
Search Optimization for Large Data Sets for GDPR
Authors: Miao Wang, Jun Ma, and Jenny Medeiros
This post describes our approach to addressing the challenges of cost and scale in scanning for GDPR compliance in Adobe Experience Platform.
In today’s data-driven economy, user data is an increasingly valuable asset. Although as companies collect increasingly more personal information, users have rightfully raised the question of how to manage their data privacy.
In response, the European Union instituted the General Data Protection Regulation (GDPR), which aims to give EU individuals control over their personal data. This has prompted other nations to strengthen their own data privacy laws, such as the upcoming California Consumer Privacy Act (CCPA). Under these protections, users have the right to request a copy of their data collected by a company or have it erased.
To ensure Adobe Experience Platform customers meet data privacy regulations, we developed Adobe Experience Platform Privacy Service, which automates applications to provide users with the option to access or delete their personal information. The problem is that organizations must complete each GDPR request within 30 days of receiving it, and current systems to scan datasets at scale are expensive and time-consuming. This puts organizations at risk of missing the deadline, resulting in a multi-million dollar fine and the loss of their customer’s trust.
In this post, we detail our approach to using bloom filters as a fast, cost-effective solution to complete GDPR requests at scale. We also compare bloom filter’s performance against the current system and reveal how we plan to expand this feature so more customers can responsibly manage their user’s personal information.
The problem with scanning large datasets
To understand the challenge of processing GDPR requests at scale, we should first give a general explanation of how Adobe Experience Platform Privacy Service handles a single user’s request to access or delete their personal information.
- The service receives the GDPR request and notifies the corresponding Adobe solution (in this case: Adobe Experience Platform).
- An internal service finds all the datasets containing data belonging to the user in question.
- The service then processes the request by filing a Spark job to scan each dataset, one by one.
- The Spark job scans and filters the data based on the user’s ID, then returns the results to complete the request.
In this process, the Spark job presents the main challenge for two reasons:
