
Cross-Device Analysis Using Adobe Experience Platform and Customer Journey Analytics
Authors: Jaemi Bremner (#Jaemi_Bremner), Sunil Kumar A K, and Sachin Yelchithaya (#Sachin_Yelchith).

In this blog, we are explaining different approaches on how we can build a dataset in Adobe Experience Platform to perform cross-device analysis using Customer Journey Analytics which was incepted from multiple customer requests.
Statistics from various sources depict the usage of multiple devices across digital domains. This makes it interesting to get some insight into specific patterns of consumer behavior across devices.
While mobile usage is on the constant rise, tablets and desktops continue to mark their presence as well. Generally, around twenty percent of cross-device transactions completed on a desktop start on a smartphone, and 35% of those completed on a smartphone begin on a desktop. Ignoring to measure the cross-device performance, this alone could lead to poor decisions based on weak or insufficient data.
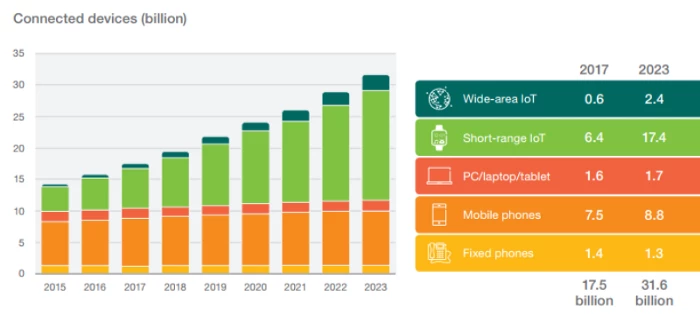
A study says globally, 31.6 billion connected devices are expected to be in use by 2023 in Figure 1.
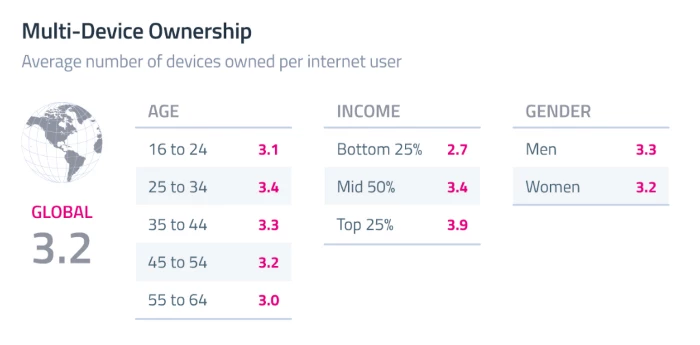
Similarly globally, digital consumers own 3.2 connected devices in Figure 2 below.
Use Cases Productized from Market Research and Customer Feedback
Based on the above research, it justifies performing cross-device analysis to understand the customer journey for us to consider for features for Adobe Experience Platform.
Below are some of the use cases that are best answered by cross-device analysis. Cross-device analysis is a feature that transforms Adobe Analytics from a device-centric view to a person-centric view. It helps in solving the below use cases:
- Types of devices that customers use to interact with my brand.
- General pattern of the device path during the course of the customer journey.
- Interaction begins on a specific device and eventually completes on a different device.
- Campaign click-throughs that land on one device eventually leads to conversion somewhere else.
- Behavior of users with multiple devices differs from the users with a single device.
Our Objective for Cross-Device Analytics Development
Based on the above research, the most prevalent need from our customers is to stitch different devices from the same user and perform analysis. This feature would enable the customers to improve delivering exceptional experiences in real-time.
Our customers need a solution to consolidate this user journey and then provide meaningful insight to their users’ journeys across multiple devices across desktop, mobile, tablet, and IoT.
Challenges
For cross-device analysis, we rely on the Adobe Analytics data that flows into Adobe Experience Platform via the out-of-the-box Adobe Analytics connector. For cross-device analysis, it was of utmost priority to have the customer login information persisted across all of the events specific to the user. The mid-values dataset that stores the Analytics data does not persist the customer login information across the hits that depicts the customer journey or customer events. Moreover, we would also miss out on the customer login information on those events where the customer does not login to the digital property.
We could summarize the challenges into the below points:
- Non-persistence of customer login in analytics mid-value dataset
- Different ECIDs/cookie for different devices
- Non-existence of pre-authenticated stitching based on
customer_idpre/post login
Solution and Architecture
The customer login information is generally captured in one of the eVars as part of Adobe Analytics implementation. As described above, this eVar is not persisted across all of the events that are part of the user journey.
