
GraphQL: Making Sense of Enterprise Microservices for the UI
Authors: John Anderson and Nate Ross

This blog details how Adobe Experience Platform engineering uses GraphQL with over 40 internal contributors across 40 API endpoints at Adobe to improve their agility and velocity.
GraphQL has become an important tool for enterprises looking for a way to expose services via connected data graphs. These graph-oriented ways of thinking offer new advantages to partners and customers looking to consume data in a standardized way.
Apart from the external consumption benefits, using GraphQL at Adobe has offered our UI engineering teams a way to grapple with the challenges related to the increasingly complicated world of distributed systems. Adobe Experience Platform itself offers dozens of microservices to its customers, and our engineering teams also rely on a fleet of internal microservices for things like secret management, authentication, and authorization.
Breaking services into smaller components in a service-oriented architecture brings a lot of benefits to our teams. Some drawbacks need to be mitigated to deploy the advantages. More layers mean more complexity. More services mean more communication.
GraphQL has been a key component for the Adobe Experience Platform user experience engineering team: one that allows us to embrace the advantages of SOA and helping us to navigate the complexities of microservice architecture.
Adjusting to a Microservice-Oriented World
HTTP Overhead
One of the issues facing UI teams is increased HTTP overhead. Consider first an example situation where a UI needs to fetch every “A” object, along with its related “B” objects. Each “B” also optionally has a “C”. Before GraphQL, the flow looked something like this:
There are a number of user-experience challenges with this approach:
- The calls are larger in number, compared to a single call to a monolith. While some techniques (like multiple subdomains) can mitigate this effect, modern browsers also limit the number of concurrent calls.
- These network segments are long and traverse the public network, causing increased latency and decreased client application performance.
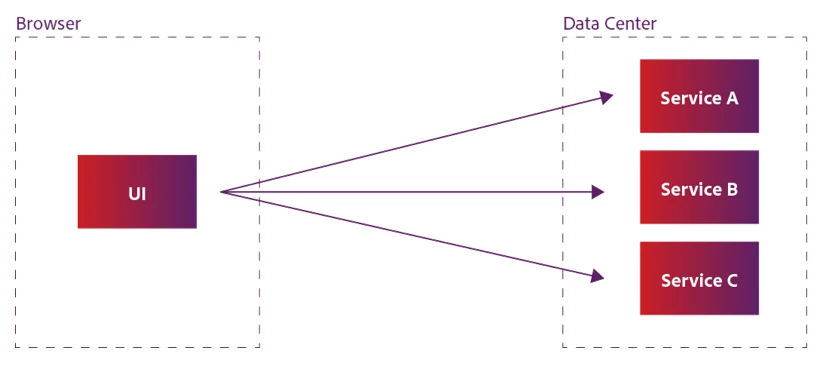
GraphQL installations allow enterprise teams to access multiple object domains with a single call, significantly reducing the resulting HTTP overhead. The call flow instead looks more like this:

In this example, a single, expensive network call is made over the public network. Once inside the data center, GraphQL can orchestrate all the dependent calls that need to be made>inside the data center, where network I/O is much less expensive.
Data Stitching and Call Orchestration
This brings us to two related topics:
- How do objects from various services get reformatted and joined together for presentation in a UI?
- Which parts of an application house (and ideally centralize) this logic?
For example, if I want to show a list of datasets in Adobe Experience Platform, I may also want to show the related XDM schema, along with the first and last name of the user who created it. These objects come from three different systems and need to be formatted and joined for presentation in a table in the UI. Additionally, I want to optimize the call orchestration. Once I have dataset metadata, I can fetch schema and user profile information in parallel.
Before GraphQL, this code was often spread throughout various pieces of a large UI application. This is likely due to a number of reasons:
- Our UI is maintained by many teams and dozens of engineers. Coordinating and detecting this sort of duplication poses a difficult and manually-enforced collaboration problem.
- UIs are often built for a specific flow. Ubiquitous objects (like user profiles, pagination metadata, or a core domain object) are used in various contexts throughout the experience. Anticipating these contexts is difficult.
GraphQL’s graph-oriented consumption pattern and its strong typing solve this problem. Every time our engineering team sees a dataset in an API response, it always looks the same. This makes a huge difference not only in terms of code duplication and application maintenance, but it offers a level of standardization we haven’t been able to embrace in the past. Here is a GraphQL query example fetching related data from three services:
query dataset($id: String!) {
dataset (id: $id) {
name
state
createdUser {
firstName
lastName
}
schema {
id
name
createdDate
modifiedDate
}
}
}REST offers us a standard way to interact with domain objects in terms of URL familiarity, statelessness, and HTTP verbs. However, GraphQL gives engineering teams a level of semantic standardization (and validation!) that is hugely beneficial. Knowing how to build components against common data shapes accelerates UI development and makes fixing bugs and extending our applications quicker and easier.
Here’s a snapshot of the graph we interact with as UI engineers working on the AEP UI. Traversing and documenting this complexity manually just isn’t scalable. By integrating our upstream APIs with GraphQL, we get this sort of discoverability out of the box.

