
Mastering Adobe Customer Journey Analytics Experimentation: Your Comprehensive Crash Course
Introduction
The Adobe Customer Journey Analytics (CJA) Experimentation Panel is an Analysis Workspace template that empowers organizations to analyze and interpret their A/B tests and multivariate experiments within the CJA ecosystem. This specialized Analysis Workspace panel serves as a gateway to deep experimentation insights, enabling organizations to comprehensively understand how various iterations of their digital experiences influence user behavior patterns and drive business outcomes. Through its template framework for experimentation analysis, the panel enables businesses to make data-informed decisions with confidence and precision, leveraging advanced statistical methodologies and intuitive visualizations. To maximize the value of these experimental insights across your organization, it becomes paramount to establish strong alignment within your analytics and measurement teams regarding the specific experimentation approaches and methodologies being employed, ensuring these align with the CJA functionality detailed in the sections that follow. This alignment not only ensures consistent interpretation of results but also promotes a unified approach to experimentation that can scale effectively across different teams and initiatives.
In this crash course blog post, we will provide an in-depth exploration of the Experimentation Panel's key elements and functionalities. Our crash course will encompass four critical areas:
- Context Label Process: We'll review setting up and implementing the required context labels, which enable accurate experiment data identification and analysis within CJA.
- Experimentation Panel Input Settings: We'll explore the configuration options in the panel's input template and show how to optimize these settings for your business objectives and experimental designs.
- Underlying Logic and Statistical Techniques: We'll explain the calculations, statistical methods, and analytical frameworks that power the Experimentation Panel, demonstrating how to generate reliable and actionable insights.
- Understanding Experimentation Results: We'll explore how to interpret the panel's output, including conversion rates, lift calculations, confidence intervals, and statistical significance indicators to make informed decisions.
By the end of this blog post, you'll have a comprehensive understanding of how the CJA Experimentation Panel can elevate your approach to digital experiences and data-driven decision-making. Let's walk through a high-level overview of the Experimentation Panel process in CJA, guiding you through each critical step from initial setup to final analysis:
- Interpret the Experimentation statistical results in CJA Workspace
Setting Up Your Experimentation Panel Dimensions: Context Label Process
Before diving into the Experimentation Panel, it's crucial to properly set up your experiment using context labels. This process ensures that your experiment data is correctly identified and analyzed within CJA on a per Data View basis. Here are the steps to follow:
- Define your experiment variables: This crucial first step involves identifying and documenting the specific dimensional elements you want to test within your experiment. These components should be carefully selected to align with your testing objectives and should represent measurable aspects of your digital experience that you hypothesize will impact user behavior or business outcomes. Be mindful of the implications of the Data View variable persistence settings for your chosen experiment components, as these settings directly impact how experiment dimension data attributed over time. The persistence configuration determines how long experimental values remain associated with a person, which can significantly affect your analysis results in the reporting window. Additionally, depending on your data structure, you may need to leverage Data View component settings or derived fields to effectively parse both experiment identifiers and variant information from a consolidated field to values of interest, ensuring proper data organization for experiment analysis.
