

Modeling XDM Data for Data Science at Scale on Adobe Experience Platform
Author: @danny-miller , Shrutivj, and Douglas Paton

In this post, we look at data science for XDM and make it scale. We look at how we build tens and hundreds of models and activate it for Adobe Experience Platform. And we look at how data science is manifested at Adobe and basics around operationalizing.
This blog details a single implementation or customization on Adobe Experience Platform. Not all aspects are guaranteed as general availability. If you need professional guidance on how to proceed, then please reach out to Adobe Consulting Services on this topic.
When it comes to data science models, our focus tends to be on building all these amazing models. But what about operationalizing or activating them with the Adobe Experience Platform.
We look at the output, which eventually turns into a score or classification that can be assigned to a person. We look at things like if a person is likely to buy or churn. This, may in turn or in parallel, feed into whether a person is considered a High-Value Customer or a High Credit Risk.
Once we have this information, we take the data and add it to the Unified Profile of that person, and activate the profile depending on their preferences.
There are a few ways we go about using data science across Adobe in our products.
The first is with embedded AI technology, like Adobe Sensei, within our products. Adobe Sensei helps users deliver personalized, more timely experiences by analyzing their data using machine learning. We also offer users out of the box models that they can use without having to know too much about data science.

Users also have the option to bring custom models into the fold. They can work with data science models that are built externally and execute them within Adobe Experience Platform without having to export and import data. Our customers can also build their own models inside of Adobe Experience Platform using Data Science Workspace. This gives our customers the ability to focus on the analysis that is most important to them, such as cluster analysis, churn, product recommendations, for example.
Customers also have the ability to bring in their own scores, which gives customers the ability to utilize models and data that is not in Adobe Experience Platform.
We have to be able to store the data of these models. The challenge is that they may contain both external and internal scores and as a business evolves, how things are modeled within the business changes as well.
The big question we found ourselves asking was how do we store models in such a way to allow us to store hundreds of ever-changing models and scores?
Basics for storing data
At its most basic, whether you’re using an out of the box solution, building your own in Data Science Workspace or bringing your own scores into the equation, stored data contains something like the following:
- Model Name/Used for
- Product
- Score or classification
- Date executed
Each model also puts results into a new dataset.
The questions we were left to sort out were how do we bring this in? We found the idea of having one dataset per model allowed us to have the most control over the data. As the current score changes over time, we had to consider whether we store the data in the current state or do we look at past states as well.
We had three approaches we could take to manage this.
- A records-based approach. With this method, we create a new attribute for every single model. So every time we built a new model, we needed a new attribute. We also only knew the current state and could only segment using the current state. As new models roll out, we’re modifying the schema.
- Time-series (Experience Event) approach. This allowed us to store the data as an event, not a record. We still needed to create a new attribute for each model. But, because we stored this as an event, we had the ability to know both the current state and the historical state, allowing us to use a more dynamic form of segmentation. The schema gets modified here, but we have a timestamp, which gives us a history of each event.
- Generic approach. With this approach, we pivoted the data and, as a result, didn’t have to create a new attribute each time. The model name, attributes, and score can change, but the schema remains the same.
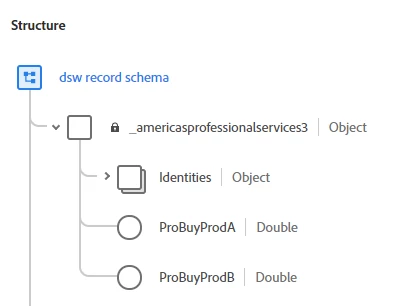