- Data size: The deadline to complete a GDPR request is 30 days, but enterprises commonly ingest several terabytes (TB) or even petabytes (PB) of data within that time frame. To meet regulations (and avoid costly fines), enterprises need a system capable of quickly processing GDPR requests on top of these large amounts of data. This, however, leads to our second challenge.
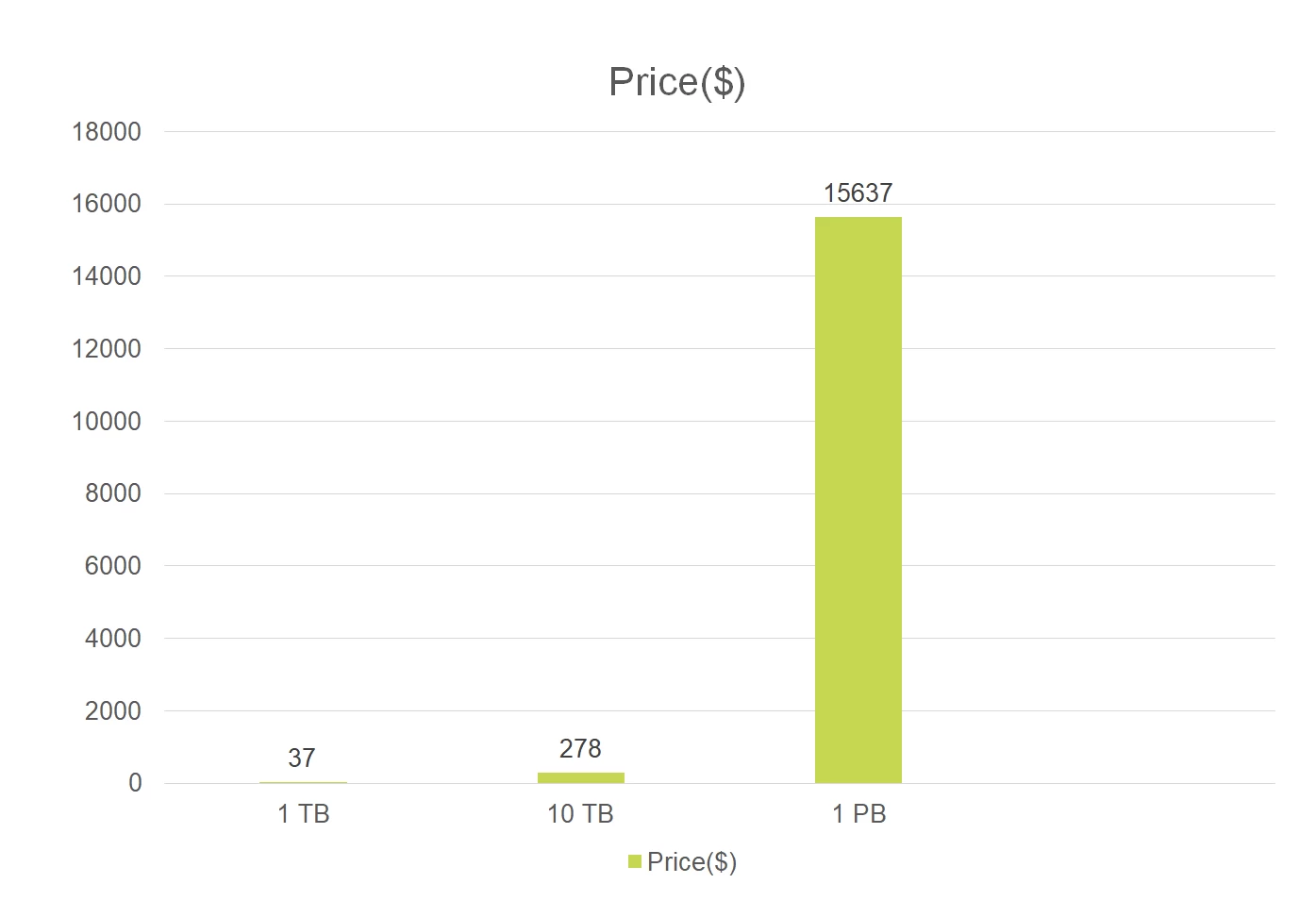
- Cost: Processing data at such a large scale is costly. To get an estimate, we ran a Spark job on two Experience Event datasets (based on Experience Data Model schema) and calculated the cost to scan 1 TB, 10 TB, and 1 PB of data. In our results, we found that scanning 1TB of data once would cost $37, adding up to $278 to scan 10 TB. This means that to scan 1 PB of data, companies are looking at a cost of $15,637 per request. See figure below.
Additionally, the problem of expensive dataset scanning is exacerbated by the fact that a Spark job must scan mountains of data unnecessarily. For example, consider a data set containing 700 TB with 35 billion unique users. On average, each user only has 20KB of data, but the Spark job must scan the entire 700 TB to find that small 20KB.
To solve this, we can enlist data skipping to avoid reading irrelevant data and save costs. In this approach, tables are partitioned by time. A query can then check the partition’s time range and skip the ones that don’t have relevant data, reducing the amount of data to be scanned per query and dramatically boosting performance.
There are a few data skipping approaches, but none offer a cost-effective approach to the specific use case of processing GDPR requests.
- Skipping by min/max statistics is too coarse grain and may not be able to skip multiple partitions.
- Bucketing doesn’t support multiple ID columns in a dataset.
- Dictionary encoding works better with low cardinality value.
Subsequently, we decided that our best solution was to implement bloom filters.
Bloom filter provides faster lookup at a lower computational cost
Bloom filter is a fast, space-efficient probabilistic data structure that can add an element to a set or check whether a given element is in the set. An empty bloom filter is a bit array of bits, all set to 0. There are also several hash functions, each of which finds the bit position that should be changed from 0 to 1, then updates the array.
When querying whether a given element is in the set or not, if it returns:
- False then the element is “definitely not in the set”
- True then the element is “probably in the set”
The “probably in the set” means that false-positive matches are possible, but false negatives are not.