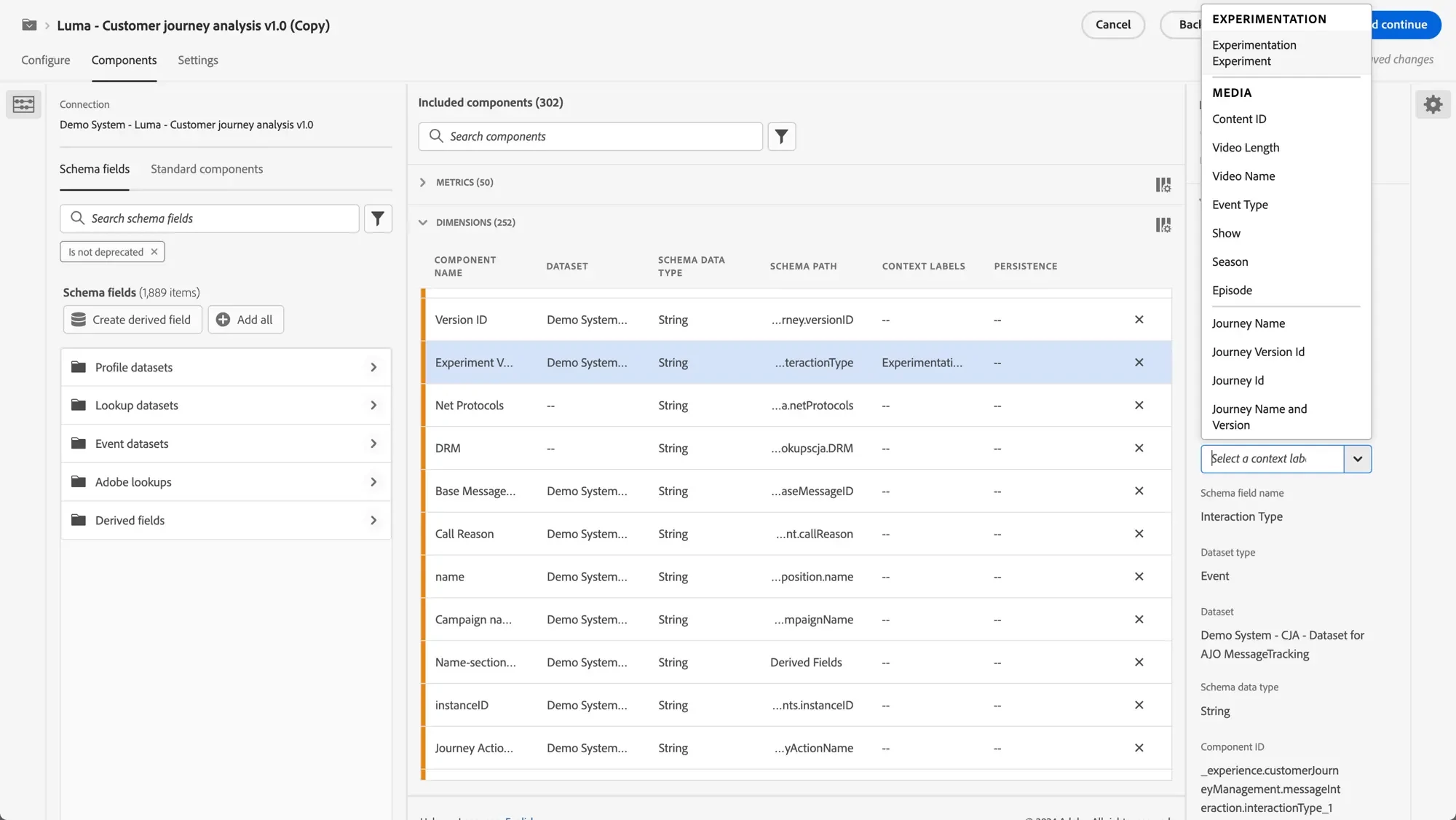
- Assign experiment context labels at the Data View components dimension level: Note that at this time only one set of experiment context labels can exist per Data View - if you need to support multiple experiments, you'll need to either swap the context labels or create separate Data Views for each differing experiment use case. Once your data structure is properly configured, proceed with assigning these two required pre-defined context labels to your experiment dimensions:
- Experimentation Experiment, which corresponds to the specific test or experiment being conducted. This label helps identify the overall experiment structure and allows for proper categorization within CJA.
- Experimentation Variant, which corresponds to the different versions or treatments being tested within the experiment. This label is crucial for maintaining experimental integrity, as it must accurately and consistently identify control and treatment groups. Any mislabeling or imbalance in these designations can severely compromise the statistical validity of the experiment results, since the panel's underlying calculations depend on precise group comparisons. Proper variant labeling ensures that control and treatment populations are correctly segmented, enabling accurate lift calculations and confidence intervals. Without this foundational accuracy in variant designation, the entire experimental framework and its statistical inferences would be unreliable.
