
Adobe Experience Platform Orchestration Service with Apache Airflow
Authors: Richard Ding, Tamal Biswas, Hitesh Shah, and Steven Sit
The following is a summary of how we deployed an orchestration service using Apache Airflow for Adobe Experience Platform.
Modern big data applications need to connect to many different backend services and build sophisticated data pipelines or workflows. These workflows need to be deployed, monitored, and run either on regular schedules or triggered by external events. Adobe Experience Platform component services needed an orchestration service to enable their users to author, schedule, and monitor complex hierarchical (including sequential and parallel) workflows for Apache Spark (TM) and non-Spark jobs.
What is the Adobe Experience Platform orchestration service?
We have built an orchestration service to meet Adobe Experience Platform requirements. It is architected based on a guiding principle to leverage an off-the-shelf, open-source orchestration engine that is abstracted to other services through an API, and extendible to any application through a pluggable framework. This orchestration service leverages an underlying execution engine for scheduling and executing various workflows. It also provides a pluggable interface for other services to create then run job workflows based on their unique needs.
Here is an example (diagram below): A data scientist creates a machine learning workflow by submitting training jobs on a scheduled basis to have better control of the training sessions and compute resources. Data scientists work within a familiar UI to build or select a model, specify the training dataset, and then pass on these details in form of a workflow to the orchestration service to schedule this training. This workflow may contain a single job or a chain of logically organized jobs.
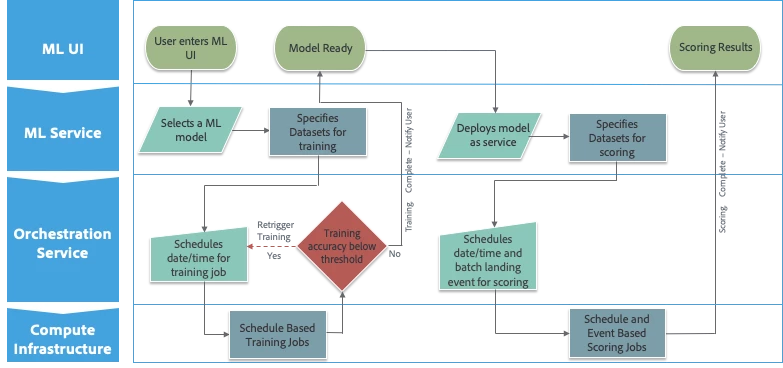
As part of the workflow definition, we introduce the concept of operators, which are interfaces to various resources like compute, storage, or even an event pipeline, that are needed by a specific job. For the majority of Adobe Experience Platform workflows, compute infrastructure is where the Spark jobs for machine learning training are executed. Data scientists have the option to run the workflow once, or to base it on a schedule or event-based triggers. They can even set criteria like minimum training accuracy. The criteria are checked within the workflow after the last job and, if required, the workflow will be re-triggered automatically by the orchestration service. Once the necessary training accuracy is achieved, the workflow stops after sending the appropriate notification to the user.
The Adobe Experience Platform orchestration service is a fully managed service using Apache Airflow as its scheduler and execution engine. Our orchestration service supports a REST API that enables other Adobe services to author, schedule, and monitor workflows.
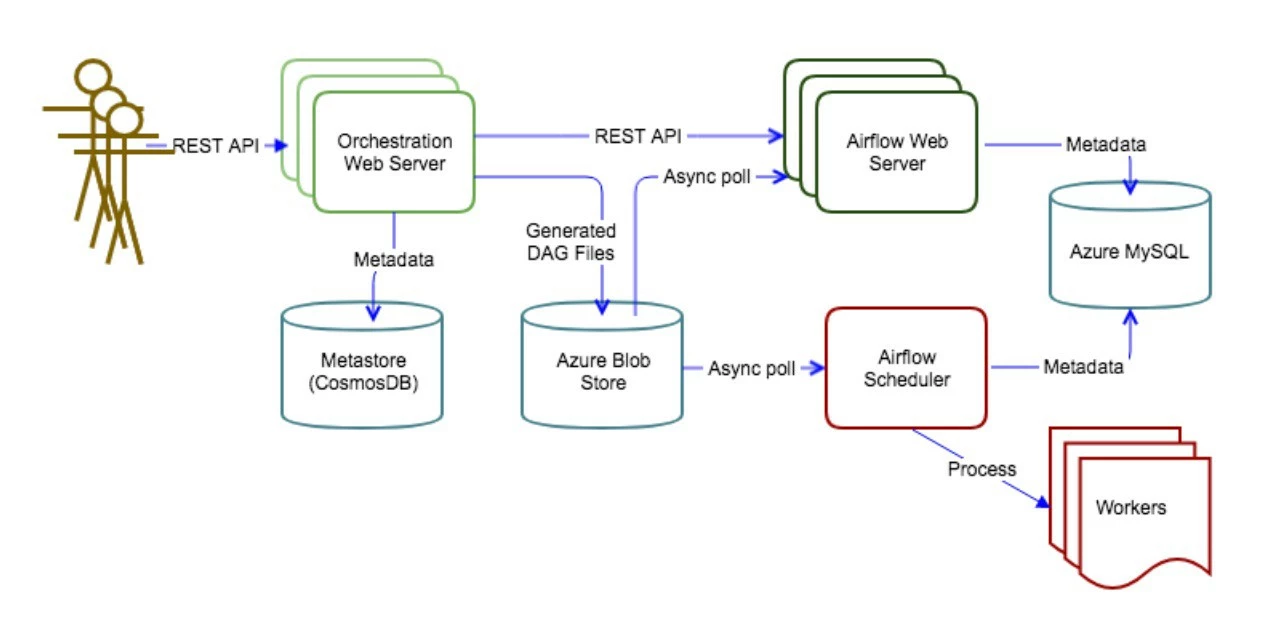
As the above diagram shows, the orchestration service is deployed on Azure and utilizes several Azure managed services. The same architecture can also be deployed to other cloud providers.