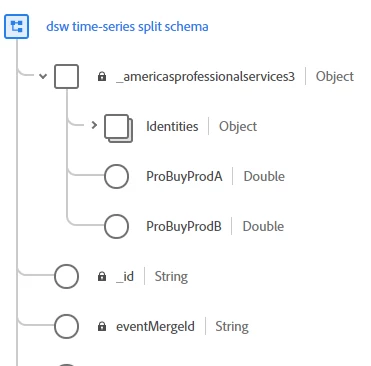
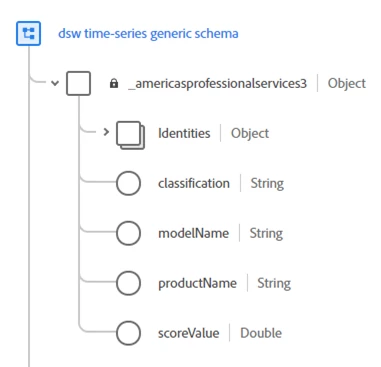
How does this affect segmentation?
Segmentation is handled differently for each of the three approaches. With the records-based approach, segmentation is simple. There isn’t much that needs to happen because you only know the current state, so segmentation is based on that state.
When an event-based approach is used, segmentation is a bit more complicated. You have to look at the current value, and you have to make sure that there haven’t been any other events following that value. This is valuable because it allows you to build a segment based on what a score used to be versus what it is now. Or build a segment for those who changed states from yesterday to today.
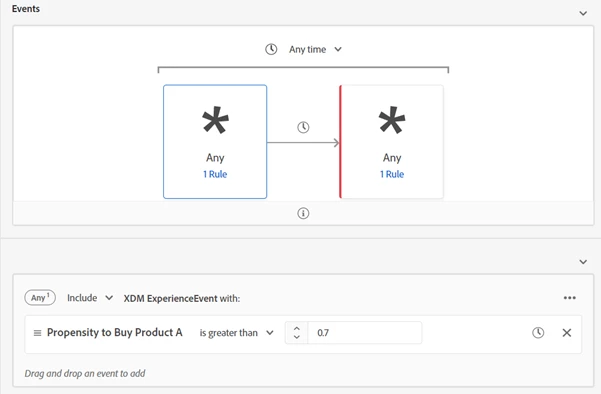
For the generic approach, segmentation is even more complicated. You need to know the current state and specify model name and product name because they are stored as data, not specific attributes, but you also need to exclude certain things, as well. What’s nice about this is that the schema doesn’t change, so this provides more flexibility to ingest various data science models without changing schemas with the tradeoff of more complex segmentation.
Other things that we need to consider
As we worked on this, we came across other factors that we need to address. Versioning was a big one. Models are constantly evolving as they are used and there is a need to bake in support for that. We are faced with the task of figuring out how we define that (or if we even need to). In the end, we decided we didn’t need to explicitly track a version number in the schema since we had a date associated with the score.
We also need to consider independent data science teams within a company. We asked questions like are they building their own models? Do they need governance? Does each team operate in isolation or do we need to find a way to coordinate their efforts? The design of multiple datasets using the same schema allows for teams to independently populate their own dataset using a common structure. Data governance still needs to be involved to ensure whatever model and product names being used are not clashing with others.
There was also the matter of complexity and whether or not that’s the responsibility of the data team, the modeling team, or the segmentation team. Since each choice shifts the complexity to another area, there is a tradeoff that needs to be considered in terms of skill set, scale and ongoing GTM speed as each model is operationalized.
What is the recommendation?
What we found while looking at these things is that there is no clear answer. There are too many factors at the moment, things like how much scaling is needed by anyone business unit (BU).
Our preference was to lean towards an enterprise view with BU-specific flexibility. Allow for each BU to manage and store their own dataset while utilizing a common enterprise schema. This allows for what we think is a good balance of control and flexibility along with a common schema that can evolve slowly over time as needed.
We can use profile merge policies in segmentation to include or exclude, depending on where or if needed. It also allows for flexibility within the governance of the data feed ownership.
Looking to the future
The next step we need to take is to look at managing the schema holistically and over time. We need to determine whether we use smaller, individualized schema for each team (based on a common core) or use a single, massive uber schema that everybody shares. We also need to determine whether data science teams own the schema they work with or if they need to tap into an Enterprise data modeler or shared service. There is also the possibility of a hybrid approach where one team does things one way and another uses a different approach.
As we are just beginning to explore this at various companies and the tradeoffs, we’ll be going deeper into this in future posts.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up here for future Adobe Experience Platform Meetups.
References
- Adobe Experience Platform — https://www.adobe.com/experience-platform.html
- Adobe Sensei — https://www.adobe.com/sensei.html
- Data Science Workspace — https://www.adobe.com/experience-platform/data-science-workspace.html
Originally published: Feb 6, 2020