- Implement experiment collection: Ensure that your experiment's dimensional event data, associated with the two experiment context labels, is captured and sent to Adobe Experience Platform (AEP) for eventual ingestion into the given CJA Connection and corresponding Data View.
Experimentation Panel: Configuring Input Settings
After setting up your experiment and ensuring data flows into CJA, the next crucial step is configuring the Experimentation Panel using the input template settings. These settings are the backbone of your analysis, allowing you to fine-tune the parameters that will shape your results. By carefully selecting these options, you can tailor the panel to focus on the specific aspects of your experiment that matter most to your business objectives. Let's explore how these settings enable you to define the scope and focus of your analysis:
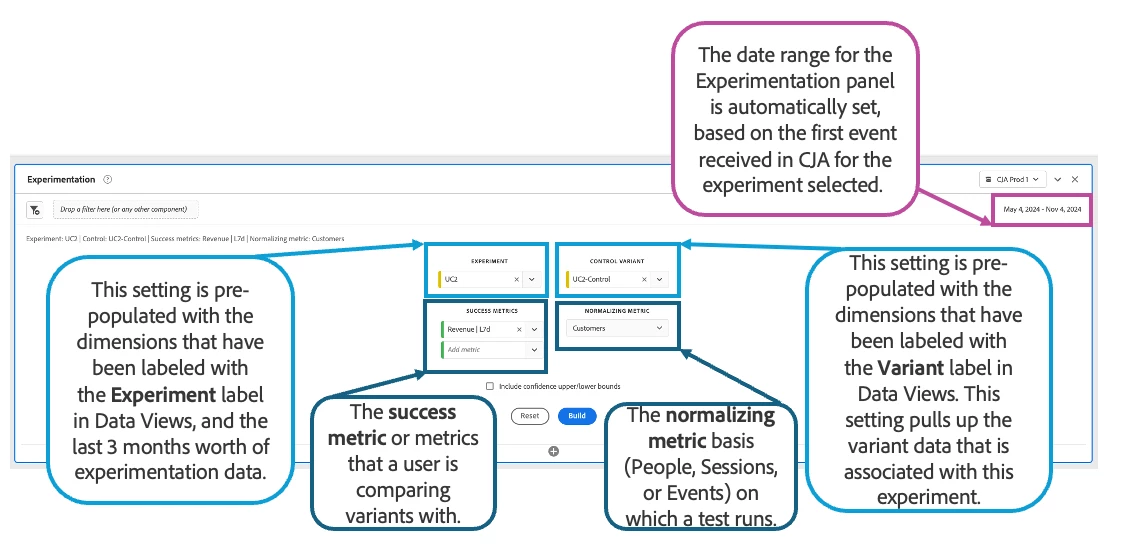
- Date Range: Specify the time period for your analysis. The Experimentation Panel automatically sets this based on when it first received data for the selected experiment. You can adjust this range to be broader or narrower as needed.
- Experiment: A set of variations on an experience shown to users to determine which performs best. An experiment consists of two or more variants, with one designated as the control variant. This setting automatically displays values from dimensions labeled with the Experiment tag in data views, showing the last 3 months’ of experimentation data.
- Control (Variant): You must select one variant as the control, and only one variant can serve as the control variant. This setting automatically displays values from dimensions labeled with the Variant context label in Data View and shows the variant data associated with this experiment.
- Success Metrics: Choose the success metric(s) for your experiment (e.g., orders, revenue). Note that not all calculated metrics are compatible with the Experimentation Panel.
- Normalization Metric: Choose a baseline metric (People, Sessions, or Events) to standardize results across variants with different exposure levels.
- Include confidence upper/lower bounds: Enable this option to display the upper and lower confidence interval boundaries.
