Question
Data Requirements in Customer AI | Adobe Experience Platform
Hello,
We finished this step
2D image generated by VLM in visionOS
As you can see, the result is based on another image dataset.
This is a result
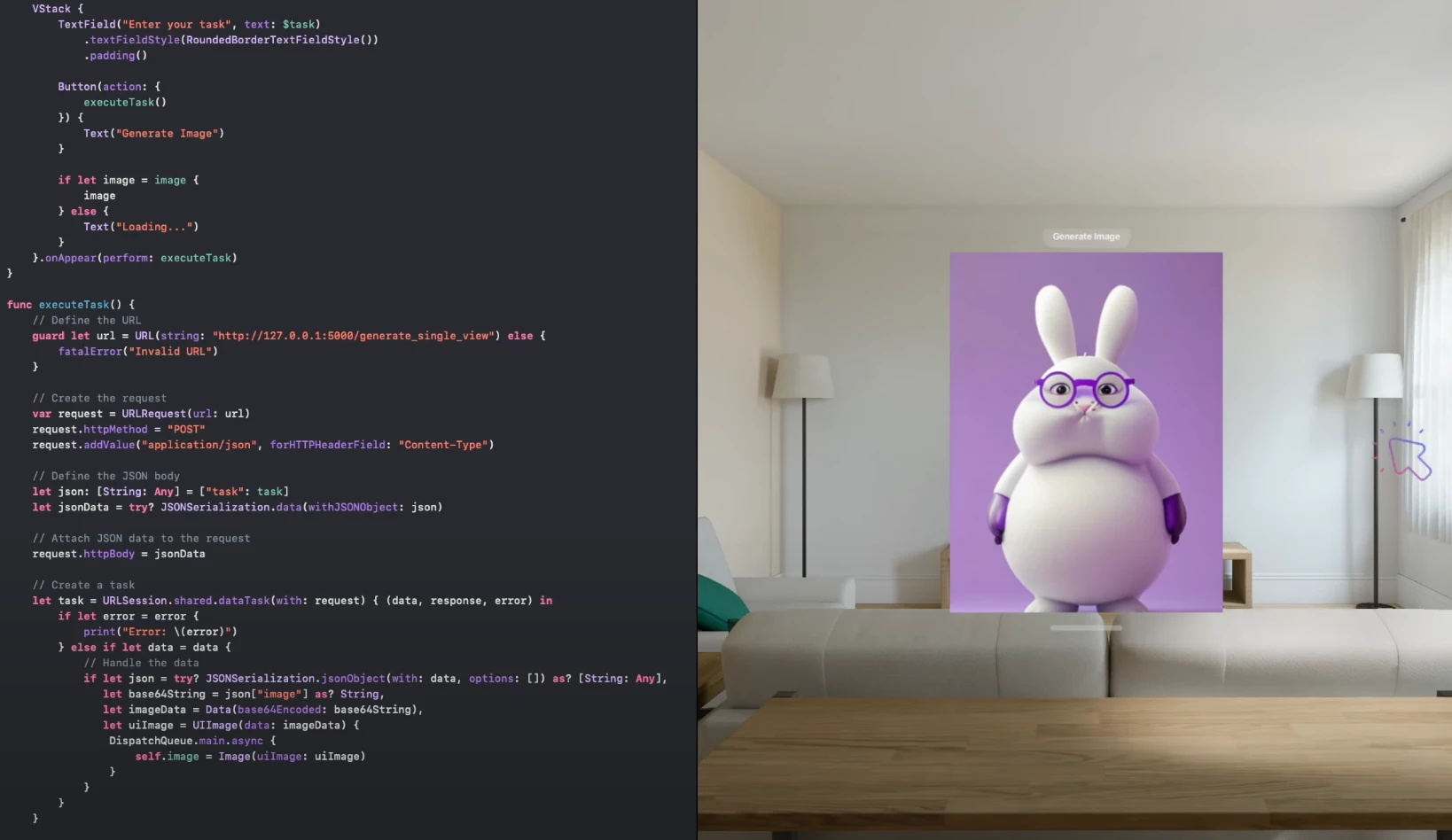
and we need a lot of cute 3d character image without background


I would like to use Adobe stocks such as
https://stock.adobe.com/kr/images/3d-monster-cartoon-character-fun-toy/637252498
as dataset to train diffusion model
Let me know what should I do.
Flus, why there is no Adobe AI conference?