

Using Spinnaker Like a Pro When Multi-Tenancy Is a Nightmare
Author: Dan Popescu

This blog detail one of the most common operational procedure Adobe Experience Platform performs with Spinnaker. Please note this scenario may not apply if the environment you’re working with is not dynamic. In our case, there many teams with multiple Kubernetes clusters so there is a constant need for onboarding/removing clusters or adding/removing namespaces from accounts.
Spinnaker is one of the most powerful open-source tools available for performing continuous deployments. My team is one of the first at Adobe to use Spinnaker in production at scale and over time we’ve expanded from VM deployments in AWS to Kubernetes and Azure.
The whole CD ecosystem is based on Spinnaker and we offer this solution for multiple teams within the company. Currently, more than 20 different engineering teams use our Adobe Experience Platform.
When talking about multi-tenant solutions one of the most important aspects to consider is isolation. This implies that teams cannot interact with each other’s infrastructure and thus if any incidents happen the blast radius is contained.
To get a general perspective of our environment:
- We manage over 100 Kubernetes clusters, perform VM deployments, and AMI baking for both AWS and Azure over thousands of instances.
- We have tens of Jenkins servers, use multiple repositories for Helm/Docker.
- The whole setup is hooked to a single Spinnaker setup.
All in all, we have ~300 Spinnaker accounts. Therefore, a lot of work needs to be done to keep the infrastructure up to date. Due to the number of accounts, Spinnaker needs to continuously scan all accounts (AWS, Azure, and Kubernetes). Spinnaker needs to fetch the latest objects to reflect infrastructure changes, scan, and retrieve Docker images and Helm charts across all repositories. Finally, it needs to perform many deployments over hundreds of Spinnaker applications.
This continuous process gets more complex with each account we onboard on Adobe Experience Platform. It took multiple iterations to get to this multi-tenant setup. To give you a perspective on why we need to have automation in place for all manual tasks, the whole ecosystem is currently managed by a small team of 5 which handles both the infrastructure management for Kubernetes, AWS, and Azure and the deployment platform based on Spinnaker.
Spinnaker dynamic account onboarding
Before we dive further into the multitenancy details, we need to talk about how we’ve implemented this feature since it is a critical step for our self-serviceable multi-tenant platform. As mentioned in the introduction, our Spinnaker environment is dynamic and accounts are frequently created, modified, or deleted. The task of onboarding or removing an account was one of the most frequent toil work we had to perform.
Before adding the dynamic account feature we used to have an onboarding process that was tedious and prone to errors. When talking about Kubernetes specifically, onboarding a cluster requires several steps. In our case, there was a collaboration between clients and Spinnaker administrators:
Client-side
- The first thing that the client had to do was to create the necessary resources that are needed by Spinnaker to authenticate against the cluster. This involved creating the Spinnaker service account, a role with the required permissions, and then finally, binding them together.
- Once the necessary service account was configured, the kubeconfig file had to be generated. The file and the cluster details were then sent securely to a Spinnaker admin.
Admin-side
- With the received data the admin had to add the account details in our helm deployment and then perform a sync on Spinnaker.
Even if we had to onboard a new cluster, remove an existing one or modify its details, a new Spinnaker deployment had to be performed. This was a tedious and time-consuming process that we had to address. Below is a short diagram of the old account onboarding process:
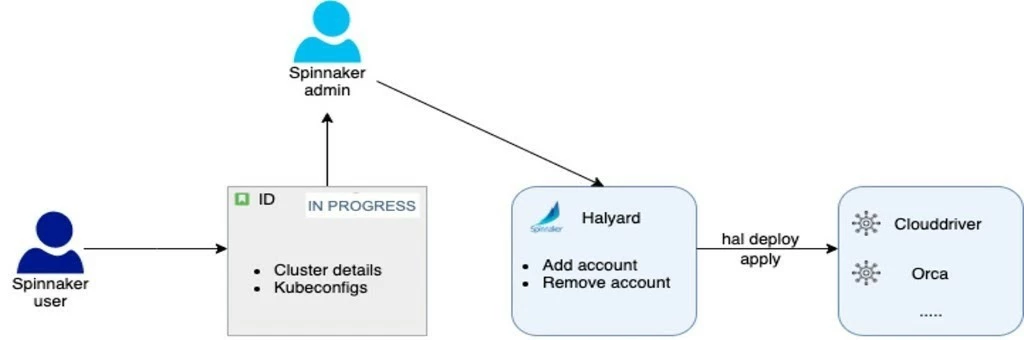
We decided to find a way in which this process was a great customer experience while involving less work from Spinnaker admins. After looking into several solutions on how to achieve this, we’ve decided to go with Spring cloud configuration and since the infrastructure is running on AWS, add support for S3 storage for cluster files.