Experimentation Panel Logic: A Deep Dive into Key Elements
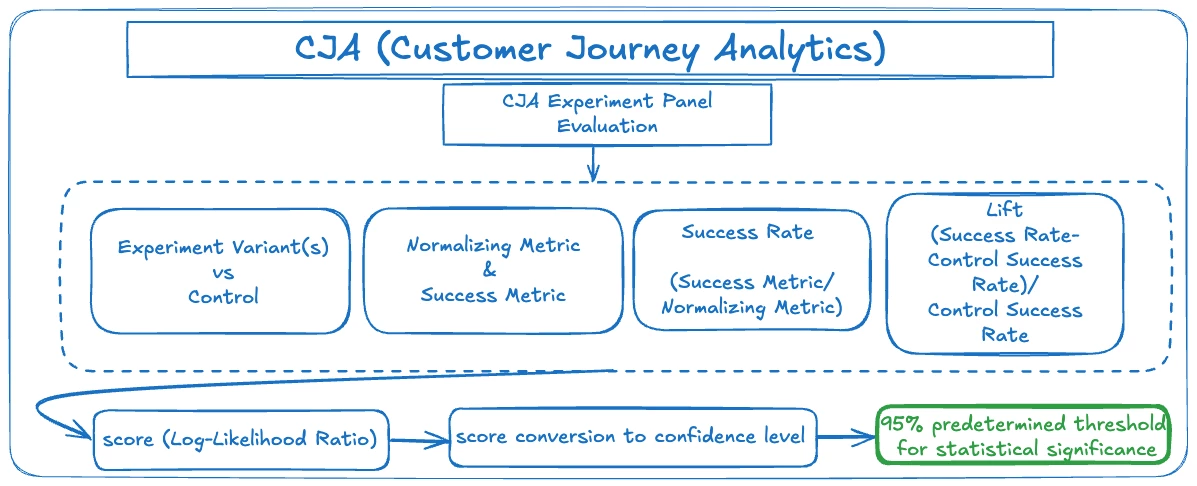
The Experimentation Panel uses a statistical method called Sequential Probability Ratio Test (SPRT) for ongoing analysis of test results. This approach compares different treatment groups against a control group by calculating a Log-Likelihood Ratio score for each group, which converts into a confidence level. The higher the confidence level, the stronger the evidence that a treatment group is outperforming the control.
This method's key strength lies in its ability to deliver statistically valid results at any point during the experiment without risking false positives. This continuous monitoring capability makes it invaluable for businesses needing quick insights. Teams can check results frequently throughout the experiment, allowing decision-makers to act promptly on significant findings and optimize their testing strategies effectively.
The Experimentation Panel's statistical methods form the foundation of your experiment analysis. Understanding these core elements will help you interpret results with clarity:
- Control (Baseline): The control group functions as the fundamental reference point for all experimental comparisons, serving as the established baseline against which all other variants are measured. By definition, the control group is assigned a 0% lift and 0% confidence level, as it represents the current standard or existing version being tested. This baseline designation is crucial for maintaining consistency in measurement and enables meaningful comparative analysis across all experimental variants.
- Comparison: Each row in the results table represents a distinct experimental variant or treatment group, which is systematically evaluated against the designated control group. This comparison framework allows for visualization of how different variations perform relative to the baseline, enabling precise measurement of the impact of each experimental modification. The row-by-row structure ensures that each variant's performance metrics are directly comparable to the control, facilitating straightforward interpretation of experimental outcomes.
- Lift Calculation: Lift represents the relative performance improvement of a variant compared to the control group, expressed as a percentage difference in success rates. The calculation follows this formula: (Success Rate - Control Success Rate) / Control Success Rate. For example, if a variant achieves a 15% success rate while the control group shows a 10% success rate, the lift would be (0.15 - 0.10) / 0.10 = 0.50, indicating a 50% lift in performance. This metric is essential for quantifying the magnitude of improvement that each experimental variant delivers compared to the baseline control group, helping teams assess the practical significance of their experimental results alongside statistical confidence measures.
