
GPU Accelerated High-Performance Machine Learning Pipeline
Author: Lei Zhang

In this blog, we detail how Adobe’s AI/ML services team is currently working with NVIDIA to build a GPU-based high-performance machine learning pipeline.
Even brands with the most loyal customers have to ensure that their marketing messages are effective and engaging. It is becoming a greater imperative for brands to improve user engagement and manage fatigue with more channels than ever before in order to lead in Customer Experience Management (CXM).
Adobe’s AI/ML services are a suite of AI-as-a-Service offerings designed specifically for marketers to power better customer experiences — all without data science expertise. It includes a high-performance data processing pipeline and state-of-the-art machine learning models. Adobe’s AI/ML services suite includes:
- Attribution AI: Understand the incremental impact of every customer interaction
- Customer AI: Deliver insights about each individual customer
- Journey AI: Optimize design and delivery of customer journeys
- Content AI capabilities: Interpretation and discovery of the best performing content
- Leads AI: Identify the most qualified leads for B2B
In the following, we will use Journey AI as an example. Journey AI helps brands optimize content across email, SMS, push notifications, and more. It helps optimize customers’ experience, maintain customers’ brand awareness, and ensure that customers are not overwhelmed, by providing predictive insights in areas like optimal send times, content types, and channel frequency.
Challenges in the Machine Learning Pipeline
Architecturally, Journey AI consists of complicated data pipelines including ETL jobs, machine learning model training, and prediction jobs. The pipelines include ETL jobs, machine learning model training, and prediction jobs. The ETL jobs usually involve a large volume of data and cost considerable time and money. Machine learning model training and prediction job is another important task in the pipeline. It uses the processed data from ETL jobs to train models. This step involves heavy calculation and usually takes a long time.
Since the Journey AI machine learning pipeline takes a long time to run, its costs can be significant for our customers. We are working with NVIDIA to address this challenge.
NVIDIA GPU-Accelerated High-Performance Machine Learning Pipeline
In order to reduce the long run time and high cost, Adobe’s AI/ML services team is currently working with NVIDIA to build a GPU-based high-performance machine learning pipeline. This pipeline uses GPU compute alone, executing the same jobs that were run via CPU but with significantly faster speed and lower total cost.
A graphics processing unit (GPU) is a processor that is specifically designed to handle intensive graphics rendering tasks. It has been widely used for high-quality gaming, 3D modeling software, video editing software. With the development of the NVIDIA CUDA platform, GPUs can process data science workflows at an extremely fast speed, including building machine learning models, such as neural networks and XGBoost.
NVIDIA is working on bringing the popular in-memory big data processing engine, Apache Spark, onto the GPU to accelerate its processing speed. The official name for the plugin that accelerates Spark applications is RAPIDS Accelerator for Apache Spark 3.0. This plugin enables Spark SQL and Dataframe operations to gain significant acceleration without any code changes. This includes when they run on GPU such as high cardinality joins high cardinality aggregates, high cardinality sorts, and windowing operations.
For our first project, one of the Journey AI machine learning pipelines has been fully migrated onto GPU workers, in order to evaluate its performance. This pipeline has two parts: feature generation and model prediction (Figure 1). The feature generation part is to convert the raw data to the meaningful feature data that can be used to train the model. This work involves a large amount of table join aggregation and windowing functions. It is implemented on Apache Spark. For the results reported here, the model prediction part is used on a pre-trained XGBoost model and generated feature data to predict the event probability.
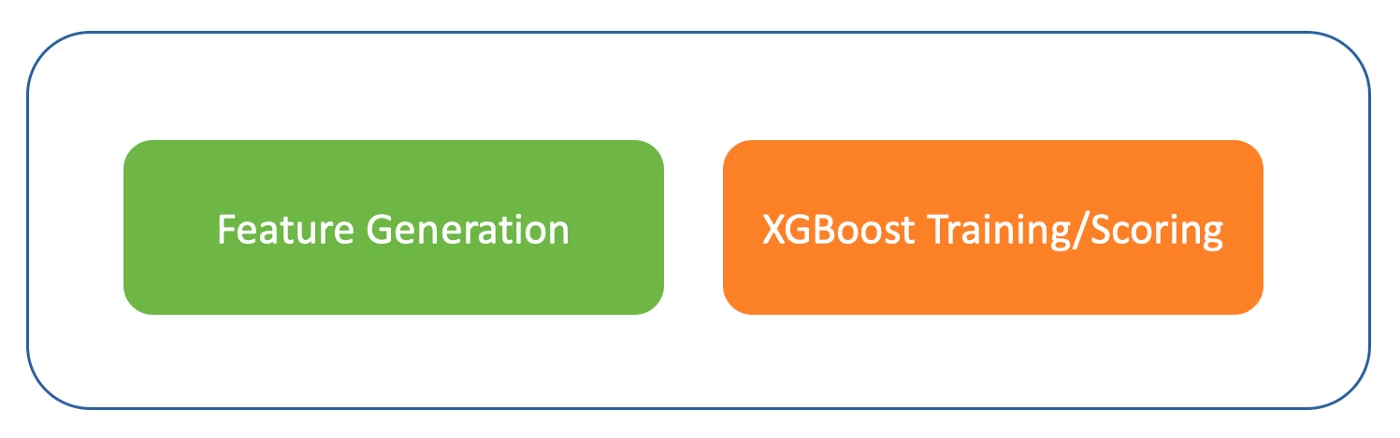
Benchmark Test and Results
In the benchmark test, two computing clusters are used: one CPU cluster which contains a group of Standard_L4 workers (6 Cores and 32 GB Memory), and one GPU cluster which contains a group of Standard_NC6s_v3 workers (6 Cores, 112GB Memory, 1 V100 GPU processor). In order to make the two clusters have similar run costs given the same amount of time, we kept the ratio between the number of workers in the CPU cluster and the number of workers in the GPU cluster as 5:1.
