
MobileSDK – CDP: Data Refresh Strategy
MobileSDK – CDP: Data Refresh Strategy
Authors: Meera Ankam, Raminder Singh Bagga
Introduction
In mobile app development, ensuring data accuracy and completeness is crucial. Mobile SDKs capture user interactions and other relevant data, but transmission failures can lead to incomplete or lost batches due to network issues, server downtime, or SDK bugs. Reingestion mechanisms retransmit failed data batches to prevent data loss.
This blog presents strategies and best practices for reingestion to effectively manage and mitigate the impact of failed batches from Mobile SDKs to the Edge Network and into the Adobe Experience Platform (AEP) Dataset.
Real World Customer Example
Background
We're diving into a strategy guide on re-ingesting failed batches using Adobe Mobile Edge SDK for data collection. Many of our customers rely on this SDK to construct XDM (Experience Data Model) on the client side, ensuring consistent data structure and interoperability across Adobe Experience Cloud solutions. The data is then transmitted to AEP (Adobe Experience Platform) through Edge.
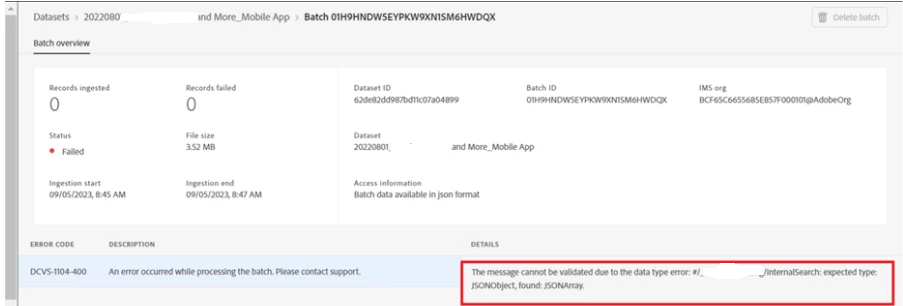
However, during one release, a customer's mobile developers encountered a misconfiguration in XDM, resulting in 5500 failed batches. This misconfiguration caused the data collection process to fail when handling JSON objects from internal searches. In this blog, we'll explore how to address such issues, ensuring no critical data is lost.
Challenges
Re-ingesting failed batches with MobileSDK presented several challenges:
- Lack of Automated Reingestion in AEP: AEP does not have an automated capability to re-ingest failed batches, so we must ensure data security both at rest and in transit during restoration.
- Large Data Volume: The size of the failed batches is substantial, both in terms of the number of files and the data volume. This requires significant external storage and processing power for restoration.
- Inconsistent Data Attributes: The mapping used in data collection preparation couldn't be applied to ingest the failed batches into the AEP dataset. This is because data originating from various interactions has different attributes when streamed through the MobileSDK.
We'll delve into these challenges and how to overcome them in the sections that follow.
Impact of MobileSDK Failed batch:
The failed batches had a significant impact on both data integrity and user experience:
- Substantial Data Loss: The loss of 5500 batches of data greatly impacted the ability to target and engage the intended audience, making re-ingestion essential.
- Compromised Personalization: Personalization efforts suffered as they rely heavily on the events that failed to ingest. Without these crucial data points, delivering personalized experiences was challenging.
In this blog, we'll explore how to address these issues through effective reingestion strategies, ensuring your data remains accurate and your personalization efforts stay on track.
Below screenshot shows, how a failed MobileSDK batch looks like due to invalid JSON array objects which occurred due to misconfiguration of JSON objects:
How to Avoid Failures for Incoming Data:
Dealing with incoming data can sometimes lead to failures, especially when handling complex JSON object arrays. To mitigate these issues, you can use AEP’s data mapper functions to correct common errors.
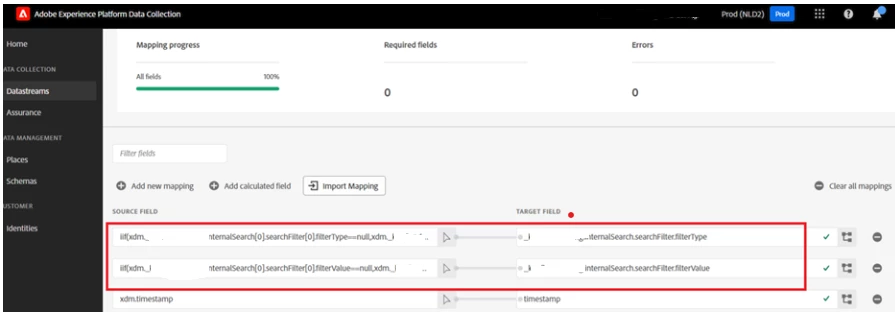
Fixing JSON Object Arrays
If you're encountering problems with filterType in searchFilter, the following data preparation fix can help:
FIX: Data prep:
iif(body.xdmEntity.<tenant>.internalSearch[*].searchFilter[*].filterType==null,
body.xdmEntity. <tenant>.internalSearch.searchFilter[0].filterType,
body.xdmEntity. <tenant>.internalSearch[*].searchFilter[*].filterType)
This function checks if filterType is null and, if so, uses a default value from the first searchFilter. This approach ensures that your data is processed correctly and minimizes the risk of failures during ingestion.