The new process performs account synchronization automatically, requires no Spinnaker deployments, and has low maintenance. The key of the whole operation is that the Clouddriver microservice periodically reads the S3 bucket and performs an account refresh on the list if changes are detected.
The new mechanism is still a two-sided solution but it’s more compact and efficient:
Client-side
- The client opens a new PR in our repository and adds the necessary account details.
Admin-side
- The admin reviews and merges the PR.
Once the PR is merged, a Kubernetes job starts which validate the data and generates the Clouddriver config file for the new account. The file is then pushed to S3 bucket where all account details are stored. The kubeconfig files are stored in the same bucket but in a different path. Finally, the clouddriver-local.yaml file is generated which contains the newly added account. Spinnaker periodically scans the S3 bucket for this file and if a new version is detected, a Clouddriver account refresh is performed. Within 2 minutes after the PR is merged, the new account will appear in the Spinnaker UI. Below is the simplified diagram of the dynamic account onboard process:

To enable this feature, follow the Spinnaker documentation as shown in the section using an S3 backend. The new setup helped a lot in reducing the toil work we had to perform and allowed us to focus more on developing new features for Spinnaker. In case you are dealing with similar issues on your side, then maybe this article can give you an overview of how to transition to a setup like this.
Spinnaker and Multi-Tenancy
We use a multi-layer approach to isolate teams while ensuring a great customer experience:
-
At the Spinnaker account level: Teams will have LDAP permissions set for each account. If you are familiar with the Clouddriver config file structure, then the following image will look familiar:

This will set read and write permissions for each Spinnaker account thus allowing only authorized users to access them.
-
At the Spinnaker application layer: LDAP enforcement is again configured here to allow certain groups access to an application:
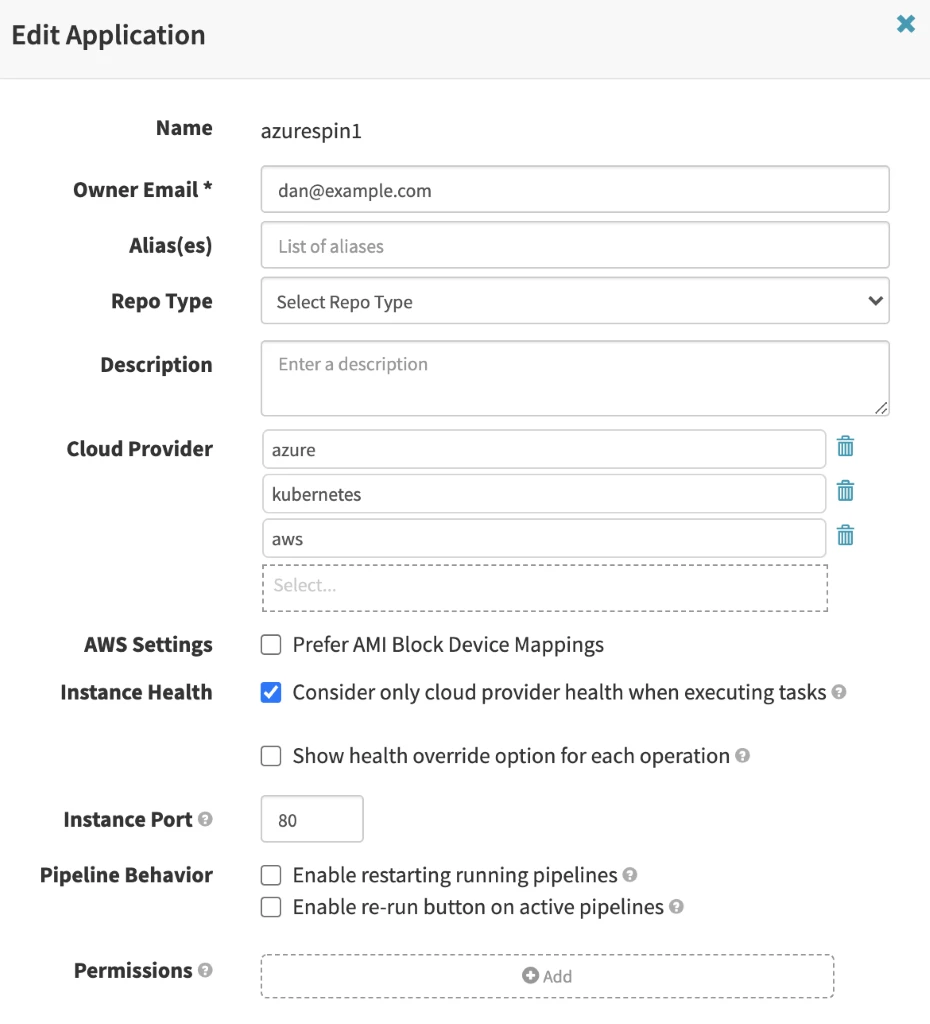
Note that even if you have access to a Spinnaker application in the UI, another validation takes place at the account level as shown in the previous section.