Flow summary:
- Orchestration service clients call REST API with a JSON payload to create workflows.
- Orchestration service validates the JSON and generates Airflow DAG (Directed acyclic graph) files which then are pushed to an Azure Blob Storage container.
- Orchestration service updates its metastore with metadata associated with the workflows.
- Airflow scheduler and web server pull the DAG files from Azure Blob Storage to their local DAG directories (in a one-minute interval).
- Airflow scheduler polls its local DAG directory and schedules the tasks. Airflow workers run these tasks.
- Orchestration service can also call Airflow REST endpoint(s) to trigger workflow runs.
Challenges
We had a few logistical as well as technical challenges to overcome while building the Adobe Experience Platform orchestration service.
The first challenge was to narrow down on a suitable open-source orchestration engine. We had several choices: Apache Airflow, Luigi, Apache Oozie (too Hadoop-centric), Azkaban, and Meson (not open source). We did an assessment and PoC to rank each option for criteria important to Adobe Experience Platform as well as to validate our assumptions. Airflow stood out because of its vibrant community, ease of deployment, rich intuitive UI, and extensibility.
The second challenge was regarding Python. One of the key learnings out of the PoC was that Airflow workflows are written as Python scripts. Python is very popular among our data scientists. However, we faced a significant adoption hurdle since for the majority of the Adobe Experience Platform services Java/Scala as the language of choice. We had to bake in a plan to overcome this challenge.
Lastly, Airflow did not have support for REST APIs. We did like the other advantageous features of Airflow that are suited for our requirements, including metadata in relational databases, module and extensible architecture, and an out-of-the-box UI for DevOps task. To overcome these shortcomings, we decided to build a REST API layer on top of Airflow and make it easy for other services to create workflows/DAGs in the form of a JSON payload. We created a translation engine within the orchestration service to create the actual Python DAGs (required by Airflow) out of the JSON-based workflows submitted through the REST APIs. This provided the necessary abstraction by not exposing the complexities of Python-based workflow scripts for development teams primarily focused on Java/Scala.
The Adobe Experience Platform orchestration service needed a layered design
We had diverse use cases when we started working on the Adobe Experience Platform orchestration service. There are traditional ETL pipelines, workflows for data landing, reports for batch queries, and machine learning workflows. Some of the workflows are triggered on schedules, but many are triggered on-demand. The workflows also vary greatly in terms of frequency, duration, and concurrency.
In order to handle this complexity, we decided to have a layered design and pluggable architecture. Adhering to the Adobe API-First design principle, the Adobe Experience Platform orchestration service exposed an internal REST endpoint, which provided an abstraction layer on top of the workflow engine (i.e. Airflow). In this abstract layer, we allow different teams to define separate JSON workflows for different use case domains.
We then asked each team to provide Task Handler plugins, which generate Airflow DAG files based on the JSON workflows. At runtime, the Adobe Experience Platform orchestration service invokes the right task handler based on the type of workflow, validates the generated DAG file, and pushes the file to a shared Blob storage.
The layered approach has these advantages:
- It makes easy for end users such as data scientists and UI/tooling developers to build workflows since they are just using another familiar endpoint of Adobe managed services.
- The pluggable architecture allows many teams to work on the project in parallel so that orchestration service team can concentrate on core features such as scalability, stability, and debuggability.
- Orchestration service layer is responsible for workflow authentication and authorization.