To select a bloom filter for Adobe Experience Platform, we compared several variants with certain improvements, such as cuckoo filter, which supports dynamic deletion and a lower false-positive rate. We decided to use the original bloom filter nonetheless since it’s the only one supported by Spark.
Benefits of bloom filters
Bloom filters are widely used to optimize the performance of data search queries. For example Google Bigtable, ApacheHBase, and PostgreSQL use bloom filters to save on costly disk lookups for non-existent rows or columns. Medium itself uses bloom filters to determine whether a user has already read an article before adding it to their recommendations.
In short, companies use bloom filters for its key benefits, such as:
- Strong space advantages over other data structures since bloom filters don’t store the elements themselves.
- Faster processing of requests — allowing more time to accommodate delays in case of failure.
- Data skipping that saves on expensive data scanning for elements that don’t exist in a set.
- Support of larger datasets using the same service level target (SLT). For example, a 1 PB dataset doesn’t require scanning 1 PB of data, so the dataset can be scaled.
Bloom filter example
To illustrate how this bloom filter operates in Adobe Experience Platform, we used an Experience Event dataset. The image below shows the layout of this dataset, in which names with the suffix .parquet are representing files and names starting with datasetId or ACP represent directories.
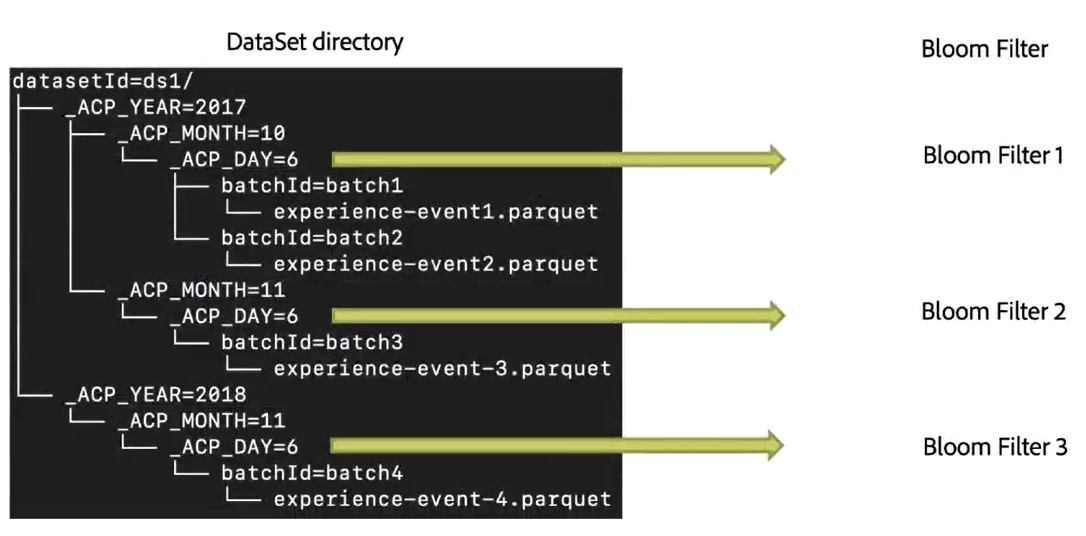
As shown in the image, the dataset is partitioned by day. We gathered the data within each day, pinpointed the user IDs, then generated one bloom filter for each partition. With the bloom filters in place, they were ready to process data requests.
In the case of a customer sending a request to access or delete their data, a Spark job would scan this dataset and read each partition’s bloom filter. If a partition didn’t contain the customer’s data, it would skip the whole partition and only scan those that do before returning the results to the customer.
Testing the performance of bloom filters
To measure the performance of this solution, we ran a Spark job in a 1 TB dataset. Each job consisted of one driver and 40 executors, where each executor had eight cores.