As part of the cross-device analysis solution, one of the foremost tasks is to have the eVar persisted across all of the events that are part of the user journey.
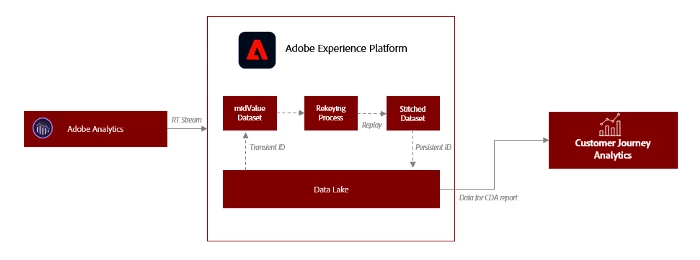
Below steps summarises the high-level approach to prepare the data for a cross-device analysis implementation:
- Adobe Analytics data is streamed into Adobe Experience Platform into the Global midValues dataset.
- Dataset includes the
customer_idin one of the eVars, which is typically populated after a user authenticates. - Adobe Analytics events records prior to authentication will need to be persisted to the customer_id that is captured post-authentication.
- Persisted data can then be used for reporting within Customer Journey Analytics or other BI reporting tools.
Our architecture approach was:
- Backward Stitching using Query Service
- Forward Stitching using Query Service
- Last Known
customer_id/ First Knowncustomer_id - Adobe Experience Platform Engineering
1. Backward Stitching using Query Service
In this approach, we identify the latest user login information and then move back in the history to persist this information. Customers on their side could decide on the number of months they would prefer to look back into the history to persist the user login information.
The below steps would summarize the steps involved:
- Partition the Analytics mid-values dataset based on the Adobe Analytics ID or the ECID. In the example shown below one of the partitions is represented by
MCID2A781E49 (Note: ThisMCIDis just a superficial ID to represent a givenMCID) - Within each partition that is ordered by the timestamp in ascending order, identify the last known value within the
customer_idfield. In the below example thecustomer_idwould be “1165450014” - On to the new field within the dataset, copy this
customer_idbackward until we locate a non-blank value within thecustomer_idfield. In the below example thecustomer_idwould be “581607124” - Repeat the above step until we are within the stipulated lookback window (e.g. 13 months of AA midValues data)
- For all the latest post-login events, the last known
customer_idis forward filled
Sample Windows Analytical function to implement the below logic
STRUCT(STRUCT(NVL(NVL(_experience.analytics.customDimensions.eVars.eVar1,
LAST_VALUE(FIRST_VALUE(_experience.analytics.customDimensions.eVars.eVar1, true) OVER (PARTITION BY endUserIDs._experience.aaid.id ORDER BY timestamp ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING), true)
over (PARTITION BY endUserIDs._experience.aaid.id ORDER BY timestamp)),endUserIDs._experience.aaid.id) AS rekeyedID) AS stitchedID) AS _tenantid,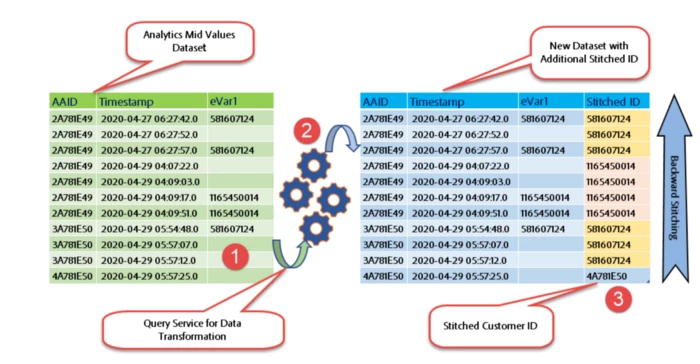
Note: The stitched ID is color-coded to have an easier understanding.
Pros
- In this approach, every known
customer_idis considered to stitch the customer journey. - For any given conversion for a given
customer_id, we could traceback his entire journey (based on the lookback window). - We can now report independently on every known customer from the same browsing cookie.
- We can now analyze the same customer on multiple devices.
- This logic can be applied to those customers who don’t have a CJA license.
Cons
- With Backfill logic, we might mark an event from a known
customer_idto an event that possibly originated from the previous knowncustomer_id. - The logic could be relatively complex as we need to ensure that we backfill a given
customer_iduntil we locate the previous knowncustomer_id. - Based on the volume of data (depending on the look-back window), the query will have to be scheduled either daily/weekly resulting in latency in the stitched data.