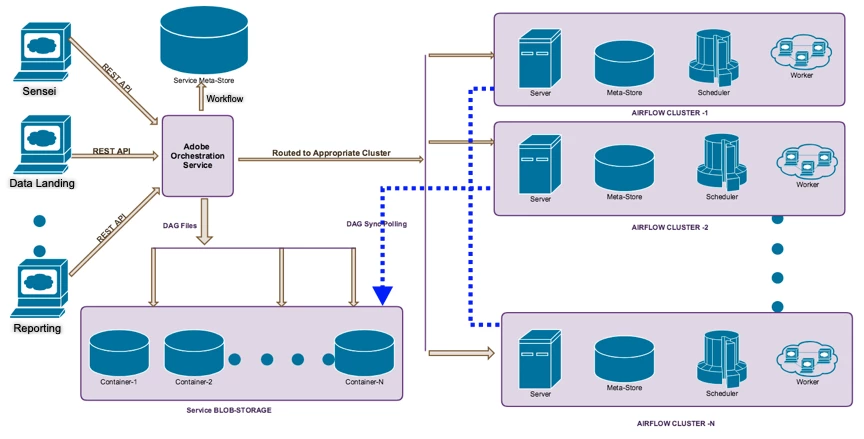
On the Airflow layer, we implemented multi-cluster deployment. All client services interact with a single Adobe Experience Platform orchestration service cluster. We provision one Airflow cluster instance specifically for every single service. At runtime, the orchestration service routes the workflows to the appropriate cluster by the service client ID. This gives us the flexibility to configure Airflow clusters differently to meet different use cases and provides a level of isolation. For example, during an A/B test, we got a requirement for a new Airflow cluster to divert some traffic to it.
We provided Docker images and documentation so that developers can easily setup an end-to-end development environment on their local machines. We only allow teams to integrate their workflows, handlers, and operators after all unit tests and end-to-end tests pass in the local setup. This proves very beneficial in our multi-team parallel development environment.
Airflow contributions
One of our clusters reported a production issue in which the orchestration service's tasks were getting stuck in the retry phase (up_for_retry state). On investigation, we found a race condition in the Airflow scheduler if retry interval is small. Increasing the retry interval for a workflow to a few minutes (from 5 to 8 minutes) seems to alleviate the problem. We contributed a fix (AIRFLOW-3136) for this race condition and the fix is available in Airflow v1.10.1.
Another issue we encountered is that some workflows are stuck in "INACTIVE" state for a long period of time, around 30 minutes. This is due to some MySQL errors that sometimes result in crashing of the main process of Airflow Scheduler. We upstreamed AIRFLOW-2703 to improve Scheduler's resiliency against MySQL DB errors and it is now available in Airflow v1.10.2.
Workflows are created and run only once for most of our ML use cases. We are consistently observing increased latency/delay in scheduling workflow or task runs. This is due to the increase in the number of DAG files on Airflow cluster. We backported AIRFLOW-1002 then implemented delete operation on the orchestration service REST endpoint. The delete REST API only removes the corresponding DAG file so that users can still have the history of workflow runs. We developed a workflow cleanup utility to remove the history of workflow runs from the Airflow cluster (AIRFLOW-1002). But we allow the Airflow cluster owner (i.e. client service) to set the retention policy.
In testing of Airflow Kubernetes executor, we found that Airflow Scheduler is creating worker pods sequentially (one pod per Scheduler loop) and this limited the K8s executor pod creation rate since we were launching many concurrent tasks. An enhancement was proposed and implemented (AIRFLOW-3516) that improved K8s executor pod creation rate.
What's next?
We are very happy with Apache Airflow as the workflow engine that powers the Adobe Experience Platform orchestration service. The layered and pluggable development model serves us well with many development teams from different organizations. The multi-cluster deployment model allows us to scale the service to support diverse use cases. But we are still early in our Airflow journey. We are continuously learning and acknowledge more development needs to be done.
We need to scale Airflow to support thousands of concurrent running workflows. We are now experimenting with Airflow Kubernetes Executor. We are able to launch 500 pods to run 500 concurrent tasks. To scale further (> thousand) we encountered MySQL connection issues. This seems to be a known issue and we are planning to work with the Airflow community to remove the task heartbeat management from Kubernetes Executor. We run multiple Airflow clusters in a shared Kubernetes cluster, with the unique namespace for each Airflow cluster.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups
Documentation and References
- Documentation: https://airflow.apache.org/
- Airflow is now Apache Top-Level Project: http://globenewswire.com/news-release/2019/01/08/1681851/0/en/The-Apache-Software-Foundation-Announces-Apache-Airflow-as-a-Top-Level-Project.html
- Apache®, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Originally published: Feb 4, 2019