Implementing this fix can help avoid failures in all incoming data, maintaining smooth and reliable data ingestion.
How to re-ingest the failed batches:
Re-ingesting Failed MobileSDK Batches: A Step-by-Step Guide
To address and re-ingest failed MobileSDK batches efficiently, follow these detailed steps:
1. Retrieve and Download Failed Batches
- Retrieve Failed Batch ID: Use the Catalog Service API to get a sample failed batch ID.
- Download the Batch: Utilize the Data Access API to download the failed batch file and place it manually in an S3 bucket.
2. Process and Prepare Data
- ETL Job for Cleanup: Set up an AWS Glue job to process the file. Move it to a different folder within the same S3 bucket and remove the _errors element from each file.
3. Re-ingest Data
- Scheduled Dataflow: Create a scheduled dataflow in AWS to ingest the cleaned data from S3 into AEP. Use the downloaded file as the master file and provide the necessary field mappings for ingestion.
4. Batch Processing
- Upload in Batches: Given the volume of data (5500 batches totalling 2TB), upload files in batches of 1500 into S3. This aligns with AEP ingestion guardrails, which suggest a batch size between 256MB and 100GB, with a maximum of 1500 files per batch.
5. Incremental Ingestion
- Master File and Incremental Data: For the initial set, schedule the dataflow to ingest the master file. Once successfully ingested, upload up to 1500 files per batch, using the same mapping as the master file. This will allow incremental ingestion based on the predefined mappings.
6. Final Steps
- Complete Processing: Continue to download, process, and ingest any remaining failed batches into the AEP dataset, following the same procedures and mappings.
By following these steps, you can effectively manage and re-ingest failed MobileSDK batches, ensuring all critical data is successfully processed and integrated into AEP.
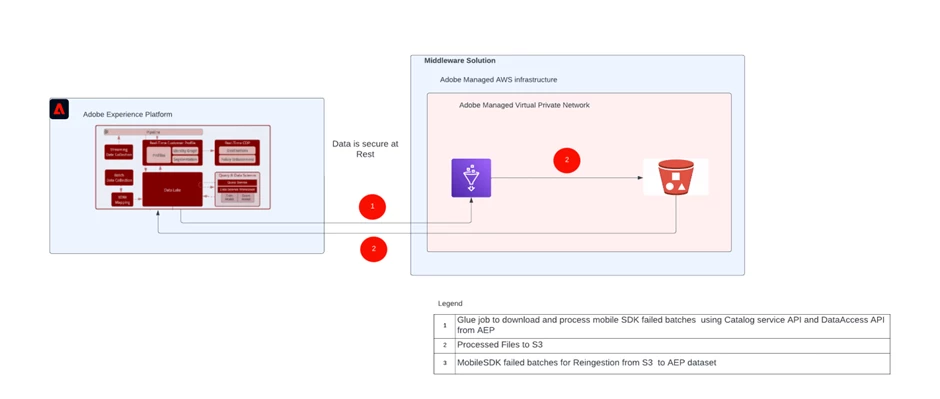
AWS S3 Architecture
Here is the high-level simplified architecture of AEP and middleware ingestion:
In step 1, the data is downloaded with by AWS ETL Glue jobs which is configured to use data access API, which helps to download the failed batch data from the platform.
