Enable Partial Ingestion for a Dataset already receiving clickstream data from the Web SDK
I have configured a datastream/dataset/dataflow to receive clickstream data from a website the has an event driven data layer and the Adobe WebSDK.
Looking at the dataflow runs, there are some batches failing due to typeOf errors (expected string, found integer).

The developers in charge of the event driven data layer are having trouble replicating the specific typeOf error to be able to fix it in the data layer, and the data in question is part of the product array so it would be cumbersome to add code checks in the tag manager to convert the data to the proper type.
There are options to enable partial ingestion of a dataset within a typical error threshold, but i don't see any way to apply this setting to a dataset that is already receiving data from the webSDK.
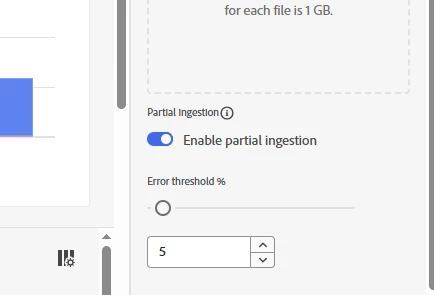
The toggle in the picture appears to just be for dragging/dropping files into the dataset.
Is there something in the UI i'm missing? I don't think it is worthwhile to make data layer changes or tag manager changes because 2 out of 80k records are causing a batch to fail, but I think that AEP should still ingest the batch if only 2 out of 80k records are failing.