API Heterogeneity
APIs created by different teams tend to accrue slight differences despite our efforts to discourage it. UI engineering teams looking to use multisource data often encounter these differences:
- Pagination schemes
- Authentication
- Authorization
- Varied representations of common data objects
REST API standardization is an important effort, and GraphQL helps us identify inconsistencies that teams can fix. It also gives us the agility to abstract away these differences for UI engineers consuming the graph.
Even in the sunny case that an enterprise organization’s standardization efforts are perfect, there will still be events out of our control that cause latency between the practical and the ideal. We’ve added some top-notch folks to Adobe in the past few years, and these new teams and their APIs will take some time adjusting to our technology and standards. In the meantime, the UI teams can bridge those gaps with GraphQL integrations.
It’s worth noting that UI engineering teams often build views for API data that doesn’t yet exist. We’ve had great success at Adobe in defining our own GraphQL schemas before the upstream data services are live. This gives us the flexibility to move forward with mock data today, allowing us to connect the final plumbing later.
Summary of GraphQL Advantages
- Easy to learn and use
- Amazing toolset and IDE integration
- Vastly improves UI engineering team agility and velocity
- Faster client application performance
- Cross service discoverability, standards, semantics, and validation
Operations
- 0 downtime, 0 customer outages
- CPU usage low (5–10%) on K8s cluster, using 0.5 cores across instances
- Low memory usage (<200MB)
Engineering Collaboration
- Over 40 internal contributors, across UI engineering, data services engineering, and operations
- 10–30 commits per week
- 3000–5000 additions per week
- 40+ API endpoints integrated and in use
“GraphQL for Adobe Experience Platform has been running in some form since the spring of 2019. We recommend using GraphQL for enterprises and their UI engineering teams, based on our experience.”
GraphQL Challenges
As various UI teams have started picking up GraphQL throughout Adobe, we ran into a few challenges along the way. None of them were insurmountable and we were able to learn a few things in the process.
One Graph Principle
As our team in Adobe Experience Platform started investigating GraphQL, we were surprised to find out that several other groups throughout the company were at various stages of adoption as well. Several of these implementations also contained objects we wanted to include within our graph. Our desire for a single unified graph dictated that we needed to converge. However, within a large organization like Adobe, it would be very difficult to bring two separate GraphQL APIs together into one.
A few options emerged to solve this issue. We explored publishing reusable GraphQL modules via npm, we looked at a fork model where teams could push and pull changes from a single upstream repository and a few other approaches. Ultimately, we decided to use Apollo Federation which allowed us to have a single gateway with federated schemas. This allowed each team to continue developing their own GraphQL API independently, but house them all behind a single gateway that understood how to federate queries between these instances. This topic deserves its own separate post, so keep an eye out for a follow-up article.
Thinking in Graphs
Another challenge for us was helping our teams rethink their objects as graphs. While many of our internal UI models were already structured in this manner, we were also very used to the data shapes provided by our API service teams.
Typically with an API response, you get a foreign key identifier in the response. It’s up to the developer to make the API call, get the response, and stitch the response to the previous response to create the model for the view. We had scenarios where a developer stitched six responses at once in complex models. This creates complex maintenance of the stitched responses.
Using GraphQL, the UI developer asks for the data in the shape they need. This eliminates the complexity and maintenance required for multiple API responses across UIs. The tendency for developers to include foreign keys in their GraphQL models was a challenge. We had to discourage this practice in favor of graph composition. As a group, we identified these common pitfalls, and through presentations and meticulous code review we were able to establish patterns and learn as a group.
In another case, an upstream API had a recursive object structure. It took us a considerable amount of time to figure out how we would represent the result because it was not apparent to the UI how many levels of depth would be required. We ended up completely reshaping the response to an array type to avoid the temptation to make everything a generic JSON type.
Versioning
GraphQL best-practices are clear when it comes to versioning. Don’t do it. As a group, we were tempted on several occasions to take the path of versioning things like a typical REST API. We opted for a process that allows for schema evolution through a combination of schema deprecation markers and robust logging. This helped us know when to drop an old object or field. Finally, this gave us the data on which teams to talk to in order to accelerate this process.
What’s Next
Expect a follow-up blog from us on our GraphQL innovations.
Follow the Adobe Experience Platform Community Blog for more developer stories and resources, and check out Adobe Developers on Twitter for the latest news and developer products. Sign up for future Adobe Experience Platform Meetups.
References
- Adobe Experience Platform
- Graph QL
- API Documentation
- npm
- Apollo Federation
- Apollo Federation Documentation
- JSON
Originally published: Mar 4, 2021