- Confidence Calculation: The confidence calculation uses a method called Sequential Probability Ratio Test (SPRT) to determine how sure we can be about the results. Think of it like this: as customers interact with different versions of your website or app, the system continuously collects data and updates its level of certainty about which version is performing better. The beauty of this approach is that it's like checking the score of a game while it's still being played - you can look at the results at any time, and the statistics remain valid. This is different from traditional testing methods where you have to wait until the end to draw conclusions. For example, if Version A shows strong positive results early on, you can be confident in those results without waiting for the entire test period to end. This flexibility allows businesses to make faster, data-informed decisions while maintaining statistical reliability.
- Threshold: The panel employs a predetermined statistical significance threshold of 95%, which serves as the critical boundary for determining experimental validity. This threshold represents the conventional level of confidence required in statistical testing, ensuring that any observed differences between variants are unlikely to have occurred by chance. When the confidence level exceeds this 95% threshold, it provides strong statistical evidence that the observed differences are meaningful and can be used to inform decision-making with a high degree of certainty.
- Interpretation: The relationship between lift and confidence is directly proportional - as the measured lift in performance increases, the statistical confidence in that result typically increases as well. This means that variants showing larger improvements over the control group tend to accumulate stronger statistical evidence supporting their effectiveness. For instance, if a variant demonstrates a 50% lift in conversion rate, it's more likely to achieve high confidence levels compared to a variant showing only a 5% lift. This pattern occurs because larger differences in performance are less likely to occur by chance, making it easier to establish statistical significance. However, it's important to note that this relationship also depends on other factors such as sample size and the consistency of results over time. Groups with higher lifts will generally achieve higher confidence levels more quickly, allowing for faster decision-making in the experimentation process.
- Anytime Validity: The "Anytime Valid" feature is a statistical property that maintains the integrity of confidence levels throughout the entire experiment lifecycle. This innovative approach enables researchers and analysts to examine results at any point during the testing period, whether it's after a few days or several weeks, while maintaining statistically sound conclusions. Unlike traditional fixed-horizon testing methods that require predetermined sample sizes and duration, this flexibility allows teams to make informed decisions as soon as significant results emerge. The ability to implement flexible stopping rules - deciding to conclude an experiment early if clear results emerge, or extending it if results are inconclusive - doesn't inflate the risk of false positives or compromise the statistical validity of the findings. This powerful feature balances the need for rigorous statistical analysis with the practical demands of agile business decision-making.
