
Adobe Experience Platform's Setup for Apache Airflow on Kubernetes
Authors: Raman Gupta, Anand Gupta, Piyush Dewnani, Richard Ding, and Jody Arthur
Learn how Adobe Experience Platform is leveraging Apache Airflow support for Kubernetes to achieve high scale. This article builds on our previous work to build an orchestration service to enable users to author, schedule and monitor complex hierarchical jobs using Apache Airflow for Adobe Experience Platform. You can get additional insights on how Adobe Experience Platform is using Apache Airflow to exponentially scale its workflows for better performance here.
Adobe Experience Platform’s Orchestration Service provides APIs to author and manage multi-step workflows. Behind the scenes, this service leverages Apache Airflow as its workflow execution engine. With the 1.10.1 release, Apache Airflow added support for Kubernetes (K8S) Executor. Now, with K8S Executor, a new K8S pod is created for each instance of a workflow task, resulting in one-to-one mapping between the worker pod and its corresponding task. Based on the ability to scale K8S worker pods horizontally we decided to explore the use of K8S Executor to help us achieve higher scale with Adobe Experience Platform’s orchestration service.
With initial results that were promising, we decided to migrate more of our workload to Airflow’s K8S Executor. This post will illustrate how we set up Apache Airflow on Kubernetes to scale Adobe Experience Platform workflows and share some results from our benchmarking tests.
Architecture
Figure 1 shows the current architecture of Adobe Experience Platform Orchestration service with Apache Airflow set up to run in Kubernetes Executor mode. Apache Airflow’s Scheduler is a long-running daemon service. So, our first step was to deploy Airflow scheduler as a long-running pod inside a K8S cluster’s namespace.
Currently, all interaction between Airflow’s web server and its scheduler and execution engine happens through Airflow’s metastore. Airflow’s scheduler creates new worker pods by invoking the K8S master API. For each workflow task, one K8S worker pod gets submitted by the scheduler. Worker pods are configured to run in “run-once” mode with each running from a few minutes to a few days depending on the task. We have the Airflow scheduler configured to run as a long-running pod on K8S with the pod configured to run in a specific K8S namespace. This allows us to set up multiple Airflow schedulers on a single K8S cluster.
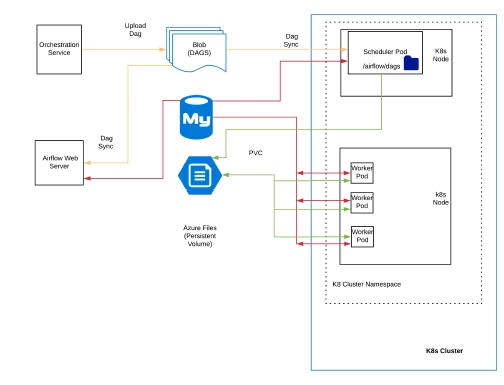
Syncing workflows dynamically on Airflow Cluster
All components of Airflow, including its web server, scheduler, and worker, expect the workflow files to be in their local directory. To accomplish this, workflow files are synced from our Azure blob store to the Airflow scheduler and Airflow server’s local workflow directory at /usr/local/airflow/dags. On Airflow scheduler, the local workflow directory is also mounted to the Azure files share folder. A persistent volume (PV) is created backed by the Azure file share and a corresponding persistent volume claim (PVC) is created in the namespace. This PVC is used in Airflow worker K8S pod(s) to make workflow files accessible locally.
Syncing of new workflow files to the local workflow directory paths for Airflow scheduler and Airflow web server is done using rclone utility which runs periodically. This job runs inside a sidecar container to the Airflow scheduler pod and syncs all workflow files from Azure blob to the local workflow directory.
Kubernetes resources and deployment
In a Kubernetes cluster, we have multiple installations of Airflow, each in a different namespace. Namespaces allow us to achieve tenant-level isolation and extend our multicluster model, where each customer has workflows running on a separate instance of Airflow. In each namespace we have an Airflow scheduler running in a pod along with some other K8S objects such as PVCs, configmaps, and secrets.