Speed test: Bloom filter vs. no bloom filter
For this initial test, we ran the Spark job for the 1 TB dataset without a bloom filter, then ran it a second time with a bloom filter. As shown in the graph below, we found that without a bloom filter the scan required 67 minutes to complete. In contrast, with a bloom filter, the second scan only lasted 7 minutes — cutting the Spark job’s runtime by 89%.
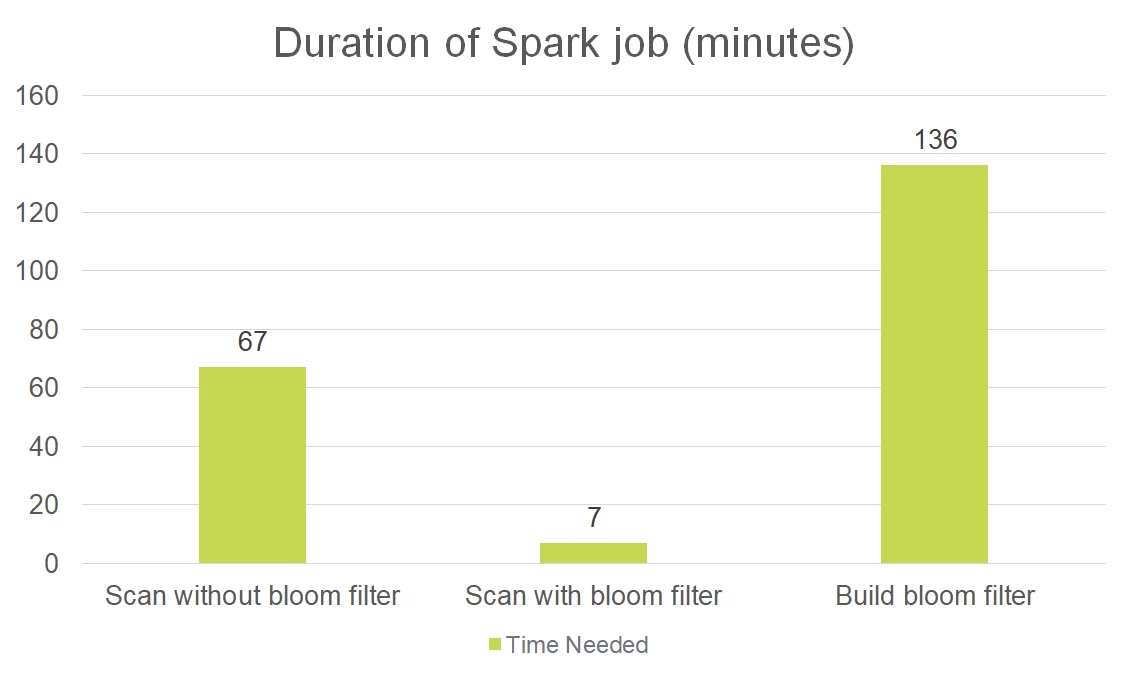
The graph above also shows that an extra computing cost is introduced when building a bloom filter from a raw dataset. This cost, however, can be amortized across multiple scans since a single bloom filter can be used multiple times.