-
At the Kubernetes namespace layer: Until now we have covered isolation layers that are built into Spinnaker, there is one more that is a custom feature for our Kubernetes multi-tenant platform. When talking about multi-tenant Kubernetes clusters one of the most critical items to consider is to provide a namespace isolation mechanism. Adobe has built its own Kubernetes onboarding solution (in short, EKO) to provide its users a self-serviceable platform for managing namespaces. These namespaces (aka virtual K8s clusters) provide its users LDAP enforcement for setting custom permissions and resource quotas. Teams will only have access to their intended namespaces while being allowed to consume their allocated resource quotas. This API driven architecture is shown in the following diagram:
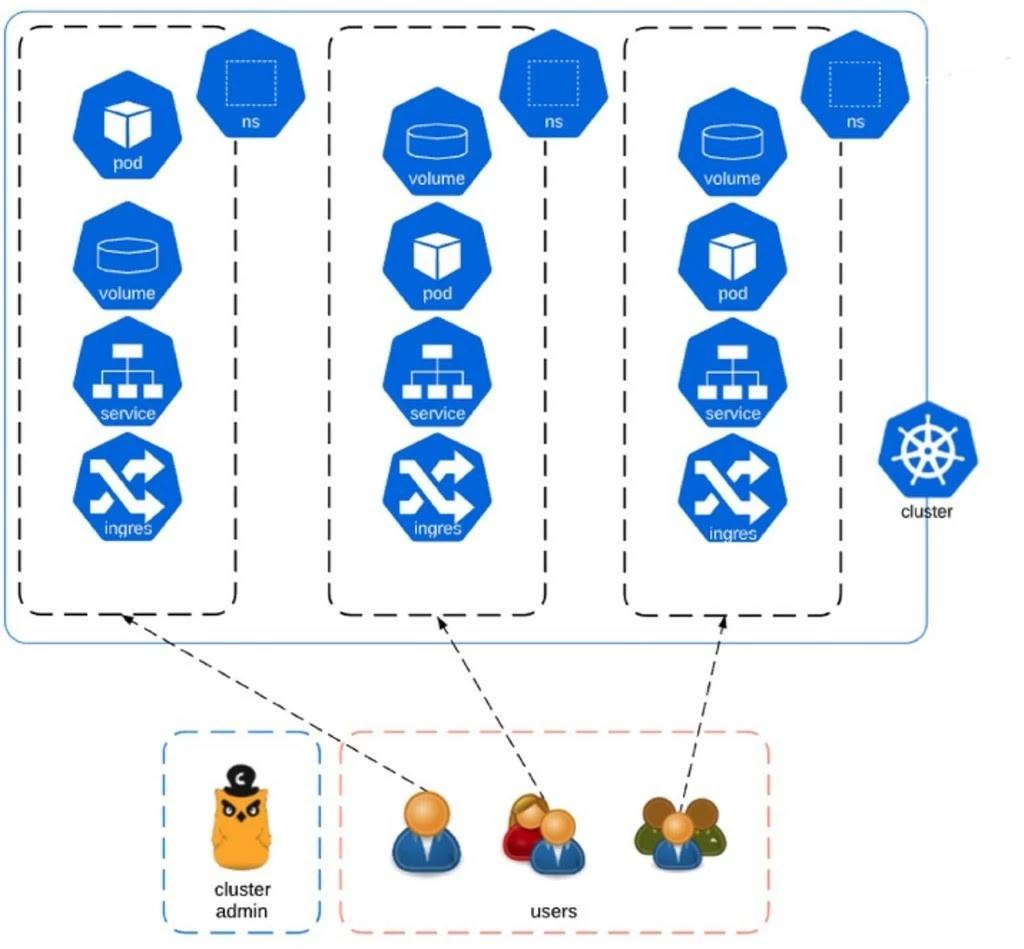
EKO allowed us to hook Spinnaker and dynamically perform namespace management. This solution is built and maintained by another team within Adobe and the section was just a short overview of the whole setup.