- Query Service approach when implemented on large volumes of Adobe Analytics data could be resource-intensive.
- Maintenance of the scheduled query on a regular basis.
- Any Privacy requests like GDPR/CCPA on Analytics will not be implicitly applied to new stitched dataset.
2. Forward Stitching using Query Service
On similar lines of Backfilling the customer_id, we could as well forward fill the customer_id as seen in the below example.
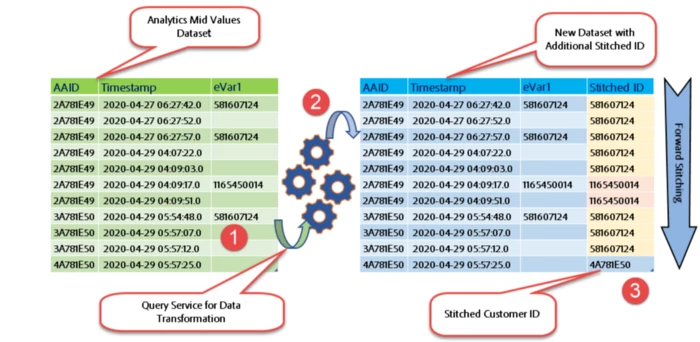
Note: The stitched ID is color-coded to have an easier understanding.
Pros:
- In this approach, every known
customer_idis considered to stitch the customer journey. - For any given conversion for a given
customer_id, we could traceback his entire journey (based on the lookback window). - We can now report independently on every known customer from the same browsing cookie.
- We can now analyze the same customer on multiple devices.
- This logic can be applied to those customers who don’t have a CJA license.
Cons:
- With forward fill logic, we might mark an event from a known
customer_idto an event possibly originating from the subsequent knowncustomer_id. - The logic could be relatively complex as we need to ensure that we forward fill a given
customer_iduntil we locate the next knowncustomer_id. - Based on the volume of data (depending on the look-back window), the query will have to be scheduled either daily/weekly resulting in a lag in the stitched data.
- Query Service approach when implemented on large volumes of Adobe Analytics data could be resource-intensive.
- Any Privacy requests like GDPR/CCPA on Analytics will not be implicitly applied to new stitched dataset.
3. Last Known MCID — First Known MCID
- Generate master lookup ideally with two fields. One of the fields is the
AAIDorMCID, followed by thecustomer_id. customer_idcould either be the LAST KNOWNcustomer_idor the FIRST KNOWNcustomer_idfor a givenMCIDbased on the client’s choice.- At any given point in time, we would ideally have one
customer_idalone perMCID, irrespective of the number of distinctcustomer_id’s that might flow in as part of Adobe Analytics data - In the below example, 116540014 is backfilled across every occurrence of the
MCID2A781E49
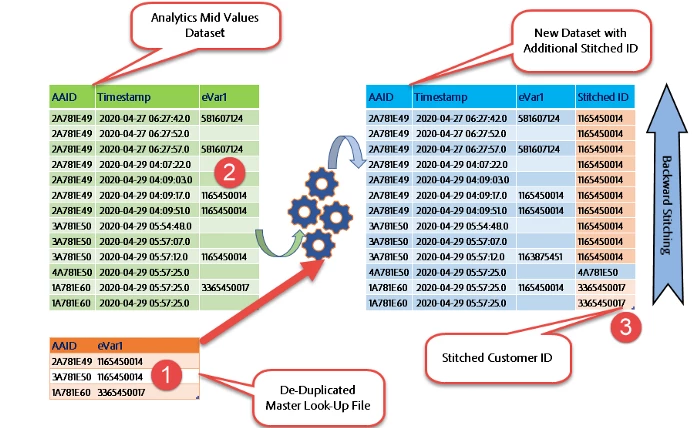
In the above example, eVar1 stores the customer_id. The last known eVar1 per MCID is backfilled for the rest of the occurrences of the event. Here, 1165450014 is copied across all the occurrences of the MCID 2A781E49. The rest of the Non-Blank eVar1 (e.g. 581607124) are ignored for the MCID 2A781E49
Pros:
- At any given point in time, we could reinstate the historical Stitched ID based on a new logic.
- The processing time/resources could be lesser as we need to identify only either the Last known or the First known
customer_idfor a given browsingMCID. - This logic can be applied to those customers who don’t have a CJA license.