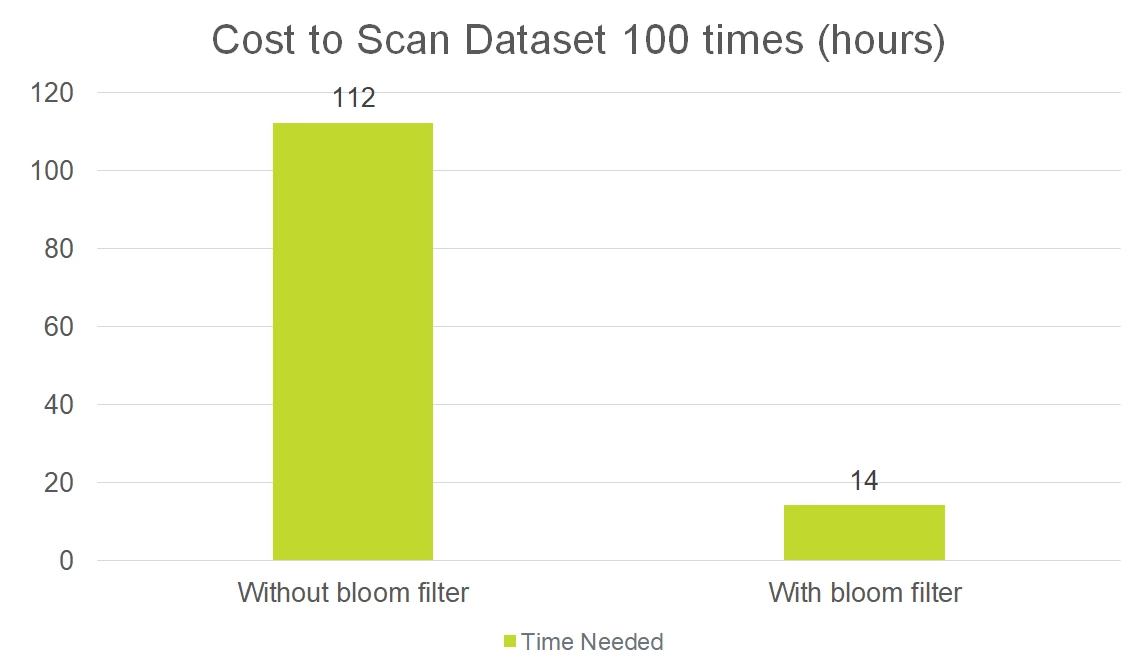
Scale test: Bloom filter vs. no bloom filter
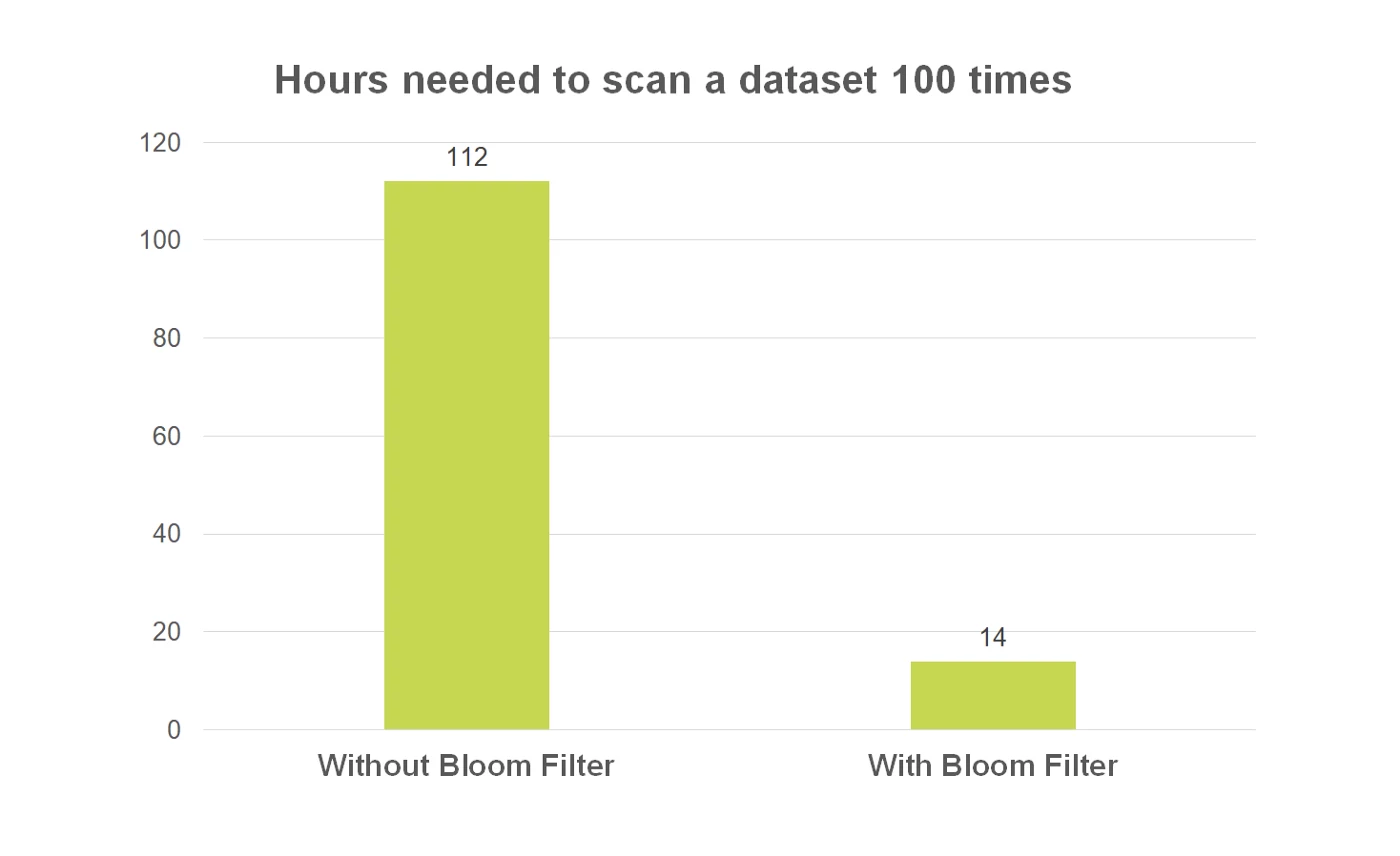
To measure the cost of running a Spark job at a larger scale, we calculated the hours needed to scan a 1 TB dataset 100 times with and then without a bloom filter. As shown in the graph below, we determined that without a bloom filter, the Spark job would take 112 hours, whereas scanning with a bloom filter would only take 14 hours — an 87% reduction in runtime.
Finally, we compared the bloom filter’s performance with Databricks Delta, which uses a Z-Order index to help with data skipping. For this test, we converted a raw dataset in production to Delta format, then ran a Z-Order optimization on the ID column along with an ID search query. The results showed that the bloom filter approach performs slightly better than Delta, taking one second less to search by ID.
In conclusion, these tests verify the advantages of implementing bloom filters to rapidly sift through terabytes of data within minutes, allowing organizations with large datasets to comply with each GDPR request in good time, as well as help them maintain customer loyalty and trust.
Implementation challenges
We had a few challenges while implementing bloom filters in Adobe Experience Platform. One challenge was to update an existing bloom filter to include new data ingested after the filter had been built. Similarly, we needed to reflect the new data after a GDPR deletion request.
