
Supercharge your Classification Rule Builder in Adobe Analytics!
A common (and incredibly useful!) technique in Adobe Analytics is to concatenate multiple values into a variable and then use the classification rule builder to split these values back out in to separate classifications. This is fantastic way to save on the number of variables being used as we all know we have a limited number of props and eVars available!
What I hope to show you in this blog post is a method to make this process of concatenating and splitting out values more robust and faster to implement in a way that will mean you never have to spend time figuring out RegEx in the Classification Rule Builder ever again.
Background
The approach Adobe teaches is to:
- concatenate all your values into a variable with a delimiter (such as a “|”) between them
- use the classifications rule builder to split these values back out
For example, the value in your variable may be…
Email|JuneSale|20130601
Where the first value is the channel (e.g. email), the second value is campaign name (e.g. JuneSales) and the third value is the campaign launch date (e.g. 20130601)
However, this runs into some common issues:
- You'll probably have to take time figuring out the RegEx needed to split out each value every time you set one of these up
- If a value is missing for some reason, it can break
- If the order in which the values appear changes, it can break
There is a simple solution to all these issues!
…when setting the variable add a short prefix to each of the values captured.
For example:
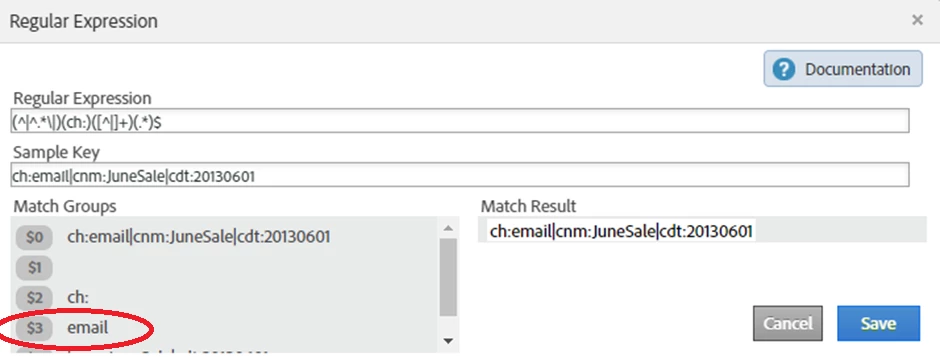
ch:email|cnm:JuneSale|cdt:20130601
…then use the below reusable line of RegEx in the classification rule builder to pull out each of the classifications based on the prefix…
(^|^.*\|)(INSERT_PREFIX_HERE)([^|]+)(.*)$
The only thing you need to change is the prefix*. For example:
(^|^.*\|)(ch:)([^|]+)(.*)$ pulls out the channel
(^|^.*\|)(cnm:)([^|]+)(.*)$ pulls out the campaign name
(^|^.*\|)(cdt:)([^|]+)(.*)$ pulls out the campaign date
The value that you want to extract always resolves to the match group $3…
Which can then be used to set the classification in the rule builder:

Conclusions
By adding a prefix to each value it allows you to use a reusable bit of RegEx to do all of your classifications. It also means that the RegEx is unaffected by the order or whether a value is missing. Hopefully this will make your classifications easier to set up and more robust!
* the reusable regex is set up to look for the pipe delimiter between the main sections and a colon delimiter between the prefix and the value – you’ll need to do some editing if you want to use other delimiters!