We use helm as a package manager to install and upgrade each of these K8S objects. Separate helm charts are maintained in the GitHub repository for each of these K8S constructs.
The following are a few configurations we did to set up Apache Airflow:
- Creation of K8S namespaces.
- Creation of persistent volume (for Adobe Experience Platform, these are backed by an Azure file share) & persistent volume claim.
Figures 2–4 below show some snippets from template yaml file from helm charts for each of the K8S objects we have deployed in a namespace.

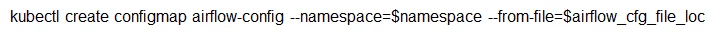

We maintain separate GitHub repositories for Airflow scheduler, Airflow worker, and the helm charts. Any changes are deployed using a CI/CD pipeline, which was built using Jenkins pipeline to sequentially deploy the changes to each K8S namespace in multiple environments for development and production releases. The pipeline first builds the docker images for Airflow scheduler and Airflow worker and uploads them to Adobe Experience Platform’s docker registry. It then uses helm client to install the updated helm charts with updated image tags to each of the namespaces.
Logging
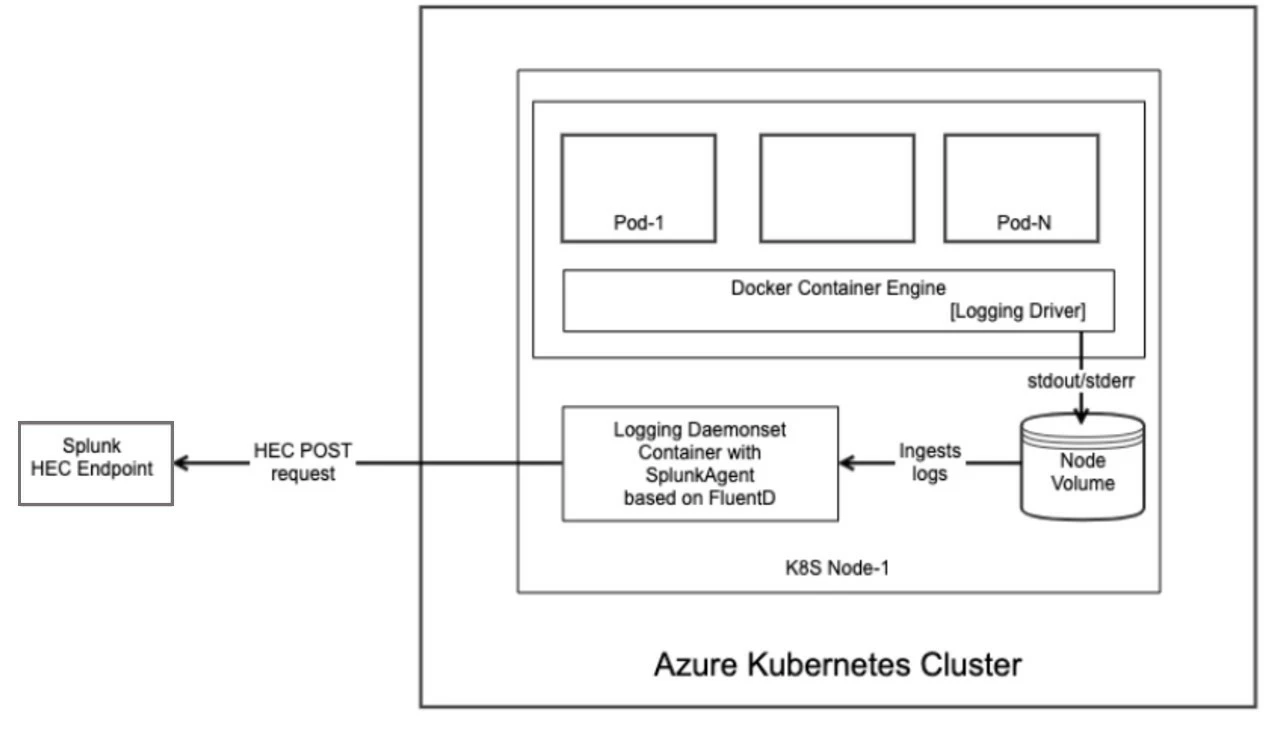
All application logs from the Airflow scheduler pod and worker pods are written to the console (Figure 4). For this we override the default logging_config_class with handlers to emit all Airflow scheduler and worker logs to the console.