The Mathematics Behind Anytime Valid Inference in the Experimentation Panel
To provide a comprehensive understanding of the mathematical foundations underlying Anytime Valid Inference for the results presented, we will delve into the SPRT approach. This sophisticated statistical method forms the cornerstone of Experimentation Panel analysis, enabling us to draw robust conclusions from our experimental data while maintaining statistical integrity throughout the testing process.
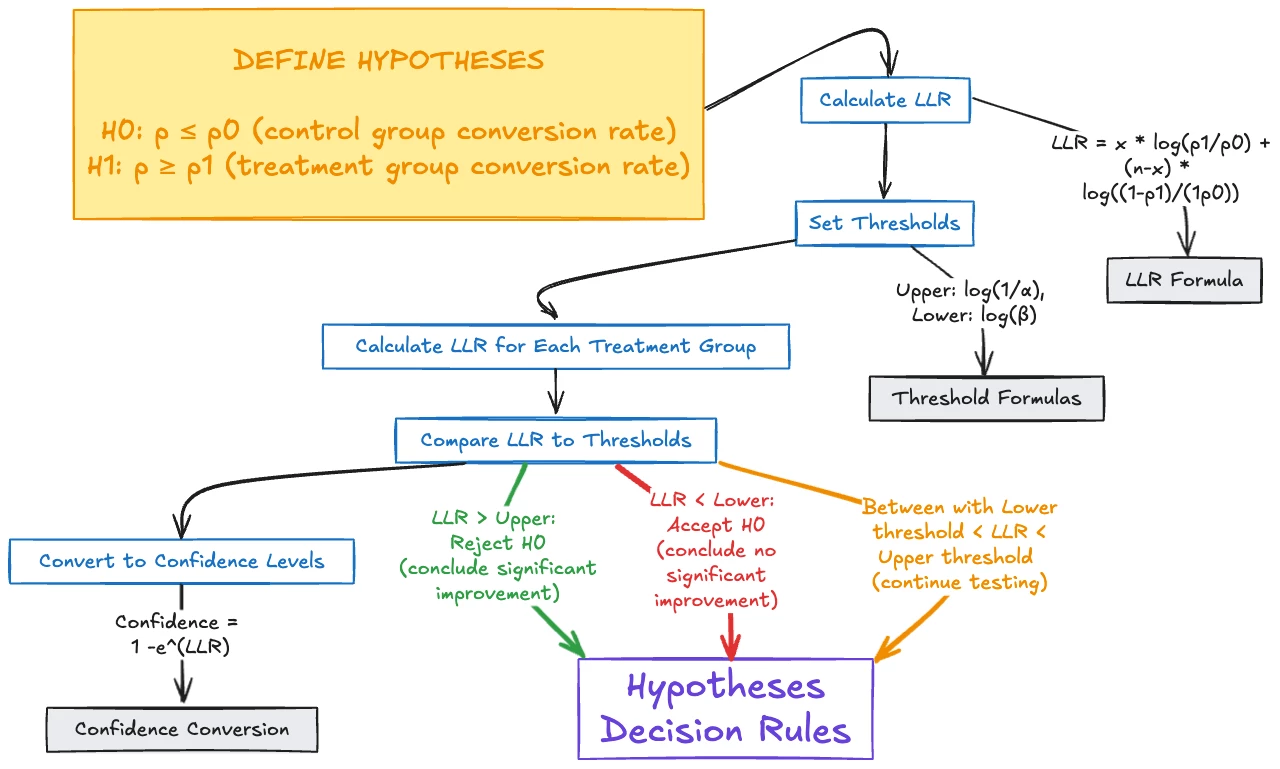
- Define hypotheses:
H0: p ≤ p0 (control group conversion rate)
H1: p ≥ p1 (treatment group conversion rate)
- Calculate the Log-Likelihood Ratio (LLR) for each group:
LLR = x * log(p1/p0) + (n-x) * log((1-p1)/(1-p0))
Where:
x = number of successes
n = total number of trials
p0 = control group conversion rate
p1 = treatment group conversion rate
- Set thresholds:
Upper threshold: log(1/α), where α is the desired false positive rate
Lower threshold: log(β), where β is the desired false negative rate
- Calculate LLR for each treatment group:
Example: LLR = successes * log(treatment_rate/control_rate) + (trials-successes) * log((1-treatment_rate)/(1-control_rate))
- Compare LLR to thresholds:
If LLR > Upper threshold: Reject H0, conclude significant improvement
If LLR < Lower threshold: Accept H0, conclude no significant improvement
If Lower threshold < LLR < Upper threshold: Continue testing
- Convert to confidence levels:
Confidence = 1 - e^(-LLR) (approximate conversion)
Example: For a given LLR, calculate 1 - e^(-LLR) to get the confidence level
These calculations demonstrate the robustness of the Anytime Valid Inference method in providing statistically sound confidence levels throughout the entire duration of an experiment. By employing this sophisticated approach, researchers and analysts can continuously monitor their experiments without compromising the integrity of their results or increasing the likelihood of false positives. This methodology offers a significant advantage over traditional fixed-horizon testing methods, as it allows for flexible stopping rules and real-time decision-making based on accumulating evidence.
The ability to conduct ongoing monitoring without inflating the risk of false positives is particularly valuable in dynamic business environments where timely insights can drive critical decisions. It empowers organizations to respond swiftly to emerging trends or significant findings, potentially leading to faster implementation of successful variations or early termination of underperforming experiments. This balance between statistical rigor and operational flexibility makes the Anytime Valid Inference method an invaluable tool in the arsenal of data-driven decision-makers across various industries.