The downloaded data is kept in S3 bucket. Perform the cleanup activities on the files downloaded. Further, use AEP S3 OOTB connector for setup the S3
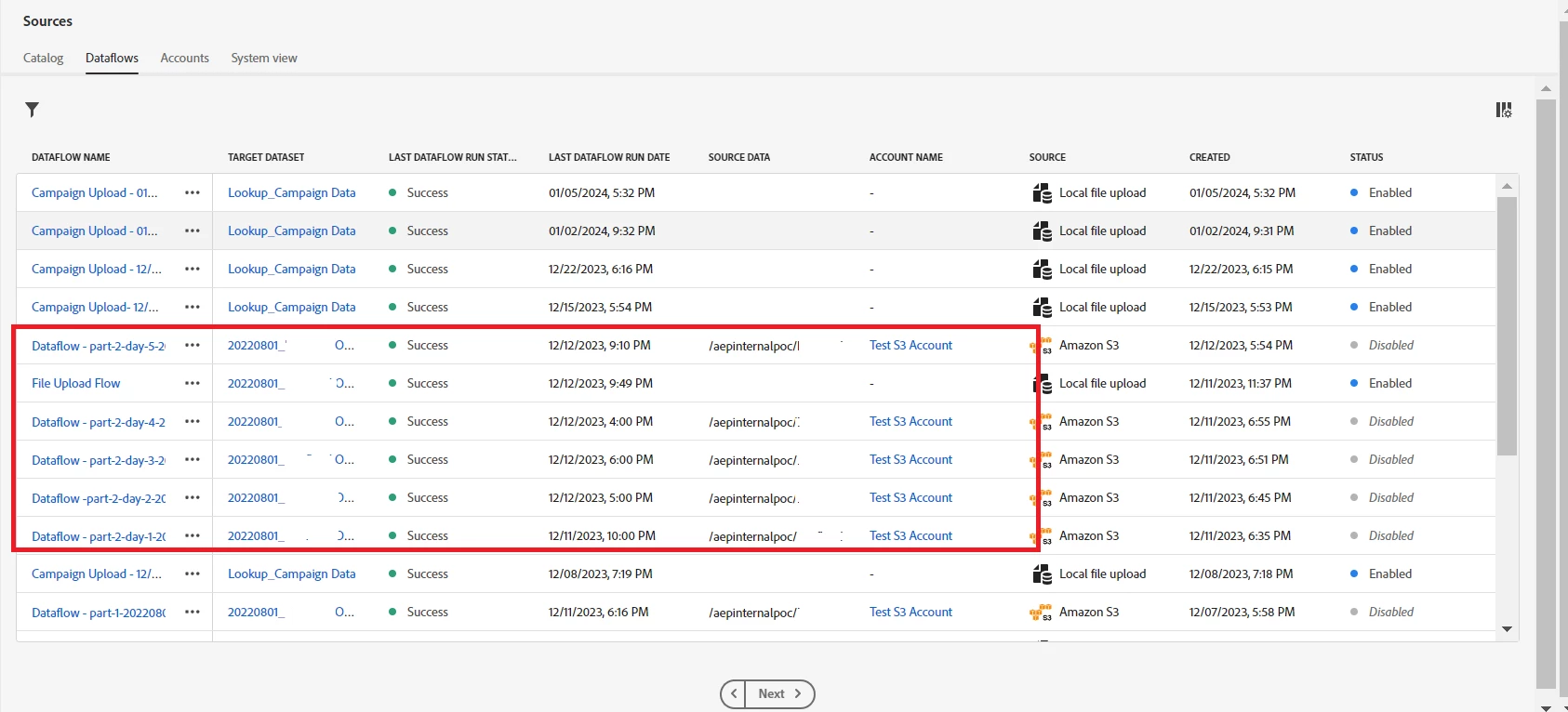
One time batch S3 dataflow ingestion:
Conclusion:
Re-ingesting failed batches is a vital component of maintaining effective data processing pipelines. Implementing a robust re-ingestion strategy delivers several key benefits:
- Data Integrity: Re-ingestion ensures that errors or missing data points are identified and corrected, preserving the accuracy and completeness of the data.
- Improved Reliability: Automating the re-ingestion process enhances the reliability of data pipelines, minimizing the risk of incomplete or inaccurate data sets.
- Enhanced Performance: Timely re-ingestion reduces processing delays, ensuring that downstream analytics and applications receive up-to-date and accurate information.
- Operational Efficiency: Clear protocols and automated mechanisms streamline operations, allowing teams to focus on strategic tasks rather than manual error correction.
- Resilience to Failures: A well-designed re-ingestion strategy improves the overall resilience of data pipelines, enabling systems to recover swiftly from failures and maintain continuous data flow.
- Regulatory Compliance: For regulated industries like finance or healthcare, re-ingestion processes support adherence to data governance standards and regulatory requirements.
In summary, a robust re-ingestion strategy not only addresses failures effectively but also strengthens the overall data processing infrastructure, ensuring reliability, accuracy, and compliance.
Related links:
https://developer.adobe.com/experience-platform-apis/references/catalog/
https://developer.adobe.com/experience-platform-apis/references/data-access/
Amazon S3 Source Connector Overview | Adobe Experience Platform
Best Practices For Data Modeling | Adobe Experience Platform