We did encounter a few challenges when setting up Apache Airflow on Kubernetes, particularly when it came to logging. For example, we found that it can be challenging at times to distinguish the logs of one task from those for another. We were able to solve this issue and contributed the fix (#5264) to the Airflow community for issue AIRFLOW-4457. Our fix sets a custom log formatter for each task where each task’s logs are prefixed with a unique string (e.g. “{{ti.dag_id}}-{{ti.task_id}}-{{execution_date}}-{{try_number}}z”). This makes the log for a given task easily searchable and improves the debugging process. We can set this prefix format by setting the variable “task_log_prefi x_template” in the airflow.cfg file.
We also explored the use of a sidecar versus a DaemonSet approach for Airflow logging on K8S. We settled on a DaemonSet-based approach to publishing the worker pod’s logs for Airflow scheduler and Airflow worker to our Splunk server. The reason for this boils down to performance.
With Adobe Experience Platform, we can expect to run 1000’s of worker pods concurrently. Given this, we determined that a sidecar approach with an extra container and a logging agent in each pod would cause a significant resource footprint in the cluster. Moreover, creating a sidecar container for logging for every task would also significantly increase the time required to spin up a pod. Therefore, we decided on the DaemonSet approach in which a logging agent pod could be deployed to run on each node to forward all logs. We use the official splunk helm charts to deploy the DaemonSet into the K8S cluster.
Benchmarking results for Apache Airflow on Kubernetes
We ran various load tests to capture Apache Airflow performance on Azure Kubernetes Service. We ran multiple tests with 500 and 1000 Workflows created in a short period of time.
Airflow Version
Task Type
Airflow Configuration
Number of Azure nodes (type : F8s_v2)
MySQL Config
1.10.2
1 Bash Operator Task in each Workflow, configured to sleep for 60 minutes
MAX_THREADS=8
CONCURRENCY=1000
6
Core: 8, Disk Size: 100 GB, Connection limit: 2500
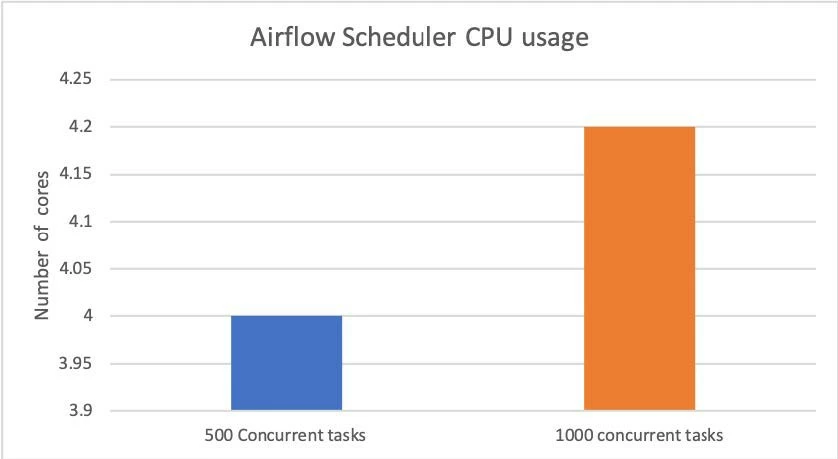
The following three figures show the resource usage patterns that we observed with 500 and 1,000 concurrent running tasks in a K8S namespace.