Interpreting Experimentation Panel Results
The Experimentation Panel offers a suite of data visualizations and summary results designed to enhance your understanding of observed experiment performance. At the forefront of the panel, you'll encounter summary change visualizations, which provide a recap of your selected panel settings. These visual summaries offer a quick snapshot of key metrics and experiment parameters, allowing for assessment of overall performance trends. For added flexibility and ongoing optimization, the panel features an edit function, accessible via the pencil icon in the top right corner, enabling you to make real-time adjustments to your experiment parameters as needed.
By default, the Experimentation Panel uses an 'Exposure to multiple variants' filter that only includes Person IDs exposed to one distinct variant at the People container level. This filter prevents experiment results from being skewed by users who receive multiple variants. However, since this filtering depends on experimentation execution and CJA identity declaration, you may need more traffic to reach statistical confidence if many people receive multiple variants after stitching is applied. You can add more filter logic to further refine the experimentation variant inclusion results.
A text summary offers a quick overview, indicating whether the experiment is conclusive and summarizing the outcome. The panel determines conclusiveness based on statistical significance (refer to Statistical methodology). You'll also see summary numbers for the top-performing variant, highlighting its corresponding lift and confidence levels.
For each success metric you've chosen, the panel displays two key visualizations: a freeform table and a conversion rate line chart. These visual aids help you analyze your experiment results in depth. As per Experience League Experimentation panel output interpretation of the observed results is as follows:
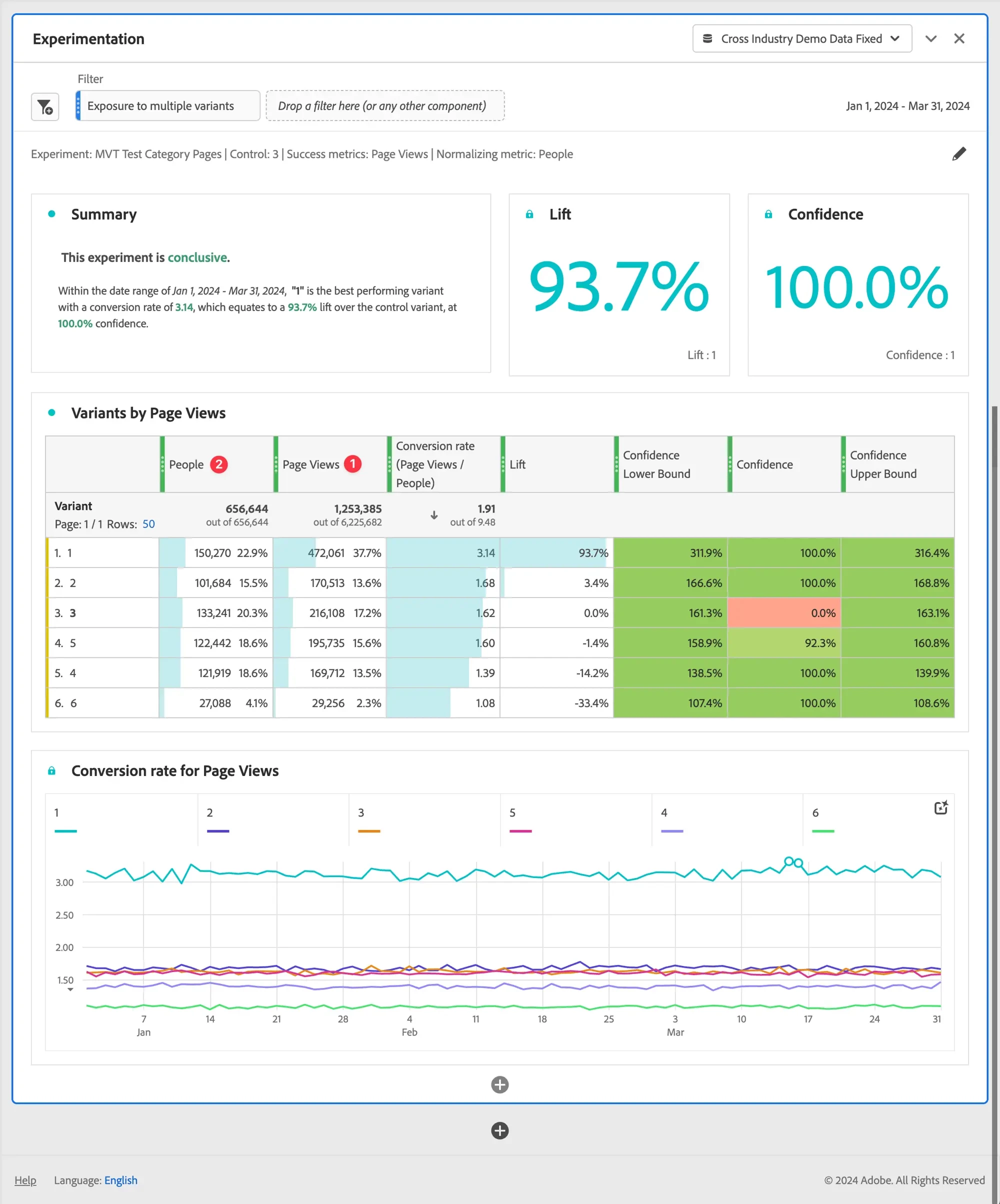
1. Experiment is conclusive: Every time you view the experimentation report, the data that has accumulated in the experiment up to this point is analyzed. The analysis declares an experiment to be conclusive when the anytime valid confidence crosses a threshold of 95% for at least one of the variants. With more than two arms, a Benjamini-Hochberg correction is applied to correct for multiple hypothesis testing.
2.
Best performing variant: When an experiment is declared to be conclusive, the variant with the highest conversion rate is labeled as the best performing variant. Note that this variant must either be the control or baseline variant, or one of the variants that crosses the 95% anytime valid confidence threshold (with Benjamini-Hochberg corrections applied).
3.