We have taken the Spinnaker dynamic account onboarding mechanism described previously and extended it to incorporate this new feature for creating and deleting Kubernetes namespaces by using the EKO API. Spinnaker allows you to build extensions using custom job stages which we have considered when implementing this feature. These custom stages look native to Spinnaker and users will be able to add these to their pipelines as desired.
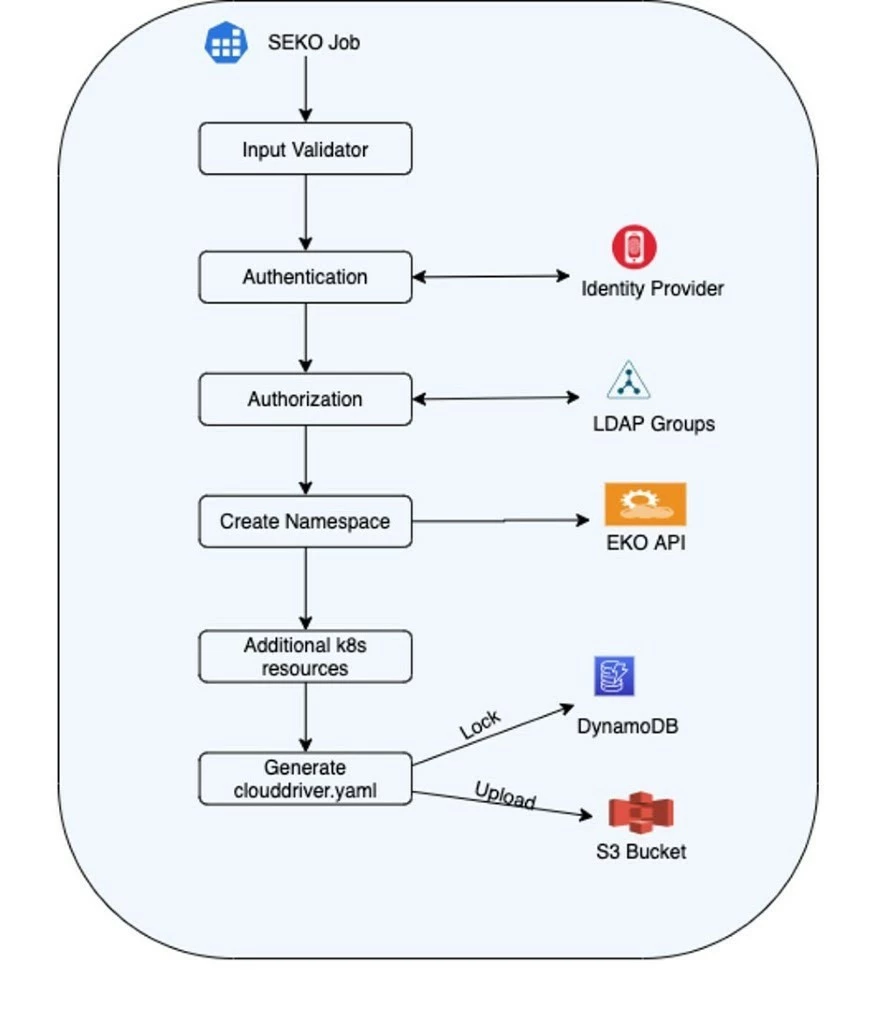
This new feature was named SEKO (Spinnaker Kubernetes Account Onboarder) and allows users to automatically onboard namespaces in our multi-tenant platform via custom Create and Delete stages. With it, you can perform namespace creation, automatic onboarding in Spinnaker, application deployments and namespace deletion in a single pipeline execution (this is important). The image below shows an overview diagram for how this mechanism works:
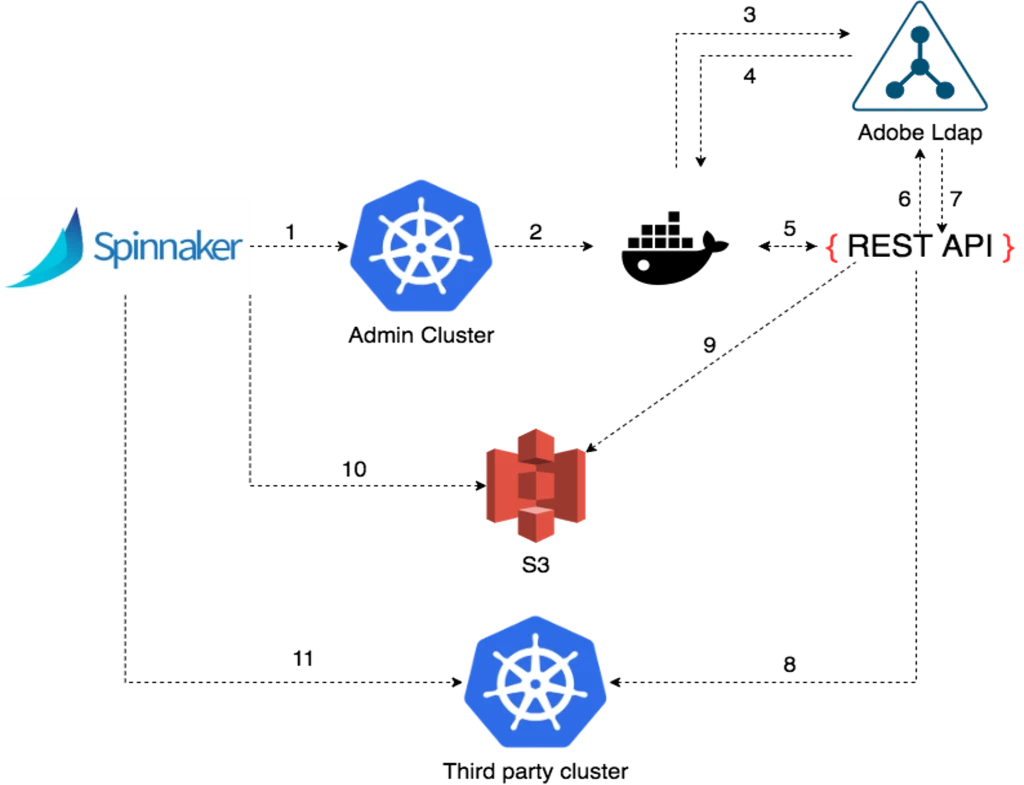
Behind these custom stages there is a Python application that’s executed by Spinnaker and performs several steps, as follows:
- Spinnaker schedules a new job on the admin K8s cluster.
- Container starts in an isolated namespace (OPA enforcement).
- The executing user is authenticated against Adobe’s LDAP.
- One JWT token is generated that will be used to authenticate against the EKO API.
- A request is sent to EKO for the intended operation (create/deletion) which contains all details needed to identify the namespace.
- EKO will also validate on its side that the requesting user has the necessary rights to perform the operation.
-
The user is either allowed or denied access.
Behind the scenes, EKO will create the following Kubernetes objects:
- Namespace
- ResourceQuota
- LimitRange
- NetworkPolicy
- Rolebinding
These objects are needed for providing an isolated namespace for each team.
- Spinnaker service account is created on the multi-tenant cluster. A role binding is created for this service account on the given namespace. This will grant Spinnaker the necessary permissions on the namespace. SEKO takes care of the steps described so far, next steps are performed by the dynamic onboarding mechanism in Spinnaker.
-
Kubeconfig and the Clouddriver files are generated and uploaded in the S3 bucket.
-
Spinnaker periodically performs account refresh by scanning the S3 bucket and detecting changes.
-
Namespace is now accessible in the Spinnaker UI as a new account and can be used for deployments.