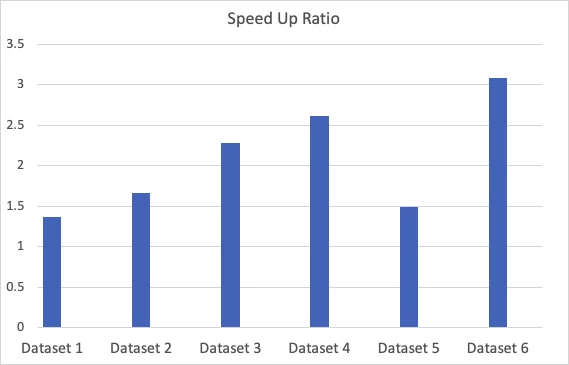
The first benchmark test focuses on the feature generation part of the pipeline, which is to test the performance of the Spark query. The same Spark query was tested across six customers with different data sizes. The speed-up ratio of GPU cluster to CPU cluster is shown in Figure 2. Overall, the speed-up ratio ranges from 1.5 to 3 times. This high speed-up ratio also represents 20% — 60% time saving and 20% — 60% cost reduction.
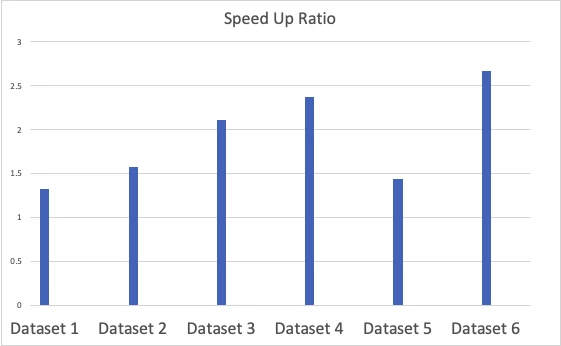
The second benchmark tested is to test the whole pipeline, which includes feature generation (Spark query job) and machine learning model (XGBoost) prediction. The generated feature data was immediately passed to the XGBoost model for prediction, without a temporary saving process. The pipeline was tested on the same six customers as above. The speed-up ratio of GPU cluster to CPU cluster is shown in Figure 3. The speed-up ratio ranged from 1.5 to 3 times. This high speed-up ratio also represents 20% — 60% time saving and 20% — 60% cost reduction.
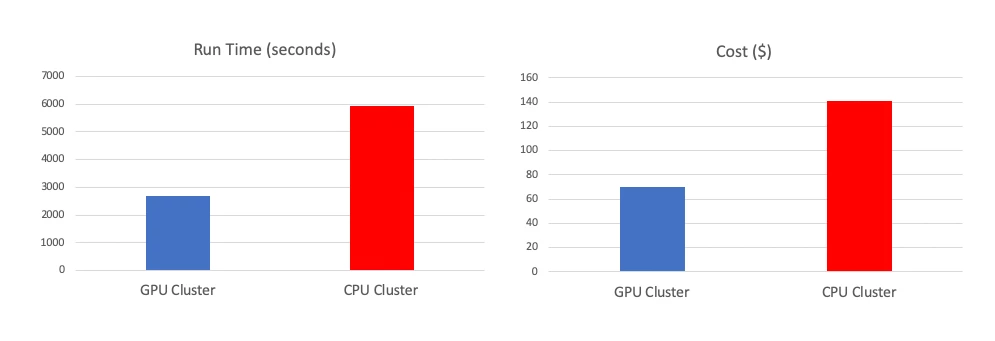
In the last benchmark test, we tested our pipeline on our largest dataset. It had five data sources, with over 3 TB of data in total. This pipeline also has more complicated join and aggregation in the feature generation stage. Twenty GPU workers in the GPU cluster and 100 CPU workers in the CPU cluster were used in the tests. The benchmark test results are shown in Figure 4. The GPU cluster significantly outperformed the CPU cluster: with 2 times faster, and at the cost of 50% of the CPU cluster.
Looking ahead
Adobe and NVIDIA plan to continue working on accelerating machine learning pipelines for Adobe’s AI/ML services with the latest NVIDIA GPU technology. With the development of new functions and improvement on compatibility, more and more Spark and machine learning jobs can be done on GPU with significantly faster speed and cost reduction.
References
Related Blogs
- How Adobe Does Millions of Records per Second Using Apache Spark Optimizations — Part 1
- Adobe Does Millions of Records per Second Using Apache Spark Optimizations — Part 2
Thanks to Adangelo.
Originally published: Apr 22, 2021