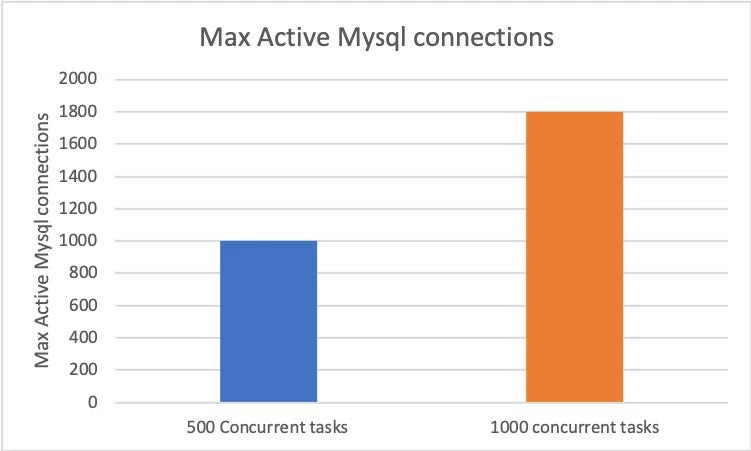
Observations, results, and moving forward
The following were some major observations from our work on setting up Airflow with K8S Executor:
- Airflow K8s worker pod(s) are memory intensive — In our benchmarking tests, we found that each worker pod required approximately 170 MB of memory.
- This setup results in a high number of MySQL connections — Each worker pod creates a MySQL connection for heart beating and task state management.
- The number of MySQL connections increases linearly with a number of pods — For 1,000 concurrent worker pods, there would be about 1,000 MySQL connections. However, we were able to identify a workaround, which is to use a connection pooler such as PgBouncer or ProxySQL between Airflow and Airflow database to allow pooling and reuse of existing connections.
- It seems that the K8S job watcher in Airflow’s K8S Executor can be used to keep track of worker pods health. There are discussions in the community about removing MySQL dependency (for a heartbeat) in K8S Executor mode to monitor worker pods’ health.
- The startup is a bit slow — In our testing, we observed that it can take a couple of minutes to move a worker pod from pending state to running state.
- In our testing, we also found that only one K8S pod was being created in every scheduler loop. However, we were able to improve the pod creation rate in airflow and have contributed our code for this to the Airflow community.
Overall, our results have been very promising. Deploying Apache Airflow on K8S cluster and running in K8S Executor mode, we have been able to achieve the scale we were looking for. And, we are now in the process of migrating all our Airflow installations from local executor mode to K8S Executor on K8S cluster to handle a variety of workloads for Adobe Experience Platform at a much higher scale.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Adobe Experience Platform — https://www.adobe.com/experience-platform.html
- Apache Airflow — https://airflow.apache.org/
- Azure — https://azure.microsoft.com/en-us/
- Azure Kubernetes Service — https://azure.microsoft.com/en-us/services/kubernetes-service/
- Blob Storage on Azure — https://azure.microsoft.com/en-us/services/storage/blobs/
- Kubernetes DaemonSet — https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
- Kubernetes Executor — https://airflow.apache.org/docs/1.10.1/kubernetes.html
- Kubernetes Standardized Glossary — https://kubernetes.io/docs/reference/glossary/
- Helm Charts for Kubernetes on GitHub — https://github.com/helm/charts
- Jenkins Pipeline — https://jenkins.io/doc/book/pipeline/
- Persistent volumes in Kubernetes — https://kubernetes.io/docs/concepts/storage/persistent-volumes/
- PgBouncer — http://www.pgbouncer.org/
- ProxySQL — https://www.proxysql.com/
- Rclone for cloud storage — https://rclone.org/
- Splunk Helm Charts for Kubernetes — https://github.com/splunk/splunk-connect-for-kubernetes
- Splunk Server — https://www.splunk.com/en_us/it-operations/server-monitoring.html
- Fixes and Improvements Contributed by Adobe Experience Platform:
- Code for enhancing task logs by adding task context — https://issues.apache.org/jira/browse/AIRFLOW-4457
- Support for creating K8S worker pods in batches — https://github.com/apache/airflow/pull/4434
- Code for improving K8S Executor’s pod creation rate — https://issues.apache.org/jira/browse/AIRFLOW-3516
Originally published: Dec 12, 2019