Conversion rate: The conversion rate that is shown is a ratio of the success metric value ➊ to the normalizing metric value ➋. Note that this value can be larger than 1, if the metric is not binary (1 or 0 for each unit in the experiment)
4.
Lift: The Experiment report summary shows the Lift over Baseline, which is a measure of the percentage improvement in the conversion rate of a given variant over the baseline. Defined precisely, it is the difference in performance between a given variant and the baseline, divided by the performance of the baseline, expressed as a percentage.
5.
Confidence: The anytime valid confidence that is shown is a probabilistic measure of how much evidence there is that a given variant is the same as the control variant. A higher confidence indicates less evidence for the assumption that control and non-control variant have equal performance. The confidence is a probability (expressed as a percentage) that you would have observed a smaller difference in conversion rates between a given variant and the control. While in reality there is no difference in the true underlying conversion rates. In terms of p-values, the confidence displayed is 1 - p-value.
Conclusion
The CJA Experimentation Panel is a template that simplifies the analysis and interpretation of A/B tests and multivariate experiments. It provides a toolkit—from experiment and variant component context labeling in Data Views to built-in statistical methods—that helps organizations make confident, data-informed decisions about their experiments.
Key takeaways from this crash course include:
- AEP>CJA Data Integration: Understanding how experiment results data flows from AEP to CJA is essential for accurate analysis
- Flexible per Experiment Panel Configuration: The Experiment panel offers customization options, allowing you to tailor analysis parameters to your specific testing needs
- Experimentation Panel Statistical Methods: Built on Sequential Probability Ratio Tests (SPRT), the panel provides reliable, anytime-valid statistical insights
- Experimentation Panel Results and Visualization: The panel offers charting and detailed performance metrics that simplify tracking, understanding, and communicating experimental results
Through effective use of the CJA Experimentation Panel, organizations can unlock comprehensive insights into user behavior patterns, implement data-informed improvements to their digital experiences, and achieve substantial business results through systematic experimentation and analysis. By leveraging the panel's statistical methodology and intuitive visualization capabilities, teams can make more informed decisions about their digital initiatives, ultimately leading to enhanced user engagement and improved business outcomes.