the sandbox to a terminal state. The tasks also hold their states which help decide the sandbox request state. The service monitors the sandbox requests tasks which are stuck in a pending state and will send those metrics to observability. Based on those metrics alerts are raised informing the team to take action.
- Triggering sandbox pooling: The service also holds the position to top up the pool of sandboxes in case of some failures, as the pooling mechanism depends on provisioning there can be failures which leads the sandbox creation/reset/deletion to a failed state. Watchdog service helps to trigger the pool for orgs where the pool is not filled completely, thus serving as a bridge between the failure and getting the pool filled up.
- Total number of sandboxes: Watchdog service has another job setup that queries the total number of sandboxes for each IMSOrg and its corresponding state and sends it to observability. This metric helps understand the total sandboxes for IMSOrg sliced by sandbox state.
What’s Next
There are currently two sandbox types, each having its own data and operation isolations:
- Development: The development sandboxes as the name suggests are used for development-oriented work within an ecosystem whereas the production sandbox can be used for production environments.
- Production: The production sandboxes are used for production environments.
The service will start supporting multiple production sandboxes which will allow the user to create more than one production sandboxes to cater to the needs of data isolation at the production environment level. For example, if the company wants to separate data based on regions it can have separate production sandboxes for each region. Similar to the development sandboxes there is also a warm pool of production sandboxes that maintain a high availability and low latency for the production sandbox operations (create/delete/reset).
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up for future Adobe Experience Platform Meetups.
References
- Adobe Experience Platform
- Adobe Experience Platform Sandboxes Documentation
- Azure CosmosDB Documentation
- Azure CosmosDB Documentation-Transactions and optimistic concurrency control
- Adobe I/O Documentation
- Prometheus
- Grafana
Thanks to Emtiaz Ahmed and Gustavo Javier Mazal.
Originally published: Mar 18, 2021