SEKO will act as a liaison between multiple entities which are part of this process. Going further into the details on how it works, SEKO allows us to parallelize stages (running multiple in parallel) since we want those to be used in multiple pipelines across multiple Spinnaker applications. This also means that in case two pipelines want to modify the account list at the same time their changes are not overridden. Therefore, we’ve added a locking mechanism using DynamoDB which creates a queuing process while S3 file uploads are performed. The internals of our app is shown in the following diagram:
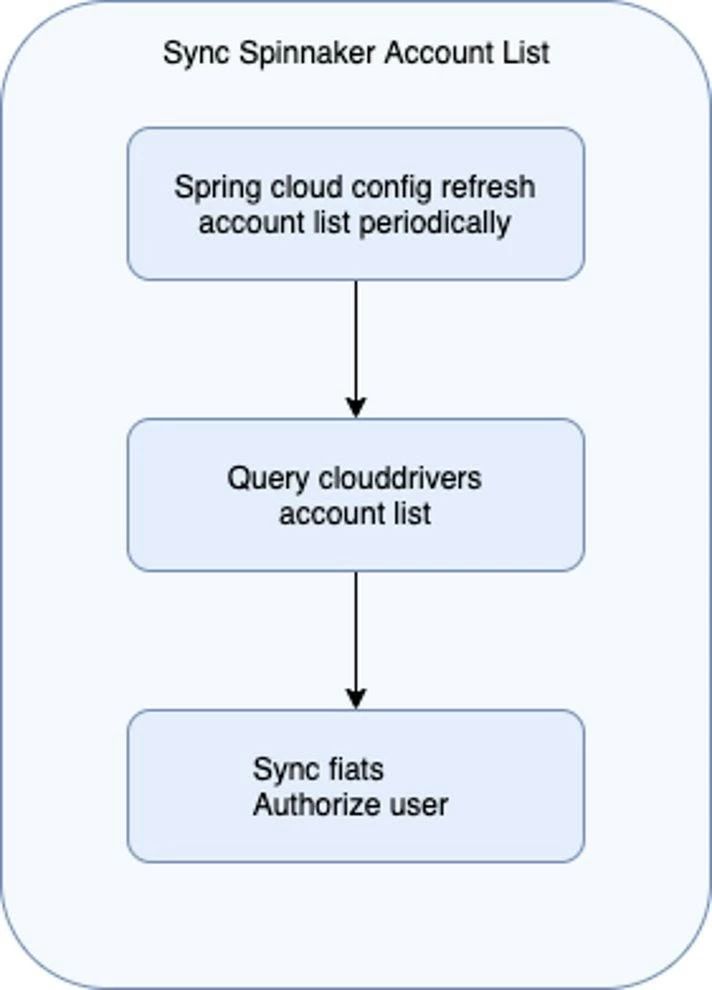
Spring cloud configuration will periodically refresh the account list by scanning the S3 bucket. Clouddriver microservices will then be synchronized to include the newly created/removed account. Finally, the Fiat microservice will perform a user authorization process across accounts. This internal mechanism is exemplified in the following image:
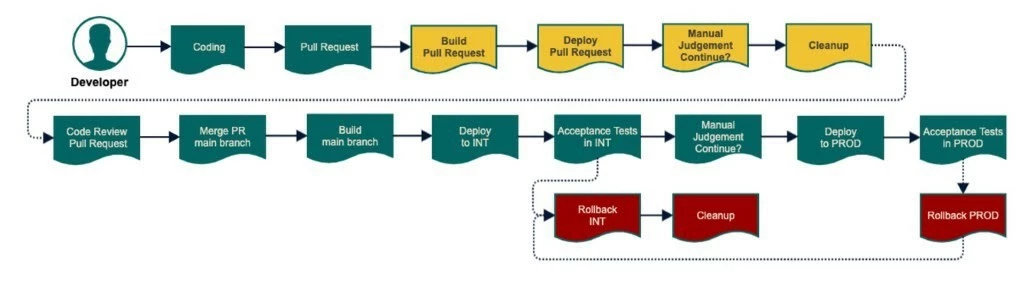
This feature unlocked the possibility of spawning preview environments. Preview Environments are short-lived environments based on Git Pull Requests. This happens before the code is merged into the Main Branch and can be considered an addendum to the standard CI/CD pipeline. Imagine that you are developing an app and while building a new feature you want to perform an e2e integration testing before merging it in master. A preview environment will be created and your feature will be tested as part of the whole setup before merging it:
Of course, our setup did not come without challenges, and below are some which we had to overcome:
- Dynamic configuration reload speed slows down with a big number of accounts. Since the reloading process takes a while, we also had to implement a mechanism for dynamic wait until Clouddrivers microservices sync — API calls
- Mechanism for user authorization in Fiat — API calls
- Concurrent updates on Clouddriver account list — locking mechanism
- Limiting the number of Spinnaker accounts by grouping multiple namespaces under a single umbrella.
- Idempotency for consecutive stage executions
- Isolation per team — authorization mechanism
I hope this article gives you an overview of how Spinnaker can be leveraged to manage resources in a multi-tenant infrastructure. Making sure that all pieces fit together was challenging for us and took several iterations before coming up with this final solution. Having a seamless way to manage Kubernetes namespaces in multi-tenant clusters is a crucial part when providing a self-serviceable platform. The complexity of any CI-CD setup increases with each account/cluster/team that is added and having a feature like the one described here allowed us to offer an easy-to-use platform based on Spinnaker.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
Originally published: Feb 25, 2021