In both cases, our simplest solution was to periodically rebuild the bloom filter so it could include the new data. Although this approach presented yet another challenge: if a GDPR request should appear while a bloom filter is being generated, it was important to ensure the request had access to the most recent data.
To solve this problem, our current procedure is to delay the incoming request until the bloom filter has been built. Considering the end-to-end SLT for GDPR can take a full 30 days, a few hours delay in processing the request is of little significance.
What’s next?
To further refine our bloom filter approach, we intend on implementing a cuckoo filter to support dynamic deletion as well as dynamic addition, which will guarantee existing bloom filters are always up to date and spare us from continually rebuilding them to reflect new or deleted data. Cuckoo filter also promises a better false-positive rate and reduced time complexity.
Additionally, we plan to streamline bloom filter’s performance by expanding the read logic from the Spark job driver and distributing the work to various executors. This will allow the system to read bloom filters concurrently, rather than sequentially, and cut the overall processing time.
Lastly, we are preparing the bloom filter feature for production so other Adobe platforms, such as Adobe Experience Platform Query Service, can also leverage bloom filters to optimize its search queries.
With many more exciting improvements ahead, we’re proud to embrace data protection standards and continue helping organizations better understand their customers through Adobe Experience Platform while safeguarding every user’s right to data privacy.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
Originally published: Oct 24, 2019