Cons:
- We cannot report independently on every known customer from the same browsing cookie.
- Master Lookup size limitations.
- Any Privacy requests like GDPR/CCPA on Analytics will not be implicitly applied to new stitched dataset.
4. Adobe Experience Platform Engineering Recommendation
Since more and more customers are interested in generating insights with stitched data, Adobe Experience Platform Engineering came up with the new feature of generating the stitched dataset based on the mid-value. Currently, this feature is in beta, and validation of logic is in progress. The productized feature is called Cross Channel Analytics. Customers with CJA license will get this feature out of the box.
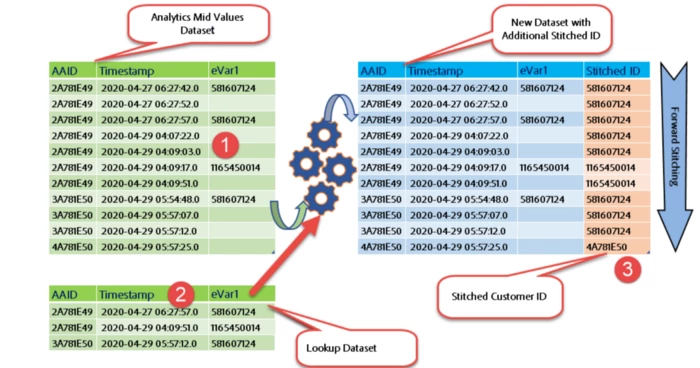
Pros:
- In this approach, every known
customer_idis considered to stitch the customer journey. - For any given conversion for a given
customer_id, we could traceback his entire journey (based on the lookback window). - We can now report independently on every known customer from the same browsing cookie.
- Stitched data being made available near real-time.
- We can now analyze the same customer on multiple devices.
- Similarly, we could also analyze people using the shared device.
- Any Privacy requests like GDPR/CCPA on Analytics dataset will be implicitly applied to new stitched dataset as well.
Cons:
- With Forward Fill logic, we might mark an event from a known
customer_idto an event possibly originating from the subsequent knowncustomer_id. - Periodic batch-reply would be required here to ensure the look-up dataset and stitched dataset is up-to-date. This could potentially change the reporting numbers to a small extent.
- This feature is available for only those customers who have a CJA license.
Create a connection with the stitched dataset in cross-device analysis to build a visualization and analyze how the customer interacts with different devices.
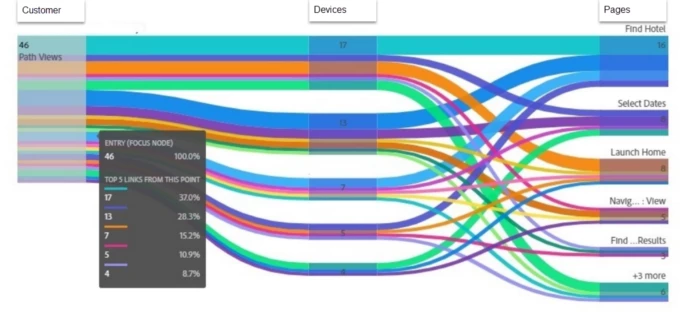
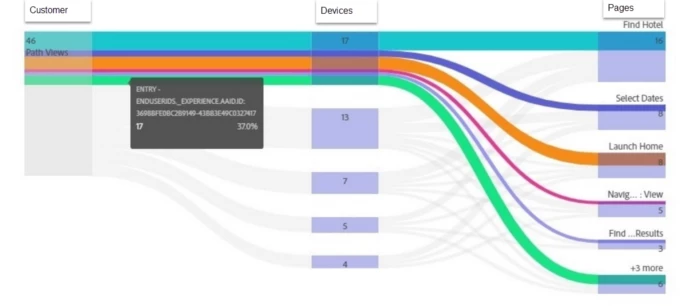
In the above example, you can see Customer X had a total of 46 sessions and used 5 devices to browse the site. You can see the distribution of traffic across different pages from Different devices from a customer in cross-device analysis.
Note: This solution also helps to analyze or report based on shared devices (people per device).
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetup.
References
- Adobe Experience Platform
- Adobe Analytics
- Cross-Device Analysis
- Customer Journey Analytics
- Query Service
- Cross Channel Analytics Overview
- Market Research
Originally Published: Mar 25, 2021